| CATEGORII DOCUMENTE |
| Bulgara | Ceha slovaca | Croata | Engleza | Estona | Finlandeza | Franceza |
| Germana | Italiana | Letona | Lituaniana | Maghiara | Olandeza | Poloneza |
| Sarba | Slovena | Spaniola | Suedeza | Turca | Ucraineana |
DOCUMENTE SIMILARE |
|
Le 320C50 est spécifié, dans sa version standard, pour un temps d’exécution de 50 ns, pour une horloge cadencée à 40 MHz. Il faut donc 2 cycles d’horloge pour exécuter une instruction.
Le multiplieur du DSP permet d’effectuer une multiplication en un temps de cycle (50 ns). Mais si l’on compte le temps pour lire l’instruction, pour la décoder et pour l’exécuter, il est évident qu’il est impossible d’exécuter une instruction en un temps de cycle, en utilisant une structure séquentielle classique.
Le principe du pipeline est utilisé depuis le début du siècle en usine. C’est le principe du travail à la chaine. Chaque opération est découpée en opérations élémentaires effectuées en parallèle.
Le C5X comporte 4 niveaux de pipeline qui consistent en :
FETCH : Recherche de l’instruction par accès à la mémoire programme,
DECODE : Décodage de l’instruction et des adresses des opérandes,
OPERAND (ou READ) : Lecture des opérandes en mémoire données ( bus de données),
EXECUTE : Exécution de l’opération et écriture du résultat.
Chaque niveau travaille en parallèle et envoie le résultat de son exécution à un buffer utilisé par le niveau supérieur. Cette découpe permet d’exécuter une instruction en 50 ns au lieu des 200 ns nécessaires si l’on n’avait pas utilisé le pipeline.
|
CLK | |||||||||||||||||
|
FETCH |
Instruction N |
Instruction N+1 |
Instruction N+2 |
Instruction N+3 |
|
||||||||||||
|
DECODE |
Instruction N-1 |
Instruction N |
Instruction N+1 |
Instruction N+2 |
|||||||||||||
|
OPERAND |
Instruction N-2 |
Instruction N-1 |
Instruction N |
Instruction N+1 |
|||||||||||||
|
EXECUTE |
Instruction N-3 |
Instruction N-2 |
Instruction N-1 |
Instruction N |
|||||||||||||
Il y a en permanence 4 instructions dans le pipeline. Cela n’est pas sans poser des problèmes dans certaines configurations. La plupart du temps, c’est le processeur qui gère les cassures de pipeline sauf pour des cas particuliers que l’utilisateur devra gérer.
Il existe 2 types de branchement :
les branchements inconditionnels : B (Branch), BACC (Branch to address in ACCumulator),
les branchements conditionnels : BCND adresse, condition.
De la même façon il existe 2 types de CALL :
les CALL inconditionnels : CALL, CALA (CALl to address in Accumulator),
les CALL conditionnels : CC adresse, condition.
Remarque : Dans les 2 cas, le retour de procédure est fait par RET ou par RETC condition (si l’on désire faire des retours de procédure sous conditions).
Il est possible de définir plusieurs conditions pour un branchement ou un appel à procédure :
Exemples :
BCND BRANCH, LT, NOV ; If ACC < 0 et pas de dépassement alors GOTO BRANCH
CC PROC, GT ; If ACC > 0 alors CALL PROC
CC OVERFLOW, OV ; If Overflow GOTO OVERFLOW
OVERFLOW . ; routine de gestion du débordement
RETC GEQ ; Si ACC 0 alors retour
; sinon continuer
RET ; retour
Dans cet exemple, on utilise l’instruction RETC pour retourner vers le programme principal si ACC 0, sinon on finit de traiter le dépassement.
|
Opérandes |
Condition |
|
EQ |
ACC = 0 |
|
NEQ |
ACC |
|
LT |
ACC < 0 |
|
LEQ |
ACC |
|
GT |
ACC > 0 |
|
GEQ |
ACC |
|
C |
C = 1 |
|
NC |
C = 0 |
|
OV |
OV = 1 |
|
NOV |
OV = 0 |
|
|
broche BIO à 0 |
|
TC |
TC = 1 |
|
NTC |
TC = 0 |
|
UNC |
aucun |
Fig. 32 : Les différentes conditions pour BCND, CC et RETC
Branchements ou CALL inconditionnels :
Dans le cas d’un branchement ou d’un CALL inconditionnel (ou RET), il y a cassure du pipeline. Ces instructions prennent donc 4 cycles.
|
|
CALL |
ad_PROC |
Instruction 1 |
Instruction 2 |
Instruction 3 |
Instruction 4 |
|
|||||||||||||||||||||||||||||||||||||||||||||||||
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
DECODE |
Instruction N-1 |
CALL |
Instruction 1 |
Instruction 2 |
Instruction 3 | |||||||||||||||||||||||||||||||||||||||||||||||||||
|
OPERAND |
Instruction N-2 |
Instruction N-1 |
CALL |
Instruction 1 |
Instruction 2 | |||||||||||||||||||||||||||||||||||||||||||||||||||
|
EXECUTE |
Instruction N-3 |
Instruction N-2 |
Instruction N-1 |
CALL |
Instruction 1 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||
Dans l’exemple ci-dessus, à l’exécution du CALL le processeur se branche à l’adresse ad_PROC et va lire l’instruction notée Instruction 1 qui ne sera exécutée que 4 cycle plus tard (du à la cassure du pipeline).
Pour palier à ce problème, il est possible d’utiliser l’instruction CALLD. Cette instruction ne prendra alors que 2 cycles. Par contre, les 2 instructions suivantes (instructions de 1 mot) ou l’instruction suivante (instruction prenant 2x16 bits) seront exécutées avant le branchement.
Exemple :
CALLD ad_PROC
ADD #01234h ; cette instruction sur 2 mots est exécutée avant Instruction 1
.
ad_PROC *Instruction 1
|
|
CALLD |
ad_PROC |
ADD |
1234h |
Instruction 1 |
Instruction 2 |
Instruction 3 |
Instruction 4 |
|
|||||||||||||||||||||||||||||||||||||||||||||||
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
DECODE |
Instruction N-1 |
CALLD |
ADD |
Instruction 1 |
Instruction 2 |
Instruction 3 | ||||||||||||||||||||||||||||||||||||||||||||||||||
|
OPERAND |
Instruction N-2 |
Instruction N-1 |
CALLD |
ADD |
Instruction 1 |
Instruction 2 | ||||||||||||||||||||||||||||||||||||||||||||||||||
|
EXECUTE |
Instruction N-3 |
Instruction N-2 |
Instruction N-1 |
CALLD |
ADD |
Instruction 1 |
|
|||||||||||||||||||||||||||||||||||||||||||||||||
Les instruction BD, BACC, CALAD et RETD fonctionnent sur le même principe.
Branchements ou CALL conditionnels :
Les branchements ou CALL conditionnels fonctionnent sur le même principe, sauf que le temps mis par ces instructions est de 4 cycles si la condition est vraie (cassure du pipeline) ou de 2 cycles si la condition est fausse (dans ce cas, il n’y a pas cassure du pipeline et le processeur exécute les instructions qui suivent le branchement conditionnel).
Il est possible d’utiliser les branchement ou CALL conditionnels retardés. Dans ce cas, les 2 instructions suivantes (instructions de 1 mot) ou l’instruction suivante (instruction prenant 2x16 bits) seront exécutées avant le branchement ou ne seront pas exécutés si la condition du branchement est fausse.
Exemples :
OPL #030h, PMST ; OU entre le registre de contrôle PMST et 030h, mise à jour du bit TC par la PLU
BCND NEW_ADR, EQ ; branchement à NEW_ADR si ACC = 0
Ces 2 instructions prennent 6 cycles en cas de saut (cas où ACC = 0) ou 4 cycles si condition fausse. Ces 2 instructions peuvent être remplacées par :
BCNDD NEW_ADR, EQ ; branchement retardé à NEW_ADR si ACC = 0
OPL #030h, PMST .
Ces 2 instructions ne prennent que 4 cycles, que la condition soit vraie ou fausse et ceci grace au branchement retardé.
Cas du branchement retardé avec condition vrai, branchement vers l’instruction à l’adresse NEW_ADR notée instruction 1
|
|
BCNDD |
NEW_ADD |
OPL |
30h |
Instruction 1 |
Instruction 2 |
Instruction 3 |
Instruction 4 |
|
|||||||||||||||||||||||||||||||||||||||||||||||
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
DECODE |
Instruction N-1 |
BCNDD |
OPL |
Instruction 1 |
Instruction 2 |
Instruction 3 | ||||||||||||||||||||||||||||||||||||||||||||||||||
|
OPERAND |
Instruction N-2 |
Instruction N-1 |
BCNDD |
OPL |
Instruction 1 |
Instruction 2 |
| |||||||||||||||||||||||||||||||||||||||||||||||||
|
EXECUTE |
Instruction N-3 |
Instruction N-2 |
Instruction N-1 |
BCNDD |
OPL |
Instruction 1 |
|
|||||||||||||||||||||||||||||||||||||||||||||||||
Cas du branchement retardé avec condition fausse, il n’y a pas de branchement vers l’instruction 1
|
FETCH |
BCNDD |
NEW_ADD |
OPL |
30h |
Instruction N+4 |
Instruction +5 |
Instruction N+6 |
Instruction N+7 | ||||||||||||||||||||||||||||||||||||||||||||||||
|
DECODE |
Instruction N-1 |
BCNDD |
OPL |
Instruction N+4 |
Instruction +5 |
Instruction N+6 | ||||||||||||||||||||||||||||||||||||||||||||||||||
|
OPERAND |
Instruction N-2 |
Instruction N-1 |
BCNDD |
OPL |
Instruction N+4 |
Instruction +5 | ||||||||||||||||||||||||||||||||||||||||||||||||||
|
EXECUTE |
Instruction N-3 |
Instruction N-2 |
Instruction N-1 |
BCNDD |
OPL |
Instruction N+4 |
|
|||||||||||||||||||||||||||||||||||||||||||||||||
Attention : il est possible de placer OPL après le branchement conditionnel car le résultat de cette instruction n’est pas utilisée par le test. Il aurait été faux de remplacer : par :
SUB #200h ; ACC = ACC - 200h BCNDD NEW_ADD, EQ
BCND NEW_ADD, EQ SUB #200h
puisque l’instruction SUB est utilisé pour le test du branchement.
Dans le cas où le branchement est utilisé pour sauter un ou 2 mots de code, le branchement conditionnel peut être remplacer par l’instruction XC.
Exemple :(prend 6 cycles) peut être remplacé par :(prend 3 cycles)
BCND SUM, NC XC 1, C
ADD ONE ADD ONE
SUM APAC APAC
Ce conflit est provoqué quand une instruction de chargement de registre auxiliaire précède une instruction utilisant ce registre. Ce conflit entraine la perte de 2 cycles en attendant que le registre auxiliaire soit correct.
Exemple :
LAR AR2, #012h ; AR2 12h
ADD * ; ACC ACC + (AR2)
ADD VAL
|
FETCH |
LAR AR2, #12 |
ADD * |
ADD VAL |
Instruction N+5 |
Instruction N+6 |
Instruction N+7 | ||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Instruction N-1 |
LAR AR2, #12 |
ADD (12h) |
ADD VAL |
Instruction +5 |
Instruction N+6 | ||||||||||||||||||||||||||||||||||||||||||||||||||
|
OPERAND |
Instruction N-2 |
Instruction N-1 |
LAR AR2, #12 |
lecture adresse 12h |
ADD VAL |
Instruction +5 | ||||||||||||||||||||||||||||||||||||||||||||||||||
|
EXECUTE |
Instruction N-3 |
Instruction N-2 |
Instruction N-1 |
LAR AR2, #12 |
ADD (12h) |
ADD VAL |
|
|||||||||||||||||||||||||||||||||||||||||||||||||
A chaque fois que le processeur lit une instruction LAR suivit d’une instruction faisant appel à l’adressage indirect, il ajoute automatiquement 2 cycles de latence. En effet, la valeur de AR2 n’est connue que lors de l’exécution de LAR , alors que le processeur fait appel à cette valeur au moment du DECODE de ADD *.
Il intervient lorsque l’on veut sauver un registre auxiliaire en mémoire et qu’on utilise ce registre en adressage indirect dans l’instruction suivante ; il y a alors perte d’un cycle.
Exemple :
SAR AR2, VAL ; écriture de AR2 en mémoire, AR2 = 12h
![]() ADD *+ ;
La modification du registre auxiliaire ne peut se faire qu’après la lecture de
ADD *+ ;
La modification du registre auxiliaire ne peut se faire qu’après la lecture de
Attente d’un cycle du processeur jusqu'à la lecture de AR2 par SAR
;celui-ci
par l’instruction SAR (cycle READ)
|
FETCH |
SAR |
ADD *+ |
Instruction N+3 |
Instruction N+4 |
Instruction N+5 |
Instruction N+6 | ||||||||||||||||||||||||||||||||||||||||||||
|
DECODE |
Instruction N-1 |
SAR |
AR2 = AR2 + 1* |
Instruction N+3 |
Instruction N+4 |
Instruction +5 | ||||||||||||||||||||||||||||||||||||||||||||
|
OPERAND |
Instruction N-2 |
Instruction N-1 |
lecture AR2 |
lecture adr 12h |
Instruction N+3 |
Instruction N+4 | ||||||||||||||||||||||||||||||||||||||||||||
|
EXECUTE |
Instruction N-3 |
Instruction N-2 |
Instruction N-1 |
SAR |
ADD (12h) |
Instruction N+3 |
|
|||||||||||||||||||||||||||||||||||||||||||
Les changements sur les registres auxiliaires se font lors du DECODE. Donc le processeur attend un cycle pour que le changement de AR2 ne s’opère qu’après lecture de celui-ci (cycle OPERAND) par SAR.
Celui-ci peut être assez fréquent car le processeur multiplexe les bus en sortie si le programme et les données sont situés en mémoire externe. L’accès lors du cycle de recherche d’instruction ne peut se faire au même cycle qu’une écriture ou une lecture de valeur en mémoire données (READ ou EXECUTE). Le processeur perd alors un cycle à chaque instruction. La solution consiste à ranger en mémoire interne ou bien de partitionner le programme à l’extérieur, par exemple, et les données à l’intérieur, ou inversement.
Comme nous l’avons vu au chapitre 8.1.2. , il y a un conflit de type Decode/Execute lors de l’accès aux registres auxiliaires ; l’écriture du registre auxiliaire n’étant effective qu’au cycle Execute, ce qui est détecté par le processeur lors de l’utilisation de l’instruction LAR, instruction dédiée aux registres auxiliaires.
Par contre, l’utilisateur peut aussi changer la valeur des registres auxiliaires lors d’un accès en mémoire page 0. Dans ce cas le processeur ne détectera pas le conflit de pipeline et donc n’ajoutera pas les 2 cycles de latence nécessaire.
Exemple : A ne pas faire !
LAR AR2, #067h ; AR2 = 67h
LACC #064h ; ACC = 00000064h
SAMM AR2 ; sauvegarde de ACC dans AR2 effective au cycle EXECUTE
LACC *- ; AR2 = 66h
ADD *- ; AR2 = 65h
ADD * ; AR2 = 64h. c’est seulement pour cette instruction que l’instruction SAMM
; met à jour AR2
![]()
|
FETCH |
SAMM AR2 |
LACC *- |
ADD *- |
ADD * |
Instruction N+4 |
Instruction N+5 |
Instruction N+6 | |||||||||||||||||||||||||||||||||||||||||||
|
|
Instruction N-1 |
SAMM AR2 |
AR2 = 67 - 1 |
AR2 = 66 - 1 |
AR2 = 64 |
Instruction N+4 |
Instruction +5 | |||||||||||||||||||||||||||||||||||||||||||
|
OPERAND |
Instruction N-2 |
Instruction N-1 |
SAMM AR2 |
lecture (67h) |
lecture (66h) |
lecture (64h) |
Instruction N+4 | |||||||||||||||||||||||||||||||||||||||||||
|
EXECUTE |
Instruction N-3 |
Instruction N-2 |
Instruction N-1 |
AR2 |
ACC (67h) |
ACC += (66h) |
ACC += (64h) |
|
||||||||||||||||||||||||||||||||||||||||||
Exemple : correct !
LAR AR2, #067h ; AR2 = 67h
LACC #064h ; ACC = 00000064h
SAMM AR2 ; sauvegarde de ACC dans AR2 effective au cycle EXECUTE
NOP ; attente de
NOP ; 2 cycles pour la prise en compte de l’instruction SAMM
LACC *- ; AR2 = 63h
ADD *- ; AR2 = 62h
ADD * ; AR2 = 64h. c’est seulement pour cette instruction que l’instruction SAMM
Conclusion :
Pour toute écriture de registres mappés en mémoire, il faut attendre deux cycles avant leur utilisation. Les accès directs (par exemple : LAR, LT ou SAR) ne posent pas de problèmes car dans ce cas c’est le processeur qui gère l’attente.
Lors de la définition de la configuration mémoire (par exemple CLRC CNF), il faut deux temps de latence pour que la modification mémoire prenne effet.
L’exemple donné pour les registres auxiliaires peut se généraliser pour les registres de la figure 33. Ainsi avant l’utilisation de tous les registres de la figure 33, il faudra insérer des temps d’attente entre l’écriture du registre et son utilisation (si celle-ci suit l’écriture).
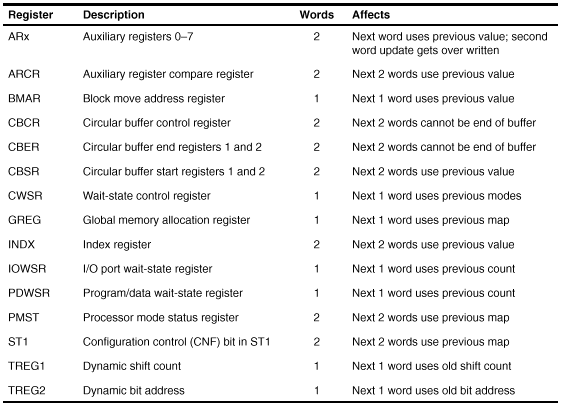
Fig. 33 : Temps de latence entre l’écriture du registre et sa prise en compte effective.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 654
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2024 . All rights reserved