| CATEGORII DOCUMENTE |
Vom trece acum sa studiem cele mai importante structuri neliniare care apar in algoritmii pentru calculatoare: arborii. In general vorbind, structura arborescenta implica o relatie de ramificare intre noduri, foarte asemanatoare celei intalnite la crengile unui arbore din natura.
Una dintre definitiile cele mai raspandite ale arborilor (nu neaparat binari) este urmatoarea (dupa D.E. Knuth):
Definitie: Un arbore este o multime finita T de unul sau mai multe noduri, care are proprietatile:
i) exista un nod special, numit radacina arborelui, notat cu Rad(T)
ii)
toate celelalte noduri din T sunt repartizate in ![]() multimi disjuncte T1, .,Tm, fiecare multime la randul sau
fiind un arbore. Arborii T1, .,Tm se numesc subarborii
radacinii.
multimi disjuncte T1, .,Tm, fiecare multime la randul sau
fiind un arbore. Arborii T1, .,Tm se numesc subarborii
radacinii.
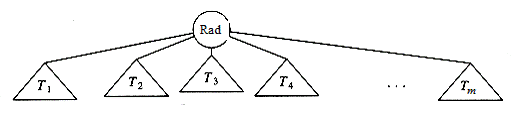
Figura 3.1‑ Arbore generic
Se observa ca definitia de mai sus este recursiva: am definit un arbore pe baza unor arbori. Totusi, privind cu atentie definitia ne dam seama ca nu se pune problema circularitatii, deoarece un arbore cu un singur nod este alcatuit doar din radacina, iar arborii cu n>1 noduri sunt definiti pe baza arborilor cu mai putin de n noduri. Exista si definitii nerecursive al arborilor[1], dar definitia recursiva este mai adecvata, deoarece recursivitatea pare sa fie o trasatura inerenta structurilor arborescente. Caracterul recursiv al arborilor este de altfel prezent si in natura, deoarece mugurii arborilor tineri cresc si se dezvolta in subarbori care la randul lor fac muguri si asa mai departe.
Nodul radacina al fiecarui subarbore se numeste fiul (sau copilul) radacinii, iar radacina este tatal (sau parintele) fiecarui nod radacina din subarbori.
Din definitia recursiva reiese ca un arbore binar este o colectie de n noduri, dintre care unul este radacina, si n-1 muchii. Faptul exista n-1 muchii se deduce din observatia simpla ca fiecare muchie leaga un nod de parintele sau si fiecare nod, in afara de radacina, are exact un parinte.
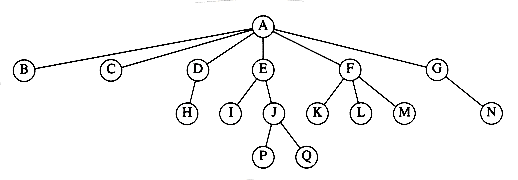
Figura 3.1‑ Un arbore oarecare
In arborele din Figura 3.1‑2, radacina este A. Nodul F il are ca parinte pe A, si are fii K,L si M. Nodurile care nu au fii se numesc frunze. Frunzele din arborele de mai sus sunt B,C,H,I,P,Q,K,L si M. Nodurile cu acelasi parinte se numesc frati. In mod asemanator se definesc relatiile nepot, bunic etc.
Un drum de la un nod n1 la un nod nk
este o secventa de noduri n1,
n2, ., nk astfel incat ni este tatal lui ni+1 pentru ![]() . Lungimea unui drum este numarul de muchii ale drumului,
adica k-1.
. Lungimea unui drum este numarul de muchii ale drumului,
adica k-1.
Pentru oricare nod ni, nivelul (adancimea) nodului este lungimea unicului drum de la radacina la ni. Astfel, nivelul radacinii este 0. In arborele din Figura 3.1‑2, nivelul nodului E este 1, iar al nodului Q este 3. Adancimea unui arbore este definita ca fiind maximul adancimilor nodurilor. In exemplul nostru, adancimea arborelui este egala cu adancimea nodului P (sau Q) care este 3.
Definitie: Un arbore binar este un arbore in care orice nod are cel mult doi fii.
Figura 3.2‑1 arata ca un arbore binar consta intr-o radacina si doi subarbori Ts si Td, oricare din ei putand sa fie vid (sa lipseasca).
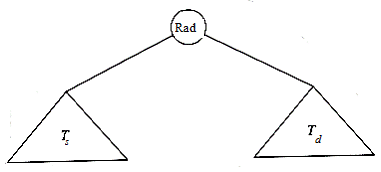
Figura 3.2‑ Arbore binar generic
O proprietate a arborilor binari
care este adeseori deosebit de importanta este ca adancimea medie a
unui arbore binar cu n noduri este
considerabil mai mica decat n.
Se poate arata ca adancimea medie a unui arbore binar este
proportionala cu ![]() , iar adancimea medie a unui caz particular de arbore binar, arborele binar de cautare, este
proportionala cu
, iar adancimea medie a unui caz particular de arbore binar, arborele binar de cautare, este
proportionala cu ![]() . Din pacate, in cazurile degenerate, adancimea unui
arbore poate fi chiar n-1, dupa
cum se vede si in Figura
3.2‑2(a):
. Din pacate, in cazurile degenerate, adancimea unui
arbore poate fi chiar n-1, dupa
cum se vede si in Figura
3.2‑2(a):
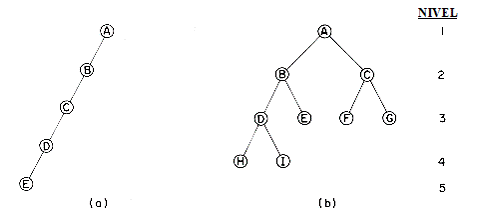
Figura 3.2‑ Exemple de arbori binari:
(a) arbore binar degenerat
(b) arbore binar echilibrat
Inaltimea unui arbore binar este
foarte importanta, deoarece multe operatii definite asupra arborilor
(stergere de nod, inserare de nod etc.) sunt proportionale cu
inaltimea arborelui. Din acest motiv, s-a recurs la diferite metode
pentru a mentine adancimea unui arbore proportionala cu ![]() (arbori AVL, arbori Red-Black etc).
(arbori AVL, arbori Red-Black etc).
Conform cu Figura 3.2‑1, putem defini un arbore binar ca fiind o multime finita de noduri care este fie vida, fie este formata dintr-o radacina si doi arbori binari. Aceasta definitie sugereaza o metoda naturala de reprezentare in calculator a arborilor binari: fiecare nod va fi o structura formata din trei elemente: INFO - informatia utila a nodului, FS - adresa fiului din stanga si FD - adresa fiului din dreapta. Daca un nod nu are fiu in stanga atunci FS este NIL, analog, daca nu are fiu in dreapta, atunci FD este NIL.
Acest lucru poate fi realizat in Pascal definind un tip record PNod astfel:
type PNod = ^Nod ;
Nod = record
INFO : tip ;
FS, FD : PNod ;
end;
sau in C++:
typedef struct Nod ;
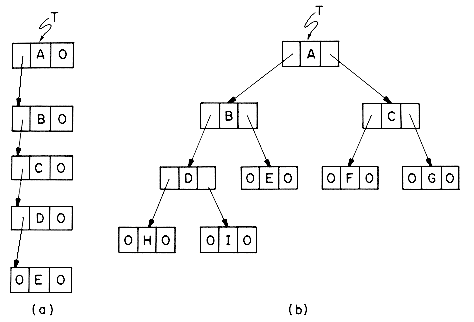
Figura 3.2‑ Reprezentarea inlantuita a arborilor din Figura 3.2‑2
Variabila T din figura de mai sus este o variabila pointer care indica radacina arborelui.
Exista mai multi algoritmi pentru manevrarea structurilor arborescente, si o idee care apare de foarte multe ori este notiunea de parcurgere, de 'deplasare' prin arbore. Parcurgerea unui arbore este de fapt o metoda de examinare sistematica a nodurilor arborelui in asa fel incat fiecare nod sa fie vizitat o singura data. Parcurgerea completa a unui arbore[2] ne ofera o aranjare lineara a nodurilor, si operarea multor algoritmi este simplificata daca stim care este urmatorul nod la care ne vom deplasa intr-o astfel de secventa, pornind de la un nod dat.
Exista trei moduri principale in care un arbore binar poate fi parcurs: nodurile se pot vizita in preordine (RSD), inordine (SRD) si in postordine. Aceste trei metode sunt descrise recursiv, ca si definitia arborelui.
Daca un arbore binar este vid (nu are nici un nod) parcurgerea lui nu presupune nici o operatie; in caz contrar parcurgerea comporta trei etape:
|
Parcurgerea in preordine |
Parcurgerea in inordine |
Parcurgerea in postordine |
|
Se viziteaza radacina |
Se parcurge subarborele stang |
Se parcurge subarborele stang |
|
Se parcurge subarborele stang |
Se viziteaza radacina |
Se parcurge subarborele drept |
|
Se parcurge subarborele drept |
Se parcurge subarborele drept |
Se viziteaza radacina |
Pentru arborele din Figura 3.2‑2 (b) gasim ca nodurile in preordine sunt:
A B D H I E C F G
deoarece mai intai se viziteaza radacina A, apoi subarborele stang (B D H I E) si apoi subarborele drept (C F G).
Similar, parcurgerea in inordine are ca rezultat sirul:
H D I B E A F C G
iar parcurgerea in postordine:
H I D E B F G C A
Numele de preordine, inordine si postordine deriva, bineinteles de la pozitia relativa a radacinii fata de subarbori. Rutinele care realizeaza cele trei parcurgeri sunt descrise mai jos. Fiecare rutina are ca parametru o referinta catre radacina subarborelui care este vizitat. Evident ca la primul apel, parametrul este chiar radacina arborelui care este vizitat.
PREORDINE(P)
daca P <> NIL atunci //daca nu am ajuns la o frunza
VIZITEAZA(P) //se viziteaza radacina subarborelui
INORDINE(P.FS) //se viziteaza subarborele stang
INORDINE(P.FD) //se viziteaza subarborele drept
sf_daca
END (PREORDINE)
Celelalte doua parcurgeri se realizeaza absolut analog:
|
INORDINE(P) daca P <> NIL atunci INORDINE(P.FS) VIZITEAZA(P) INORDINE(P.FD) sf_daca END (INORDINE) |
POSTORDINE(P) daca P <> NIL atunci INORDINE(P.FS) INORDINE(P.FD) VIZITEAZA(P) sf_daca END (POSTORDINE) |
Una dintre cele mai importante aplicatii ale arborilor este utilizarea acestora in probleme de cautare. Pentru simplitate, noi vom presupune ca fiecare nod contine o inoformatie-cheie stocata in campul pe care l-am numit generic INFO. In cazul general campul INFO contine pe langa cheia de cautare si alte informatii pe care noi aici le ignoram deliberat. De exemplu, daca nodurile arborelui contin datele personale ale elevilor unei scoli, el ar avea structura: Numar_Matricol, Nume, Prenume, Adresa etc. Totusi, asa cum vom vedea, pentru operatiile care se realizeaza asupra arborelui putem face abstractie de toate informatiile in afara de numarul matricol al elevului. Numarul matricol este o cheie de cautare deoarece el identifica in mod unic un elev.
Proprietatea care face ca un arbore binar sa devina un arbore binar de cautare este: pentru oricare nod X, al arborelui toate nodurile din subarborele stang au chei mai mici decat cheia lui X, si toate nodurile din subarborele drept au chei mai mari decat cheia lui X.
De exemplu, arborii din Figura 3.2‑ nu sunt arbori binari de cautare, deoarece, in ambele cazuri, in stanga nodului A se afla nodul B, care are valoare mai mare decat A (daca consideram ordinea alfabetica).
Sa studiem cu atentie arborii din Figura 3.3‑ . La prima vedere, ambii par sa fie arbori binari de cautare; examinand totusi mai minutios arborele din dreapta, constatam ca nodul 7, desi este mai mare decat radacina, 6, se afla in stanga ei, ceea ce contravine regulii arborilor de cautare.
Sa vedem acum care sunt principalele operatii care se realizeaza asupra arborilor binari de cautare:
Cautarea unui nod in arbore
Gasirea minimului si maximului
Inserarea unui nou nod
Stergerea unui nou nod
Vidarea arborelui (stergerea tuturor nodurilor)
Vom detalia in continuare, pe rand, aceste operatii.
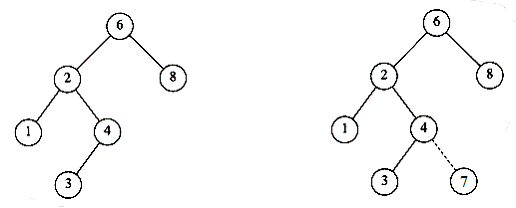
Figura 3.3‑ Doi arbori binari. Numai arborele din stanga este si arbore binar de cautare
Exercitii:
Desenati arborii binari de cautare de inaltime 2,3,4,5 si 6 pentru multimea de chei:
Scrieti ordinea nodurilor rezultata pentru parcurgerea in preordine, inordine si postordine a arborilor de cautare de la exercitiul 1
Asa cum le spune si numele, arborii binari de cautare au fost conceputi pentru a se putea cauta informatiile rapid si usor. Sa presupunem ca in arborele de cautare din Figura 3.3‑ (cel din stanga), dorim sa gasim nodul care are cheia 4. Pentru aceasta comparam valoarea 4 cu radacina. Deoarece 4<6, nodul cautat se afla in subarborele stang, care are radacina 2. Comparam 4 cu 2. Deoarece 4>2, nodul cautat se afla in subarborele drept. Comparam pe 4 cu cheia fiului din dreapta al lui 2, constatam ca sunt egale si ne oprim. Daca in loc de cheia 4 am fi cautat cheia 5, atunci am fi ajuns in subarborele drept al lui 4, care este vid, deci nodul 5 nu se gaseste in arbore.
Rutina Find(T,x) de mai jos, cauta un nod cu valoarea x, in arborele cu radacina T si returneaza adresa la care nodul se gaseste. Daca nodul nu este gasit, atunci se returneaza NIL:
FIND(T,x)
daca T = NIL atunci
return NIL //nodul x nu se gaseste in arbore
daca T.INFO > x atunci
return Find(T.Fs , x) //se cauta in fiul din stanga al nodului T
daca T.INFO < x atunci
return Find(T.Fd , x) //se cauta in fiul din dreapta al nodului T
altfel // T.INFO = x, nodul a fost gasit
return T //se returneaza adresa nodului cu cheia x
END (FIND)
Gasirea minimului si maximului inseamna a returna adresa nodurilor din arbore care au cheia cea mai mica, respectiv cea mai mare. Sunt convins ca in acest moment unii isi pun intrebarea: 'de ce sa returnam adresa nodului care contine minimul sau maximul, in loc sa returnam chiar valoarea minimului sau a maximului?' Raspunsul este ca returnarea valorii in loc de adresa ar genera o inconsistenta cu procedura Find din paragraful anterior. Intr-un tip abstract de date este important ca operatiile similare sa realizeze lucruri similare. Existenta unui anumit standard al operatiilor usureaza foarte mult munca celor care utilizeaza TAD-ul[3].
Pentru a gasi elementul minim al unui arbore se porneste de la radacina si se merge catre stanga cat timp mai exista un fiu in stanga. Punctul de oprire este cu siguranta cel mai mic element. Pentru a gasi elementul maxim se procedeaza similar, cu deosebirea ca se merge spre dreapta.
Rutina Find_Max(T) de mai jos returneaza adresa nodului cu valoarea maxima a arborelui cu radacina T. Daca arborele este vid, se returneaza NIL:
FIND_MAX(T,x) //recursiv
daca T = NIL atunci //arborele este vid, nu avem maxim
return NIL
daca T.FD = NIL atunci //nu avem fiu in dreapta, deci am gasit maximul
return T
altfel
return Find_Max(T.FD , x) //se merge in fiul din dreapta al nodului T
END (FIND_MAX)
Procedura Find_Max este atat de simpla, incat multi programatori nu se obosesc sa foloseasca recursivitatea. Varianta iterativa a acestei rutine porneste cu o variabila referinta, P, de la radacina, dupa care P este mutata catre dreapta pana cand nodul indicat de ea nu mai are fiu in dreapta:
FIND_MAX(T,x) //iterativ
daca T = NIL atunci //arborele este vid, nu avem maxim
return NIL
P = T // se copiaza adresa radacinii in P
Cat timp P.FD <> NIL
P = P.FD
return P
END (FIND_MAX)
Observati cu cata grija s-a tratat cazul degenerat al unui arbore vid (fara nici un nod). Acest lucru este important de realizat, mai ales in cazul programelor recursive.
Poate va intrebati de ce a fost nevoie in varianta iterativa sa copiem valoarea T a radacinii in variabila auxiliara P. Raspunsul este ca la pagina 1 am realizat conventia ca toti parametri sunt transmisi prin referinta, deci modificarea lui T in Find_Max ar afecta variabila T din programul apelant.
Exercitii.
Sa se scrie variantele recursive si iterative ale procedurii Find_Min care returneaza adresa nodului cu valoare minima din arbore.
De ce in cazul variantei recursive a procedurii Find_Max nu a fost nevoie sa salvam valoarea variabilei T?
R. Deoarece in cazul variantei recursive, variabila T nu a fost modificata! La fiecare apel recursiv se depune pe stiva valoarea parametrului de apel (T.FD)!
Sa presupunem ca avem numerele de la 1 la 1000 intr-un arbore binar de cautare si ca dorim sa cautam numarul 363. Care dintre urmatoarele secvente nu poate constitui o secventa de noduri examinate?
a.
b.
c.
d.
e.
R. c si e
Profesorul Stietot are impresia ca a descoperit o proprietate remarcabila a arborilor de cautare. Sa presupunem ca o cautare pentru cheia k in arbore se termina intr-o frunza. Consideram urmatoarele multimi: A - nodurile din stanga drumului parcurs pana la k, B multimea cheilor aflate chiar pe acest drum si C, multimea cheilor din dreapta drumului. Profesorul Stietot sustine ca toate cheile din A sunt mai mici decat cele din B, care sunt la randul lor mai mici decat cele din C. Dati cel mai mic contraexemplu care sa spulbere afirmatia lui Stietot!
Rutina de inserare este conceptual destul de simpla. Pentru a insera x in arborele cu radacina T, ne 'afundam' in interiorul arborelui exact ca si in cazul rutinei Find. Daca valoarea x este gasita in arbore, atunci nu facem nimic[4]. In caz contrar inseram un nod cu cheia x, in ultimul punct din calea care a fost parcursa. Figura 3.3‑ ne arata ce se petrece. Pentru a insera valoarea 5, traversam arborele ca si cand am realiza procesul de cautare. Cand ajungem la nodul cu cheia 4, trebuie sa mergem catre dreapta, dar nu exista subarbore drept, deci 5 nu este in arbore si acesta este locul in care trebuie inserat.
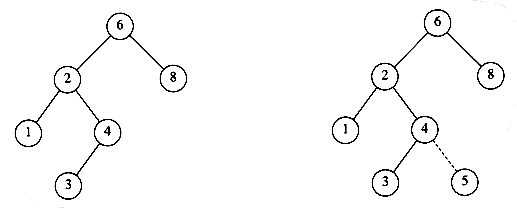
Figura 3.3‑ Arbore binar de cautare inainte si dupa inserarea valorii 5
Rutina Insert(T , x) de mai jos realizeaza inserarea nodului cu cheia x in arborele cu radacina T.
INSERT(T,x)
daca T = NIL atunci //x nu se afla in arbore, aici este locul unde trebuie inserat
T DISPON // se aloca memorie pentru noul nod
T.INFO = x //se completeaza informatia utila a noului nod
T.FS = T.FD = NIL //noul nod nu are fii
altfel daca T.INFO > x atunci
Insert(T.FS , x) //se cauta punctul de inserare in stanga lui T
altfel daca T.INFO < x atunci
Insert(T.FD , x) //se cauta punctul de inserare in dreapta lui T
// altfel T.INFO = x, nodul a fost gasit si nu facem nimic
END (INSERT)
Observati asemanarile evidente intre algoritmul INSERT si algoritmul FIND din paragraful 3.3.1! Totusi, algoritmul INSERT ascunde un aspect de o mare finete: cum se leaga noul nod inserat (5 in exemplul nostru) de tatal sau (4)? In procedura Insert nu apare nicaieri un cod explicit care sa semnaleze ca fiul din dreapta al lui 4 nu mai este NIL, ci este noul nod inserat. Raspunsul este urmatorul: deoarece am convenit ca transmiterea parametrilor de face prin referinta, rezulta ca orice modificare facuta de Insert asupra variabilei T se reflecta si in programul apelant. Sa urmarim procedura Insert pentru exemplul din Figura 3.3‑ : in momentul in care T indica nodul cu cheia 4, avem ca T.INFO<x si deci se va executa linia:
return Find(T.FD , x)
Dar T.FD este NIL, deoarece 4 nu are fiu in dreapta. In consecinta, la apelul recursiv vom avea T = NIL, deci se aloca memorie pentru T si se completeaza informatiile din T. Deoarece T este transmis prin referinta, modificarea lui se va reflecta si in parametrul apelant T.FD. In consecinta, T.FD va indica catre noul nod inserat.
Pentru arborii binari de cautare, ca de altfel si pentru alte structuri de date, cea mai dificila operatie este stergerea. In cazul operatiei de stergere, dupa ce am gasit nodul care trebuie sters trebuie sa consideram mai multe posibilitati.
Daca nodul care trebuie sters este o frunza, el poate fi sters imediat prin inlocuirea legaturii parintelui sau cu NIL.
Daca nodul care trebuie sters are doar un singur fiu (indiferent ca este stang sau drept), stergerea lui se face prin ajustarea legaturii parintelui sau pentru a-l 'ocoli' (vezi . Figura 3.3‑ )
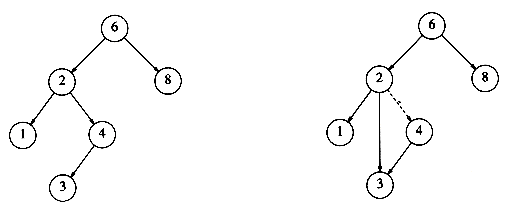
Figura 3.3‑ Stergerea unui nod (4) cu un singur fiu (inainte si dupa). Legatura 2-3 'ocoleste' nodul 4
Cazul complicat apare atunci cand nodul care trebuie sters are doi fii. Strategia generala in acest caz este de a inlocui cheia nodului care trebuie sters cu cea mai mica cheie din subarborele sau drept (care este usor de gasit) dupa care nodul cu aceasta cheie se sterge. Deoarece cel mai mic nod din subarborele drept nu poate sa aiba fiu in stanga, stergerea lui este usoara.
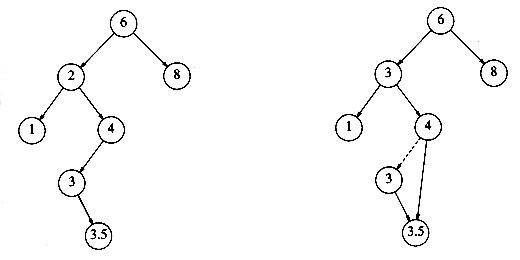
Figura 3.3‑ Stergerea unui nod (2) cu doi fii (inainte si dupa). Cel mai mic nod din subarborele drept al lui 2 este 3. Se inlocuieste 2 cu 3, dupa care 3 se sterge prin 'ocolire'
In Figura 3.3‑ , stergerea nodului 2 presupune urmatorii pasi:
se gaseste cel mai mic nod din subarborele drept, care este 3
se inlocuieste informatia din nodul 2 cu 3
se sterge nodul 3 prin 'ocolire'
O intrebare care poate aparea in acest moment este de ce se alege ca nod de inlocuire cel mai mic nod din subarborele drept? Aceasta alegere este facuta pentru a pastra structura de arbore de cautare. Acest nod este, pe de o parte, mai mare decat toate nodurile din subarborele stang al nodului sters si, pe de alta parte, el este evident mai mic decat nodurile din subarborele drept.
Daca, de exemplu, am alege nodul 4 si am inlocui nodul 2 cu nodul 4, si apoi am sterge fostul nod 4, atunci arborele rezultat nu ar fi arbore de cautare, deoarece in dreapta lui 4 am avea nodurile 3 si 3.5 (Figura 3.3‑ )!
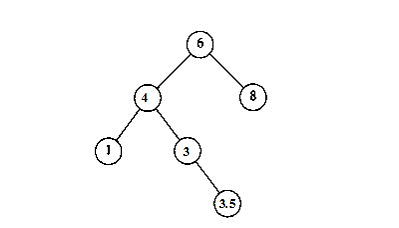
Figura 3.3‑ Arborele rezultat prin inlocuirea nodului 2 cu nodul 4. Acesta nu este un arbore binar de cautare, deoarece in dreapta lui 4 se afla 3.
Algoritmul Delete(T , x) de mai jos, care nu este deloc banal, realizeaza stergerea nodului cu cheia x din arborele de radacina T:
DELETE(T,x)
daca T = NIL atunci //x nu se afla in arbore
scrie 'EROARE: Nodul nu exista in arbore'
daca T.INFO > x atunci
Delete(T.FS , x) //se cauta nodul de sters in subarborele stang al nodului T
altfel daca T.INFO < x atunci
Delete(T.FD , x) //se cauta nodul de sters subarborele drept al nodului T
altfel //am gasit nodul care trebuie sters
daca T.FS <> NIL si T.FD <> NIL //nodul de sters are doi fii
temp = Find_Min(T.FD) //se cauta cel mai mic nod din subarborele drept
T.INFO = temp.INFO //se inlocuieste nodul care trebuie sters
Delete(T.FD , temp.INFO) //se sterge cel mai mic nod din subarb. drept
altfel //nodul are unul sau zero fii
temp = T //se salveaza in temp adresa nodului T
daca T.FS <> NIL atunci // are doar subarbore stang
T = T.FS //se 'ocoleste' nodul T prin stanga
altfel daca T.FD <> NIL atunci //are doar subarbore drept
T = T.FD //se 'ocoleste' nodul T prin dreapta
altfel //nu are deloc fii
T = NIL //nodul T este sters
temp DISPON //se elibereaza memoria nodului sters
END (DELETE)
Liniile 1-7 din algoritmul de mai sus realizeaza cautarea nodului care trebuie sters, de aici si asemanarea cu functia Find din paragraful 3.3.1. Liniile 8-12 trateaza cazul in care nodul care trebuie sters are doi fii. In aceasta situatie se incarca in variabila temp adresa celui mai mic nod din subarborele drept (utilizand procedura Find_Min din paragraful ), se inlocuieste informatia din nodul care trebuie sters si apoi se sterge recursiv (!!!) cel mai mic nod din subarborele drept. Liniile 12-20 trateaza cazul fericit in care nodul care trebuie sters are cel mult un fiu. In liniile 14-15 nodul de sters are fiu stang, deci se poate ocoli prin stanga; similar in liniile 16-17 nodul este ocolit prin dreapta, iar in linia 19, nodul este pur si simplu eliminat, neavand nici un fiu.
De remarcat ca si in cazul acestui algoritm, ca si in cazul lui Insert, reactualizarea legaturilor este asigurata de transmiterea prin referinta a parametrului T.
Sunt constient de faptul ca intelegerea algoritmului de stergere nu este deloc simpla, si, tocmai de aceea, indraznesc sa afirm ca aceia care fac un efort si il inteleg in profunzime pot sa spuna fara falsa modestie ca sunt niste buni programatori!
Sa scriem nodurile rezultate din parcurgerea in inordine a primului arbore din Figura 3.3‑ :
Observam ca nodurile apar in ordine crescatoare! Aceasta observatie este valabila nu numai pentru acest arbore, ci pentru orice alt arbore binar de cautare. Daca gandim parcurgerea in inordine recursiv, nu vom mai fi deloc surprinsi de acest rezultat. Ce inseamna de fapt parcurgere in inordine? Se parcurge mai intai subarborele stang, apoi se parcurge radacina si, in final, se parcurge subarborele drept. Nodurile din subarborele stang sunt mai mici decat radacina si, conform parcurgerii, ele sunt vizitate inaintea radacinii, iar nodurile din subarborele drept, care sunt mai mari, vor fi vizitate dupa radacina.
Bazandu-ne pe aceasta
simpla observatie, putem defini o metoda simpla de sortare,
care (culmea!) este si rapida (![]() ). Totusi, trebuie sa recunoastem ca
aceasta metoda nu este folosita in practica datorita
informatiei suplimentare care trebuie retinuta pentru a memora
legaturile catre fiii unui nod. Metoda de sortare utilizand arbori
binari de cautare are urmatorii pasi:
). Totusi, trebuie sa recunoastem ca
aceasta metoda nu este folosita in practica datorita
informatiei suplimentare care trebuie retinuta pentru a memora
legaturile catre fiii unui nod. Metoda de sortare utilizand arbori
binari de cautare are urmatorii pasi:
se citesc elementele care trebuie sortate si se introduc rand pe rand intr-un arbore binar de cautare utilizand algoritmul de inserare din paragraful
se parcurg nodurile arborelui binar de cautare in inordine, utilizand procedura INORDINE din 3.2.1. Nodurile vor fi parcurse in ordine crescatoare
BIN_SORT
T = NIL //la inceput arborele este vid
Citeste n //numarul de elemente care se sorteaza
Pentru i = 1, n
Citeste x //se citeste un nou element
Insert(T,x) //se insereaza noul element in arbore
Sf_pentru
INORDINE(T) //se parcurge arborele in inordine
END (BIN_SORT)
Observatie: in cazul in care dorim sa obtinem nodurile arborelui in ordine descrescatoare, vom modifica procedura de parcurgere in inordine astfel incat mai intai se parcurge subarborele drept apoi radacina si in final subarborele stang.
Sa analizam acum pe scurt care este timpul de executie al operatiilor pe care le-am definit asupra arborilor binari de cautare (cautare, gasire de minim, inserare si stergere). Toate aceste operatii se 'adancesc' in arbore plecand de la radacina si mergand pe o directie bine definita. In consecinta numarul maxim de noduri parcurse este egal cu adancimea, h, a arborelui. Deoarece parcurgerea unui nod se realizeaza in timp constant, O(1), rezulta ca aceste operatii au in ansamblu o complexitate de O(h).
Problema este cum se exprima h, inaltimea arborelui, in
functie de numarul n de noduri. Se poate demonstra ca
in cazul in care cheile arborelui respecta o distributie
uniforma, adancimea arborelui este in ![]() . Deci complexitatea medie a operatiilor realizate pe
arbori binari de cautare este
. Deci complexitatea medie a operatiilor realizate pe
arbori binari de cautare este ![]() .
.
Am vazut la inceputul paragrafului 3.2 ca in cazul arborilor binari degenerati, adancimea poate sa fie chiar n. In aceasta situatie, complexitatea tuturor operatiilor devine O(n). Incercati sa inserati intr-un arbore vid cheile 5,4,3,2,1. Veti obtine un arbore de genul celui din Figura 3.3‑ . Un arbore simetric se obtine in situatia in care nodurile sunt date in ordine crescatoare.
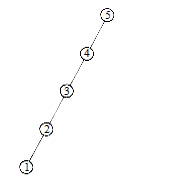
Figura 3.3‑ Arbore binar de cautare degenerat, obtinut prin inserarea de chei descrescatoare
In capitolele urmatoare vom vedea cateva
'trucuri' la care se recurge pentru a pastra adancimea unui arbore binar
de cautare in ![]() , chiar si in cazul cel mai nefavorabil.
, chiar si in cazul cel mai nefavorabil.
De exemplu, in teoria grafurilor, un arbore este definit ca un graf conex si fara cicluri sau ca un graf conex minimal sau ca un graf fara cicluri maximal
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 5535
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved