| CATEGORII DOCUMENTE |
Interogari la nivel de grup (de agregare / sintetizatoare)
Multe dintre cererile de informatii nu necesita nivelul de detaliere furnizat de interogarile SQL prezentate pana acum. De exemplu, urmatoarele cerinte presupun determinarea unei singure valori sau a unui numar mic de valori care sintetizeaza continutul bazei de date.
Care este totalul cotelor tuturor agentilor de vanzari?
Care este cea mai mica, respectiv cea mai mare cota ?
Cati agenti de vanzari si-au depasit cota ?
Care este media valorii comenzilor ?
Care este media valorii comenzilor pentru fiecare birou de vanzari in parte?
Cati agenti de vanzari lucreaza la fiecare birou de vanzari in parte ?
SQL poate raspunde la aceste cereri prin utilizarea unor functii de grup si prin utilizarea clauzelor GROUP BY si HAVING in instructiunea SELECT.
Functii de grup
SQL ne permite sa sintetizam datele din baza de date prin utilizarea unor functii de grup asupra coloanelor. O functie de grup primeste ca argument o intreaga coloana si furnizeaza ca rezultat o singura valoare, care sintetizeaza datele din coloana respectiva. De exemplu, functia AVG( ) primeste ca parametru datele dintr-o coloana si returneaza media lor aritmetica.
Care este cota medie de vanzari si media vanzarilor pentru agentii de vanzari ?
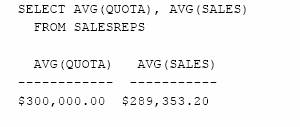
Figura 5.17 ne arata grafic cum sunt obtinute rezultatele interogarii. Prima functie de grup primeste ca parametru valorile din coloana QUOTA si calculeaza media lor aritmetica ; cea de-a doua functie calculeaza media aritmetica a valorilor din coloana SALES. Interogarea produce o singura linie in rezultatul interogarii, linie care sintetizeaza datele din tabela SALESREPS.
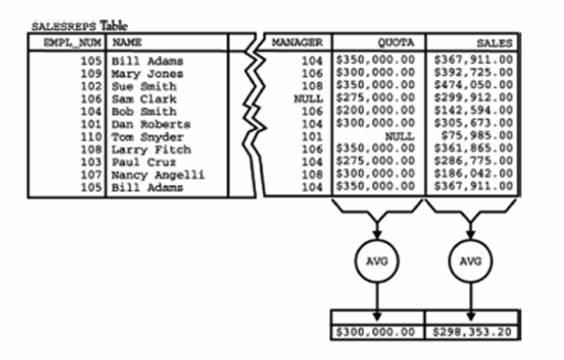
Figura 5.17 Interogare sintetizatoare
SQL ofera sase functii de grup:
SUM() calculeaza totalul valorilor dintr-o coloana.
AVG() calculeaza media aritmetica a valorilor dintr-o coloana.
MIN() determina cea mai mica dintre valorile unei coloane.
MAX() determina cea mai mica dintre valorile unei coloane.
COUNT() determina numarul valorilor dintr-o coloana.
COUNT(*) determina numarul liniilor din rezultatul interogarii.
Argumentul unei functii de grup poate fi numele unei coloane, ca in exemplul precedent, sau o expresie SQL.
Care este procentul mediu de vanzari al agentilor?

Pentru a procesa aceasta interogare, SQL construieste o coloana temporara care contine valoarea expresiei (100 * (SALES/QUOTA)) pentru fiecare linie din tabela SALESREPS si apoi calculeaza media aritmetica a valorilor acestei coloane.
Determinarea totalului unei coloane (SUM)
Functia de grup SUM( ) determina suma valorilor dintr-o coloana. Datele din coloana respectiva trebuie sa fie de tip numeric (intreg, real zecimal, real in virgula mobila sau money). Rezultatul functiei SUM( ) este de acelasi tip cu datele din coloana respectiva dar rezultatul poate avea precizie mai mare.
In continuare sunt prezentate cateva exemple care utilizeaza functia SUM( ).
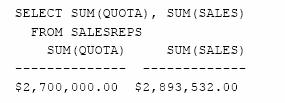
Care este totalul cotelor si al vanzarilor tuturor agentilor de vanzari?
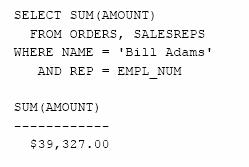
Care este totalul comenzilor primite de Bill Adams?
Determinarea mediei aritmetice (AVG)
Functia de grup AVG( ) determina media aritmetica a valorilor dintr-o coloana. Ca si in cazul functiei SUM( ), datele din coloana respectiva trebuie sa fie de tip numeric. Tipul de data al rezultatului poate sa difere de cel al valorilor din coloana respectiva. De exemplu, daca aplicam functia AVG( ) unei coloane de tip intreg, rezultatul poate fi de tip real zecimal sau real in virgula mobila, in functie de SGBD-ul pe care lucram.
In continuare sunt prezentate cateva exemple care utilizeaza functia AVG( ).
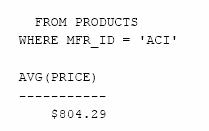
Sa se determine pretul mediu al produselor realizate de ACI.
![]()
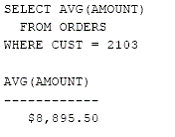
Sa se determine valoarea medie a comenzilor facute de ACME Mfg. (clientul cu numarul 2103)
Determinarea valorilor minime si maxime (MIN si MAX)
Functiile de grup MIN() si MAX() determina cea mai mica, respectiv cea mai mare, dintre valorile unei coloane. Datele din coloana respectiva pot fi de tip numeric, sir de caractere sau date/time. Rezultatul va avea exact acelasi tip de data cu al valorilor din coloana respectiva.
Mai jos sunt prezentate cateva exemple care utilizeaza aceste functii de grup.
Care sunt cea mai mica si cea mai mare dintre cotele agentilor de vanzari?
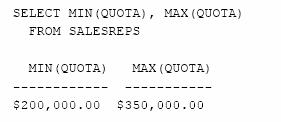
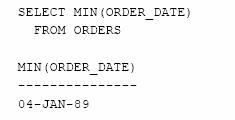
Care este cea mai veche comanda existenta in baza de date?
Care este cel mai bun procent de vanzari al unui agent?

Cand sunt utilizate functiile de grup MIN( ) si MAX( ), numerele sunt comparate in ordine algebrica, sirurile de caractere in ordine lexicografica, datele calendaristice in ordine cronologica iar duratele de timp pe baza lungimii acestora.
Numararea valorilor (COUNT)
Functia de grup COUNT( ) numara valorile dintr-o coloana. Datele din coloana respectiva pot avea orice tip de data. Functia COUNT( ) returneaza un intreg.
Mai jos sunt prezentate cateva exemple de interogari in care este utilizata aceasta functie.
Sa se determine numarul clientilor.
![]()

Care este numarul agentilor de vanzari care si-au depasit cota ?

Cate comenzi au valoarea mai mare de $25.000 ?
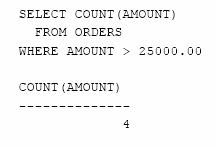
Functia COUNT( ) ignora valorile datelor din coloana transmisa ca parametru; ea pur si simplu numara valorile din aceasta coloana. Ca urmare, nu conteaza ce coloana ii specificam ca argument. Exemplul precedent poate fi scris asadar si in modul urmator:
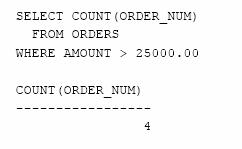
De fapt nu este eficient sa gandim interogarea sub forma 'numara cate valori de comezi ' sau 'numara cate numere de comezi ' ; este mai simplu sa gandim 'numara cate comenzi '. Din acest motiv SQL suporta o functie de grup speciala , COUNT( * ), care numara liniile si nu valorile datelor. In continuare este reformulata interogarea anterioara utilizand functia COUNT (*) .
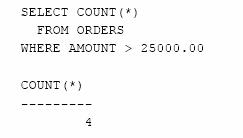
Daca ne gandim la functia COUNT( * ) ca avand semnificatia "numara liniile", interogarea devine mai usor de citit. In practica functia COUNT( * ) este aproape intotdeauna utilizata in locul functiei COUNT( ) pentru a numara linii.
Valorile nule si functiile de grup
Functiile de grup, SUM(), AVG(), MIN(), MAX(), si COUNT() primesc ca argument valorile unei coloane si furnizeaza ca rezultat o singura valoare. Ce se intampla daca una sau mai multe dintre valorile coloanei respective sunt NULL? Standardul ANSI/ISO SQL precizeaza ca valorile NULL sunt ignorate de functiile de grup.
Urmatoarea interogare ne arata cum functia COUNT() ignora valorile NULL dintr-o coloana.
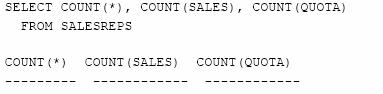
![]()
Tabela SALESREPS contine zece linii, asadar COUNT( * ) returneaza zece. Coloana SALES contine zece valori NOT NULL, asadar COUNT(SALES) returneaza, de asemenea, valoarea zece. Coloana QUOTA are valoarea NULL pentru cel mai nou agent de vanzari; functia COUNT(QUOTA) ignora aceasta valoare NULL si returneaza valoarea noua. Din cauza acestei anomalii, functia count( * ) este aproape intotdeauna utilizata in locul functiei count( ), cu exceptia situatiilor in care dorim sa specificam, pentru o anumita coloana, excluderea valorilor NULL din numarul total al valorilor.
Ignorarea valorilor NULL are un impact mai mic in cazul functiilor MIN( ) si MAX( ) totusi poate cauza unele probleme in cazul functiilor SUM( ) si AVG( ). Sa consideram urmatorul exemplu:

Ne-am astepta ca cele doua expresii - (SUM(SALES) - SUM(QUOTA)) si SUM(SALES-QUOTA) - din lista de selectie sa produca acelasi rezultat dar exemplul ne arata ca nu este asa. Motivul este faptul ca in coloana QUOTA exista o valoare NULL. Expresia SUM(SALES) insumeaza totalul vanzarilor pentru toti cei zece agenti de vanzari in timp ce expresia SUM(QUOTA) insumeaza numai noua valori ale cotelor. Expresia SUM(SALES) - SUM(QUOTA) calculeaza diferenta dintre cele doua totaluri. Totusi, functia de grup SUM(SALES-QUOTA) are argumente valori nenule doar pentru noua din cei zece agenti; in linia cu o valoare NULL pentru cota, diferenta furnizeaza valoarea NULL, care este ignorata de functia SUM( ). Astfel, vanzarile pentru agentul fara cota, care sunt incluse in calculul anterior, sunt excluse din acest calcul. Asadar, cand apar valori NULL, cele doua expresii nu calculeaza exact acelasi lucru.
Standardul ANSI/ISO specifica reguli precise pentru tratarea valorilor nule in cazul functiilor de grup:
Daca o valoare dintr-o coloana este NULL, aceasta este ignorata de functiile de grup.
Daca o coloana nu contine date (asadar coloana este goala) atunci functiile de grup SUM( ), AVG( ), MIN( ) si MAX( ) returneaza valoarea NULL; functia COUNT( ) returneaza valoarea zero.
Functia COUNT( * ) numara liniile si nu depinde de prezenta sau absenta valorilor NULL intr-o coloana. Daca nu exista linii, returneaza valoarea zero.
Eliminarea liniilor duplicat (DISTINCT)
Reamintim faptul ca putem adauga cuvantul cheie DISTINCT la inceputul listei de selectie pentru a elimina liniile duplicat din rezultatul interogarii. Putem, de asemenea, sa eliminam valorile duplicat dintr-o coloana inainte de a aplica functii de grup asupra acesteia. Pentru a elimina valorile duplicat includem cuvantul cheie DISTINCT inainte de argumentul functiei de grup, imediat dupa paranteza deschisa.
In continuare sunt prezentate doua exemple care ilustreaza cum sunt eliminate valorile duplicat in cazul functiilor de grup.
Cate titluri distincte sunt detinute de agentii de vanzari?
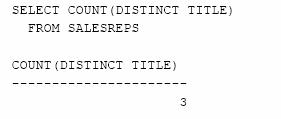
Cate birouri de vanzari au agenti care si-au depasit cota?
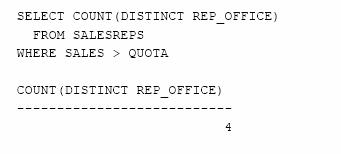
Gruparea inregistrarilor (Clauza GROUP BY )
Interogarile totalizatoare prezentate pana acum seamana cu totalurile de la sfarsitul unui raport. Ele condenseaza toate datele detaliate din raport intr-o singura linie. Uneori insa, in rapoartele tiparite avem nevoie si de "subtotaluri". Clauza GROUP BY ne ofera posibilitatea de a realiza acest lucru.
Rolul clauzei GROUP BY este cel mai usor de inteles prin exemple. Sa consideram urmatoarele doua interogari:
Care este media valorilor comenzilor?
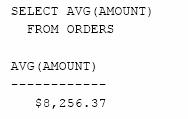
Care este media valorilor comenzilor realizate de fiecare agent de vanzari?
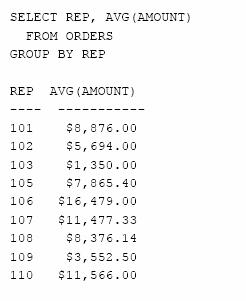
Prima interogare este o simpla interogare totalizatoare, ca in exemplele anterioare. Cea de-a doua, produce cateva linii totalizatoare - cate una pentru fiecare grup, insumand valorile comenzilor primite de un agent de vanzare.
Figura 5.18 ne arata cum lucreaza cea de-a doua interogare.
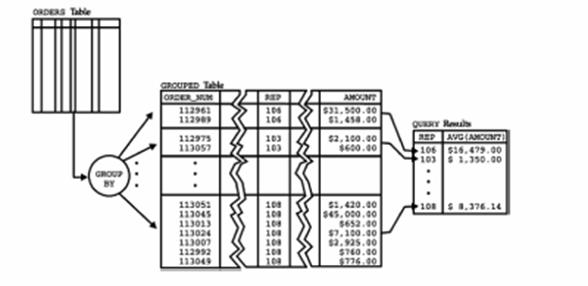
Figura 5.18 Gruparea inregistrarilor
Conceptual, SQL proceseaza interogarea astfel:
1. SQL imparte comenzile in grupuri de comenzi, cate un grup pentru fiecare agent de vanzari. In interiorul unui grup, toate comenzile au aceeasi valoare a coloanei REP.
2. Pentru fiecare grup, SQL calculeaza media valorilor coloanei AMOUNT si genereaza o singura linie in rezultatul interogarii ; linia contine valoarea coloanei REP pentru grupul respectiv si media aritmetica a valorilor comenzilor
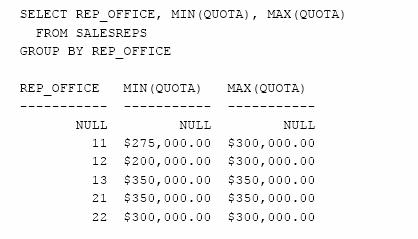
Care este intervalul in care sunt cuprinse cotele asignate pentru fiecare birou de vanzari?
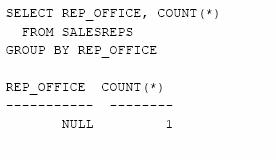
Cati agenti de vanzari lucreaza la fiecare birou in parte?
Cati clienti diferiti sunt serviti de fiecare agent de vanzari in parte?

Exista o legatura stransa intre functiile de grup si clauza GROUP BY. Reamintim ca o functie de grup primeste ca argument valorile dintr-o coloana si produce ca rezultat o singura linie. Cand este prezenta clauza GROUP BY, SQL grupeaza inregistrarile si aplica functia de grup fiecaruia dintre grupuri in parte, producand in rezultat cate o singura linie pentru un grup.
Gruparea dupa mai multe coloane
SQL poate grupa rezultatele interogarii pe baza continutului a doua sau mai multe coloane. De exemplu, sa presupunem ca dorim sa grupam comenzile dupa agentii de vanzari si dupa clienti. Urmatoarea interogare grupeaza datele pe baza ambelor criterii:
Sa se calculeze totalul valorii comenzilor pentru fiecare agent de vanzari si pentru fiecare client.
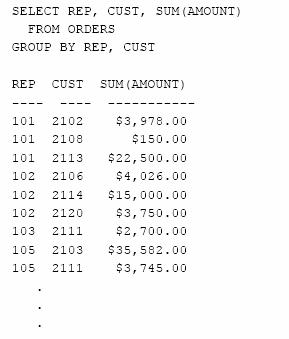
Chiar si in cazul gruparii dupa mai multe coloane, SQL furnizeaza un singur nivel de grupare. Interogarea produce cate o linie separata pentru fiecare pereche agent de vanzari/client. Este imposibil in SQL sa cream grupuri si subgrupuri cu doua nivele de subtotaluri. Tot ce putem face este sa ordonam rezultatele interogarii.
Sa se calculeze totalul comenzilor pentru fiecare client si pentru fiecare agent de vanzari, ordonate dupa client si, pentru fiecare client in parte, ordonate dupa agentii de vanzari.
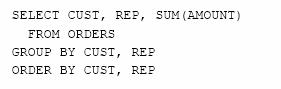
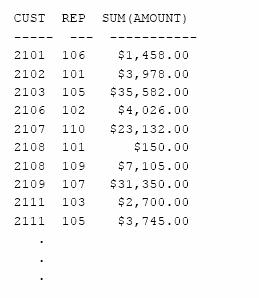
Mentionam, de asemenea, ca este imposibil sa obtinem atat rezultate detaliate cat si rezultate totalizatoare intr-o interogare SQL. Pentru a obtine rezultate detaliate, cu subtotaluri, sau subtotaluri pe mai multe nivele, este nevoie sa utilizam SQL programatic.
Restrictii asupra gruparii inregistrarilor
Gruparea inregistrarilor este supusa anumitor restrictii. Coloanele dupa care se face gruparea trebuie sa fie coloane ale tabelelor specificate in clauza FROM. Nu putem face gruparea pe baza unor valori calculate. Exista, de asemenea, restrictii in ce priveste lista de selectie: toate elementele care apar in lista de selectie trebuie sa aiba aceeasi valoare pentru toate liniile din grup. Aceasta inseamna ca lista de selectie poate contine:
O constanta
O functie de grup
O coloana de grupare, care are prin definitie aceeasi valoare pentru toate liniile din grup
Orice expresie care contine combinatii ale elementelor de mai sus.
In practica, o interogare cu gruparea inregistrarilor va include intotdeauna in lista de selectie atat o coloana de grupare cat si o functie de grup. Daca in lista de selectie nu apare nici o functie de grup atunci interogarea poate fi exprimata mai simplu utilizand clauza SELECT DISTINCT, fara GROUP BY. Reciproc, daca nu includem in lista de selectie o coloana de grupare, nu vom putea preciza carui grup ii corespunde o anumita linie din rezultatul interogarii.
O alta limitare consta in faptul ca SQL ignora informatiile referitoare la cheile primare si la cele straine cand analizeaza corectitudinea gruparii inregistrarilor.
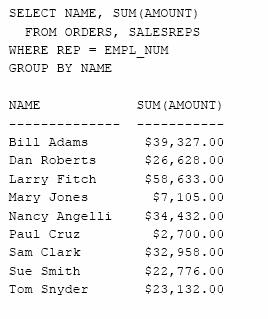
Sa se calculeze totalul comenzilor pentru fiecare agent de vanzari.
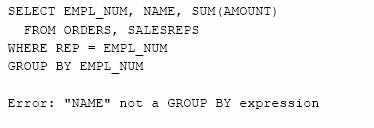
Avand in vedere natura datelor, interogarea pare corecta deoarece gruparea dupa numarul agentului de vanzari este de fapt aceeasi cu gruparea dupa numarul si apoi dupa numele acestuia. Mai exact, EMPL_NUM este cheie primara in tabela SALESREPS asadar coloana NAME va avea o singura valoare pentru fiecare grup. Cu toate acestea, SQL semnaleaza o eroare deoarece coloana NAME nu este specificata explicit in coloanele de grupare. Pentru a elimina eroarea trebuie sa includem coloana NAME ca pe a doua coloana de grupare.
Sa se calculeze totalul comenzilor pentru fiecare agent de vanzari.
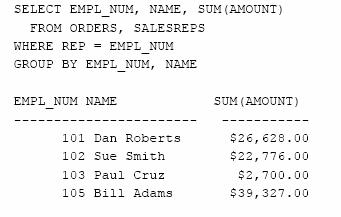
Bineinteles, daca numarul agentului de vanzari nu este necesar in rezultatul interogarii, il putem elimina din lista de selectie.
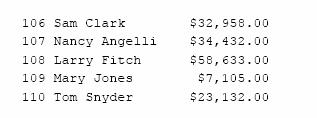
Sa se calculeze totalul comenzilor pentru fiecare agent de vanzari
Valori NULL in coloanele de grupare
Prezenta unor valori null in coloanele dupa care se face gruparea inregistrarilor ridica anumite probleme. Daca valoarea coloanei este necunoscuta, carui grup ii va fi asociata inregistrarea ? In clauza WHERE, cand sunt comparate doua valori NULL distincte, rezultatul este NULL (nu TRUE); asadar, doua valori NULL distincte nu sunt considerate egale. Aplicarea acestei reguli in cazul clauzei GROUP BY, ar face ca fiecare dintre liniile care au valoarea NULL in coloana de grupare sa fie plasate in cate un grup. Aceasta regula se dovedeste a fi prea dificila. Standardul ANSI/ISO SQL precizeaza ca in cazul in care este prezenta clauza GROUP BY, valorile NULL din coloana de grupare sunt considerate egale. Astfel, daca doua linii au valoarea NULL intr-o coloana de grupare si valori nenule identice in celelalte coloane de grupare, ele vor fi grupate impreuna.
Urmatorul exemplu de interogare se refera la tabela din Figura 5.19 si ilustreaza cum trateaza SQL valorile NULL in cazul clauzei GROUP BY.
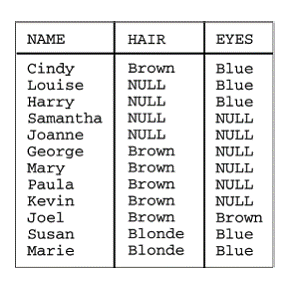
Figura 5.19 Tabela PEOPLE
SELECT HAIR, EYES, COUNT(*)
FROM PEOPLE
GROUP BY HAIR, EYES
HAIR EYES COUNT(*)
--------- ----- ----- ----
Brown Blue 1
NULL Blue 2
NULL NULL 2
Brown NULL 4
Brown Brown 1
Blonde Blue 2
Desi modul de tratare a valorilor NULL in cazul clauzei GROUP BY este clar specificat in standardul ANSI/ISO, el nu este implementat inca de toate SGBD-urile. Se recomanda realizarea, in prealabil a unor mici aplicatii de testare a comportamentului specific al SGBD-ului respectiv.
Selectia grupurilor de inregistrari (Clauza HAVING)
Asa cum clauza WHERE este utilizata pentru a selecta, individual, liniile care intervin intr-o interogare, clauza HAVING poate fi utilizata pentru a selecta grupuri de linii. Clauza HAVING consta din cuvantul rezervat HAVING urmat de o conditie de selectie pentru grupurile de linii. Sa consideram urmatorul exemplu :
Care este media valorii comenzilor pentru acei agenti de vanzari ale caror comenzi insumeaza mai mult de $30.000?
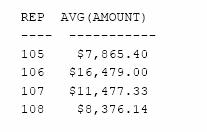
Figura 5.20 ne arata grafic cum proceseaza SQL aceasta interogare. Mai intai, clauza GROUP BY grupeaza comenzile dupa id-urile agentilor de vanzari ; apoi, clauza HAVING elimina orice grup pentru care totalul comenzilor nu depaseste $30.000. In final, clauza SELECT calculeaza media aritmetica a comenzilor pentru fiecare din grupurile ramase si genereaza rezultatul interogarii.
Conditiile de selectie pe care le putem include in clauza HAVING sunt aceleasi ca in cazul clauzei WHERE.
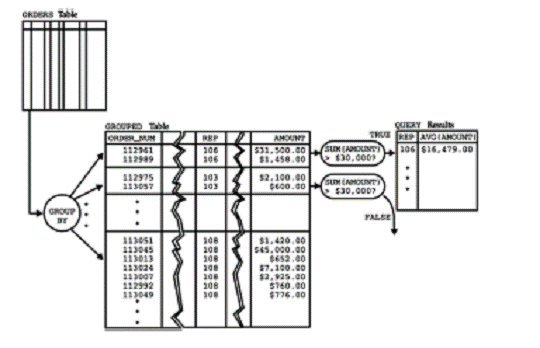
Figura 5.20 Procesarea selectiei grupurilor de inregistrari
Pentru fiecare birou cu doi sau mai multi angajati, sa se calculeze cota totala si totalul vanzarilor pentru toti agentii de vanzari care lucreaza in biroul respectiv.

Sa se afiseze pretul, cantitatea aflata in stoc si cantitatea totala comandata din fiecare produs pentru care cantitatea totala comandata este cu 75% mai mare decat cantitatea aflata in stoc.

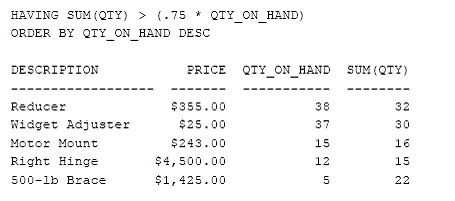
Pentru a procesa aceasta interogare, SQL parcurge urmatorii pasi :
1. Efectueaza joinul tabelelor ORDERS si PRODUCTS pentru a afla descrierea, pretul si cantitatea din stoc pentru fiecare produs comandat.
2. Grupeaza liniile rezultate dupa id-ul producatorului si al produsului.
3. Elimina grupurile in care cantitatea comandata (suma coloanei QTY pentru toate comenzile din grup) este mai mica decat 75% din cantitatea aflata in stoc.
4. Calculeaza cantitatea totala pentru fiecare grup.
5. Genereaza cate o linie totalizatoare in rezultatul interogarii, pentru fiecare grup.
6. Ordoneaza liniile din rezultat in ordinea descrescatoare a cantitatii.
Asa cum am precizat anterior, coloanele DESCRIPTION, PRICE si QTY_ON_HAND trebuie specificate ca si coloane de grupare dor pentru ca apar in lista de selectie. Ele nu contribuie de fapt cu nimic la gruparea inregistrarilor, deoarece MFR_ID si PRODUCT_ID identifica o singura linie din tabela PRODUCTS.
Restrictii asupra conditiei de selectie a grupurilor de inregistrari
Clauza HAVING este utilizata pentru a exclude grupuri de linii din rezultatul interogarii, asadar conditia de selectie pe care o contine trebuie sa fie una care se aplica grupului ca intreg mai degraba decat liniilor individuale. Aceasta inseamna un element din conditia de selectie a clauzei HAVING poate fi:
O constanta
O functie de grup
O coloana de grupare, care are prin definitie aceeasi valoare pentru toate liniile din grup
Orice expresie care contine combinatii ale elementelor de mai sus.
In practica, conditia de selectie din clauza HAVING va include cel putin o functie de grup. Daca nu, atunci conditia de selectie poate fi mutata in clauza WHERE si aplicata liniilor individuale.
Valorile NULL si conditia de selectie din clauza HAVING
Ca si conditia de selectie din clauza WHERE, conditia de selectie din clauza HAVING poate produce unul dintre urmatoarele trei rezultate: TRUE, FALSE sau NULL. Numai grupurile pentru care conditia de selectie este TRUE vor contribui la obtinerea rezultatelor interogarii. Anomaliile care pot aparea in legatura cu valorile NULL sunt aceleasi ca in cazul clauzei WHERE.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1199
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved