| CATEGORII DOCUMENTE |
PROBLEMELE ARHITECTURILOR PARALELE
Cand proiectam un nou sistem de calcul paralel, trebuie sa raspundem la urmatoarele intrebari fundamentale:
1. Tipul, numarul si dimensiunea procesoarelor;
2. Tipul, dimensiunea si repartitia modulelor de memorie, modul de partajare a datelor;
3. Modul de interconectare si sincronizare a procesoarelor si a modulelor de memorie.
Desi exista variatii mari in numarul si dimensiunea procesoarelor si a modulelor de memorie, totusi, solutiile de conectare sunt cele care fac sa difere esential modelele de arhitecturi paralele.
Din punctul de vedere al aplicatiilor executate pe arhitecturile paralele, avem doua categorii:
1. Time-sharing, partajarea in timp a procesorului de mai multe programe independente (ex. Unix). Un multiprocesor realizat cu mai multe procesoare este mai potrivit pentru astfel de sarcini, decat sa construiesti uniprocesoare tot mai sofisticate. Serverele de fisiere, de baze de date, de Web sunt standardizate pe multiprocesoare si detin un segment semnificativ din piata de calculatoare.
2. Parallel processing program (program de prelucrare paralela), un singur program care ruleaza pe mai multe procesoare simultan. Istoria calculatoarelor a demonstrat ca este foarte greu sa scrii programe concurente bune, care sa mearga bine pe orice arhitectura paralela (sa exploateze la maximum paralelismul oricarei masini, adica sa fie portabil).
Paralelismul poate fi exploatat la diferite niveluri:
nivel bit: aritmetica pe biti paraleli; elementele de procesare sunt construite sa opereze simultan pe mai multi biti (4, 8, 16, 32, 64 sau 128); cel mai scazut nivel de paralelism, asigurat de toate procesoarele actuale;
nivel variabila sau instructiune: mai multe variabile pot fi calculate simultan (vector sau scalari); procesoare construite sa execute simultan mai multe instructiuni prin suprapunerea fazelor de executie (pipeline = linie de asamblare cu unitati specializate, 5-12 etape) si prin suprapunerea executiei instructiunilor de acelasi tip sau diferite (superscalar mai multe unitati de acelasi tip sau de tip diferit, 2-6); transparent pentru programator, nivel asigurat de majoritatea procesoarelor actuale;
nivel proces: grupuri de instructiuni (rutine) ale aceluiasi task pot fi executate in paralel pe mai multe procesoare, colaborand strans pentru obtinerea rezultatului; ex. prelucrarea unei imagini de catre mai multe procesoare; nivel asigurat de multiprocesoarele actuale prin planificare statica (utilizator sau compilator) sau dinamica (sistem de operare);
nivel task: executia in paralel a mai multor sarcini ale aceluiasi program (ex: prelucrarea datelor de la senzori, calcule de pozitie si viteza si comanda motoarelor articulatiilor unui robot; prelucrarea si servirea a mii de cereri in paralel intr-un server de comert electronic);
nivel job: executia simultana, independenta a mai multor programe diferite (time-sharing).
1.1. Modele de comunicare
Pentru a intelege importanta comunicatiilor dintre procese (arhitectura interconexiunilor) e suficient sa ne imaginam ce comunicatii sunt necesare pentru a repartiza sarcinile si a sincroniza lucrarile de construire a unei case de catre 1 lucrator, 10, 100, 1000 sau 1000000 de lucratori. De fapt aceasta problema a comunicatiilor nu e noua, ea e semnalata si de Biblie, prin pilda celebra a Turnului Babel.
Sunt doua modele de comunicare: procesoare cu memorie partajata (multiprocesoare) si procesoare cu transfer de mesaje (procesoare cu memorie distribuita sau multicalculatoare).
 Toate procesoarele partajeaza o
memorie fizica comuna (fig. 1). Procesele care lucreaza pe un
multiprocesor partajeaza un spatiu de adrese unic. Procesele
comunica prin variabile partajate in memoria comuna (ex. unul scrie
datele in memorie, iar celalalt le citeste). Accesul la variabile
este simplu: executia instructiunilor LOAD (incarca) si
STORE (salveaza), iar sincronizarea proceselor se poate face prin bariere,
zavoare, semafoare, regiuni critice si monitoare. Memoriile cache
minimizeaza comunicatiile pe magistrala sau retea. Sunt
necesare protocoale de asigurare a coerentei cache-urilor.
Toate procesoarele partajeaza o
memorie fizica comuna (fig. 1). Procesele care lucreaza pe un
multiprocesor partajeaza un spatiu de adrese unic. Procesele
comunica prin variabile partajate in memoria comuna (ex. unul scrie
datele in memorie, iar celalalt le citeste). Accesul la variabile
este simplu: executia instructiunilor LOAD (incarca) si
STORE (salveaza), iar sincronizarea proceselor se poate face prin bariere,
zavoare, semafoare, regiuni critice si monitoare. Memoriile cache
minimizeaza comunicatiile pe magistrala sau retea. Sunt
necesare protocoale de asigurare a coerentei cache-urilor.
Este un model usor de inteles pentru programatori si are o gama foarte larga de aplicatii.
 Fiecare procesor are memoria sa
privata (fig. 2) la care numai el are acces prin instructiuni LOAD
si STORE. Un astfel de sistem se mai numeste si multicalculator
sau sistem cu memorie distribuita (distributed memory system).
Fiecare procesor are memoria sa
privata (fig. 2) la care numai el are acces prin instructiuni LOAD
si STORE. Un astfel de sistem se mai numeste si multicalculator
sau sistem cu memorie distribuita (distributed memory system).
Procesoarele comunica intre ele folosind transferul de mesaje prin reteaua de interconectare. Pentru aceasta se folosesc primitive de tip SEND (trimite) si RECEIVE (receptioneaza). Comunicarea de mesaje poate fi sincrona sau asincrona, directa (de la proces la proces - peer-to-peer), prin cutii postale globale sau prin canale de legatura intre procese.
Acest tip de comunicatie da programelor de pe multicalculatoare o structura diferita si mult mai complicata decat a programelor de pe multiprocesoare. Impartirea corecta a datelor si plasarea lor optima in memoriile private sunt aspecte majore intr-un multicalculator. Toate aceste aspecte fac programarea multicalculatoarelor mult mai complicata.
Multiprocesoarele sunt mult mai greu de construit si mai putin scalabile, dar sunt foarte usor de programat. In schimb, muticalculatoarele sunt foarte usor de construit si sunt foarte scalabile (usor se pot ajunge la arhitecturi cu mii de procesoare), dar sunt greu de programat. Din acest motiv, foarte mare parte din cercetarile actuale in arhitecturi paralele urmaresc realizarea convergentei celor doua tipuri de arhitecturi in forme hibride care sa combine avantajele fiecareia. Astfel, regia comunicatiilor prin transfer de mesaje nu mai este lasata in seama programatorului ci este preluata de sistemul de operare sau de sisteme de asistenta a executiei dependenta de limbajul de programare (nivel peste sistemele de operare) care ofera programatorului un spatiu virtual de adrese partajat la nivelul paginilor sau al blocurilor (de memorie cache) unic in cadrul sistemului.
Aceasta abordare este numita DSM (Distributed Shared Memory, rom: memorie distribuita partajata). Aceasta permite utilizarea modelului de programare cu memorie partajata utilizand comunicatii simple prin LOAD si STORE. Se creaza astfel programatorului iluzia unei memorii partajate mari, dar comunicatiile trebuie sa fie rare avand in vedere ca transferul paginilor de memorie dureaza mult. Memoriile cache minimizeaza transferurile prin retea. Sunt necesare protocoale de coerenta a cache-urilor si a memoriilor private.
1.2. Retele de interconectare
Am aratat ca retelele de interconectare sunt utilizate atat in multiprocesoare cat si in multicalculatoare si sunt similare. Deosebirea este ca in multiprocesoare retelele leaga procesoarele la modulele de memorie, iar in multicalculatoare retelele leaga procesoarele sau modulele de memorie intre ele. Prin retea se trimit mesaje (pachete).
Pentru a simplifica prezentarea, in continuare vom utiliza termenul de nod pentru a desemna modulele de memorie sau una din combinatiile:.
Retelele interconecteaza procesoare cu memorii sau procesoare intre ele (prin procesor se poate intelege si combinatiile: procesor + memorie cache sau procesor + memorie cache + memorie privata) si constau din urmatoarele componente:
1. Interfete.
2. Legaturi.
3. Comutatoare.
Interfata conecteaza un procesor sau un modul de memorie la retea. De regula este un cip (de multe ori acesta poate contine mai multe interfete). Interfata asigura logica de control care implementeaza protocoalele de acces la retea si buffere de memorie (de regula cozi FIFO = First-In-First-Out). Utilizand mai multe cozi pentru un canal fizic, se pot realiza canale virtuale si implementa politici de calitate a serviciilor (tratare diferentiata a pachetelor, alocare de banda etc).
Legaturile sunt canalele fizice pe care se deplaseaza bitii. Ele pot fi din cupru sau fibra optica. Pot fi seriale (latime de un bit) sau paralele (8/16/32/64/128 biti). Fiecare legatura are o largime de banda (numarul maxim de biti transferati pe secunda). Legaturile pot fi simplex (unidirectionale), semi-duplex (intr-un singur sens la un moment dat) sau duplex (in ambele sensuri simultan).
Comutatoarele sunt dispozitive cu mai multe porturi de intrare si mai multe porturi de iesire si realizeaza functia de comutare a pachetelor de la un port de intrare la unul sau mai multe porturi de iesire in functie de un camp adresa continut in pachet sau de politica de comutare stabilita de program.
Pachetele pot fi scurte (2 octeti) sau lungi (pagini de memorie de 2/4/8/16/32/64 kocteti).
Latenta unei retele reprezinta timpul necesar unui pachet pentru a traversa reteaua de la sursa la destinatie. Este de preferat o retea cu latenta mica, largime de banda mare si rata erorilor mica, deziderate greu de realizat avand in vedere antagonismul lor: latenta mica inseamna interfete cu buffere mici, comutatoare fara memorie si transfer de pachete scurte, dar avem dezavantajul ca informatia utila din pachet e redusa in comparatie cu informatia de control (campuri de adrese si coduri detectoare de erori) ceea ce face ca largimea de banda sa scada. O largime de banda mare presupune interfete cu buffere mari si transferul de pachete lungi, ceea ce creste latenta si rata erorilor. O rata a erorilor mica cere comutatoare cu memorie si coduri detectoare si corectoare de erori si creste latenta si scade largimea de banda.
In proiectarea unei retele trebuie sa se tina cont de urmatoarele aspecte:
1. Topologia retelei (modul de aranjare a componentelor).
2. Tehnicile de comutare a pachetelor si modul de tratare a competitiei la resurse.
3. Algoritmii de rutare a pachetelor catre destinatie.
Topologia retelei de interconectare descrie modul de aranjare a legaturilor si comutatoarelor. Topologiile pot fi modelate ca grafuri cu legaturile ca arce si comutatoarele ca noduri. Fiecare nod din retea are un numar de legaturi (arce) conectate la el. Numarul de legaturi la un nod dau gradul nodului sau incarcarea la iesire (fanout).
In analiza topologiei unei retele se iau in considerare urmatorii parametri (proprietati):
Diametrul retelei: reprezentat de distanta (numarul de arce) dintre cele mai departate doua noduri. De diametru este legata latenta maxima. Este de preferat ca diametrul retelei sa fie cat mai mic (ideal ). Important este si diametrul mediu al retelei (furnizeaza latenta medie).
Largimea de banda a bisectiei (bisection bandwidth): se partitioneaza reteaua in doua parti egale (ca numar de noduri) si calculeaza largimea de banda totala a arcelor care leaga cele doua jumatati ale retelei. Se ia cazul cel mai defavorabil (daca exista un astfel de caz).
Dimensionalitatea retelei: reprezinta numarul de drumuri posibile intre doua noduri. Ex: o retea zero-dimensionala este o retea in care exista o singura cale intre sursa si destinatie; o retea unu-dimensionala este reteaua in care exista doua cai; si asa mai departe.
Pentru a descrie topologia legaturilor se folosesc functii de permutare. acestea sunt functii bijective simple prin care fiecarei intrari i se asociaza o iesire si numai una. Prin combinarea lor se pot realiza conexiuni complexe.
Fiecarui nod i se asociaza o adresa x formata din m biti:
x = (bm,bm-1,,b1) bi = bitul i N = 2m numarul maxim de noduri.
Se defineste functia de permutare f
f : M M (M = multimea nodurilor Mx Mx Mf(x)
Reteaua de interconectare noduri poate fi descrisa ca permutari pe reprezentarile binare ale adreselor.
Vom defini in continuare functiile de permutare uzuale insotite de exemple pentru m = 3 biti N = 23 = 8 noduri; in aceste exemple nu vom figura nodurile de tip procesor si memorie care se conecteaza la nodurile boxe de comutare
1. Permutarea identica (identity):
I(x) x
2. Permutarea deplasare circulara (inel):
R(x) = (x+1) mod N
Fig.
3. Permutarea inel (pentru m = 3
biti N = 23 = 8
noduri)
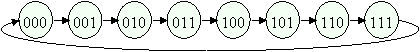
Este o retea folosita in multe sisteme paralele. Este o retea unu-dimensionala, fiecare pachet are doua optiuni de rutare: spre stanga sau spre dreapta.
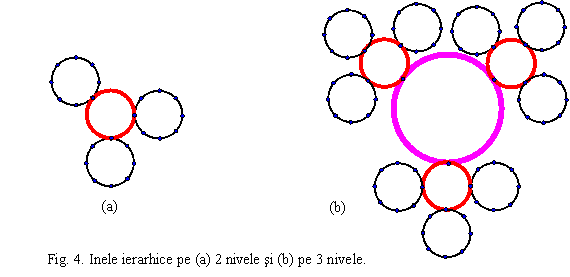
Se pot defini si inele ierarhice (fig. 4) prin interconectarea mai multor inele printr-un alt inel. Ierarhia poate fi 2, 3 sau mai multe nivele.
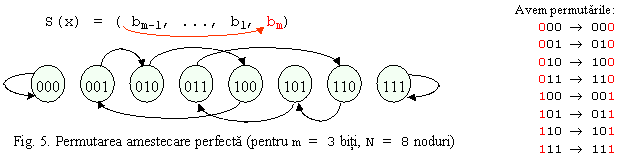 3.
Permutarea amestecare perfecta (perfect shuffle):
3.
Permutarea amestecare perfecta (perfect shuffle):
Mai sunt utilizate si permutarile:
- subamestecare de ordinul k (k-subshuffle):
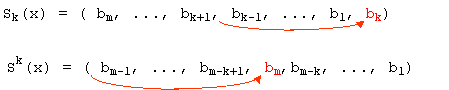
- superamestecare de ordinul k (k-supershuffle):
Este o topologie foarte raspandita deoarece in ea se transpun natural foarte multe aplicatii. Denumirea de amestecare perfecta vine de la modul de amestecare a cartilor de joc: separarea pachetului in doua parti egale si apoi amestecarea lor prin intercalarea cartilor.
4. Permutarea fluture (butterfly):
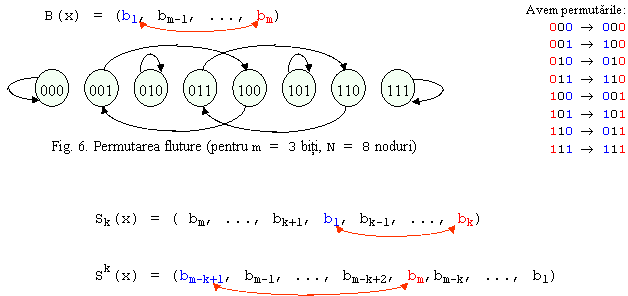
Mai sunt utilizate si permutarile:
- subfluture de ordinul k (k-subbutterfly):
- superfluture de ordinul k (k-superbutterfly):
5. Permutarea schimbare (exchange):
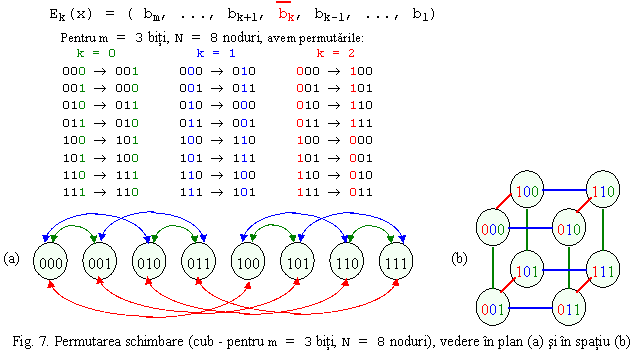
Observatie: fiecare nod e conectat la nodurile fata de care adresele difera printr-un singur bit.
Topologiile pentru m > 3 se numesc topologii hipercub (hypercube). Hipercuburile au urmatoarele proprietati:
Hipercuburile pot fi definite inductiv (un hipercub de ordinul n+1 este constituit din doua hipercuburi de ordinul n, plus conexiunile tuturor acestor noduri; fig. 8):
hipercubul de ordinul 1: are N1 noduri
si P1 legaturi;
hipercubul de ordinul 2: are N2 noduri
si P2 = 2P1 + = 2 legaturi;
hipercubul de ordinul 3: are N3 noduri
si P3 = 2P2 + legaturi;
hipercubul de ordinul 4: are N4 noduri
si P4 = 2P3 + legaturi;
hipercubul de ordinul n: are Nn 2n noduri
si Pn = 2Pn-1 + 2n-1 = n 2n-1 legaturi.
Numarul de conexiuni creste numai logaritmic in raport cu numarul de noduri:
Pn n 2n-1 n 2n/2
dar N = 2n atunci n = logN
rezulta: Pn = (N/2)logN
Un hipercub este un supraset al altor retele de interconexiuni (inele, arbori etc): transpunerea lor se face prin dezactivarea unor conexiuni.
Hipercuburile sunt scalabile: rezultat al definirii recursive.
Diametrul creste liniar cu dimensionalitatea: ex. un cub 10-dimensional (de ordinul 10) are noduri, dar diametrul (distanta maxima dintre doua noduri) este de numai 10. Pretul platit este incarcarea la iesire (fanout) mai mare, ceea ce inseamna mai multe porturi pe nod, complexitatea nodului creste odata cu numarul de noduri din retea. Pentru o retea grila (vezi punctul 6) tot cu 1024 de noduri, aranjate 32 x 32, diametrul este 62, deci de 6 ori mai mare. Dar complexitatea nodului ramane constanta indiferent de numarul de noduri din retea.
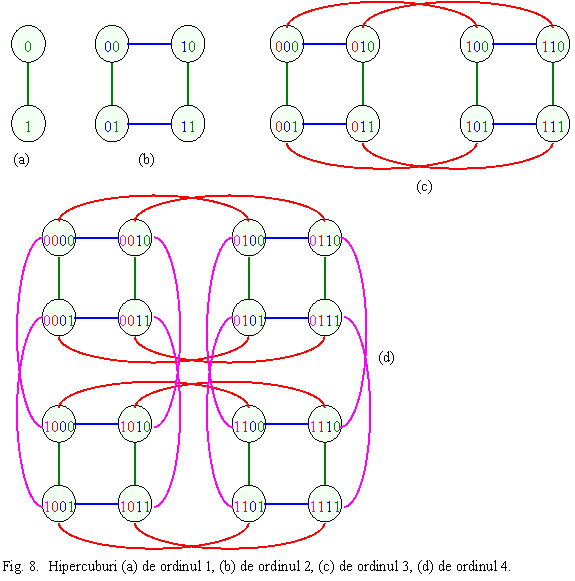
Hipercuburile au scheme de rutare simple, bazate pe eticheta (adresa nodului): lungimea drumului dintre 2 noduri este egala cu numarul de biti prin care etichetele nodurilor difera.
Hipercuburile sunt tolerante la defectari: intre doua noduri sunt mai multe drumuri posibile.
Toate aceste proprietati fac din retelele hipercub alegerea preferata pentru retelele de interconectare din sitemele de inalta performanta.
6. Permutarile deplasari simple pe domenii (simple-shifter): au ca rezultat grila sau plasa (mesh).
M+r(x) = (x + r), 0 x < (k-1)r pentru legaturile verticale
Mk (x) = (x + 1), (k-1) x < k(r-1) pentru legaturile orizontale
unde r = N este latura grilei,
iar k = 1..r, este numarul de linii sau coloane al grilei.
Exemplu: pentru m = 4 biti, N = 24 = 16 noduri, r = , latura grila.
Vom avea functiile:
B (x) = (x + 4), 0 x < 12
Bk (x) = (x + 1), (k-1) x < 3k, k = 1..4
Obtinem permutarile:
pentru legaturile verticale: - pentru legaturile orizontale:
4 8 k = 1 k = 2 k = 3 k
5 9 13 0 1 4 8 12
6 10 14 1 2 5 9 13
7 11 15 2 3 6 10 14
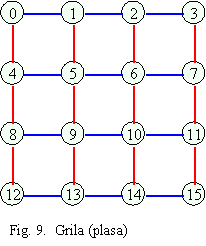
Grila este o topologie unidimensionala folosita in multe sisteme comerciale. Prezinta o mare regularitate si este usor de scalat (complexitatea nodului nu creste cu dimensiunea grilei). Diametrul creste proportional cu radacina patrata a numarului de noduri:
d = 2r = 2 N
7. Permutarile deplasari circulare (barrel-shifter): au ca rezultat torurile simple sau duble.
B+r(x) = (x + r) mod N pentru torul vertical
Bk (x) = (x + 1) mod kr, (k-1) x < kr pentru torul orizontal
unde r = N este lungimea circumferintei torului,
iar k = 1..r, este numarul de cercuri al torului orizontal.
Exemplu: pentru m = 4 biti, N = 24 = 16 noduri, r = , circumferinta tor.
Vom avea functiile:
B (x) = (x + 4) mod 16
Bk (x) = (x + 1) mod 4k, (k-1) x < 4k
Obtinem permutarile: - pentru torul orizontal:
pentru torul vertical: k = 1 k = 2 k = 3 k
4 8 12 12 0 4 5 8 12
5 9 13 13 1 5 6 9 10 13
6 10 14 14 2 6 7 10 11 14
7 11 15 15 3 7 4 11 15
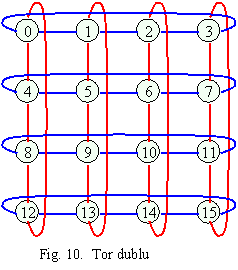
Torul dublu (double torus) este o grila cu marginile conectate. Are avantajul ca diametrul este mult mai mic decat la grila (in exemplul alaturat diametrul este 2 si nu 6 cat este pentru grila).
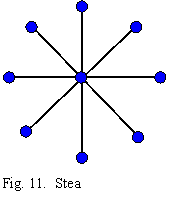
8. Topologia stea (star - fig. 11) este o topologie zero-dimensionala in care procesoarele si memoriile sunt conectate la nodurile exterioare, iar nodul central face doar comutare. Este o topologie intalnita des la retelele de calculatoare, este simpla dar are dezavantajul ca nu este toleranta la defecte, iar nodul central poate fi o sursa majora de strangulare.
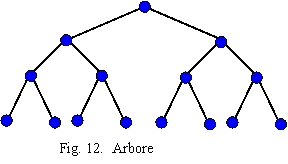
9. Topologia arbore sau stea extinsa (tree, extended star - fig. 12) este o topologie de asemenea zero-dimensionala des intalnita in retelele de calculatoare. Largimea de banda a bisectiei este egala cu capacitatea legaturii. Deoarece traficul creste pe masura ce ne apropiem de radacina, o solutie practica este sa crestem largimea de banda a legaturilor din vecinatatea radacinei. Se optine asa-numitul arbore gros (fat tree). Nodul radacina si cele din imediata vecinatate a lui nu conecteaza procesoare si memorii sau, daca da, atunci conecteaza procesoare si memorii foarte rapide, cu un statut special (in cazul retelelor de calculatoare, conecteaza servere foarte puternice).
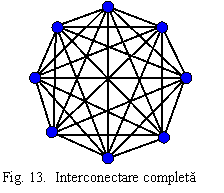
10. Interconectarea completa (full interconect - fig. 13) este o topologie utilizata la sistemele cu numar relativ redus de procesoare. Asigura o conexiune directa intre oricare doua noduri ale retelei. Are foarte multe avantaje: maximizeaza largimea de banda a bisectiei, minimizeaza diametrul (este 1) si este excesiv de toleranta la defecte (poate pierde oricare N-2 legaturi si este in continuare complet conectata), este neblocabila. Are insa marele dezavantaj ca necesita un numar foarte mare de legaturi N(N-1)
In practica, sunt utilizate doua moduri de implementare a retelelor: retele cu o singura etapa (single-stage) si retele multietapa (multistage).
Retelele cu o singura etapa
Figura 14 (a) ilustreaza conceptul de retea cu o singura etapa, sau retea recirculanta. Iesirile unui ciclu devin intrarile ciclului urmator, si procesul se poate repeta. Totusi, in realitate, aceste retele au numai N terminale, asa cum se arata in figura 14 (b).
Retelele cu o singura etapa pot asigura un numar limitat de functii (de permutare) in fiecare ciclu, dar se pot obtine functii mai complicate utilizand reteaua in mod iterativ. Compromisul realizat de aceste retele este ca au un cost scazut, dar se pierde mult la timpul de operare.

Retelele cu o singura etapa pot fi descrise matematic printr-un set de functii bijective pe care reteaua le poate asigura intr-un ciclu:
NET
Numarul de functii ce pot fi asigurate simultan depinde de complexitatea hardware-ului. In anumite moment de timp, unele procesoare pot sa nu participe la transferul datelor.
Exemple de retele cu o singura etapa:
reteaua inel (Ring):
RING
consta din permutarile identitate si deplasare circulara.
reteaua cel mai apropiat vecin (Nearest-Neighbor) :
NN
consta dintr-un inel bidirectional. R-1 este deplasarea circulara inversa: R-1 R = I
reteaua amestecare-schimbare (Shuffle-Exchange):
SE
E o retea populara deoarece un mare numar de aplicatii se transpun natural in ea.
reteaua amestecare perfecta - cel mai apropiat vecin (Perfect-Shuffle - Nearest-Neighbor):
SNN
Retelele multietapa
Retelele multietapa sunt utilizate cand sunt necesare o gama mai larga de conxiuni si numarul de procesoare este mare. Asa cum se prezinta in Figura 15, aceste retele constau dintr-o serie de etape de comutare (switching stage) legate prin retele de permutare (permutation connection).

Etapele de comutare constau din boxe de comutare aranjate intr-o coloana. Boxele de comutare au mai multe intrari si mai multe iesiri si pot asigura mai multe functii de comutare. In figura 16 prezentam boxe de comutare cu 2 intrari si 2 iesiri care pot asigura 4 functii de comutare.

Vom prezenta in continuare doua exemple de retele multietapa.
Reteaua cub multietapa
Aceasta retea conecteaza N intrari la N iesirisi consta din logN etape formate din N boxe de comutare. Reteaua cub multietapa pentru N este prezentata in Figura 17. Reteaua e definita astfel incat etapa i implementeaza functia de permutare schimbare (cub) Ei. Boxele de comutare sunt simple, fara buffere, si sunt comandate prin program la nivel de etapa.
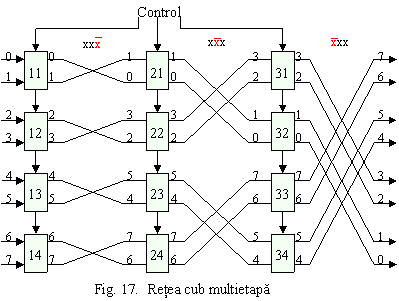
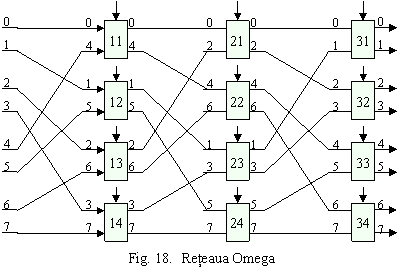
Reteaua Omega
Aceasta retea conecteaza N intrari la N iesiri si consta din logN etape formate din N boxe de comutare. Reteaua Omega pentru N este prezentata in Figura 18. Legaturile implementeaza functia de permutare amestecare perfecta (perfect-shuffle). Boxele de comutare sunt simple, fara buffere, si sunt comandate individual, prin program.
In functie de capacitatea lor de a evita blocarile, retelele se clasifica in urmatoarele 4 categorii:
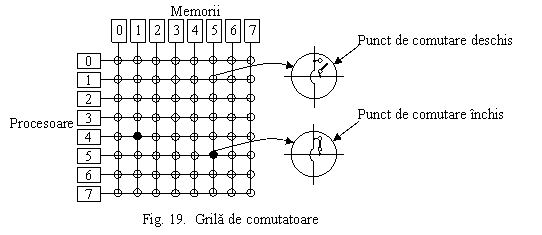
(1) Retele strict neblocante (strictly nonblocking): pot conecta orice intrare nefolosita cu orice iesire nefolosita indiferent de ce alte conexiuni sunt in lucru. Aceasta inseamna ca e posibila efectuarea conexiunilor in orice ordine.
De exemplu, o interconectare cu grila de comutatoare (crossbar - Fig. 19) este strict neblocanta. Dearece pentru a conecta un numar foarte mare de procesoare si module de memorie, numarul de comutatoare creste foarte repede (N2) retelele grila de comutatoare sunt prohibitiv de scumpe, s-au facut eforturi mari pentru a proiecta retele strict neblocante cu mai putin de N2 comutatoare.
Retelele Clos sunt exemple de retele implementate eficient. O retea Clos cu 3 nivele este prezentata in Figura 20. Fiecare etapa consta dintr-un numar de boxe mai mici cu grile de comutatoare (crossbar switches). Numarul de intrari este N = rn, unde r este numarul de boxe de comutare de pe primul si ultimul nivel, iar n este numarul de intrari la fiecare boxa. Clos a aratat ca reteaua are mai putin de N2 puncte de incrucisare (crosspoints) pentru N si in general cere cel mult Ne logN puncte de incrucisare. Pentru m 2n-1, reteaua Clos este strict neblocanta.
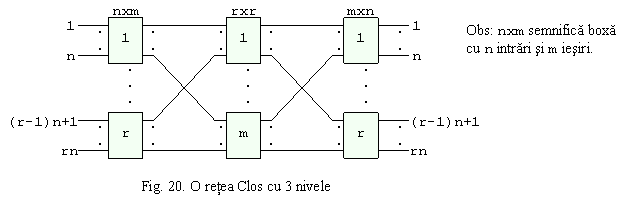
(2) Retele neblocante in sens larg (wide-sense nonblocking): poate gestiona toate conexiunile posibile fara blocare, dar poate sa o faca numai daca sunt utilizate reguli specifice de rutare pentru realizarea conexiunilor. Toate conexiunile dorite trebuie specificate inainte inceperii calculelor de rutare. Clos a aratat ca pentru m 3n reteaua prezentata in Figura 20 este o retea neblocanta in sens larg. Aceste retele au mai putine noduri de comutare decat retelele strict neblocante.
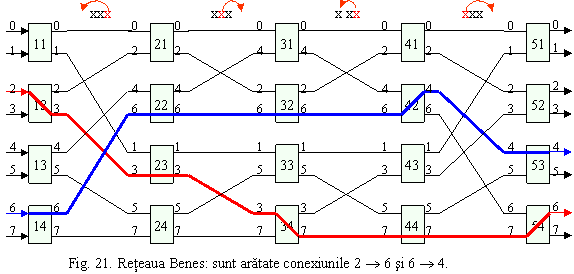
(3) Retele neblocante prin rearanjare (rearrangeable nonblocking): pot asigura toate conexiunile posibile dintre intrari si iesiri prin rearanjarea conexiunilor existente. Toate conexiunile dorite trebuie specificate inainte inceperii calculelor de rutare. Reteaua Clos prezentata in Figura 20 este neblocanta prin rearanjare daca m n. Un exemplu de retea rearanjabila ce conduce la un minim de puncte de comutare a fost propus de Benes. Figura 21 prezina o retea Benes binara cu 8 intrari si 8 iesiri. In general, cand numarul de intrari este N = 2n, numarul de etape este 2n-1 si numarul de boxe de comutare este N(2n-1)/2. Reteaua asigura functiile de permutare amestecare perfecta:
BENES =
(3) Retele blocante (blocking interconnection): pot asigura multe, dar nu toate conexiunile posibile dintre intrari si iesiri. Exemple de retele blocante: reteaua Omega, reteaua cub etc.
Asa cum am prezentat, retelele sunt formate din etape de permutare (firele de legatura) si etape de comutare (contin boxe de comutare). Retelele interconecteaza procesoare sau procesoare cu module de memorie. Figura 22 prezinta un exemplu de retea cu 4 boxe de comutare, fiecare boxa are 4 porturi de intrare si 4 porturi de iesire, porturile contin zone tampon de memorie (buffer) organizate in cozi FIFO. Fiecare port de iesire al unui comutator este conectat cu un port de intrare al altui comutator printr-o legatura seriala sau paralela. Legaturile paralele pot transfera mai multi biti simultan, deci au o largime de banda mai mare, dar au dezavantajul ca bitii pot ajunge la momente de timp diferite - fenomenul de distorsiune (skew), deci trebuie asigurata sincronizarea (cu semnale de control). Legaturile paralele sunt mai scumpe (numar mare de pini si de legaturi), de aceea in arhitecturile masiv paralele se prefera legaturi seriale de foarte mare viteza pe cupru sau fibra optica.
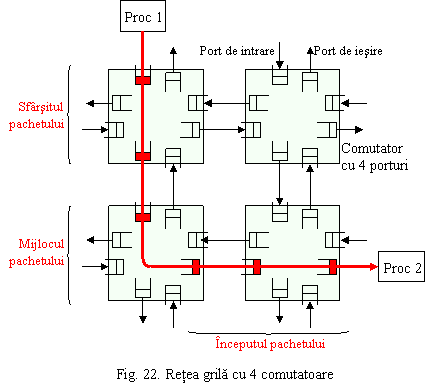
In retele sunt utilizate 3 tehnici de baza de comutare: comutare de circuite, comutare de pachete si comutarea gaura de vierme.
(1) Comutarea de circuite (circuit switching)
Inainte ca un pachet sa fie trimis, mai intai este rezervata intreaga cale de la sursa la destinatie (toate porturile si toate cozile), astfel incat atunci cand incepe transmisia toate resursele necesare sunt garantat disponibile si toate pachetele se pot deplasa cu viteza maxima (Figura 22). Este foarte eficienta pentru transmisii intensive de date, dar este dezavantajoasa in cazul cand transferurile sunt doar ocazionale.
(2) Comutarea de pachete
Are doua variante:
comutare de pachete cu memorare si retransmitere (store-and-forward packet switching);
comutare de pachete cu cale directa virtuala (virtual cut through switching).
Comutarea de pachete cu memorare si retransmitere
Pachetul este memorat complet la receptie, verificat sa nu contina erori si numai dupa acea transmis mai departe la urmatorul comutator spre destinatie. Aceasta tehnica presupune utilizarea de comutatoare cu memorie suficienta pentru stocarea temporara a unui numar mare de pachete. Avand in vedere ca nu se face o rezervare dinainte a porturilor spre destinatie, se poate intampla ca dupa receptia unui pachet, portul de iesire necesar sa fie ocupat cu transmiterea altui pachet.
Sunt utilizate 3 strategii de stocare temporara:
Stocare temporara la intrare (input buffering): fiecare port de intrare are asociate una sau mai multe cozi FIFO. Daca pachetul din capul cozii nu poate fi transmis pentru ca portul de iesire este ocupat, atunci el asteapta. Problema este ca raman blocate si alte pachete din spatele pachetului blocat, dar care asteapta pentru alte porturi de iesire, chiar daca aceste porturi sunt libere. Aceasta situatie se numeste blocarea de cap de linie (head-of-line blocking).
Stocarea temporara la iesire (output buffering): elimina blocarea de cap de linie, prin asociarea cozilor la porturile de iesire, astfel incat, pachetele, pe masura ce sunt receptionate, sunt stocate in cozile porturilor de iesire corespunzatoare caii spre destinatie.
Stocare temporara comuna (common buffering): atat prima cat si a doua strategie aloca un numar fix de zone tampon fiecarui port. Daca pachetele sosesc mai repede decat pot fi transmise, apare situatia ocuparii tuturor zonelor tampon si pierderea de pachete care nu mai pot fi receptionate. Solutia stocarii temporare comune permite alocarea dinamica a zonelor tampon functie de necesitatile porturilor, dintr-un rezervor central. Desi are avntajul ca poate elimina pierderea de pachete si stocarea de pachete lungi, totusi necesita o administrare mai complexa, iar un port mai incarcat poate, la un moment dat, sa acapareze intreaga memorie blocand restul porturilor.
Comutare de pachete cu cale directa virtuala (virtual cut through switcing)
Tehnica comutarii de pachete cu memorare si retransmitere are avantajul unei transmisii fara erori, dar prezinta problema unei latente (intarzieri) foarte mari: fiecare comutator mai intai memoreaza intregul pachet apoi il retransmite mai departe (intarzierea este proportionala cu numarul de comutatoare de pe calea pana la destinatie). Comutare de pachete cu cale directa virtuala reduce latenta prin urmatoarea abordare: comutatorul stocheaza doar antetul pachetului pentru a determina portul de iesire dupa care incepe retransmiterea sa fara a mai astepta sfarsitul pachetului. Are dezavantajul ca pot fi retransmise si pachete ce contin erori. In cazul in care portul de iesire nu e liber, aceasta tehnica recurge si ea la stocarea intregului pachet sau a unei parti a lui pana ce portul de iesire devine liber.
(3) Comutarea gaura de vierme (wormhole switching)
Incearca sa imbine avantajele comutarii de circuite cu cel al comutarii de pachete cu cale directa virtuala. Primul pachet dintr-un mesaj (de reghula unul mai scurt, eventual numai antet cu adresele destinatie si sursa) seteaza un canal ce va fi urmat si de restul pachetelor din mesaj - ca o gaura de vierme. Numai ca atunci cand pachetul din fata nu mai poate avansa (blocat intr-un comutator la un port de iesire), primul comutator trimite un pachet pe calea inversa spre sursa pentru blocarea intregului lant de transfer, astfel incat pachetele mesajului poate ramane insirate pe mai multe comutatoare, ca un vierme.
Algoritmii (tehnicile) de rutare furnizeaza metode de stabilire a cailor de domunicatie (rute de la sursa la destinatie) si de rezolvare a conflictelor (blocarea) in cazul retelelor cu dimensionalitatate mai mare sau egala cu unu (cand exista cel putin doua cai de la sursa la destinatie).
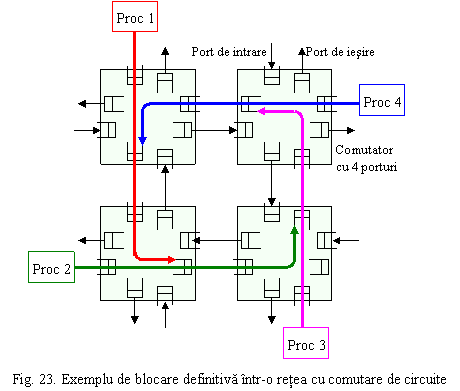
Un algoritm de rutare bun poate distribui incarcarea pe mai multe legaturi (incarcare balansata) pentru a utiliza complet largimea de banda disponibila a retelei si pentru a evita blocarile definitive (deadlock). O blocare definitiva apare atunci cand mai multe pachete aflate simultan in tranzit prin retea cer simultan aceleasi resurse, blocandu-se simultan astfel incat nici unul nu mai poate avansa.
Figura 23 prezinta un exemplu de blocare definitiva intr-o retea cu comutare de circuite. Fiecare procesor incearca sa stabileasca un canal de comunicatie cu procesorul din coltul opus lui. Actiunea a fost inceputa simultan de toate procesoarele si fiecare a reusit sa rezerve porturile din comutatorul alaturat lui si portul de intrare de pe urmatorul comutator, dar a gasit ocupat portul de iesire si atunci asteapta eliberarea lui pastrand insa ocupate porturile deja rezervate. Acest lucru conduce la o blocare definitiva a tuturor procesoarelor.
Exista 3 tehnici de rutare de baza:
(1) Schema de rutare centralizata (centralized routing): o logica de control centrala ia toate deciziile logice necesare stabilirii cailor de comunicatie. E usor de realizat pentru sisteme pe scara mica si medie. Logica centrala este un factor de gatuire.
(2) Schema de rutare la sursa (source routing): sursa determina in avans calea in retea pana la destinatie exprimata prin lista porurilor de iesire de la fiecare comutator. Fiecare port are alocata o adresa exprimata printr-un numar de biti (1 - 16 biti). Antetul fiecarui pachet contine lista adreselor porturilor de iesire. Sunt doua metode prin care un comutator isi determina adresa portului de iesire pe care-l va folosi: o metoda presupune ca fiecare comutator sa elimine din lista campul de adresa destinat lui, astfel incat urmatorul comutator va gasi adresa portului sau in capul listei de adrese; o alta metoda presupune utilizarea unui pointer la lista de adrese, incrementat pe rand de fiecare comutator dupa ce a identificat adresa portului sau de iesire. Prima metoda are avantajul ca scurteaza dimensiunea pachetului, dar ultima metoda este de preferat atunci cand pachetul transmis cere un mesaj de raspuns care ar putea sa se intoarca pe aceeasi cale, si atunci fiecare comutator, pe masura ce pachetul avanseaza spre destinatie, inlocuieste adresa portului sau de iesire cu adresa portului pe care a intrat pachetul astfel ca atunci cand pachetul ajunge la destinatie are in antet lista porturilor pe care ar trebui sa revina raspunsul, numai ca in ordine inversata (aceasta nu e o problema, se mai poate adauga un bit de stare in antet care sa indice ca pointerul la lista de adrese trebuie incrementat sau decrementat).
(3) Rutare distribuita (distributed routing): decizia privid calea pe care trebuie s-o urmeze fiecare pachet spre destinatie o ia fiecare comutator local. Fiecare comutator are o lista de adrese de destinatie posibile si portul de iesire asociat fiecarei adrese. Sunt doua scheme de rutare distribuita:
Rutare statica: daca tabela de rutare este predefinita (inainte de inceperea executiei, de programator, compilator sau sistemul de operare), atunci toate pachetele cu aceeasi adresa destinatie vor urma intotdeauna aceasi cale.
Rutare dinamica sau adaptiva: daca tabela de rutare este generata dinamic de fiecare comutator pe baza informatiilor despre traficul curent.
1.3. Performanta calculatoarelor paralele
Scopul construirii unei arhitecturi paralele este in primul rand performanta: sa functioneze mult mai rapid decat o arhitectura uniprocesor. Obligatoriu, aceasta performanta trebuie obtinuta la un cost acceptabil. De fapt aceasta a fost boala de care au suferit primele calculatoare paralele: proiectarea si implementarea lor au durat foarte mult ceea ce le-au facut foarte scumpe, iar cand au aparut pe piata erau deja uzate moral (egalate ca performanta de calculatoarele uniprocesor). De asemeni, pretul lor foarte ridicat a facut ca ele sa aiba o piata foarte mica, deci si un numar foarte mic de aplicatii, in general neportabile de la o arhitectura paralela la alta. Multe din aceste arhitecturi au suferit de faptul ca erau prea revolutionare, iar piata nu era pregatita sa le accepte. Dar, totusi, investitia in cercetarea arhitecturilor paralele, inceputa chiar din anii 1950, nu s-a irosit in zadar ci, atunci cand tehnologia a permis, iar piata a devenit pregatita sa le accepte (anii 1990), arhitecturile paralele au cunoscut o adevarata explozie, recastigandu-si locul meritat.
In continuare vom examina cateva aspecte legate de performanta ale arhitecturilor paralele.
Vom examina in continuare doar metricile hardware. Interesante aici sunt performantele procesoarelor (CPU - Central Processing Unit, rom: UCP - Unitate Centrala de Prelucrare), ale memoriei, ale sistemului de intrare iesire (I/O - Input/Output) si ale retelei de interconectare. Avand in vedeere ca performantele CPU, memoriei si I/O comporta aceleasi discutii ca si la sistemele uniprocesor, vom analiza in continuare doar metricile de performanta ale retelelor de interconectare.
Asa cum am mai precizat, exista doua elemnte cheie ale performantei retelelor de interconectare: latenta si largimea de banda.
Latenta: este timpul necesar transmiterii unui pachet prin retea, din momentul inceperii transmiterii sale de catre emitatorul initial si momentul terminarii receptiei sale de catre receptorul final. Daca se socoteste si timpul necesar primirii raspunsului, atunci avem latenta dus-intors (roundtrip latency). In functie de elementele care transmit si receptioneaza pachetele, latenta poate desemna:
timpul de citire sau scriere a unui cuvant, bloc sau pagina de memorie;
timpul de comunicare intre procesoare.
De regula, latenta este rezultatul contributiei mai multor factori ce difera in functie de tehnica de comutare si algoritmul de rutare.
In cazul comutarii de circuite, latenta este suma timpului de stabilire a canalului de comunicatie si timpul de transmitere a pachetului. Prectic se desfasoara urmatoarele operatii: se transmite mai intai un pachet de sondare care rezerva circuitele si se asteapta raportarea rezultatului; se asambleaza pachetul de date si se transmite apoi pachetul la viteza maxima.
Daca notam: Ts - timpul total de stabilire a canalului de comunicatie;
Ta - timpul de asamblare a pachetului;
d - dimensiunea pachetului (in biti);
b - largimea de banda a canalului de comunicatie (in biti/secunda);
Lcc - latenta pentru comutarea de circuite,
atunci: Lcc = Ts + Ta + d/b secunde.
Pentru a receptiona si un raspuns de r biti:
Lcc = Ts + Ta + (d+r)/b secunde
In cazul comutarii de pachete cu memorare si retransmitere (store and forward), nu mai este necesar un timp de stabilire a circuitelor, in schimb fiecare comutator trebuie sa receptioneze intregul pachet, sa faca unele operatii de regie proprie (verifica daca pachetul contine erori, citeste adresa portului destinatie, incrementeaza/decrementeaza un pointer, eventual asteapta terminarea transmisiei pechetelor din coada portului de iesire) si abia dupa aceasta retransmite pachetul catre urmatorul comutator.
Notam: Tr - timpul propriu de regie a comutatorului;
n - numarul de comutatoare;
Lsf - latenta pentru comutarea de pachete cu memorare si retransmitere (store and forward)
Obtinem: Tr + d/b secunde, latenta pentru un comutator.
Lsf Ta n(Tr + d/b) + d/b
Obs: ultimul termen d/b reprezinta timpul de transmisie a pachetului de la ultimul comutator la destinatie.
In cazul comutarii de pachete cu cale directa virtuala (virtual cut through) sau gaura de vierme (wormhole), nu se mai asteapta receptionarea intregului pachet, ci numai antetul ce contine adresa portului de destinatie si nu se mai face verificarea daca pachetul contine erori.
Notam: Tra - timpul propriu de regie a comutatorului pentru receptia antetului;
Lct - latenta pentru comutarea de pachete cu cale directa virtuala;
Obtinem: Lsf Ta nTra + d/b
Largimea de banda: reprezinta numarul de octeti transferati pe secunda. Exista mai multe metrici pentru largimea de banda:
largimea de banda a biscetiei: largimea de banda insumata a arcelor care leaga cele doua jumatati ale retelei;
largimea de banda totala (agregate bandwidth): calculata prin simpla insumare a largimilor de banda a tuturor legaturilor retelei si reprezinta numarul total de biti ce poate fi transferat prin retea la un moment dat.
Importanta este si largimea de banda la intrare si iesire a procesoarelor si memoriilor care trebuie sa se afle in stransa corelatie cu acea a legaturilor retelei.
Este de preferat o retea cu latenta mica, largime de banda mare si rata erorilor mica, deziderate greu de realizat avand in vedere antagonismul lor: latenta mica inseamna interfete cu buffere mici, comutatoare fara memorie si transfer de pachete scurte, dar avem dezavantajul ca informatia utila din pachet e redusa in comparatie cu informatia de control (campuri de adrese si coduri detectoare de erori) ceea ce face ca largimea de banda sa scada. O largime de banda mare presupune interfete cu buffere mari si transferul de pachete lungi, ceea ce creste latenta si rata erorilor.
In practica, este mai usor de crescut largimea de banda (cresterea numarului de biti transferati simultan pe canalele paralele sau canale seriale de viteza mai mare), dar este mult mai greu de redus latenta.
In cazul arhitecturilor paralele, metoda cea mai la indemana de crestere a performantei pare a fi cea de a mai adauga sistemului procesoare (CPU). Un sistem a carui performanta poate fi crescuta liniar (sau aproape liniar) prin adaugarea de procesoare (si memorie) se numeste scalabil. Scalabilitatea este dezideratul principal al arhitecturilor paralele. Vom analiza in continuare principalele implicatii ale scalabilitatii arhitecturilor paralele.
Sa presupunem ca vom scala un sistem de 4 procesoare conectate prin magistrala (o arhitectura destul de comuna a zilelor noastre) - Fig. 24(a) - la 16 procesoare conectate prin aceasi magistrala - fig. 24(b). Daca largimea de banda a magistralei este de b MBps, atunci scalarea sistemului a redus largimea de banda disponibila pentru un procesor de la b/4 la b/16. Avand in vedere scaderea largimii de banda, rezulta deci ca acest sistem nu este scalabil.
Daca realizam aceasi scalare, dar pentru un sistem cu retea grila de comutatoare asa cum se arata in Fig. 24(c) si (d), fara a se figura comutatoarele ci direct procesoarele. Observam ca pentru topologia grila adaugarea de procesoare presupune si adaugarea de legaturi, mai mult chiar, largimea de banda nu scade ci creste. Cauza: creste numarul de legaturi/procesor de la la
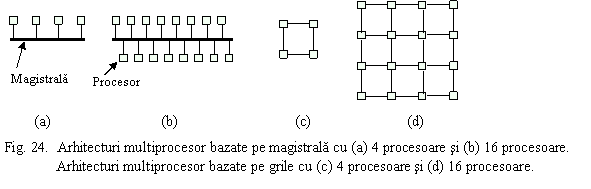
Dar trebuie sa analizam si celalalt aspect al performantei sistemelor paralele: latenta. In cazul sistemelor conectate prin magistrala, diametrul retelei nu creste prin scalare si deci nu creste nici latenta in cazul absentei traficului (in cazul traficului intens, latenta poate creste foarte mult datorita intarzierilor cu care un procesor poate obtine magistrala). In cazul grilei, scalarea conduce la cresterea diametrului retelei de la 2 la 6 si deci creste corespunzator si latenta. Pentru o grila cu N nxn noduri diametrul este 2(n-1), iar diametrul mediu este n (radical din numarul de procesoare).
Un sistem scalabil ideal ar trebui sa-si mentina largimea de banda medie pe procesor si latenta medie constanta, dar in practica desi este realizabila pastrarea largimii de banda si chiar cresterea ei, latenta in schimb creste cu dimensiunea, cresterea sa logaritmica, ca la topologia hipercub, este aproape tot ce se poate obtine. Exista desigur si topologia interconectarii complete la care dimensiunea ramane costanta 1, dar numarul de legaturi este prohibitiv de mare: N(N-1)/2, deocamdata imposibil de realizat pentru sisteme foarte mari.
Cresterea latentei poate fi acceptata pentru aplicatii care comunica rar (granularitate mare), dar este dezastroasa pentru aplicatii care schimba foarte des date si necesita multe sicronizari (garnularitate fina si medie). De aceea proiectantii de sisteme incearca, atunci cand nu reusesc sa reduca latenta, macar sa o ascunda.
Tehnici de reducere si ascundere a latentei
(1) Replicarea datelor: are doua aspecte
(a) Organizarea ierarhica a memoriilor fiecarui procesor (memorii cache pe 1, 2 sau 3 nivele asociate fiecarui procesor) asigura posibilitatea de a pastra blocuri date si instructiuni cat mai aproape de procesor, adica de locul in care sunt folosite. Organizarea ierarhica are la baza doua principii:
principiul localizarii spatiale: daca s-a executat o instructiune dintr-un bloc de cod, e foarte probabil ca vor fi executate si instructiunile urmatoare din acel bloc; acest lucru e valabil si pentru accesul la date, nu neaparat organizate in vectori sau matrici; in general programele au o organizare secventiala;
principiul localizarii temporale: o instructiune care a fost executata o data e probabil ca ea sa mai fie executata la momentele de timp urmatoare (sa faca parte dintr-o bucla sau dintr-o functie apelata mai des); si o data poate fi referita de mai multe ori.
In organizarea ierarhica, nivele de memorie au aspectul unei piramide: nivelele superioare, mai apropiate sau incluse in procesor, sunt mai rapide dar de dimensiune mai mica, iar nivelele inferioare, mai departate de procesor, sunt mai lente dar de dimensiuni mai mari. Fiecare nivel superior este un subset al nivelului imediat inferior, deci toate blocurile de date si instructiuni de pe nivelele superioare se gasesc obligatoriu si pe nivelele inferioare.
Nivelele superioare se numesc memorii intermediare (cache memory) si au o organizare asociativa: fiecare bloc are asociat un camp numit tinta (tag) ce reprezinta bitii superiori ai adresei de memorie ai blocului. Cautarea blocului in memoria cache se face dupa acest tag.
Replicarea datelor pe nivele intermediare presupune existenta unor politici (protocoale) pentru asigurarea coerentei datelor. Acesta presupune ca datele unui bloc replicat trebuie sa fie actuale: daca un alt procesor care detine o copie a acelorasi date le modifica, atunci trebuie sa difuzeze noile valori la toate celelalte procesoare care detin copii sau sa trimita semnale de invalidare a blocurilor modificate.
(a) Mentinerea mai multor copii echivalente, cu statut egal (diferit de statul secundar/primar din relatia asimetrica memorie cache / memorie principala). Plasarea acestor copii se poate face static (anticipat de programator sau compilator) sau dinamic prin politici speculative ale sistemului de operare. Si in acest caz, asigurarea coerentei copiilor este principala problema.
(2) Extragerea in avans (prefetching) a datelor ce se presupune ca urmeaza sa fie folosite. In cazul memoriilor cache se bazeaza pe principiul localizarii spatiale. In cazul memoriilor principale se pot baza pe politici speculative ale compilatoarelor sau ale sistemului de operare. Pentru pagini mari de memorie extragerea in avans poate fi costisitoare daca presupunerea nu se realizeaza.
(3) Utilizarea firelor de executie (multithreading): se bazeaza pe conceptul de multiprogramare ce permite executia pe acelasi procesor a mai multor sarcini (procese), relativ independente, prin divizarea timpului de executie (time slicing sau time sharing). Presupune mecanisme rapide de comutare a proceselor (pentru fiecare proces sistemul de operare creaza un context ce este salvat, cand procesul este dezactivat, si incarcat in procesor, cand procesul redevine activ). Un proces devine inactiv cand se blocheaza in asteptarea de date din retea sau din sistemul de intrare/iesire, sau cand i se epuizeaza cuanta de timp alocata.
(4) Utilizarea scrierilor neblocante: procesorul nu mai asteapta terminarea scrierii ci isi continua executia. Sarcina scrierii cade in sarcina controlorului memoriei cache. Scrierea poate fi executata imediat (write through) sau doar atunci cand blocul trebuie eliminat din memorie (write back) sau un alt procesor face acces la o copie a aceluiasi bloc de date. Si controlerul memoriei cache poate utiliza memorii tampon (buffere) pentru scriere pentru a nu pierde prea mult timp cu aceasta operatie.
1.4. Clasificarea arhitecturilor paralele
De-a lunugul timpului au fost propuse un mare numar de arhitecturi paralele, multe din ele au fost si realizate, chiar daca unele nu au depasit modelul experimental. Incercarile de a clasifica aceste sisteme nu au adus insa un sistem unanim recunoscut si nu a aparut inca o schema de clasificare sau notatie general acceptate. Astfel taxonomia Flynn (1972) este prea generala, cea lui Shore (1973) este depasita, iar sistemul de notatie a lui Hockney (1988) este prea complicat.
Vom prezenta in continuare taxonomia Flynn care, desi foarte generala, este totusi cea mai folosita. Dupa care vom incerca sa nuantam aceasta clasificare prin extinderea ei cu clasele mai vechi si mai noi de arhitecturi paralele.
Flynn nu si-a bazat clasificarea sa pe structura masinilor ci pe relatia instructiune de executat - date de prelucrat. Se definesc astfel fluxul de instructiuni si fluxul de date. Un flux (stream) de instructiuni este o sceventa de comenzi ce poate fi executata de un singur procesor si are asociat un singur contor de program. Un sistem cu n CPU are n contoare de program si deci n fluxuri de instructiuni. Un flux de date consta dintr-un set de operanzi.
Considerand fluxurile de instructiuni si fluxurile de date relativ independente, exista 4 combinatii ale lor (fig. 25). SISD (Single Instruction stream Single Data stream) este calculatorul von Neumann clasic, secvential, care cu o singura UCP nu poate face decat un singur lucru la un moment dat.
|
Fluxuri de instructiuni |
Fluxuri de date |
Nume |
Exemple |
|
SISD |
Masina von Neumann clasica |
||
|
Multiple |
SIMD |
Supercalculatoare vectoriale si matriciale |
|
|
Multiple |
MISD |
Practic nici unul |
|
|
Multiple |
Multiple |
MIMD |
Mutiprocesoare, multicalculatoare |
Fig. 25. Clasificarea Flynn a arhitecturilor paralele
Masinile SIMD (Single Instruction stream Multiple Data stream) au o singura unitate de control si mai multe unitati aritmetice ce pot executa simultan operatii pe mai multe seturi de date sub controlul unei singure instructiuni. In aceasta categorie intra procesoarele vectoriale si matriciale. Primul calculator din aceasta categorie a fost ILLIAC IV (sfarsitul anilor 1960), construit la Universitatea Illinois, el a fost urmat de sistemele comerciale Connection Machine CM-2, Hughes 3-D Computer si altele.
Masinile MISD (Multiple Instruction stream Single Data stream) - fluxuri multiple de instructiuni pe un singur flux de date este o clasa vida, deoarece implica executia simultana a mai multor instructiuni asupra aceluiasi operand. Flynn a mentionat ca include aici structurile specializate, dar nu a dat exemple. Altii incearca sa includa aici masinile in linie de asamblare (pipeline), dar realitatea contrazice acest rationament.
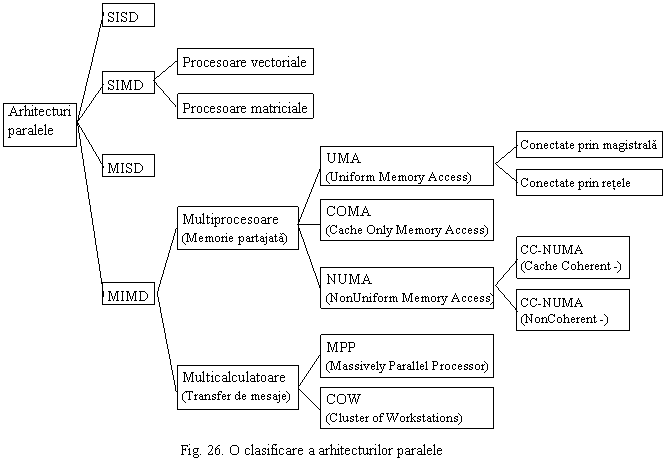
Masinile MIMD (Multiple Instruction stream Multiple Data stream) presupune mai multe CPU independente operand pe fluxuri proprii de date. In aceasta categorie intra atat multiprocesoarele (arhitecturi cu memorie partajata) cat si multicalculatoarele (arhitecturi cu transfer de mesaje). Figura 26 prezinta o clasificare extinsa a arhitecturilor paralele.
Se cunosc trei categorii de multiprocesoare (arhitecturi cu memorie partajata):
Multiprocesoare cu acces uniform la memorie (UMA - Uniform Memory Access): se mai numesc multiprocesoare simetrice (SMP - Symetrical Multiprocesor). In aceasta arhitectura mai multe procesoare partajeaza un spatiu de adrese comun. Timpul de acces la memoria partajata este acelasi pentru toate procesoarele. Acest lucru face performanta predictibila, factor important pentru scrierea de cod eficient. Exista o singura copie a sistemului de operare. Sunt conectate prin magistrale (scalabilitate pana la maxim 16 procesoare) sau prin retele (scalabilitate pana la maxim 64 procesoare). Fiecare procesor are asociata memorie cache pe 1, 2 sau 3 nivele. Principala problema - coerenta cache-urilor - este asigurata prin politici de supraveghere - spionare (snooping).
Multiprocesoare cu acces neuniform la memorie (NUMA - NonUniform Memory Access): si in aceasta arhitectura procesoarele partajeaza un singur spatiu de adrese, dar memoria este impartita fizic in mai multe module plasate fiecare in apropierea unui procesor sau grup de procesoare (pe aceasi placa). Timpul de acces la modulul de memorie din imediata vecinatate a procesorului este mult mai mic decat timpul de acces la module de memorie aflate la distanta. Sunt conectate prin retele, iar latenta este functie de dimensiunea retelei. Sunt mult mai scalabile (cu pretul platit latentei). Sunt impartite in doua subclase: cache-coerente si non-coerente.
Multiprocesoarele cu acces numai la cache (COMA - Cache Only Memory Access): sunt o categorie mai noua de multiprocesoare ce incearca sa combine avantajele masinilor UMA si NUMA printr-o plasare mai putin rigida a paginilor de memorie si transformarea memoriei principale intr-o memorie cache mare.
Multicalculatoarele (arhitecturi cu transfer de mesaje) nu au memorie partajata la nivel arhitectural (hardware), de aceea se mai numesc si arhitecturi fara acces la memorie la distanta (NORMA - NO Remote Memory Access). Multicalculatoarele se pot imparti aproximativ in doua categorii:
Procesoare masiv paralele (MPP - Massively Parallel Processor): sunt supercalculatoarele ce constau dintr-un numar foarte mare (uneori mii) de procesoare puternice (cu memorii cache pe 3 nivele si memorii private mari) conectate prin retele proprietare de foarte mare viteza. Sunt cele mai scumpe calculatoare de pe piata. Exemple: Cray T3E si IBM SP/2.
Grupuri de statii de lucru (Cluster of Workstations): sunt realizate cu componente de raft (off-shelf), adica din comert. Procesoarele, memoria, retelele de interconectare sunt disponible pe piata. De regula, totusi, arhitecturi UMA multiprocesor, dar acestea au devenit in ultimii ani produse comerciale destul de comune.
In sectiunile urmatoare vom analiza in detaliu principalele arhitecturi SIMD si MIMD prin prisma principiilor cheie de proiectare si operare.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 2653
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved