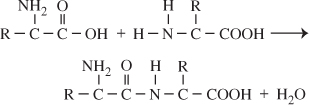| CATEGORII DOCUMENTE |
| Bulgara | Ceha slovaca | Croata | Engleza | Estona | Finlandeza | Franceza |
| Germana | Italiana | Letona | Lituaniana | Maghiara | Olandeza | Poloneza |
| Sarba | Slovena | Spaniola | Suedeza | Turca | Ucraineana |
|
Genetic Control of Protein Synthesis, Cell Function, and Cell Reproduction |
|
|
|
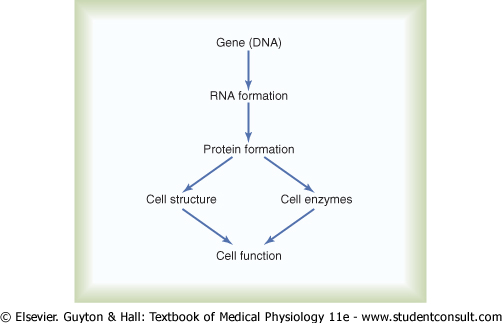
Figure 3-1 shows the general schema of genetic control. Each gene, which is a nucleic acid called deoxyribonucleic acid (DNA), automatically controls the formation of another nucleic acid, ribonucleic acid (RNA); this RNA then spreads throughout the cell to control the formation of a specific protein. Because there are more than 30,000 different genes in each cell, it is theoretically possible to form a very large number of different cellular proteins. |
|
Some of the cellular proteins are structural
proteins, which, in association with various lipids and carbohydrates,
form the structures of the various intracellular organelles discussed in Chapter
2. However, by far the majority of the proteins are enzymes that
catalyze the different chemical reactions in the cells. For instance, enzymes
promote all the oxidative reactions that supply energy to the cell, and they
promote synthesis of all the cell chemicals, such as lipids, glycogen, and adenosine |
|
Genes in the Cell Nucleus |
|
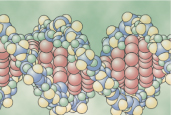
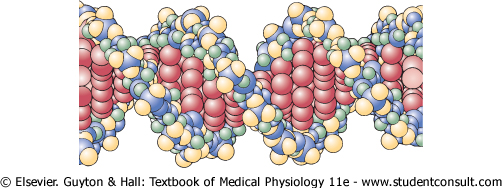
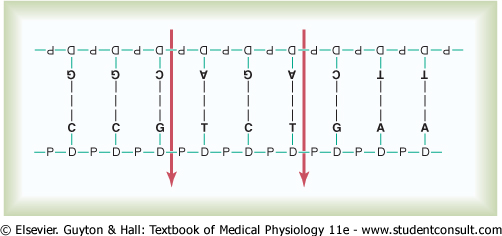
In the cell nucleus, large numbers of genes are attached end on end in extremely long double-stranded helical molecules of DNA having molecular weights measured in the billions. A very short segment of such a molecule is shown in Figure 3-2. This molecule is composed of several simple chemical compounds bound together in a regular pattern, details of which are explained in the next few paragraphs. |
|
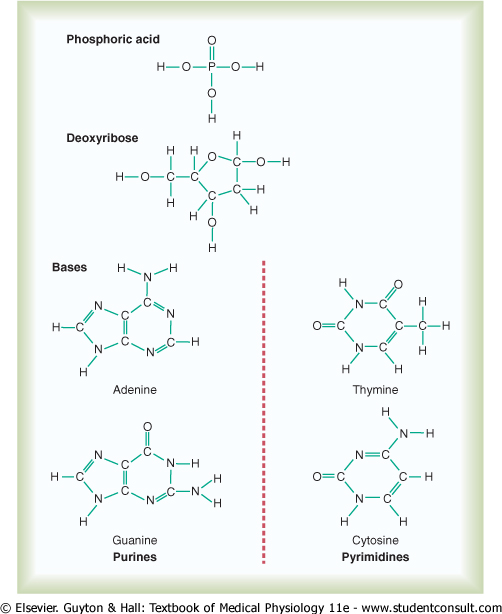
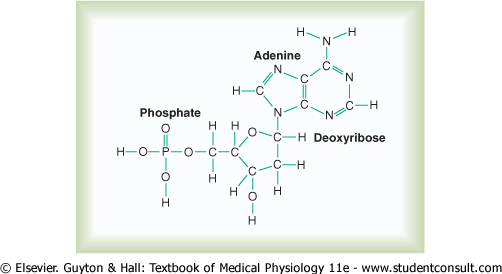
Basic Building Blocks of DNA. Figure 3-3 shows the basic chemical compounds involved in the formation of DNA. These include (1) phosphoric acid, (2) a sugar called deoxyribose, and (3) four nitrogenous bases (two purines, adenine and guanine, and two pyrimidines, thymine and cytosine). The phosphoric acid and deoxyribose form the two helical strands that are the backbone of the DNA molecule, and the nitrogenous bases lie between the two strands and connect them, as illustrated in Figure 3-6. |
|
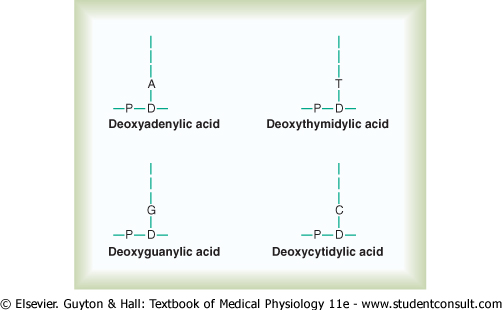
Nucleotides. The first stage in the formation of DNA is to combine one molecule of phosphoric acid, one molecule of deoxyribose, and one of the four bases to form an acidic nucleotide. Four separate nucleotides are thus formed, one for each of the four bases: deoxyadenylic, deoxythymidylic, deoxyguanylic, and deoxycytidylic acids. Figure 3-4 shows the chemical structure of deoxyadenylic acid, and Figure 3-5 shows simple symbols for the four nucleotides that form DNA. |
||||
|
||||
|
|
|
Figure 3-2 The helical, double-stranded structure of the gene. The outside strands are composed of phosphoric acid and the sugar deoxyribose. The internal molecules connecting the two strands of the helix are purine and pyrimidine bases; these determine the 'code' of the gene. |
|
|
|
|
|
Figure 3-3 The basic building blocks of DNA. |
|
page 28 |
|
|
|
page 29 |
|
||
|
|
|
Figure 3-4 Deoxyadenylic acid, one of the nucleotides that make up DNA. |
|
|||
|
|
|
Figure 3-5 Symbols for the four nucleotides that combine to form DNA. Each nucleotide contains phosphoric acid (P), deoxyribose (D), and one of the four nucleotide bases: A, adenine; T, thymine; G, guanine; or C, cytosine. |
|
||||||||||||||||||||||||
|
The DNA Code in the Cell Nucleus Is Transferred to an RNA Code in the Cell Cytoplasm-The Process of Transcription |
|
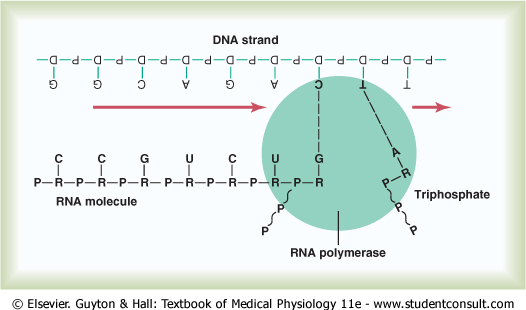
Because the DNA is located in the nucleus of the cell, yet most of the functions of the cell are carried out in the cytoplasm, there must be some means for the DNA genes of the nucleus to control the chemical reactions of the cytoplasm. This is achieved through the intermediary of another type of nucleic acid, RNA, the formation of which is controlled by the DNA of the nucleus. Thus, as shown in Figure 3-7, the code is transferred to the RNA; this process is called transcription. The RNA, in turn, diffuses from the nucleus through nuclear pores into the cytoplasmic compartment, where it controls protein synthesis. |
|
Synthesis of RNA |
|
During synthesis of RNA, the two strands of
the DNA molecule separate temporarily; one of these strands is used as a
template for synthesis of an RNA molecule. The code triplets in the DNA cause
formation of complementary code triplets (called codons) in the
RNA; these codons, in turn, will control the sequence of amino acids |
|
Basic Building Blocks of RNA. The basic building blocks of RNA are almost the same as those of DNA, except for two differences. First, the sugar deoxyribose is not used in the formation of RNA. In its place is another sugar of slightly different composition, ribose, containing an extra hydroxyl ion appended to the ribose ring structure. Second, thymine is replaced by another pyrimidine, uracil. |
|
page 30 |
|
|
|
page 31 |
|
Formation of RNA Nucleotides. The basic building blocks of RNA form RNA nucleotides, exactly as previously described for DNA synthesis. Here again, four separate nucleotides are used in the formation of RNA. These nucleotides contain the bases adenine, guanine, cytosine, and uracil. Note that these are the same bases as in DNA, except that uracil in RNA replaces thymine in DNA. |
|
'Activation' of the RNA Nucleotides. The next step in the synthesis of RNA is 'activation' of the RNA nucleotides by an enzyme, RNA polymerase. This occurs by adding to each nucleotide two extra phosphate radicals to form triphosphates (shown in Figure 3-7 by the two RNA nucleotides to the far right during RNA chain formation). These last two phosphates are combined with the nucleotide by high-energy phosphate bonds derived from ATP in the cell. |
|
The result of this activation process is that large quantities of ATP energy are made available to each of the nucleotides, and this energy is used to promote the chemical reactions that add each new RNA nucleotide at the end of the developing RNA chain. |
|
Assembly of the RNA Chain from Activated Nucleotides Using the
DNA |
|
Assembly of the RNA molecule is accomplished in the manner shown in Figure 3-7 under the influence of an enzyme, RNA polymerase. This is a large protein enzyme that has many functional properties necessary for formation of the RNA molecule. They are as follows:
|
|
Thus, the code that is present in the DNA strand is eventually transmitted in complementary form to the RNA chain. The ribose nucleotide bases always combine with the deoxyribose bases in the following combinations: |
|
DNA Base |
RNA Base |
|
guanine |
cytosine |
|
cytosine |
guanine |
|
adenine |
uracil |
|
thymine |
adenine |
|
Three Different Types of RNA. There are three different types of RNA, each of which plays an independent and entirely different role in protein formation:
|
|
Messenger RNA-The Codons |
|
Messenger RNA molecules are long,
single RNA strands that are suspended in the cytoplasm. These molecules are
composed of several hundred to several thousand RNA nucleotides in unpaired
strands, and they contain codons that are exactly complementary to the
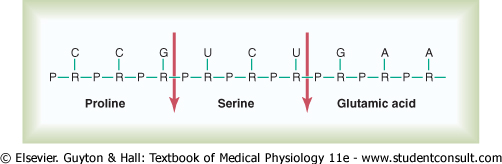
code triplets of the DNA genes. Figure 3-8 shows a small segment of a
molecule of messenger RNA. Its codons are CCG, UCU, and GAA. These are the
codons for the amino acids |
|
page 31 |
|
|
|
page 32 |
|
RNA Codons for the Different Amino Acids |
|
Transfer RNA-The Anticodons |
|
Another type of RNA that plays an essential
role in protein synthesis is called transfer RNA, because it transfers
amino acid molecules to protein molecules as the protein is being
synthesized. Each type of transfer RNA combines specifically with 1 of the 20
amino acids |
|
Transfer RNA, which contains only about 80 nucleotides, is a relatively small molecule in comparison with messenger RNA. It is a folded chain of nucleotides with a cloverleaf appearance similar to that shown in Figure 3-9. At one end of the molecule is always an adenylic acid; it is to this that the transported amino acid attaches at a hydroxyl group of the ribose in the adenylic acid. |
|
Table 3-1. RNA Codons for Amino Acids and for Start and Stop |
|
Amino Acid |
RNA |
Codons | ||||
|
Alanine |
GCU |
GCC |
GCA |
GCG | ||
|
Arginine |
CGU |
CGC |
CGA |
CGG |
AGA |
AGG |
|
Asparagine |
AAU |
AAC | ||||
|
Aspartic acid |
GAU |
GAC | ||||
|
Cysteine |
UGU |
UGC | ||||
|
Glutamic acid |
GAA |
GAG | ||||
|
Glutamine |
CAA |
CAG | ||||
|
Glycine |
GGU |
GGC |
GGA |
GGG | ||
|
Histidine |
CAU |
CAC | ||||
|
Isoleucine |
AUU |
AUC |
AUA | |||
|
Leucine |
CUU |
CUC |
CUA |
CUG |
UUA |
UUG |
|
Lysine |
AAA |
AAG | ||||
|
Methionine |
AUG | |||||
|
Phenylalanine |
UUU |
UUC | ||||
|
Proline |
CCU |
CCC |
CCA |
CCG | ||
|
Serine |
UCU |
UCC |
UCA |
UCG |
AGC |
AGU |
|
Threonine |
ACU |
ACC |
ACA |
ACG | ||
|
Tryptophan |
UGG | |||||
|
Tyrosine |
UAU |
UAC | ||||
|
Valine |
GUU |
GUC |
GUA |
GUG | ||
|
Start (CI) |
AUG | |||||
|
Stop (CT) |
UAA |
UAG |
UGA | |||
|
|
|
||
|
|
|
Figure 3-9 A messenger RNA strand is moving through two ribosomes. As each 'codon' passes through, an amino acid is added to the growing protein chain, which is shown in the right-hand ribosome. The transfer RNA molecule transports each specific amino acid to the newly forming protein. |
|
page 32 |
|
|
|
page 33 |
|
Because the function of transfer RNA is to
cause attachment of a specific amino acid to a forming protein chain, it is
essential that each type of transfer RNA also have specificity for a
particular codon in the messenger RNA. The specific code in the transfer RNA
that allows it to recognize a specific codon is again a triplet of nucleotide
bases and is called an anticodon. This is located approximately in the
middle of the transfer RNA molecule (at the bottom of the cloverleaf
configuration shown in Figure 3-9). During formation of the protein molecule,
the anticodon bases combine loosely by hydrogen bonding with the codon bases
of the messenger RNA. In this way, the respective amino acids |
|
Ribosomal RNA |
|
The third type of RNA in the cell is ribosomal RNA; it constitutes about 60 per cent of the ribosome. The remainder of the ribosome is protein, containing about 75 types of proteins that are both structural proteins and enzymes needed in the manufacture of protein molecules. |
|
The ribosome is the physical structure in the
cytoplasm on which protein molecules are actually synthesized. However, it
always functions in association with the other two types of RNA as well: transfer
RNA transports amino acids |
|
Thus, the ribosome acts as a manufacturing plant in which the protein molecules are formed. |
|
Formation of Ribosomes in the Nucleolus. The DNA genes for formation of ribosomal RNA are located in five pairs of chromosomes in the nucleus, and each of these chromosomes contains many duplicates of these particular genes because of the large amounts of ribosomal RNA required for cellular function. |
|
As the ribosomal RNA forms, it collects in the nucleolus, a specialized structure lying adjacent to the chromosomes. When large amounts of ribosomal RNA are being synthesized, as occurs in cells that manufacture large amounts of protein, the nucleolus is a large structure, whereas in cells that synthesize little protein, the nucleolus may not even be seen. Ribosomal RNA is specially processed in the nucleolus, where it binds with 'ribosomal proteins' to form granular condensation products that are primordial subunits of ribosomes. These subunits are then released from the nucleolus and transported through the large pores of the nuclear envelope to almost all parts of the cytoplasm. After the subunits enter the cytoplasm, they are assembled to form mature, functional ribosomes. Therefore, proteins are formed in the cytoplasm of the cell, but not in the cell nucleus, because the nucleus does not contain mature ribosomes. |
|
Formation of Proteins on the Ribosomes-The Process of 'Translation' |
|
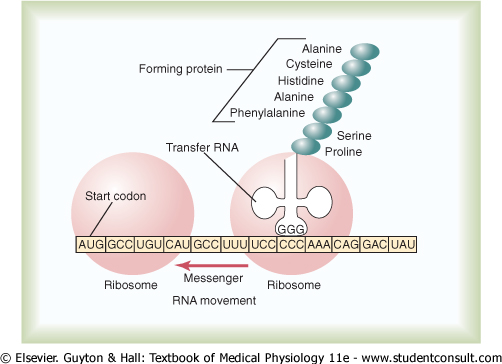
When a molecule of messenger RNA comes in contact with a ribosome, it travels through the ribosome, beginning at a predetermined end of the RNA molecule specified by an appropriate sequence of RNA bases called the 'chain-initiating' codon. Then, as shown in Figure 3-9, while the messenger RNA travels through the ribosome, a protein molecule is formed-a process called translation. Thus, the ribosome reads the codons of the messenger RNA in much the same way that a tape is 'read' as it passes through the playback head of a tape recorder. Then, when a 'stop' (or 'chain-terminating') codon slips past the ribosome, the end of a protein molecule is signaled and the protein molecule is freed into the cytoplasm. |
|
Polyribosomes. A single messenger RNA molecule can form protein molecules in several ribosomes at the same time because the initial end of the RNA strand can pass to a successive ribosome as it leaves the first, as shown at the bottom left in Figure 3-9 and in Figure 3-10. The protein molecules are in different stages of development in each ribosome. As a result, clusters of ribosomes frequently occur, 3 to 10 ribosomes being attached to a single messenger RNA at the same time. These clusters are called polyribosomes. |
|
It is especially important to note that a messenger RNA can cause the formation of a protein molecule in any ribosome; that is, there is no specificity of ribosomes for given types of protein. The ribosome is simply the physical manufacturing plant in which the chemical reactions take place. |
|
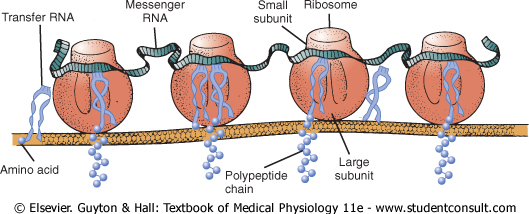
Many Ribosomes Attach to the Endoplasmic Reticulum. In Chapter 2, it was noted that many ribosomes become attached to the endoplasmic reticulum. This occurs because the initial ends of many forming protein molecules have amino acid sequences that immediately attach to specific receptor sites on the endoplasmic reticulum; this causes these molecules to penetrate the reticulum wall and enter the endoplasmic reticulum matrix. This gives a granular appearance to those portions of the reticulum where proteins are being formed and entering the matrix of the reticulum. |
|
Figure 3-10 shows the functional relation of messenger RNA to the ribosomes and the manner in which the ribosomes attach to the membrane of the endoplasmic reticulum. Note the process of translation occurring in several ribosomes at the same time in response to the same strand of messenger RNA. Note also the newly forming polypeptide (protein) chains passing through the endoplasmic reticulum membrane into the endoplasmic matrix. |
|
Yet it should be noted that except in glandular cells in which large amounts of protein-containing secretory vesicles are formed, most proteins synthesized by the ribosomes are released directly into the cytosol instead of into the endoplasmic reticulum. These proteins are enzymes and internal structural proteins of the cell. |
|
page 33 |
|
|
|
page 34 |
|
||
|
|
|
Figure 3-10 Physical
structure of the ribosomes, as well as their functional relation to messenger
RNA, transfer RNA, and the endoplasmic reticulum during the formation of
protein molecules. (Courtesy of Dr. Don W. |
|
||
|
|
|
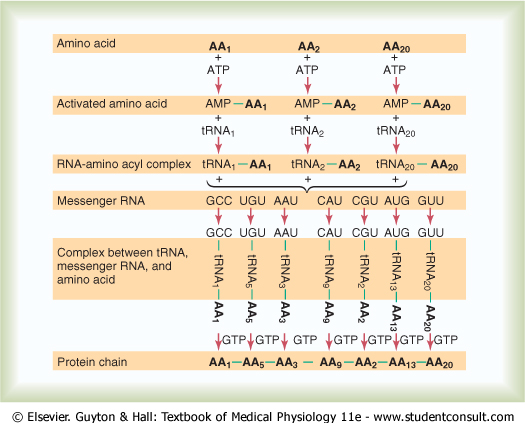
Figure 3-11 Chemical events in the formation of a protein molecule. |
|
Chemical Steps in Protein Synthesis. Some of the chemical
events that occur in synthesis of a protein molecule are shown in Figure 3-11.
This figure shows representative reactions for three separate amino acids |
|
Peptide Linkage. The successive amino
acids |
|
page 34 |
|
|
|
page 35 |
|
In this chemical reaction, a hydroxyl radical
( |
|
Synthesis of Other Substances in the Cell |
|
Many thousand protein enzymes formed in the manner just described control essentially all the other chemical reactions that take place in cells. These enzymes promote synthesis of lipids, glycogen, purines, pyrimidines, and hundreds of other substances. We discuss many of these synthetic processes in relation to carbohydrate, lipid, and protein metabolism in Chapters 67 through 69. It is by means of all these substances that the many functions of the cells are performed. |
|
Control of Gene Function and Biochemical Activity in Cells |
|
From our discussion thus far, it is clear that the genes control both the physical and the chemical functions of the cells. However, the degree of activation of respective genes must be controlled as well; otherwise, some parts of the cell might overgrow or some chemical reactions might overact until they kill the cell. Each cell has powerful internal feedback control mechanisms that keep the various functional operations of the cell in step with one another. For each gene (more than 30,000 genes in all), there is at least one such feedback mechanism. |
|
There are basically two methods by which the biochemical activities in the cell are controlled. One of these is genetic regulation, in which the degree of activation of the genes themselves is controlled, and the other is enzyme regulation, in which the activity levels of already formed enzymes in the cell are controlled. |
|
Genetic Regulation |
|
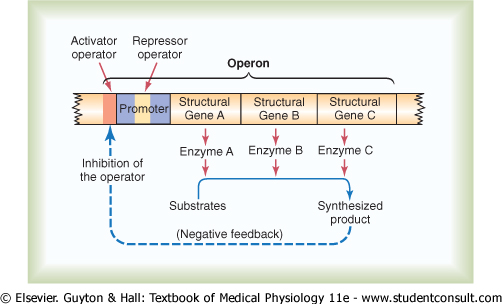
The 'Operon' of the Cell and Its Control of Biochemical Synthesis-Function of the Promoter. Synthesis of a cellular biochemical product usually requires a series of reactions, and each of these reactions is catalyzed by a special protein enzyme. Formation of all the enzymes needed for the synthetic process often is controlled by a sequence of genes located one after the other on the same chromosomal DNA strand. This area of the DNA strand is called an operon, and the genes responsible for forming the respective enzymes are called structural genes. In Figure 3-12, three respective structural genes are shown in an operon, and it is demonstrated that they control the formation of three respective enzymes that in turn cause synthesis of a specific intracellular product. |
|
Note in the figure the segment on the DNA strand called the promoter. This is a group of nucleotides that has specific affinity for RNA polymerase, as already discussed. The polymerase must bind with this promoter before it can begin traveling along the DNA strand to synthesize RNA. Therefore, the promoter is an essential element for activating the operon. |
|
||
|
|
|
Figure 3-12 Function of an operon to control synthesis of a nonprotein intracellular product, such as an intracellular metabolic chemical. Note that the synthesized product exerts negative feedback to inhibit the function of the operon, in this way automatically controlling the concentration of the product itself. |
|
page 35 |
|
page 36 |
|
Control of the Operon by a 'Repressor Protein'-The 'Repressor Operator.' Also note in Figure 3-12 an additional band of nucleotides lying in the middle of the promoter. This area is called a repressor operator because a 'regulatory' protein can bind here and prevent attachment of RNA polymerase to the promoter, thereby blocking transcription of the genes of this operon. Such a negative regulatory protein is called a repressor protein. |
|
Control of the Operon by an 'Activator Protein'-The 'Activator Operator.' Note in Figure 3-12 another operator, called the activator operator, that lies adjacent to but ahead of the promoter. When a regulatory protein binds to this operator, it helps attract the RNA polymerase to the promoter, in this way activating the operon. Therefore, a regulatory protein of this type is called an activator protein. |
|
Negative Feedback Control of the Operon. Finally, note in Figure 3-12 that the presence of a critical amount of a synthesized product in the cell can cause negative feedback inhibition of the operon that is responsible for its synthesis. It can do this either by causing a regulatory repressor protein to bind at the repressor operator or by causing a regulatory activator protein to break its bond with the activator operator. In either case, the operon becomes inhibited. Therefore, once the required synthesized product has become abundant enough for proper cell function, the operon becomes dormant. Conversely, when the synthesized product becomes degraded in the cell and its concentration decreases, the operon once again becomes active. In this way, the desired concentration of the product is controlled automatically. |
|
Other Mechanisms for Control of Transcription by the Operon. Variations in the basic mechanism for control of the operon have been discovered with rapidity in the past 2 decades. Without giving details, let us list some of them:
|
|
Because there are more than 30,000 different
genes in each human cell, the large number of ways in which genetic activity
can be controlled is not surprising. The gene control systems are especially
important for controlling intracellular concentrations of amino acids |
|
Control of Intracellular Function by Enzyme Regulation |
|
In addition to control of cell function by genetic regulation, some cell activities are controlled by intracellular inhibitors or activators that act directly on specific intracellular enzymes. Thus, enzyme regulation represents a second category of mechanisms by which cellular biochemical functions can be controlled. |
|
Enzyme Inhibition. Some chemical substances formed in the cell have direct feedback effects in inhibiting the specific enzyme systems that synthesize them. Almost always the synthesized product acts on the first enzyme in a sequence, rather than on the subsequent enzymes, usually binding directly with the enzyme and causing an allosteric conformational change that inactivates it. One can readily recognize the importance of inactivating the first enzyme: this prevents buildup of intermediary products that are not used. |
|
Enzyme inhibition is another example of negative feedback control; it is responsible for controlling intracellular concentrations of multiple amino acids, purines, pyrimidines, vitamins, and other substances. |
|
page 36 |
|
page 37 |
|
Enzyme Activation. Enzymes that are normally inactive often can be activated when needed. An example of this occurs when most of the ATP has been depleted in a cell. In this case, a considerable amount of cyclic adenosine monophosphate (cAMP) begins to be formed as a breakdown product of the ATP; the presence of this cAMP, in turn, immediately activates the glycogen-splitting enzyme phosphorylase, liberating glucose molecules that are rapidly metabolized and their energy used for replenishment of the ATP stores. Thus, cAMP acts as an enzyme activator for the enzyme phosphorylase and thereby helps control intracellular ATP concentration. |
|
Another interesting instance of both enzyme inhibition and enzyme activation occurs in the formation of the purines and pyrimidines. These substances are needed by the cell in approximately equal quantities for formation of DNA and RNA. When purines are formed, they inhibit the enzymes that are required for formation of additional purines. However, they activate the enzymes for formation of pyrimidines. Conversely, the pyrimidines inhibit their own enzymes but activate the purine enzymes. In this way, there is continual cross-feed between the synthesizing systems for these two substances, resulting in almost exactly equal amounts of the two substances in the cells at all times. |
|
Summary. In summary, there are two principal methods by which cells control proper proportions and proper quantities of different cellular constituents: (1) the mechanism of genetic regulation and (2) the mechanism of enzyme regulation. The genes can be either activated or inhibited, and likewise, the enzyme systems can be either activated or inhibited. These regulatory mechanisms most often function as feedback control systems that continually monitor the cell's biochemical composition and make corrections as needed. But on occasion, substances from without the cell (especially some of the hormones discussed throughout this text) also control the intracellular biochemical reactions by activating or inhibiting one or more of the intracellular control systems. |
|
The DNA-Genetic System Also Controls Cell Reproduction |
|
Cell reproduction is another example of the ubiquitous role that the DNA-genetic system plays in all life processes. The genes and their regulatory mechanisms determine the growth characteristics of the cells and also when or whether these cells will divide to form new cells. In this way, the all-important genetic system controls each stage in the development of the human being, from the single-cell fertilized ovum to the whole functioning body. Thus, if there is any central theme to life, it is the DNA-genetic system. |
|
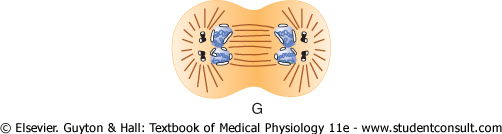
Life Cycle of the Cell. The life cycle of a cell is the period from cell reproduction to the next cell reproduction. When mammalian cells are not inhibited and are reproducing as rapidly as they can, this life cycle may be as little as 10 to 30 hours. It is terminated by a series of distinct physical events called mitosis that cause division of the cell into two new daughter cells. The events of mitosis are shown in Figure 3-13 and are described later. The actual stage of mitosis, however, lasts for only about 30 minutes, so that more than 95 per cent of the life cycle of even rapidly reproducing cells is represented by the interval between mitosis, called interphase. |
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
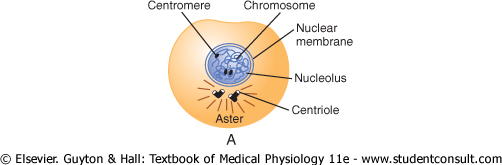
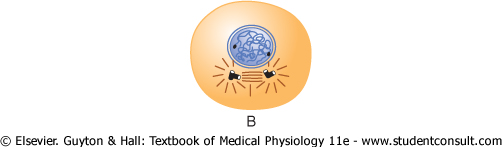
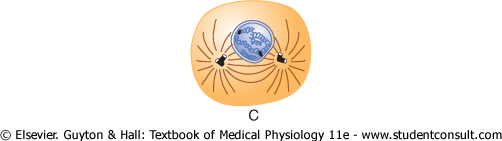
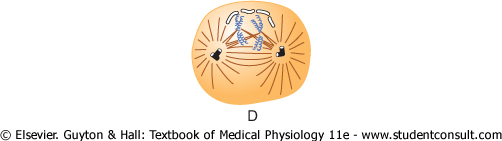
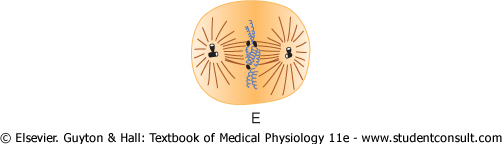
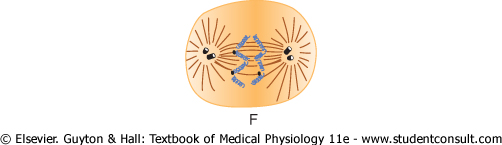
Figure 3-13 Stages of
cell reproduction. A, B, and C, Prophase. D,
Prometaphase. E, Metaphase. F, Anaphase. G and H,
Telophase. (From Margaret C. Gladbach, Estate of Mary E. and Dan Todd, |
|
Except in special conditions of rapid cellular reproduction, inhibitory factors almost always slow or stop the uninhibited life cycle of the cell. Therefore, different cells of the body actually have life cycle periods that vary from as little as 10 hours for highly stimulated bone marrow cells to an entire lifetime of the human body for most nerve cells. |
|
Cell Reproduction Begins with Replication of DNA |
|
As is true of almost all other important events in the cell, reproduction begins in the nucleus itself. The first step is replication (duplication) of all DNA in the chromosomes. Only after this has occurred can mitosis take place. |
|
page 37 |
|
|
|
page 38 |
|
The DNA begins to be duplicated some 5 to 10 hours before mitosis, and this is completed in 4 to 8 hours. The net result is two exact replicas of all DNA. These replicas become the DNA in the two new daughter cells that will be formed at mitosis. After replication of the DNA, there is another period of 1 to 2 hours before mitosis begins abruptly. Even during this period, preliminary changes are beginning to take place that will lead to the mitotic process. |
|
Chemical and Physical Events of DNA Replication. DNA is replicated in much the same way that RNA is transcribed in response to DNA, except for a few important differences:
|
|
DNA Repair, DNA 'Proofreading,' and 'Mutation.' During the hour or so between DNA replication and the beginning of mitosis, there is a period of very active repair and 'proofreading' of the DNA strands. That is, wherever inappropriate DNA nucleotides have been matched up with the nucleotides of the original template strand, special enzymes cut out the defective areas and replace these with appropriate complementary nucleotides. This is achieved by the same DNA polymerases and DNA ligases that are used in replication. This repair process is referred to as DNA proofreading. |
|
Because of repair and proofreading, the transcription process rarely makes a mistake. But when a mistake is made, this is called a mutation. The mutation causes formation of some abnormal protein in the cell rather than a needed protein, often leading to abnormal cellular function and sometimes even cell death. Yet, given that there are 30,000 or more genes in the human genome and that the period from one human generation to another is about 30 years, one would expect as many as 10 or many more mutations in the passage of the genome from parent to child. As a further protection, however, each human genome is represented by two separate sets of chromosomes with almost identical genes. Therefore, one functional gene of each pair is almost always available to the child despite mutations. |
|
Chromosomes and Their Replication |
|
The DNA helixes of the nucleus are packaged in chromosomes. The human cell contains 46 chromosomes arranged in 23 pairs. Most of the genes in the two chromosomes of each pair are identical or almost identical to each other, so it is usually stated that the different genes also exist in pairs, although occasionally this is not the case. |
|
In addition to DNA in the chromosome, there is a large amount of protein in the chromosome, composed mainly of many small molecules of electropositively charged histones. The histones are organized into vast numbers of small, bobbin-like cores. Small segments of each DNA helix are coiled sequentially around one core after another. |
|
|
|
|
||||||||
|
|
|
|
||||||||
|
|
|
|
|
|
|
The histone cores play an important role in the regulation of DNA activity because as long as the DNA is packaged tightly, it cannot function as a template for either the formation of RNA or the replication of new DNA. Further, some of the regulatory proteins have been shown to decondense the histone packaging of the DNA and to allow small segments at a time to form RNA. |
|
Several nonhistone proteins are also major components of chromosomes, functioning both as chromosomal structural proteins and, in connection with the genetic regulatory machinery, as activators, inhibitors, and enzymes. |
|
Replication of the chromosomes in their entirety occurs during the next few minutes after replication of the DNA helixes has been completed; the new DNA helixes collect new protein molecules as needed. The two newly formed chromosomes remain attached to each other (until time for mitosis) at a point called the centromere located near their center. These duplicated but still attached chromosomes are called chromatids. |
|
Cell Mitosis |
|
The actual process by which the cell splits into two new cells is called mitosis. Once each chromosome has been replicated to form the two chromatids, in many cells, mitosis follows automatically within 1 or 2 hours. |
|
page 38 |
|
|
|
page 39 |
|
Mitotic Apparatus: Function of the Centrioles. One of the first events of mitosis takes place in the cytoplasm, occurring during the latter part of interphase in or around the small structures called centrioles. As shown in Figure 3-13, two pairs of centrioles lie close to each other near one pole of the nucleus. (These centrioles, like the DNA and chromosomes, were also replicated during interphase, usually shortly before replication of the DNA.) Each centriole is a small cylindrical body about 0.4 micrometer long and about 0.15 micrometer in diameter, consisting mainly of nine parallel tubular structures arranged in the form of a cylinder. The two centrioles of each pair lie at right angles to each other. Each pair of centrioles, along with attached pericentriolar material, is called a centrosome. |
|
Shortly before mitosis is to take place, the two pairs of centrioles begin to move apart from each other. This is caused by polymerization of protein microtubules growing between the respective centriole pairs and actually pushing them apart. At the same time, other microtubules grow radially away from each of the centriole pairs, forming a spiny star, called the aster, in each end of the cell. Some of the spines of the aster penetrate the nuclear membrane and help separate the two sets of chromatids during mitosis. The complex of microtubules extending between the two new centriole pairs is called the spindle, and the entire set of microtubules plus the two pairs of centrioles is called the mitotic apparatus. |
|
Prophase. The first stage of mitosis, called prophase, is shown in Figure 3-13A, B, and C. While the spindle is forming, the chromosomes of the nucleus (which in interphase consist of loosely coiled strands) become condensed into well-defined chromosomes. |
|
Prometaphase. During this stage (see Figure 3-13D), the growing microtubular spines of the aster fragment the nuclear envelope. At the same time, multiple microtubules from the aster attach to the chromatids at the centromeres, where the paired chromatids are still bound to each other; the tubules then pull one chromatid of each pair toward one cellular pole and its partner toward the opposite pole. |
|
Metaphase. During metaphase (see Figure 3-13E), the two asters of the mitotic apparatus are pushed farther apart. This is believed to occur because the microtubular spines from the two asters, where they interdigitate with each other to form the mitotic spindle, actually push each other away. There is reason to believe that minute contractile protein molecules called 'motor molecules,' perhaps composed of the muscle protein actin, extend between the respective spines and, using a stepping action as in muscle, actively slide the spines in a reverse direction along each other. Simultaneously, the chromatids are pulled tightly by their attached microtubules to the very center of the cell, lining up to form the equatorial plate of the mitotic spindle. |
|
Anaphase. During this phase (see Figure 3-13F), the two chromatids of each chromosome are pulled apart at the centromere. All 46 pairs of chromatids are separated, forming two separate sets of 46 daughter chromosomes. One of these sets is pulled toward one mitotic aster and the other toward the other aster as the two respective poles of the dividing cell are pushed still farther apart. |
|
Telophase. In telophase (see Figure 3-13G and H), the two sets of daughter chromosomes are pushed completely apart. Then the mitotic apparatus dissolutes, and a new nuclear membrane develops around each set of chromosomes. This membrane is formed from portions of the endoplasmic reticulum that are already present in the cytoplasm. Shortly thereafter, the cell pinches in two, midway between the two nuclei. This is caused by formation of a contractile ring of microfilaments composed of actin and probably myosin (the two contractile proteins of muscle) at the juncture of the newly developing cells that pinches them off from each other. |
|
Control of Cell Growth and Cell Reproduction |
|
We know that certain cells grow and reproduce all the time, such as the blood-forming cells of the bone marrow, the germinal layers of the skin, and the epithelium of the gut. Many other cells, however, such as smooth muscle cells, may not reproduce for many years. A few cells, such as the neurons and most striated muscle cells, do not reproduce during the entire life of a person, except during the original period of fetal life. |
|
In certain tissues, an insufficiency of some types of cells causes these to grow and reproduce rapidly until appropriate numbers of them are again available. For instance, in some young animals, seven eighths of the liver can be removed surgically, and the cells of the remaining one eighth will grow and divide until the liver mass returns almost to normal. The same occurs for many glandular cells and most cells of the bone marrow, subcutaneous tissue, intestinal epithelium, and almost any other tissue except highly differentiated cells such as nerve and muscle cells. |
|
We know little about the mechanisms that maintain proper numbers of the different types of cells in the body. However, experiments have shown at least three ways in which growth can be controlled. First, growth often is controlled by growth factors that come from other parts of the body. Some of these circulate in the blood, but others originate in adjacent tissues. For instance, the epithelial cells of some glands, such as the pancreas, fail to grow without a growth factor from the sublying connective tissue of the gland. Second, most normal cells stop growing when they have run out of space for growth. This occurs when cells are grown in tissue culture; the cells grow until they contact a solid object, and then growth stops. Third, cells grown in tissue culture often stop growing when minute amounts of their own secretions are allowed to collect in the culture medium. This, too, could provide a means for negative feedback control of growth. |
|
page 39 |
|
|
|
page 40 |
|
Regulation of Cell Size. Cell size is
determined almost entirely by the amount of functioning DNA in the nucleus.
If replication of the DNA does not occur, the cell grows to a certain size
and thereafter remains at that size. Conversely, it is possible, by use of
the chemical colchicine |
|
Cell Differentiation |
|
A special characteristic of cell growth and cell division is cell differentiation, which refers to changes in physical and functional properties of cells as they proliferate in the embryo to form the different bodily structures and organs. The description of an especially interesting experiment that helps explain these processes follows. |
|
When the nucleus from an intestinal mucosal cell of a frog is surgically implanted into a frog ovum from which the original ovum nucleus was removed, the result is often the formation of a normal frog. This demonstrates that even the intestinal mucosal cell, which is a well-differentiated cell, carries all the necessary genetic information for development of all structures required in the frog's body. |
|
Therefore, it has become clear that differentiation results not from loss of genes but from selective repression of different genetic operons. In fact, electron micrographs suggest that some segments of DNA helixes wound around histone cores become so condensed that they no longer uncoil to form RNA molecules. One explanation for this is as follows: It has been supposed that the cellular genome begins at a certain stage of cell differentiation to produce a regulatory protein that forever after represses a select group of genes. Therefore, the repressed genes never function again. Regardless of the mechanism, mature human cells produce a maximum of about 8000 to 10,000 proteins rather than the potential 30,000 or more if all genes were active. |
|
Embryological experiments show that certain cells in an embryo control differentiation of adjacent cells. For instance, the primordial chorda-mesoderm is called the primary organizer of the embryo because it forms a focus around which the rest of the embryo develops. It differentiates into a mesodermal axis that contains segmentally arranged somites and, as a result of inductions in the surrounding tissues, causes formation of essentially all the organs of the body. |
|
Another instance of induction occurs when the developing eye vesicles come in contact with the ectoderm of the head and cause the ectoderm to thicken into a lens plate that folds inward to form the lens of the eye. Therefore, a large share of the embryo develops as a result of such inductions, one part of the body affecting another part, and this part affecting still other parts. |
|
Thus, although our understanding of cell differentiation is still hazy, we know many control mechanisms by which differentiation could occur. |
|
Apoptosis-Programmed Cell Death |
|
The 100 trillion cells of the body are members of a highly organized community in which the total number of cells is regulated not only by controlling the rate of cell division but also by controlling the rate of cell death. When cells are no longer needed or become a threat to the organism, they undergo a suicidal programmed cell death, or apoptosis. This process involves a specific proteolytic cascade that causes the cell to shrink and condense, to disassemble its cytoskeleton, and to alter its cell surface so that a neighboring phagocytic cell, such as a macrophage, can attach to the cell membrane and digest the cell. |
|
In contrast to programmed death, cells that die as a result of an acute injury usually swell and burst due to loss of cell membrane integrity, a process called cell necrosis. Necrotic cells may spill their contents, causing inflammation and injury to neighboring cells. Apoptosis, however, is an orderly cell death that results in disassembly and phagocytosis of the cell before any leakage of its contents occurs, and neighboring cells usually remain healthy. |
|
Apoptosis is initiated by activation of a family of proteases called caspases. These are enzymes that are synthesized and stored in the cell as inactive procaspases. The mechanisms of activation of caspases are complex, but once activated, the enzymes cleave and activate other procaspases, triggering a cascade that rapidly breaks down proteins within the cell. The cell thus dismantles itself, and its remains are rapidly digested by neighboring phagocytic cells. |
|
A tremendous amount of apoptosis occurs in tissues that are being remodeled during development. Even in adult humans, billions of cells die each hour in tissues such as the intestine and bone marrow and are replaced by new cells. Programmed cell death, however, is precisely balanced with the formation of new cells in healthy adults. Otherwise, the body's tissues would shrink or grow excessively. Recent studies suggest that abnormalities of apoptosis may play a key role in neurodegenerative diseases such as Alzheimer's disease, as well as in cancer and autoimmune disorders. Some drugs that have been used successfully for chemotherapy appear to induce apoptosis in cancer cells. |
|
Cancer |
|
page 40 |
|
|
|
page 41 |
|
Cancer is caused in all or almost all instances by mutation or by some other abnormal activation of cellular genes that control cell growth and cell mitosis. The abnormal genes are called oncogenes. As many as 100 different oncogenes have been discovered. |
|
Also present in all cells are antioncogenes, which suppress the activation of specific oncogenes. Therefore, loss of or inactivation of antioncogenes can allow activation of oncogenes that lead to cancer. |
|
Only a minute fraction of the cells that mutate in the body ever lead to cancer. There are several reasons for this. First, most mutated cells have less survival capability than normal cells and simply die. Second, only a few of the mutated cells that do survive become cancerous, because even most mutated cells still have normal feedback controls that prevent excessive growth. |
|
Third, those cells that are potentially cancerous are often, if not usually, destroyed by the body's immune system before they grow into a cancer. This occurs in the following way: Most mutated cells form abnormal proteins within their cell bodies because of their altered genes, and these proteins activate the body's immune system, causing it to form antibodies or sensitized lymphocytes that react against the cancerous cells, destroying them. In support of this is the fact that in people whose immune systems have been suppressed, such as in those taking immunosuppressant drugs after kidney or heart transplantation, the probability of a cancer's developing is multiplied as much as fivefold. |
|
Fourth, usually several different activated oncogenes are required simultaneously to cause a cancer. For instance, one such gene might promote rapid reproduction of a cell line, but no cancer occurs because there is not a simultaneous mutant gene to form the needed blood vessels. |
|
But what is it that causes the altered genes? Considering that many trillions of new cells are formed each year in humans, a better question might be, Why is it that all of us do not develop millions or billions of mutant cancerous cells? The answer is the incredible precision with which DNA chromosomal strands are replicated in each cell before mitosis can take place, and also the proofreading process that cuts and repairs any abnormal DNA strand before the mitotic process is allowed to proceed. Yet, despite all these inherited cellular precautions, probably one newly formed cell in every few million still has significant mutant characteristics. |
|
Thus, chance alone is all that is required for mutations to take place, so we can suppose that a large number of cancers are merely the result of an unlucky occurrence. |
|
However, the probability of mutations can be increased manyfold when a person is exposed to certain chemical, physical, or biological factors, including the following:
|
|
Invasive Characteristic of the Cancer Cell. The major differences between the cancer cell and the normal cell are the following: (1) The cancer cell does not respect usual cellular growth limits; the reason for this is that these cells presumably do not require all the same growth factors that are necessary to cause growth of normal cells. (2) Cancer cells often are far less adhesive to one another than are normal cells. Therefore, they have a tendency to wander through the tissues, to enter the blood stream, and to be transported all through the body, where they form nidi for numerous new cancerous growths. (3) Some cancers also produce angiogenic factors that cause many new blood vessels to grow into the cancer, thus supplying the nutrients required for cancer growth. |
|
page 41 |
|
|
|
page 42 |
|
Why Do Cancer Cells Kill? The answer to this question usually is simple. Cancer tissue competes with normal tissues for nutrients. Because cancer cells continue to proliferate indefinitely, their number multiplying day by day, cancer cells soon demand essentially all the nutrition available to the body or to an essential part of the body. As a result, normal tissues gradually suffer nutritive death. |
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 6911
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved