| CATEGORII DOCUMENTE |
| Aeronautica | Comunicatii | Electronica electricitate | Merceologie | Tehnica mecanica |
Coduri utilizate in transmisia datelor
1. Cod. Clase de coduri
2. Codare optimala
3. Exemple de coduri utilizate in compresia datelor
3.1. Codarea Huffmann
3.2. Codarea Shannon Fano
3.3. Codarea aritmetica
3.4. Codare statica vs. codare dinamica
1. Cod. Clase de coduri
Un cod C al unei surse informationale X se defineste ca fiind o mapare a simbolurilor alfabetului al sursei in siruri de lungime finita formate din simboluri ale unui alfabet . Se noteaza cu C(x) cuvantul de cod corespunzator lui x si cu l(x) lungimea cuvantului de cod C(x). De exemplu C(Red)=00 si C(Blue)=11 este un cod cu alfabetul = pentru sursa informationala avand alfabetul = . Se mai noteaza cu D numarul de simboluri al alfabetului .
Pentru a face posibila operatia de decodare (maparea inversa → ) este necesara impunerea unor constrangeri codurilor utilizate.
Definitia 1
Un cod se numeste nesingular daca fiecare simbol al alfabetului sursei este mapat intr-un sir unic format din simboluri ale alfabetului , adica
![]() (1)
(1)
Nesingularitatea asigura o descriere lipsita de ambiguitati a unui singur simbol emis de sursa. Dar de obicei sursa emite o secventa de simboluri. Doua solutii simple de rezolvare a problemei decodarii corecte a secventelor de cuvinte de cod sunt:
utilizarea codurilor de separare
presupune utilizarea unui cuvant de cod special, desemnat sa indice terminarea unui cuvant de cod si startul urmatorului cuvant de cod;
utilizarea codurilor bloc
presupune asignarea de cuvinte de cod de lungime egala, astfel incat decodorul recunoaste sfarsitul unui cuvant de cod doar prin numararea simbolurilor primite;
O alta abordare urmareste utilizarea unor cuvinte de cod care sa permita decodorului recunoasterea lor imediata. Pentru aceasta sunt necesare restrictii suplimentare aplicate codurilor.
O extensie C* a unui cod C este o mapare a sirurilor de lungime finita formate cu simboluri ale alfabetului in siruri de lungime finita formate cu simboluri ale alfabetului D definita prin:
![]() (2)
(2)
unde C(x1) C(x2)∙∙∙ C(xn) este concatenarea cuvintelor de cod. De exemplu pentru C(x1)=00 si C(x2)=11 se obtine C(x1 x2)=0011.
Definitia 2
Un cod este unic decodabil daca extensia sa este nesingulara.
Codurile unic decodabile permit decodarea corecta a secventelor de simboluri insa pot necesita analizarea intregii secvente de cod pentru decodarea unui simbol.
Definitia 3
Un cod se numeste prefixat sau instantaneu daca nici un cuvant de cod nu este prefixul altui cuvant de cod.
Codurile prefixate pot fi decodate fara analizarea cuvintelor de cod urmatoare deoarece sfarsitul unui cuvant de cod este recunoscut imediat.
Relatia intre categoriile de coduri descrise de definitiile 1, 2 si 3 este reprezentata in fig. 1:
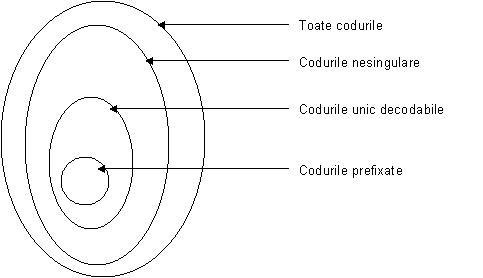
Figura 1. Clase de coduri
Pentru a ilustra diferentele dintre clasele de coduri descrise mai sus sa consideram exemplul din tabelul 1:
|
X |
Cod singular |
Cod nesingular, dar nici unic decodabil |
Cod unic decodabil, dar nu prefixat |
Cod instantaneu |
|
10 |
0 |
|||
|
010 |
00 |
10 |
||
|
01 |
11 |
110 |
||
|
10 |
110 |
111 |
Tabelul 1. Exemple de coduri
Pentru codul nesingular secventa de cod 010 are trei surse posibile (1,4;2;3,1) si prin urmare nu este unic decodabil.
Codul unic decodabil din exemplu nu este prefixat si deci nici instantaneu. Pentru a testa ca este unic decodabil se considera orice secventa de cod si se porneste de la inceput. Daca primii doi biti sunt 00 sau 10 atunci ei pot fi decodati imediat. Daca primii doi biti sunt 11 atunci trebuie analizati si bitii urmatori. Daca urmatorul bit este 1 atunci simbolul emis este 3. Daca urmeaza o secventa de zerouri atunci in functie de numarul lor, par sau impar, se interpreteaza simbolul ca fiind 3, respectiv 4.
2. Codare optimala
In codarea optimala canalul de transmisie se presupune a fi ideal. Astfel, se urmareste gasirea unor coduri care sa minimizeze numarul de simboluri ce trebuiesc trimise, bineinteles tinandu-se cont de discutia de mai sus. Problema devine gasirea unor coduri care sa realizeze compresia secventelor emise de sursa.
Lungimea medie a unui cod C se noteaza cu L(C) si este data de relatia:
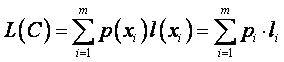 (
(
In contextul compresiei se doreste construirea unui cod prefixat ce minimizeaza L(C). Este evident ca nu se pot atribui cuvinte de cod scurte tuturor simbolurilor emise de sursa, simultan cu pastrarea proprietatii de prefixare. Seturile de lungimi de cod cu care se pot forma coduri prefixate sunt limitate de
Inegalitatea Lui Kraft
Pentru orice cod prefixat, cu un alfabet de dimensiune D, lungimile cuvintelor de cod l1, l2, , lm satisfac inegalitatea:
![]()
Reciproc, dat fiind un set de lungimi de cod care satisfac inegalitatea (4) exista un cod prefixat cu aceste lungimi.
Problema gasirii unui cod care sa ofere cea mai buna compresie poate fi acum formulata in termeni matematici sub forma unei probleme clasice de optimizare:
Sa
se gaseasca secventa de numere intregi li,
i=1m, care minimizeaza 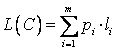 in restrictiile
in restrictiile ![]()
Renuntand intr-o prima faza la conditia ca li sa fie intregi, prin rezolvarea problemei de optimizare se obtine setul optim de lungimi de cuvinte de cod
![]() (5)
(5)
Aceasta alegere de lungimi (neintregi) ofera lungimea medie minima:
![]() . (6)
. (6)
Dar deoarece li trebuie sa fie intregi nu este intotdeauna posibila gasirea unui set intreg de lungimi de cuvinte de cod conform relatiei (5). Teorema codarii fara pierderi arata ca orice alta alegere a setului li este suboptimala si ca entropia este cea mai mica lungime medie posibila:
Teorema codarii fara pierderi
Lungimea medie a oricarui cod prefixat, avand un alfabet de dimensiune D si lungimile cuvintelor de cod li, pentru o sursa informationala X, este mai mare sau egala cu entropia HD(X), adica
![]()
cu egalitate
doar in cazul in care ![]() .
.
Un cod care ofera o lungime medie departata cu cel mult un bit fata de limita inferioara se poate obtine rotunjind superior lungimile cuvintelor de cod propuse de relatia (5):
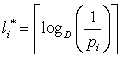 , (8)
, (8)
unde xù este cel mai mic intreg mai mare sau egal cu x. Setul de lungimi astfel calculat satisface inegalitatea lui Kraft
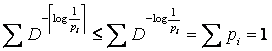 (9)
(9)
si asigura
![]() (10)
(10)
Inmultind (9) cu pi si sumand dupa i se obtine
![]() (11)
(11)
Cum un cod optimal nu poate fi decat mai bun decat codul descris mai sus si cum limita inferioara este entropia se poate spune ca lungimea medie a unui cod optimal (L*) satisface inegalitatea (12):
![]() (12)
(12)
Depasirea de maxim un bit datorata faptului ca lungimile optime nu sunt mereu intregi poate fi redusa prin distribuire pe mai multe simboluri. Acest lucru e posibil prin considerarea unei secvente (x1, x2, , xn) ca formand un supersimbol din alfabetul Xn, unde X este alfabetul sursei. Definim lungimea medie per simbol ca fiind
![]() (13)
(13)
Aplicand limitarile de mai sus putem scrie
![]() (14)
(14)
Admitand ipoteza ca X1, X2, , Xn sunt independente si identic distribuite, deci ca H(X1, X2, , Xn)= ∑H(Xi)=n H(X) se obtine
![]() (15)
(15)
Prin impartire cu n rezulta
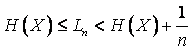 (16)
(16)
Astfel, prin alegerea unor secvente mari se poate obtine o lungime medie arbitrar de apropiata de entropie.
Ca masura a calitatii unui cod se utilizeaza eficienta definita ca raportul dintre entropia sursei si lungimea medie a cuvintelor de cod:
![]() (17)
(17)
Analizand din punctul de vedere al eficientei introduse mai sus se observa ca doar codurile instantanee se pot apropia de eficienta maxima. Codurile de separare platesc utilizarea unui cuvant de cod separator, iar codurile bloc pot atinge eficienta 1 doar daca simbolurile emisa de sursa sunt echiprobabile.
3. Exemple de coduri utilizate in compresia datelor
In continuare sunt prezentate trei coduri reprezentative pentru aspectele discutate anterior. Codurile vor fi prezentate doar pentru cazul in care cuvintele de cod sunt formate cu simboluri ale alfabetului binar = .
3.1. Codul Huffman
Codul prefixat care ofera cea mai mica lungime medie a cuvintelor de cod pentru o sursa informationala data poate fi construit printr-un algoritm simplu descoperit de Huffman. Pe scurt, algoritmul poate fi descris astfel:
se ordoneaza simbolurile in ordinea inversa a probabilitatii de aparitie.
ultimele doua simboluri (conform ordonarii de la pasul 1) sunt reunite intr-un simbol a carui probabilitate de aparitie este egala cu suma probabilitatilor celor doua simboluri reunite.
pasul doi se repeta pana cand se obtine un singur simbol a carui probabilitate de aparitie este 1.
se parcurge arborele de codare (generat prin reunirea simbolurilor descrisa la pasul 3) de la radacina pana la frunze, adica pana la simbolurile originale ale sursei, atribuindu-se fiecarei ramuri stangi simbolul 0 (sau 1) si fiecarei ramuri drepte simbolul 1 (sau respectiv 0).
Sa consideram un exemplu:
Fie sursa
informationala X cu alfabetul A = avand in ordine probabilitatile de
aparitie 0.25, 0.25, 0.2, 0.15, 0.15. Algoritmul Huffman ofera codul din
tabelul 1.2 in care e prezentat si modul de generare al codului.
|
Lungimea cuvantului de cod |
Cuvantul de cod |
X |
Probabilitati |
||||
|
01 |
|
|
|||||
|
001 | |||||||
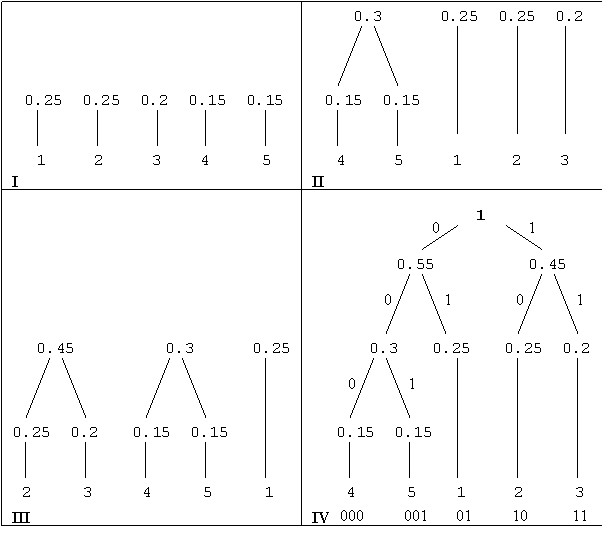
![]() Tabelul 2. Generarea codului Huffman
Tabelul 2. Generarea codului Huffman
Figura 2. Evolutia arborelui de codare.
I - simbolurile sunt ordonate dupa probabilitatile lor de aparitie:
II - simbolurile cu cele mai mici probabilitati (4 si 5) sunt reunite intr-un simbol de probabilitate 0.15 + 0.15 = 0.3, iar noul set de simboluri este reordonat:
0.3, 0.25, 0.25, 0.2
III - acum simbolurile 2 si 3 au cele mai mici probabilitati de aparitie; ele sunt reunite intr-un simbol de probabilitate 0.25 + 0.2 = 0.45 si din nou setul de probabilitati este ordonat:
0.45, 0.3, 0.25
IV - prin reunirea simbolurilor cu cele mai mici probabilitati se obtine un nou simbol de probabilitate 0.3 + 0.25 = 0.55; rezulta astfel doua simboluri de probabilitati 0.55 si 0.45 a caror reunire genereaza un singur simbol de probabilitate 1; prin urmare se trece la pasul 4 din algoritm si se atribuie arborelui creat simbolul 0 pentru ramurile din stanga si simbolul 1 pentru ramurile din dreapta.
Lungimea medie a codului obtinut este
![]()
Entropia sursei este
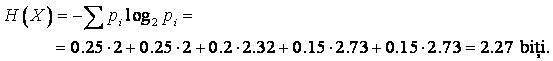
Algoritmul propus de Huffman este un algoritm "greedy", combinand la fiecare pas simbolurile cele mai putin probabile. Se poate arata ca aceasta optimalitate locala asigura algoritmului optimalitatea globala.
In cazul in care probabilitatile simbolurilor sunt puteri negative ale lui 2 (distributie diadica) codul Huffman este optim atingand o lungime medie egala cu entropia.
Prin urmare, pentru o anumita sursa orice alt cod are lungimea medie mai mare, cel mult egala cu lungimea medie a codului Huffman.
3.2. Codul Shannon-Fano
Pentru prezentarea algoritmului se va folosi un exemplu simplu .
Fie urmatoarele simboluri cu numarul lor de aparitii:
|
Simbol |
a |
b |
c |
d |
e |
|
Numar de aparitii |
15 |
7 |
6 |
6 |
5 |
Este o metoda de sus in jos care are urmatorii pasi:
Se ordoneaza simbolurile in functie de numarul de aparitii al acestora.
Recursiv, se imparte setul de simboluri in doua partitii pana cand ramane un singur simbol in fiecare grup. Acest simbol ramas va denumi o frunza din arborele care se va forma. Cele doua partitii se formeaza astfel incat suma numerelor de aparitii a simbolurilor din primul grup sa fie apropiata de suma numerelor de aparitii a simbolurilor din al doilea grup. Cele doua grupuri astfel formate reprezinta doua noduri intr-un arbore, iar ramurile sunt notate cu 0 si 1.
Pentru a determina cuvantul de cod asociat unui anumit simbol, se parcurge arborele de la radacina catre frunza care are ca nume acel simbol si se retine 0 sau 1 in functie de calea aleasa prin arbore.
Pentru exemplul considerat, arborele arata astfel:
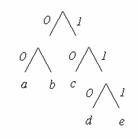
Fig.1.3. Arborele binar determinat de codarea Shannon-Fano
|
simbol |
Cod |
|
a |
00 |
|
b |
01 |
|
c |
10 |
|
d |
110 |
|
e |
111 |
3.3. Codarea aritmetica
Avantajul major al acestei metode este ca poate coda simboluri fara a folosi un numar intreg de biti / simbol. In codarea aritmetica, un mesaj de intrare de orice dimensiune poate fi reprezentat ca un numar real R din intervalul [ 0, 1 ). Cu cat mesajul de intrare este mai mare, cu atat precizia necesara pentru reprezentarea numarului R este mai mare.
Codul este construit astfel:
Se imparte intervalul [0, 1) in M segmente, unde M este numarul de simboluri din alfabet, fiecare segment avand o lungime proportionala cu probabilitatea de aparitie a simbolului respectiv.
Se alege subintervalul corespunzator primului simbol sosit.
Acest nou interval se imparte din nou in M segmente proportionale cu numarul de aparitii al simbolurilor.
Se alege subintervalul corespunzator urmatorului simbol sosit.
Se continua cu pasii 3 si 4 pana cand intreg mesajul este codat.
Se alege un numar din intervalul final, se reprezinta binar si acesta reprezinta cuvantul de cod asociat intregului mesaj.
Exemplu: Fie urmatorul set de simboluri cu probabilitatile:
|
Simbol |
probabilitate |
|
U | |
|
O | |
|
I | |
|
E | |
|
A |
Presupunem ca mesajul care se doreste a fi codat este : IOUA. Algoritmul este exemplificat in urmatoarea schema:
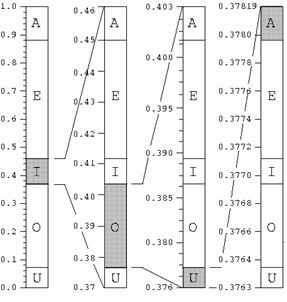
Fig.1.5. Determinarea subintervalelor in codarea aritmetica
Intervalul [0, 1) este impartit in cinci segmente proportionale cu probabilitatea fiecarui simbol. Se observa ca aparitia primului simbol al mesajului, I, restrange intervalul initial la intervalul [0.3763, 0.46). In cele din urma se ajunge la intervalul [0.3779632, 0.37819). Orice numar din acest interval poate fi folosit pentru codificarea mesajului. De exemplu, numarul 0.37817 este in acest interval, iar scrierea bianara asociata este 0.011000001101, lungimea acestui cuvant de cod fiind determinata de dimensiunea intervalului final. Dimensiunea intervalului final este determinat de produsul probabilitatilor de aparitie a simbolurilor care formeaza mesajul.
La fel ca si pentru codarea Huffman, trebuie sa stim numarul de aparitii al simbolurilor, iar acestea trebuie trimise si decodorului. De obicei, aceasta informatie aditionala este neglijabila in comparatie cu restul mesajului.
Decodorul imparte si el intervalul [0, 1) in subintervale proportionale cu probabilitatile simbolurilor din alfabet. Apoi compara numarul primit cu limitele acestor subintevale si determina intervalul in care se afla acest numar. Simbolul asociat cu acest interval reprezinta primul simbol al mesajului, iar noul interval este subintervalul corespunzator acestuia. Problema care apare este ca decodorul nu stie cand sa se opreasca. Exista doua solutii pentru a rezolva aceasta problema: transmiterea lungimii mesajului sau existenta unui simbol special care determina sfarsitul mesajului. De obicei se prefera a doua varianta.
3.4. Codare statica vs. codare dinamica
Procedurile de codare descrise mai sus sunt proceduri de codare statica. Aceasta inseamna ca probabilitatile asignate simbolurilor (adica modelul statistic al sursei) ramane nemodificat pe durata procesului de codare. Dezavantajul acestei abordari consta din faptul ca e necesara o parcurgere initiala a secventei ce va fi codata pentru determinarea numarului de aparitii si transmiterea probabilitatilor determinate decodorului. Practic, modelul statistic al sursei este determinat "off-line" de catre codor si transmis apoi decodorului.
O procedura dinamica este deci o procedura care modifica modelul statistic utilizat (probabilitatile de aparitie ale simbolurilor) in timpul codarii efective. Astfel se evita pre-parcurgerea secventei ce va fi codata. Problema principala care apare in cadrul acestei abordari este ca atat si codorul si decodorul trebuie sa utilizeze acelasi model statistic la un moment dat. Pentru aceasta si codorul si decodorul isi modifica modelul statistic pe baza simbolurilor deja analizate. Secventa de actiuni este:
Codare
Initializeaza_model()
While ( c = getc (input)) != eof )
Decodare
Initializeaza_model()
While ( c = decodeaza (input)) != eof )
Initializeaza_model() presupune asignarea unui set de probabilitati initiale de la care porneste atat algoritmul de codare, cat si cel de decodare. Este obligatoriu ca aceasta procedura sa determine acelasi set de probabilitati atat la codare cat si la decodare. In general se utilizeaza presupunerera ca simbolurile sunt echiprobabile.
Codeaza (c, output) are ca data de intrare simbolul c pe care il codeaza pe baza modelului existent si un pointer catre stream-ul de iesire, output, in care pune cuvintele de cod asignate lui c. Cuvantul de cod este determinat pe baza modelului statistic determinat la momentul curent.
Decodeaza (input) determina simbolul asociat cuvantului de cod citit, care este depus in variabila c. Decodarea se face pe baza modelului statistic determinat la momentul curent.
Actualizare_model (c) aceasta procedura este aceeasi atat la codare cat si la decodare si determina un nou set de probabilitati pe baza simbolului codat, respectiv decodat, c.
Cel mai important lucru este ca procedurile de initializare si actualizare ale modelului sa fie identice
Pretul platit pentru evitarea unei parcurgeri suplimentare a secventei codate si al transmiterii modelului statistic este platit prin faptul modelul actualizat este mai putin precis decat modelul determinat in varianta statica.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 2288
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved