| CATEGORII DOCUMENTE |
| Aeronautica | Comunicatii | Electronica electricitate | Merceologie | Tehnica mecanica |
Metode de analiza - vorbire
1 Modele pentru productia vocala
Modelele de productie vocala prezentate in literatura de specialitate, urmaresc doua aspecte:
modelarea tractului vocal, modelerea variabilitatii in timp a caracteristicilor sunetelor.
- Modelarea tractului vocal
Cel mai cunoscut model al productiei vocale este cel numit "modelul sursa-filtru", descris de Fant in 1960. Conform acestui model, componentele ansamblului de productie vocala este compus din trei parti: sursa de excitatie, echivalenta generatorului undei vocale, un tub cu cavitati de rezonanta, echivalent unui filtru, in procesarea de semnal, si tractului vocal superior,in mecanismul de productie vocala, si un filtru care simuleaza fenomenul radiatiei bucale.
Parametrii referitori la rezonantele tubului (in principal polii filtrului) pot fi folositi pentru a caracteriza din punct de vedere spectral portiuni ale fluxului sonor vocal.
Pentru modelarea tuturor sunetelor vorbirii, se folosesc doua tipuri de surse de excitatie:
- Generator de impulsuri; forma implusurilor este asemanatoare celor glotale naturale, cu o panta de crestere mai mica decat cea de scadere, si se desfasoara pe durata deschiderii glotale. Acestea sunt separate de portiuni pe care semnalul ramane la zero si corespund intervalelor de inchidere glotala. Acest tip de excitatie se produce in cazul vocalelor, consoanelor sonante (nazale, lichide) si a celorlalte consoane sonore. Trenurile de impulsuri au o panta spectrala de -12 dB/octava.
- Generator de zgomot aleator echivalent celui de fricatie produs la trecerea aerului prin portiunile constrictive, in cazul consoanelor fricative sau a celor cu portiuni fricative.
Identitatea fiecarui sunet este data de pozitiile particulare ale articulatorilor mobili careformeaza cavitatile rezonante ale tractului vocal superior. Acesta actioneaza ca un filtru asupra semnalului de excitatie. In stadiul final al modelarii sursa-filtru, se simuleaza fenomenul radiatiei
bucale, care se concretizeaza in cresterea pantei spectrale cu +6 dB/octava. In sinteza formantica a sunetelor sonore se combina efectul radiatiei bucale cu cel produs de spectrul de excitatie si se
foloseste un filtru care realizeaza, pe ansamblu, o panta spectrala de -6 dB/octava.
- Modelarea semanlului vocal in domeniul timp
Prin modelerea variabilitatii caracteristicilor sunetelor, se urmareste reprezentarea in timp a urmatoarelor trasaturi: durata si co-articularea sunetelor, evolutia in timp a principalilor parametrii ai modelului.
a. Modele pentru durata sunetelor
La nivel vorbitorului, durata sunetelor este in corelatie cu rapiditatea vorbirii. Rapiditatea vorbirii este limitata de inertia articulatorilor iar durata sunetelor variaza functie de mobilitatea articulatorilor implicati in producerea lor (miscarea buzelor si a limbii). Duratele medii ale fonemelor variaza intre 20 msec pentru consoanele plosive sonore pana la 150 msec pentru diftongi, cu o durata medie a fonemelor de 70 msec. La vocale, durata variaza, functie de context, intre valori aflate intr-un raport de 1/8 si depinde de silaba in care se afla. Kanedera si Hermansky in studiul lor au pus in evidenta faptul ca modulatia perceptuala cea mai importanta a vorbirii (modificarile cele mai importante in semnalul vocal) este realizata in jurul valori de 4-5 Hz, sau 200-250 msec cat este aproximativ durata unei silabe .
Klatt face remarca ca in recunoasterea vorbirii informatia de durata este folosita de fiintele umane pentru a distinge:
- vocalele lungi de cele scurte,
- consoanele sonore de perechile lor surde,
- silaba de final fraza de cea neaflata in pozitie final fraza,
- vocala din silaba accentuata de cea din silaba neaccentuata.
Daca se iau in considerare multitudinea factorilor care influienteaza duratele fonemelor si perceptia, rezulta modele relativ complexe. Modelul propus de Klatt stabileste 7 factori care influenteaza structura duratelor dintr-o propozitie, si 8 reguli care tin cont de acesti factori.
Un model mai simplu propus de van Santen este capabil sa modeleze 86% din situatiile de variatie a duratelor vocalelor cuprinse intr-un corpus segmentat manual. Acest model necesita urmatorii parametrii pentru controlul duratei vocalelor:
- durata intrinseca a vocalei,
- prezenta accentului de propozitie
- prezenta accentului de cuvant,
- consoana dinaintea vocalei,
- consoana dupa vocala,
- pozitia in cadrul cuvantului
- pozitia in cadrul rostirii.
In modelul statistic dezvoltat de Chung, pentru modelarea duratei la nivel de fonem si cuvant este folosita o structura cu arbori (ANGIE framework). Antrenarea arborelui este facuta be baza unui corpus de date. Informatia de durata cuprinsa in arbore poate fi folosita pentru a testa
diferite ipoteze asupra unor posibile cuvinte si a favoriza pe acelea care au o mai buna apropiere cu modelul . Folosirea acestui model, in cadrul unui proces de recunoastere a condus la o scadere cu 8% a erorilor de recunoastere in vorbirea continua si cu 22% a erorilor de recunoastere a cuvintelor.
b. Modele pentru co-articularea sunetelor
In ceea ce priveste co-articularea sunetelor vecine, aceasta se evidentiaza prin tranzitii formantice lente de la unul la celalalt care fac dificila stabilirea granitelor acestora.
In modelul dezvoltat de hman , modificarea formei tractului vocal la tranzitiile de tipul vocala-consoana-vocala a fost descrisa prin relatia :
s(x,t)=v(x)+k(t) * [c(x) - v(x)] * wc(x)
unde: s(x,t) este forma tractului vocal in pozitia x si la momentul de timp t,
v(x) este forma tractului vocal corespunzatore vocalei respective,
c(x) este forma tractului vocal corespunzatoare consoanei,
k(t) este un termen de interpolare intre 0 si 1
wc(x) este un terman care descrie marimea extrinderii co-articulatiei.
Autorul recunoaste ca e greu de descris cu acest model co-articularea intre consoane, cum ar fi in cazul tranzitiei CVC, consoana-vocala-consoana.
In modelul bazat pe teoria punctului de articulare , consoanele au asignate valori fixe pentru formanti, corespunzatoare punctului de articulare, care pot sa nu fie vizibili in semnalul vocal. Acesti formanti virtuali sunt interpolati cu formantii propriu-zisi care apar la
vocale, pentru a genera modificari formantice dependente de context. Klatt a modificat teoria punctului de articulare pentru ca valorile "formantilor" la consoane sa depinda si de tipul vocalei . Folosind aceasta metoda el a atins o inteligibilitate a consoanelor de 95% in sinteza
silabelor CVC, comparabila cu inteligibilitatea de 99% pentru silabele CVC rostite natural. Klatt nu a evaluat modelul pe extensii ale co-articulatei mai mari de 6 foneme.
In modelul propus de Lfqvist, raportat de Cohen si Massaro , segmentele de speech isi suprapun functiile de dominanta care controleaza articulatorii, existand cate o functie de dominanta pe cate un articulator. Acestea pot diferi in ceea ce priveste offset-ul de timp,
durata si marime, dand o mai mare sau mai mica pondere articulatorilor asociati cu segmentul devorbire dat.
Desi aceste modele pentru co-articulatii sunt folosite cu succes in modelarea reprezentarii miscarii articulatorilor in timpul vorbirii, ele nu pot fi folosite in sistemele de recunoastere a vorbirii.
Analiza scenelor auditive
Analiza scenelor auditive (ASA) este un model teoretic al perceptiei umane in care se foloseste o procesare bottom-up si top-down pentru a determina ce parti din semnalul de vorbire apartin unui singur eveniment acustic . Modelul este construit pornind de la analiza mediilor sonore complexe ce implica existenta mai multor sunete simultan. De asemenea, dupa izolarea unor componente de interes din fiecare portiune de semnal vocal, pentru integrarea lor intr-un 'streams', se foloseste criteriul similaritatii in ceea ce priveste frecventa de 'pitch', sau alte aspecte . Cu ajutorul acestui model Cooke si Brown au fost capabili sa detecteze si sa extraga anumite sunete 'acoperite', cum ar fi cele acoperite de sunetul unei sirene.
- Modelul Fletcher-Allen
Harvey Fletcher si colegii sai a
studiat mecanismul perceptii umane la
S=c1 * v * c2
unde: S este probabilitatea de recunoastere a silabei;
c1, v, c2 probabilitatile de recunoastere corecta a consoanelor si a vocalei dintre acestea.
Aceasta formula are o implicatii importante deoarece oameni percep fiecare fonemindividual, mai degraba ca unitate de intrare intr-o silaba. In plus, Fletcher a observat ca fiintele umane proceseaza benzile de frecventa independent si ca eroarea globala de recunoastere in mai multe benzi este data de multiplicarea erorilor in fiecare din acestea.
Allen a interpretat aceste rezultate astfel: fiintele umane efectueaza recunoasteri partiale in benzi de frecventa individuale si aceste rezultate partiale fuzioneaza pentru a produce o estimare a fonemului. Numarul benzilor de frecventa trebuie sa fie intre 10 si 30. Allen noteaza,
de asemenea, ca "reprezentarea neurala la nivelul creierului, a intensitatii sunetului este transformata intr-o masura a recunoasterii partiale noi nu trebuie sa consideram ca aceste transformari sunt triviale".
Bazat pe descoperirile lui Fletcher, Allen propune un model cascada al mecanismului de perceptie, in care energia semnalul acustic este mai intai impartita intr-un numar de benzi de frecventa intens suprapuse cu ajutorul unui bank de filtre cochlear.
Iesirile acestor benzi sunt folosite pentru a extrage trasaturile sunetului pentru al clasifica la nivel de fonem. Dupa clasificarea la nivelul fonemului se face recunoastere silabei, pe care se bazeaza apoi recunoasterea la nivel de cuvant. Allen noteaza ca in acest model simplificat nu exista
feedback intre diferitele nivele de recunoastere.
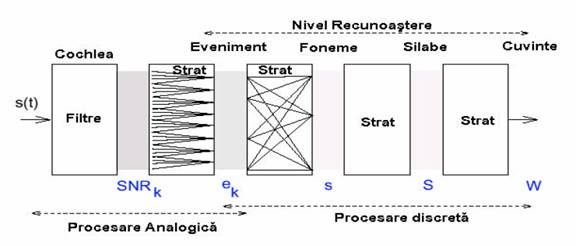
Fig. 10.Model cascada al mecanismului de perceptie propus de
Allen
2 Teoria motorie a perceptiei vorbirii
Teoria motorie a perceptiei vorbirii este una din cele mai cunoscute si mai des folosite. Intr-o versiune noua stabileste drept obiective ale perceptiei vorbirii, gesturilor fonetice intentionate ale vorbitorului necesare pentru articularea sunetelor. La nivelul creierului, acestora le corespund comenzile motoare pentru miscarea articulatorilor, care constituie comenzi invariante in raport cu un anumit sunet.Cu alte cuvinte, ceea ce percepem sunt gesture care corespund miscari articulatorilor efectuate de un vorbitor. Tot in aceasta teorie se sustine idea existentei in creier a unui "modul specializat" care transforma semnalul acustic in gesturi fonetice intentionate ale articulatorilor
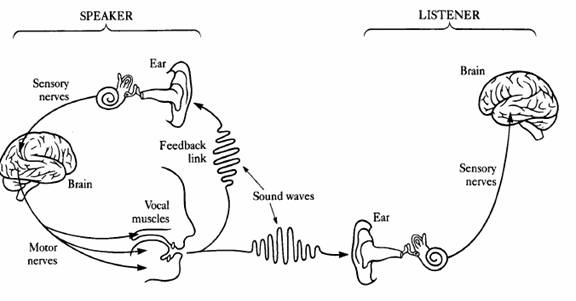
Fig. 11. Modelul lui Liberman de perceptie a vorbirii
Dupa Liberman, acest modul poate lucra dupa metoda de analiza prin sinteza, in care modelul mental al sintetizatorului este folosi pentru a genera diferite proprietati acustice. Parametrii gesturilor acustice de la intrare sintetizatorului sunt modificate pana cand eroarea dintre
proprietatile acustice sintetizate si proprietatile observate sunt minimizate. Iesirea acestui modul este reprezentata prin gesturile articulatorilor. Liberman si Mattingly afirma ca acest model al perceptiei este computational si indirect (usor invesabil).
Una din criticile aduse modelului este formulata de Cole care arata, in urma unui studiu , ca recunoasterea sunetelor se poate face si de pe spectrograma, prin 'citirea' unei forme vizuale a vorbirii fara implicarea unui modul biologic specializat. Persoanele care efectueaza citirea spectrogramelor nu fac referiri la miscarile articulatorii. Acest studiu combate afirmatiile conform carora semnalul acustic este prea complex pentru a fi mapat in categorii fonetice si aparatul perceptiei auditive necesita un stadiu intermediar, de transformare a informatiei in gesturi articulatorii.
Un alt studiu, cel al lui Lane, combate ideea transformarii semnalului acustic in parametri de miscare a articulatorilor. S-au folosit stimuli de tip CV carora li s-au inversat frecventele formantice pe axa frecventelor, obtinandu-se sunete nonverbale. Auditorii au fost antrenati sa invete sa le recunoasa si acest lucru a reusit, desi sunetele neprovenind din rostiri verbale nu pot fi puse in legatura cu acei presupusi parametri interni referitori la comanda miscarii articulatorilor .
Un alt argument il aduce Ladefoged prin ideea ca aceleasi sunete, pronuntate diferit din punct de vedere al articularii, sunt percepute ca reprezentand acelasi sunet, desi conform teoriei motoare ar trebui sa fie reprezentate intern diferit .
3 Arhitectura unui sistem de intelegere a vorbirii
Exista mai multe cai de integrare a surselor de cunostinte intr-un sistem de recunoastere a formelor pentru ca acesta sa devina un sistem de 'intelegere ' a vorbirii. Cea mai folosita arhitectura este cea de jos in sus reprezentata in fig. 12:
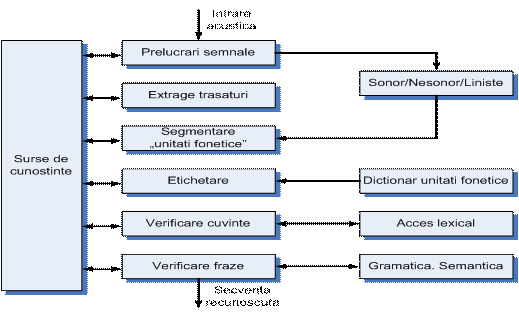
Fig.12.Sistem de intelegere a vorbirii cu arhitectura de
jos in sus pentru integrarea surselor de cunostinte.
In aceasta arhitectura, procesele de la nivelul mai jos (de exemplu determinarea parametrilor ca trasaturi esentiale, decodajul acustico-fonetic) preced procesele de la nivelurile superioare (decodaj lexical adica formare de cuvinte dupa modelul limbii) intr-o maniera secventiala, astfel incat etajele succesive sa se constranga reciproc cat mai putin.
O alta varianta intalnita in constructia sistemelor de intelegere a vorbirii este arhitectura de 'sus in jos' in care, folosind un model al limbii se genereaza ipotezele cu privire la cuvintele care se potrivesc cel mai bine cu secventa de semnal vorbit care trebuie recunoscuta .Pe baza scorurilor de potrivire se construiesc fraze corecte, cu sens pentru aplicatia respectiva.. O asemenea arhitectura este prezentata in fig.13:
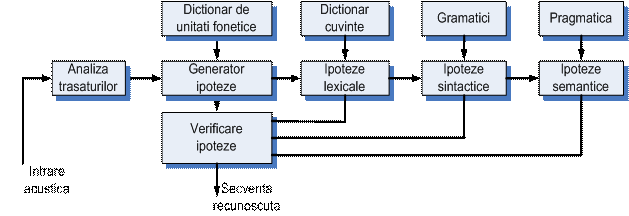
Fig.1 Sistem de intelegere a vorbirii cu arhitectura de
sus in jos pentru integrarea surselor de cunostinte.
O alta posibilitate de integrare a surselor de cunostinte in sistemele de intelegere a vorbirii, este cunoscuta sub numele de arhitectura 'blackboard'. In acest caz sursele de cunostinte sunt considerate independente. Ele comunica printr-un mediu constituit de o succesiune de operatii ipotetizare-test; fiecare din sursele de cunostite este activata de date, pe baza aparitiei unor forme pe 'blackboard' care se potrivesc cu modelele specificate de fiecare din sursele de cunostinte; sistemul lucreaza asincron si se dovedeste a fi foarte flexibil in folosirea 'economica' a surselor de cunostinte apelate numai atunci cand acestea sunt necesare .
Rezulta ca in sistemele de recunoastere a vorbirii este necesara integrarea unui mare numar de surse de cunostinte pentru a obtine performante acceptabile. In realizarea acestor sisteme doua categorii de procese joaca un rol deosebit: procesul de invatare si procesul de adaptare, care sunt adesea cuplate pentru realizarea recunoasterii.
Numeroase modele sunt aplicate in vederea implementarii acestor procese: modelul statistic Markov, modelul cu retele neuronale, modelul fuzzy al multimilor vagi precum si combinatiile acestor modele.
In recunoasterea vorbirii, un procedeu adesea folosit pentru 'standardizarea in timp' a unor secvente rostite cu rate diferite de vorbire, este alinierea temporala dinamica (ATD).
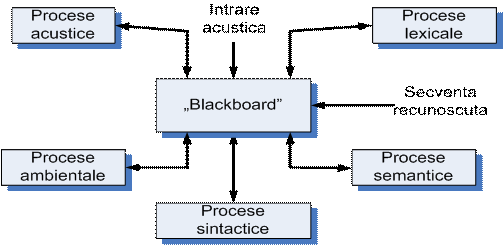
Fig.14. Arhitectura "blackboard" pentru integrarea surselor de cunostinte
intr-un sistem de intelegere a vorbiri
4 Modele Markov ascunse
Modelele Markov sunt o incercare de 'fixare' a proprietatilor statistice ale vorbirii, in structura unui automat secvential.
Modelele Markov ascunse sunt automate finite, cu un numar distinct de stari , trecerea dintr-o stare in alta stare facandu-se instantaneu la intervale de timp care corespund unei ferestre de semnal din a carei analiza rezulta un cadru de 'trasaturi esentiale' numit si vector de parametri. La fiecare trecere dintr-o stare in alta stare sistemul genereaza observatii, in automat derulandu-se concomitent doua procese aleatoare: unul reprezentat de succesiunea starilor, care este inobservabil, ascuns si un altul perfect transparent si observabil, reprezentat de succesiunea observatiilor, respectiv a vectorilor de parametri.
Un model Markov ascuns simuleaza succesiunea vectorilor din fiecare cadru de parametrii observati ca pe un proces stationar pe portiuni, deci o rostire este modelata ca o succesiune de stari ale modelului.
Daca notam cu O observatiile si cu λ un model Markov al acestor observatii, conform regulii lui Bayes reformulata, se pote scrie:
![]()
. P(λ/O) este probabilitatea aposteriori a modelului asociata cu 'unitatea fonetica' (fonem, semisilaba, silaba, cuvant) care determina succesiunea de observatii O .
. P(O/A.) este probabilitatea observatiei in condijiile modelului si ar putea fi interpretata ca o masura a probabilitatii cu care modelul poate genera observatia O, respectiv ca o probabilitate de emisie a unui anumit vector de trasaturi.
. P(λ) este o probabilitate apriori a modelului determinata de "structura" limbii si care este determinanta pentru fiecare limba
. P(O) este probabilitatea observatiei O pe care o presupunem independenta de parametrii modelului
Ecuatia poate fi privita ca ecuatia de antrenare a modelului, parametrii acestuia fiind reestimati dupa criteriul maximei plauzibilitati a secventei O in conditiile modelului λ. O asemenea antrenare in care este maximizata numai probabilitatea modelului corect ipotetizat corespunzator secventei O, conduce la lipsa de discriminare intre modele. Pe langa acest dezavantaj o alta limitare a modelelor Markov ascunse este legata de presupunerea ca procesul aleator cu care se aproximeaza segmentul de semnal vorbit are cadrele succesive decorelate, rcstrictie care nu se potriveste foarte bine vorbirii in care coarticulatia, contextul sunt foarte importante.
Modelele Markov se bucura de un suport matematic bine pus la punct in forma unor algoritmi eftcienti de antrenare si de calcul pentru probabilitatile aposteriori. Cu o buna capacitate de invatare, se pot adapta cu usurinta dinamicii temporale a semnalului si nu necesita proceduri de aliniere speciale.
Modelele Markov ascunse pot fi folosite pentru recunoasterea vorbirii atat in sisteme construite pe principiul recunoasterii formelor cat si in sisteme expert.
In sistemele de recunoastere a formelor, invatarea are loc din experienta, prin antrenarea modelului cu cazuri particulare, rezultatul antrenarii fiind un model cu anumiti parametri care se utilizeaza in recunoastere.
In sistemele expert utilizarea modelelor Markov ascunse este foarte indicata daca diferitele niveluri de constrangere (lingvistic, sintactic) pot fi formalizate statistic.
Pentru limba romana de exemplu, exista date statistice in legatura cu frecventa de aparitie pentru litere, grupuri de litere, tipuri de silabe ,s.a. pe baza carora se pot alcatui modele statistice ale limbii.
5 Modele cu retele neuronale
Un punct de vedere acceptat in ceea ce priveste retelele neuronale este capacitatea lor de a modela intr-o anumita masura procese din sistemul nervos uman .
Schema bloc bazata pe modelul perceperii vorbirii de catre orn, este prezentata in figura 15 .
In aceasta schema semnalul acustic de intrare este analizat de un 'model al urechii' care furnizeaza o reprezentare spectrala a semnalului in functie de timp. Aceasta este stocata intr-o memorie informationalo-senzoriala, la care mai au acces si alte informatii senzoriale, ca cele provenite de exemplu de la vaz si pipait. In aceasta memorie se gaseste o descriere a semnalului la nivelul 'trasaturilor' sale relevante, al parametrilor care il caracterizeaza. Memoria pe termen lung, cu caracter static si memoria pe termen scurt, cu caracter dinamic sunt utilizate in procesul de detectie a diferitelor 'trasaturi'. Dupa cateva stadii de rafinare a detectiei de trasaturi, iesirea finala a sistemului reprezinta o interpretare a informatiei continute in semnalul acustic de intrare.
Sistemul din figura 15. este un
model uman de intelegere a vorbirii la nivelul cunostintelor actuale cu privire
la mecanismele implicate in acest proces.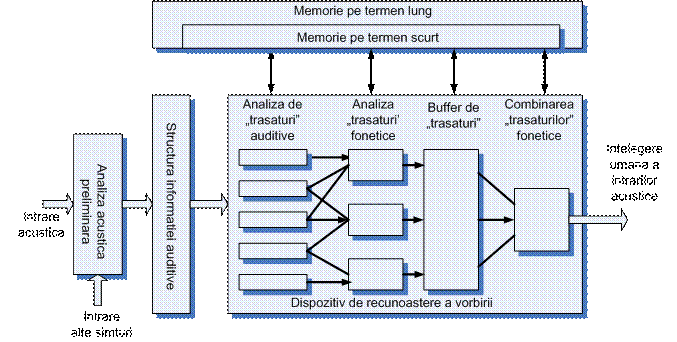
Fig.15. Schema bloc conceptuala a perceperii vorbirii de catre om.
In acest model, diferitele trasaturi obtinute prin analiza, reprezinta rezultatul unor prelucrari care au loc pe nivelele succesive parcurse de informatia culeasa cu senzori pana la creier, memoria pe termen scurt si memoria pe termen lung asigurand controlul acestor procese. Interconectarea elementelor acestei scheme sugereaza structuri asemanatoare celor din retelele neuronale, cu care se pot modela procesele de invatare si adaptare.
In momentul de fata, cu retele neuronale se construiesc sisteme mult mai simple decat creierul uman si care rezolva probleme cu mult mai simple decat cele pe care le rezolva creierul uman. Ele constituie o alternativea la metodele conventionale in recunoasterea vorbirii datorita unor calitati de necontestat.
Calitatile pe care le prezinta retelele neuronale si care le fac potrivite in recunoasterea vorbirii sunt urmatoarele:
1. Prin structura lor, rezultata din punerea in paralel a unui mare numar de elemente de calcul identice, retelele neuronale sunt procesoare tipice pentru calcul paralel, ele putand prelua setul de trasaturi care caracterizeaza formele de recunoscut.
2. Prin 'diseminarea' informatiei dar si a perturbatiei la toate elementele de calcul din retea, retelele neuronale au o mare toleranta la erori, fiind structuri foarte robuste din acest punct de vedere
Ponderile conexiunilor din retea nu sunt constranse sa fie fixe, ele pot fi adaptate in timp real, pentru imbunatatirea performantelor; retelele neuronale sunt structuri care pot fi folositepentru invatarea adaptiva.
4. Din cauza neliniaritatii inglobate in fiecare element, retelele neuronale pot aproxima cu o eroare mica orice comportare neliniara a sistemelor dinamice.
Se poate afirma ca daca proprietatea 3 este cea care asigura adaptabilitatea retelei, proprietatea 1 determina viteza acestei adaptari, proprietatea 2 detennina 'stabilitatea' iar proprietatea 4 permie optimizarea strategiei de adaptare.
In recunoasterea vorbirii retelele neuronale isi gasesc utilizarile cele mai diferite, de la aplicatiile legate de modelarea si de clasificarea sistemelor de recunoastere a formelor pana la testarea ipotezelor in sistemele expert. Retelele neuronale se utilizeaza in acelasi mod in ambele cazuri.
In cazul recunoasterii formelor in faza de antrenare reteaua isi schimba structura pentru a se adapta setului de date de antrenare, invatand deci din experienta; faza de antrenare terminata, reteaua s-a structurat si a devenit model, iar modelul poate fi folosit pentru recunoastere prin determinarea unor masuri de potrivire a datelor cu modelul.
In cazul sistemelor expert toate
informatiile materializate intr-un ansamblu de reguli sau de cunostinte sunt memorate in structura sistemului, reteaua constituind de exemplu un model de limba
sau de gramalica.
Din semnalul acustic, prin decodare fonetico-acustica se extrage, de exemplu, o
succesiune de litere: modelul de limba stabileste care sunt cuvintele care pot fi construite cu aceste litere;
aceste cuvinte devin ipoteze care sunt testate in vederea alegerii cuvantului cel mai probabil, iar
decizia luata constituie o data pentru
nivelul superior. Pentru nivelul urmator deci, datele sunt constituite dintr-o
succesiune de cuvinte din care, cu un model de gramatica putem construi
fraze-ipoteze, alegand ca solutie finala pe cea mai probabila dintre
acestea ; procesul poate astfel
continua pana la ultimul nivel, pe care selectionam fraza cea mai potrivita cu
scopul propus, corecta din punct de vedere gramatical si semantic.
Retele neuronale cu auto-organizare.
Dezvoltarea hartilor cu auto-organizare ca modele neuronale a fost motivata de o caracteristica distincta a creierului uman si anume aceea de a avea in cortexul cerebral arii corespunzatoare centrilor nervosi specializati pentru diverse activitati: vorbitul, auzul, vazul, functiile motorii etc. Aceste arii sunt localizate in aceeasi zona si, mai mult, ariile individuale arata o ordonare logica a functionalitatii lor.
Aceste retele sunt bazate pe invatarea competitiva; neuronii de iesire ai retelei concureaza intre ei pentru a deveni activi, rezultatul fiind acela ca numai unul dintre ei are aceasta sansa la un moment dat. Un neuron de iesire care invinge in aceasta competitie este numit neuron invingator.
Un mod de a induce o competitie de acest tip intre neuroni este folosirea conexiunilor laterale inhibitorii intre acestia.
Intr-o harta cu auto-organizare, neuronii sunt plasati in nodurile unei matrice, care de regula este uni sau bidimensionala. In timpul procesului de invatare, neuronii devin selectivi la diferite forme de intrare sau clase ale acestora. Localizarea neuronilor invingatori in raport cu ceilalti neuroni se face in asa fel incat se pastreaza relatiile topologice, de pozitionare, existente intre vectorii de intrare in spatiul lor multidimensional. De aceea, stratul de iesire al retelei este similar unei harti topografice a formelor de intrare in care coordonatele spatiale ale neuronilor din matrice sunt indicatori ai caracteristicilor statistice continute in formele de| intrare, si de aceea se numesc 'harti cu auto-organizare'.
In spatiul de iesire asezarea neuronilor se poate face sub forma liniara, circulara, patratica, cubica, in general m-dimensionala.
Exista doua modele de structurare a retelelor neuronale cu auto-organizare, prezentate in fig.16. In ambele cazuri neuronii sunt aranjati intr-o matrice bidimensionala. Acest tip de topologie asigura fiecarui neuron un set de vecini. Modelele difera intre ele prin modul in care sunt specificate formele de intrare.
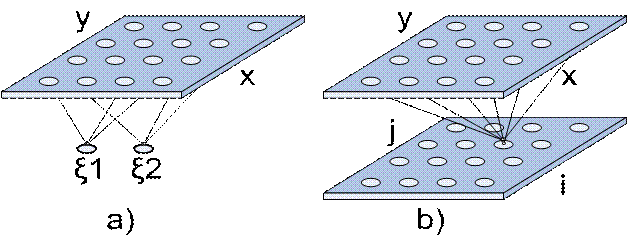
Fig.16.Tipuri de harti de caracteristici.
a)modelul Kohonen; b) modelul Willshaw-von der Malsburg.
Realizarea hartilor fonetice cu ajutorul retelelor neuronale.
Prin harta fonetica se intelege reprezentarea intr-un plan a informatiei continute in semnalul vocal. Aceasta reprezentare trebuie astfel facuta incat sa se consrve relatiile de vecinatate existente intre partile componente ale semnalului vocal in spatiul de reprezentare primar. Cum initial semnalul este caracterizat prin intermediul a 40 de coeficienti cepstrali si delta-cepstrali, problema care trebuie rezolvata consta in realizarea unei translatari din hiperspatiul initial 40-dimensional in spatiul hartii fonetice bidimensional. In literatura de specialitate o astfel de abordare se intalneste sub denumirea de selectie a caracteristicilor ( features selection).
Metoda optima de selectie a caracteristicilor consta in aplicarea transformatei Karhunen-Loeve.
Aceasta transformare depinde de statistica semnalului de intrare, ea conduce la obtinerea unor rezultate mai slabe (sub-optimale) in cazul semnalelor vocale a caror statistica nu este stationara.
Pentru obtinerea unor rezultate mai bune in selectia caracteristicilor se utilizeaza retele neuronale de tip Kohonen cu un strat de iesire bidimensional.
La alegerea acestei solutii contribuie doua idei majore:
-utilizarea unei retele neuronale, care prin structura sa paralela conduce la o prelucrare rapida a datelor;
-folosirea unei retele de tip Kohonen care datorita caracterului sau topologic ofera posibilitatea conservarii relatiilor de pozitionare din spatiul initial in cel transformat.
Pentru realizarea hartilor fonetice se poate utiliza o retea Kohonen cu un strat de iesire de forma plana, asa cum este prezentata in fig. 17. In fig. 16 sunt prezentate doua harti fonetice obtinute folosind reteaua Kohonen.
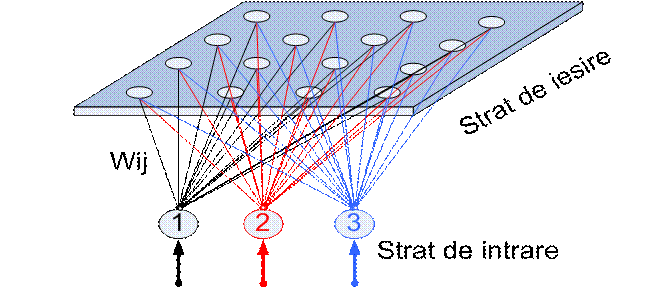
Fig.17.Structura retelei neuronale Kohonen cu strat de iesire bidimensional.
6 Modele cu logica fuzzy
Studiile arata ca in articulatia vorbirii umane nu exista delimitari nete, binare. Acest fapt isi are cauza in principal in variabilitatea ca pronuntie a vorbitorilor si in diversitatea coarticulatiilor (contextelor) posibile. Totusi cand vrem sa stabilim care este "unitatea fonetica' emisa, daca nu pot fi luate decizii clare putem sa ne adaptam la variabilitatea datelor de intrare printr-o decizie fuzzy, o decizie vaga, nuantata.
Logica fuzzy a fost propusa in 1965 de catre iranianul Lotfi Zadeh si si-a gasit numeroase aplicatii, in special in teoria recunoasterii si a reglarii automate.
Logica propusa lucreaza cu variabile 'vagi', nebinare. Daca se considera dependenta α(x), pentru definirea variabilei α in logica binara sunt valabile relatiile:
α = 1 x > xp
α = 0 x ≤ xp
care in logica fuzzy devin: α = 1 ; x > xp
0 < α < 1 ; x ≤ xp

Fig.18. Variabila fuzzy αv
Se vede ca se poate defini astfel o masura variabila, α cuprinsa intre 0 si 1 a apartenentei lui x la domeniul x ≤ xp.
Un exemplu din domeniul vorbirii ar putea prezenta interes. In testele de recunoastere a vocalelor 'o' si 'u' una din trasaturile esentiale preferate in clasificare este diferenta F3 - F1 unde F1, este frecventa formantului de ordin 1. Pentru 'o'', F3 - F1< 2,05 kHz, exista insa cazuri cand F3 -F1 ajunge pana la 2,1 kHz. Pentru 'u' F3-F1> 2,25kHz dar sunt cazuri cand aceasta diferenta poate scadea pana la 2,1 kHz. O reprezentare fuzzy a acestei situatii este prezentata in Fig.19.
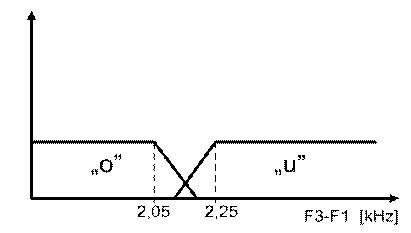
Fig. 19. Decizie fuzzy in recunoasterea vocalelor o si u .
In domeniul de incertitudine, cu 2,05< F3 - Fi<2,25 decizia se ia in favoarea vocalei la care gradul de apartenenta α este mai mare, construindu-se astfel o punte catre solutionarea comoda a unei probleme care nu parea usor de rezolvat.
Pe langa faptul ca se acomodeaza bine datelor acustice, care reprezentate parametric nu acopera un domeniu delimitat de reguli binare, punctul de vedere fuzzy se potriveste si reactiei umane, care este diferita de cea a unei masini, a unui aparat.
Putem spune deci ca logica fuzzy se adapteaza bine datelor acustice si ca intr- un anume fel 'umanizeaza' , decizia luata intr-un sistem de recunoastere, efectele pozitive concretizandu-se in rate de recunoastere crescute .
7 Alinierea temporala dinamica (ATD)
Problema compararii secventelor spectrale pentru vorbire apare din faptul ca diferite realizari acustice ale aceleiasi rostiri (cuvant, fraza, propozitie) au foarte rar aceeasi rata a vorbirii. Deci fluctuatiile ratei vorbirii trebuie mai intai normalizate inainte sa fie luata decizia recunoasterii, pentru a avea sens comparatia rostirilor.
Consideram doua forme de rostire X si Y reprezentate de secventele spectrale (x1, x2, ,xTx ) si (y1, y2, . yTy) unde x, si y, sunt vectorii de parametri ai caracteristicilor acustice pe timp scurt. Folosim ix si iy pentru a reprezenta indicii temporali ai celor doua forme X si Y.
Duratele celor doua rostiri Tx si Ty nu sunt neaparat identice. Nesimilaritatea intre X si Y este definita considerand o functie a distorsiunilor spectrale pe timp scurt d (xix, x;iy), care va fi notata pentru simplitate cu d (ix, iy), unde ix = l, 2, , Tx, iar iy_=l, 2,, Tv. . Deoarece ordinea secventiala a sunetelor este critica in definirea unei rostiri, este necesar ca indicii perechilor spectrale care urmeaza sa fie comparate sa satisfaca anumite conditii. Interactiunea intre aceste constrangeri secventiale si variatiile naturale ale ratei vorbii constituie una dintre problemele centrale ale recunoasterii vorbirii si anume, problema alinirii temporale si normalizarii.
Rezolvarea acestei probleme presupune folosirea a doua functii de deformare φx, φy,, care asociaza indicii celor doua rostiri, ix si iy cu o axa k a timpului comuna.
i x = φx (k )
k=1,2,.. T
i y = φy (k)
O masura globala a nesimilaritatii formelor dφ, (X, Y) poate fi definita pe baza functiei de deformare φ=( φx,, φy) astfel :
T
dφ, (X, Y) = ∑ [d (φx (k ), φy (k) ] n (k) / M φ
k = 1
unde d [(φx (k ), φy (k)] este o distorsiune spectrala pe timp scurt definita pentru xφx (k) si yφy (k) ; m(k) este un coeficient de ponderare a caii, iar M φ este un factor de normalizare a caii.
Gasirea celui mai bun aliniament intre o pereche de forme este echivalenta cu gasirea celei mai bune "cai' intr-o matrice a caracteristicilor acustice, in care cele doua forme au duratele Tx, respectiv Ty . Gasirea celei mai bune cai necesita rezolvarea unei probleme de minimizare pentru care de cele mai multe ori se apeleaza la tehnici de programare dinamica.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 3505
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved