| CATEGORII DOCUMENTE |
| Aeronautica | Comunicatii | Electronica electricitate | Merceologie | Tehnica mecanica |
FiabilitateA echipamentelor de calcul
1. Introducere
In acest capitol se prezinta arhitectura echipamentelor de calcul dintr-un singur punct de vedere, si anume cel al fiabilitatii. Prezentarea nu va fi exhaustiva si nici matematizata; se vor folosi mai ales exemple pentru a ilustra cum felurite consideratii despre fiabilitate influenteaza structura echipamentelor de calcul.
Principalul subiect al teoriei fiabilitatii consta in construirea de echipamente cat mai fiabile din componente nefiabile. Daca un echipament ar functiona numai atunci cand toate componentele sale ar fi functionale, ar fi virtual imposibil de construit un echipament complex, pentru ca fiabilitatea ar descreste exponential cu numarul de componente din structura sa.
Principala unealta folosita in construirea echipamentelor complexe este abstractia. Un echipament este construit pe nivele: nivelul B este alcatuit din componente de nivel A. La randul lor, componente de nivel B sunt folosite ca si cum ar fi atomice, indivizibile, pentru a construi nivelul C, si asa mai departe. Acest proces este inspirat din matematica, unde lemele si teoremele sunt folosite drept componente elementare in demonstratiile altor leme si teoreme. In acest capitol se prezinta alcatuirea unor nivele din arhitectura echipamentelor de calcul din punctul de vedere al fiabilitatii pe care o ofera nivelelor superioare. Astfel putem distinge:
Nivele care maresc fiabilitatea, construind un echipament mai fiabil din componente mai putin fiabile. Acest lucru este obtinut folosind redundanta in stocarea sau calculul informatiei. Acest tip de nivel este cel mai adesea folosit in constructia calculatoarelor contemporane.
Nivele care expun lipsa de fiabilitate nivelelor superioare, lasandu-le pe acestea sa rezolve imperfectiunile. Nivelele superioare au adesea informatii suplimentare despre cerintele reale de fiabilitate ale echipamentului si ca atare pot construi fiabilitatea pe masura necesitatilor.
Anumite nivele partitioneaza resursele in parti oarecum independente, izolate una de alta. Partitionarea are drept efect izolarea defectelor (fault isolation), astfel incat o defectiune intr-o parte sa nu afecteze celelalte parti. In calculatoare aceasta tehnica este folosita in sistemele de operare si clustere-le de calculatoare.
La ora actuala circuitele integrate pe scara larga (Very Large Scale Integrated circuits, VLSI) au ajuns la nivele incredibile de fiabilitate. Ca atare arhitectii calculatoarelor privesc in general nivelul hardware ca fiind "perfect" si folosesc aceasta abstractie foarte convenabila in proiectarea nivelelor superioare. Anumite clase de aplicatii au nevoie insa de o fiabilitate foarte ridicata (de exemplu, controlul de trafic aerian, supervizarea centralelor nucleare sau a echipamentelor militare). In astfel de misiuni critice proiectantii echipamentelor de calcul iau in considerare si posibilitatea defectelor hardware, pe care le trateaza in software.
Miniaturizarea continua a circuitelor integrate va conduce la schimbari in aceasta stare de fapt, astfel incat trebuie sa ne asteptam ca in viitor circuitele sa contina din ce in ce mai multe defectiuni si sa fie din ce in ce mai sensibile la fluctuatii termodinamice si particule de inalta energie din radiatia cosmica sau chiar din degradarea radioactiva a circuitului integrat respectiv. Astfel de schimbari vor necesita o reproiectare completa a arhitecturii echipamentelor de calcul.
Ingredientul cel mai folosit pentru a construi echipamente fiabile este redundanta. In cazul echipamentelor de calcul putem distinge doua genuri de redundanta, spatiala si temporala:
Redundanta spatiala foloseste mai multe componente decat strictul necesar pentru a implementa un anumit echipament de calcul. Resursele aditionale fac calcule suplimentare si rezultatele sunt comparate intre ele. In general, cu cat redundanta unui echipament de calcul este mai mare, cu atat poate detecta sau tolera mai multe erori.
Redundanta temporala consta in folosirea aceluiasi dispozitiv pentru a calcula acelasi lucru in mod repetat, dupa care rezultatele sunt comparate intre ele.
Defectele ce afecteaza componenta soft a unui echipament de calcul se pot clasifica in doua mari categorii:
Erori tranzitorii, care se manifesta printr-o functionare temporar eronata a unei componente, dar nu prin defectarea ei definitiva. In echipamentele de calcul contemporane, cea mai mare parte a erorilor sunt tranzitorii.
Erori permanente care se produc la un moment dat si persista pana cand echipamentul este reparat. In aceasta categorie includem si defectele din faza de proiectare sau din fabricatie.
Rezulta ca redundanta temporala poate fi folosita numai pentru a tolera defectele tranzitorii. Pentru a tolera efecte permanente trebuie sa avem o forma de redundanta spatiala.
2. Proiectarea echipamentelor de calcul
Cand proiectam un echipament complex este foarte important sa "echilibram" fiabilitatea partilor. De exemplu, daca memoria unui echipament de calcul are o fiabilitate mult mai mare decat procesorul, atunci echipamentul se va defecta cel mai adesea cu probleme de procesor. Faptul ca memoria este de foarte buna calitate nu ne ajuta cu nimic, dimpotriva probabil ca am platit un pret mai mare pentru memorie decat ar fi fost strict necesar. In general, o componenta este "destul de buna" daca nu are cea mai mare probabilitate de defectare.
In cazul analizei fiabilitatii unui echipament trebuie sa socotim nu numai costul componentelor fiabile, ci si costul intretinerii echipamentului in timpul misiunii sale (vezi figura 1.2). Daca utilizam componente foarte fiabile platim prea mult pentru constructia echipamentului, iar daca utilizam componente cu fiabilitate prea redusa, ne va costa prea mult intretinerea echipamentului. Numai contextul poate dicta cat de fiabil trebuie sa fie un echipament: de exemplu, in aplicatiile critice descrise mai sus, costul ne-functionarii echipamentului este urias, asa incat are sens sa investim in componente extrem de fiabile.
Evitarea defectelor echipamentelor de calcul este o metodologie idealizata, care presupune ca toate componentele sunt perfecte. Pentru ca hardware-ul actual are o calitate exceptionala, nivelul software in calculatoarele obisnuite adopta o astfel de viziune idealizata. Programatorii presupun ca echipamentul pe care se ruleaza programele lor este lipsit de defectiuni.
Fiabilitatea excelenta a dispozitivelor hardware este obtinuta printr-o combinatie de tehnici, cum ar fi felurite forme de redundanta, proiectare si fabricatie cu precizie foarte ridicata, si o faza agresiva de testare si "ardere" (burn-in).
Empiric s-a observat ca echipamentele de calcul tind sa aiba o mortalitate care urmareste o curba in forma de cada de baie, echivalenta ratei mortalitatii din studiile demografice. Echipamentele foarte tinere si cele foarte uzate se strica mult mai des decat echipamentele "mature". "Burn-in" este o faza de testare care foloseste componentele pana devin mature si in acest fel, componentele cu mortalitate infantila ridicata sunt eliminate in aceasta etapa.
In plus fabricantii proiecteaza si testeaza echipamentele de calcul in conditii mai nefavorabile decat cele specificate. De exemplu, pe acest fapt se bazeaza cei care fac "overclocking": specificatiile unui procesor indica frecventa de ceas la care acesta poate opera, insa in mod frecvent un procesor cu specificatie de ceas de 1Ghz poate opera la 1.2Ghz, datorita marginilor de toleranta din fabricatie.
Metoda evitarii defectelor este cu adevarat extrema. Intrucat s-a constatat ca oricare dintre componente se poate defecta, se utilizeaza proceduri de mentinere a echipamentului in functionare prin implementarea "tolerantei la defectare" (fault-tolerance).
2.1. Structuri tolerante la defectari
O metoda foarte simpla, dar scumpa, de a tolera erori este de a multiplica fiecare componenta. De exemplu, daca duplicam intreg echipamentul de calcul, aparitia unui defect poate fi detectata comparand rezultatele celor doua echipamente cu structura identica.
O alta modalitate de a tolera defectele consta in utilizarea structurilor TMR ( 4.3.1.1). In aceasta structura trei module fac aceeasi operatie si un modul de decizie ("voter") alege rezultatul majoritar. Structura va avea performante net superioare unui singur modul, insa cu un pret considerabil mai ridicat. Intrucat voterul devine elementul "slab" al structurii, exista si scheme in care echipamentul de votare este multiplicat, pentru ca decizia sa nu depinda de o singura componenta.
Un astfel de echipament de votare este folosit in calculatoarele care controleaza navetele spatiale: echipamentul este compus din cinci calculatoare, din care patru fac aceleasi calcule si al cincilea este folosit pentru operatiuni ne-critice. Rezultatele celor patru calculatoare se duc pana la echipamentele controlate (exemplu: motoare de propulsie), care calculeaza local rezultatul votului. In plus, fiecare calculator compara rezultatele cu celelalte trei, iar atunci cand unul dintre ele da rezultate diferite este scos din functiune.
Daca doua calculatoare se defecteaza, echipamentul intra intr-un mod de functionare in care rezultatele sunt comparate si recalculate atunci cand difera. Al cincilea calculator contine un echipament de control complet separat, dezvoltat de alta companie, care intra in functiune cand un bug identic este detectat in celelalte patru programe.
In continuare vor fi prezentate o serie de structuri de echipamente de calcul tolerante la defectari:
A) Procesorul IBM G5 din echipamentul S/390. In cazul acestui procesor se foloseste un tip de redundanta hibrida, care utilizeaza redundanta spatiala pentru a detecta erori tranzitorii si redundanta temporala pentru a le remedia. Acest echipament este asemanator cu modul de functionare cu doua defectiuni folosit de naveta spatiala, descris mai inainte.
Microprocesorul G5 contine doua benzi de executie identice, care sunt controlate de acelasi ceas. Toate instructiunile sunt executate in mod sincron de ambele benzi, iar la sfarsitul executiei rezultatele sunt comparate. Daca rezultatele sunt identice, rezultatul instructiunii este scris in registrul destinatie sau in memorie. Daca nu, se genereaza o exceptie software, care de obicei se soldeaza cu re-executia instructiunii-problema. Erorile tranzitorii sunt astfel reparate in mod transparent. Aceasta schema este functionala pentru ca probabilitatea ca o eroare tranzienta sa afecteze ambele benzi in acelasi mod este una foarte mica.
B) Procesor superscalar tolerant la erori tranzitorii. O schema foarte originala care foloseste doar redundanta temporala pentru a tolera erori tranzitorii a fost propusa in anul 2001 la conferinta de microarhitectura MICRO 2001 de un grup de cercetatori de la universitatea Carnegie Mellon. In aceasta schema unui procesor superscalar obisnuit i se fac cateva modificari simple, astfel incat fiecare instructiune citita sa fie lansata in executie in mod repetat. Metodele de redenumire a registrilor folosite in procesorul superscalar fac din executarea unor instructiuni suplimentare, care nu afecteaza echipamentul, un lucru foarte simplu. La sfarsitul benzii de asamblare rezultatele copiilor lansate in executie sunt comparate intre ele. Robustetea depinde de gradul de redundanta: daca fiecare instructiune este executata de doua ori, o eroare se manifesta prin rezultate diferite si instructiunea trebuie re-executata; daca o instructiune este executata de mai mult de doua ori, se poate folosi o schema de votare cu majoritate.
Un astfel de procesor poate fi proiectat sa lucreze fie in mod normal, fie in mod cu fiabilitate crescuta, depinzand de tipul de program executat. Performanta in modul cu fiabilitate ridicata este invers proportionala cu gradul de redundanta; de exemplu, daca fiecare instructiune este executata de doua ori, ar putea rezulta o scadere a vitezei de calcul la 50%. In realitate, penalizarea este ceva mai mica, din cauza ca un program nu foloseste toate resursele computationale. De exemplu, daca un program foloseste 80% din resurse, cand executam programul duplicand fiecare instructiune avem nevoie de 160% resurse, ceea ce se traduce intr-o degradare a performantei cu 37,5% (100/160 = 62,5 = 100 - 37,5).
C) Echipament de calcul tolerant la defectari avand arhitectura cu verificare dinamica. Aceasta structura, propusa in anul 1999 de catre cercetatorii de la universitatea Michigan este cunoscuta sub numele de DIVA, de la Dynamic Implementation Verification Architecture (arhitectura cu verificare dinamica).
Spre deosebire de schemele anterioare, structura DIVA e proiectata pentru a tolera atat erori tranzitorii, cat si permanente (cele din urma doar in anumite parti ale echipamentului). Observatia centrala pe care se bazeaza DIVA rezida din faptul ca este ca e mai usor de verificat daca rezultatul unui calcul e corect decat este de efectuat calculul insusi. Ca atare, arhitectura DIVA este compusa din doua procesoare diferite, fiind prezentata in figura 1.
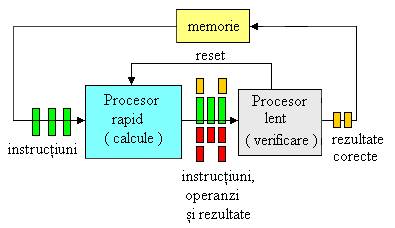
Fig.1. Structura echipamentului de calcul DIVA
Aceasta structura contine:
Un procesor complex, superscalar, foarte optimizat, care face calculele in mod normal.
Un procesor extrem de simplu, mai lent, dar foarte fiabil, care executa instructiunile in ordine, si este construit folosind tehnici de evitare a defectelor.
Echipamentul de calcul DIVA functioneaza astfel:
Procesorul complex executa toate instructiunile si calculeaza rezultatele lor. Rezultatele insa nu sunt scrise, ci sunt transmise procesorului simplu (lent si fiabil).
Procesorul simplu merge ceva mai incet, si verifica in paralel toate detaliile rezultatelor primite. Desi acest procesor este mai simplu, are o treaba mai usoara, si ca atare poate atinge aceeasi performanta ca cel rapid (exprimata in instructiuni procesate pe secunda). Cand verificarea descopera o eroare, procesorul simplu calculeaza rezultatul corect si re-porneste procesorul complex de la instructiunea urmatoare.
Foarte interesant este faptul ca o arhitectura DIVA poate tolera chiar erori de proiectare in procesorul foarte complicat, pentru ca acestea sunt detectate si corectate de procesorul lent si simplu. Poate fi chiar avantajos ca procesorul rapid sa fie proiectat "incorect", dar extrem de rapid, in cazul in care nu produce rezultate eronate prea frecvent. De exemplu, intr-un procesor normal foarte multe circuite suplimentare sunt introduse pentru a trata corect cazul programelor care se auto-modifica. In realitate, practic nici un program modern nu foloseste aceasta tehnica in mod curent; procesorul rapid fara aceste circuite poate fi facut mult mai eficient, iar corectitudinea calculelor va fi asigurata de catre procesorul lent.
2.2. Coduri detectoare si corectoare de erori
S-au prezentat deja mai multe exemple de folosire a redundantei spatiale pentru detectarea si corectarea erorilor. Costul schemelor prezentate mai inainte este substantial: ele cer o multiplicare identica a unui intreg echipament. De exemplu, redundanta modulara tripla are o eficienta de 33%, pentru ca hardware-ul este multiplicat de trei ori.
E interesant de explorat daca nu putem obtine aceleasi beneficii cheltuind mai putine resurse suplimentare. Deschizatori de drumuri au fost in aceasta privinta Claude Shannon si Richard Hamming, spre sfarsitul anilor '40. In continuare se prezinta metodele propuse de ei pentru a stoca informatie utilizand structuri tolerante la defectari.
Sa presupunem ca dorim sa stocam niste informatii codificate in baza doi intr-un mod fiabil. Putem atunci de pilda face doua copii ale informatiei. Dar o defectiune a unui singur bit va face informatia de nerecuperat, pentru ca acel bit va fi diferit in cele doua copii, si nu putem deduce care este valoarea originala. Slabiciunea acestei metode consta in faptul ca bitii stocati nu sunt "robusti": fiecare bit din mesaj este reprezentat in doar doi biti din cod.
Pentru a obtine toleranta la erori trebuie sa adaugam redundanta in cod; astfel, vom codifica n biti de informatie folosind m > n biti de cod. Cu cat m e mai mare ca n, cu atat mai robust va fi codul nostru. Cuvintele de m biti care reprezinta coduri corecte se numesc "cuvinte de cod" (code words). Se observa ca nu toate cuvintele de m biti sunt cuvinte de cod, ci numai 2n dintre ele.
Se poate defini distanta Hamming intre doua siruri de biti ca fiind numarul de diferente intre cele doua siruri. De exemplu, distanta Hamming dintre 1111 si 1010 este 2, pentru ca cele doua siruri difera in pozitiile a doua si a patra. Cea mai mica distanta Hamming dintre cuvintele unui cod este o masura foarte buna a robustetii codului. De exemplu, daca distanta Hamming intre oricare doua cuvinte este mai mare decat 3, atunci o schimbare de 1 bit poate fi intotdeauna corectata: cel mai apropiat cuvant de cod este cel care a fost modificat de eroare, pentru ca toate celelalte cuvinte de cod se vor afla la o distanta mai mare de 2 de cuvantul eronat. Astfel, un cod cu distanta Hamming 3 poate corecta orice eroare de 1 bit, si poate detecta orice eroare de doi biti. Un astfel de cod va detecta si alte erori, de exemplu va detecta unele erori de trei biti, dar nu orice eroare de trei biti. Exista efectiv zeci de coduri diferite, fiecare potrivit in alte circumstante.
Codurile detectoare si corectoare de erori sunt folosite pe larg in retelele de calculatoare. Depinzand de caracteristicile canalului de comunicatii (distanta, cost de transmisiune, viteza semnalului, zgomot) se pot folosi coduri mai mult sau mai putin robuste. In anumite cazuri e preferabil ca erorile sa fie detectate si datele incorecte sa fie retransmise, in alte cazuri costul retransmisiei este prea mare, si ca atare se folosesc coduri corectoare. Folosirea unui cod corector in transmisiunea de date se mai numeste si codare preventiva (Forward Error Correction).
Pentru comunicatia cu sondele spatiale se folosesc coduri corectoare de erori extrem de robuste, pentru ca la astfel de distante semnalul electromagnetic are nevoie de multe minute pentru a se propaga. In 1993 un grup de cercetatori francezi a inventat o clasa de coduri extrem de robuste numite Turbo-coduri care, folosind o redundanta relativ redusa de 200%, obtin o rezilienta exceptionala la zgomot, fiind foarte aproape de limitele maxime teoretice.
Turbo-codurile ilustreaza un nou tip de compromis pe care proiectantul il poate face in relatia robustete/cost: costul cel mare al unui turbo-cod nu este in cantitatea mare de informatie suplimentara, ci in algoritmul de decodificare, care este foarte complicat si necesita multe iteratii. Dupa cum am vazut si in cazul memoriilor, cu aceeasi redundanta putem obtine garantii diferite de fiabilitate, in functie de algoritmul de codificare folosit. In cazul comunicatiei interplanetare costul transmisiunii face costul decodificarii insignifiant, deci turbo-codurile sunt potrivite.
2.3. Memorii tolerante la defectari
In functie de modalitatile utilizate in scopul protectiei impotriva erorilor, memoriile in structura unui echipament de calcul se pot clasifica astfel:
Memoriile neprotejate. Aceste memorii stocheaza fiecare bit de date in mod separat si nu ofera nici o protectie impotriva erorilor. Ca atare sunt cele mai ieftine. Cum insa dimensiunea memoriilor a crescut foarte repede, la ora actuala aceasta solutie este riscanta, caci probabilitatea ca nici un bit sa nu se defecteze este foarte redusa.
Memoriile cu paritate. Aceste memorii folosesc o metoda foarte simpla pentru a detecta erori de un bit in fiecare octet (si, in general, erori care schimba un numar impar de biti). Pentru fiecare 8 biti de date aceste memorii stocheaza un al noualea bit de paritate, a carui valoare este calculata astfel incat oricare cuvant de noua biti are un numar par de biti "1" (de aici si numele schemei).
Cand hardware-ul acceseaza memoria, automat verifica si paritatea. Daca paritatea nu este corecta se declanseaza o exceptie si echipamentul de operare decide cum trebuie sa actioneze. O solutie este de a opri programul care folosea acea memorie si de a marca memoria ca fiind defecta, astfel incat alte programe sa nu o poata refolosi. Verificarea paritatii este o operatie foarte rapida, care se poate face foarte simplu folosind structuri hardware, in paralel cu transferul informatiei.
Memoriile ECC. Acestea sunt protejate cu un cod sofisticat de corectie a erorilor (Error Corecting Code). Acest cod poate corecta automat orice eroare de 1 bit care apare intr-un cuvant de 64 de biti. Pentru acest scop memoria stocheaza fiecare cuvant de 64 de biti folosind cuvinte de cod de 72 de biti. Se observa ca "risipa" (overhead) acestei scheme este aceeasi cu cea a paritatii (9/8 = 72/64). Aceasta schema ofera corectie cu o robustete mai mica, pentru ca poate corecta o eroare la 64 de biti, spre deosebire de cealalta schema care poate detecta o eroare la 8 biti.
La fiecare acces la memorie hardware-ul verifica daca cuvantul de cod este corect, iar daca nu, calculeaza automat cel mai apropiat cuvant de cod pe care apoi il decodifica. Aceste operatii sunt destul de complicate, astfel incat un echipament cu memorii ECC functioneaza cu aproximativ 5% mai lent decat unul cu memorii ce utilizeaza principiul paritatii.
Discuri. Cel mai comun suport permanent de informatie este discul, in multiplele lui implementari: hard-disc, discheta, disc optic, compact-disc, flash-disk etc. Informatiile din aceasta sectiune sunt valabile pentru multe dintre aceste tipuri de discuri.
Discurile folosesc simultan doua metode diferite de redundanta spatiala; o protectie sporita este necesara din cauza ca discurile functioneaza intr-un mediu mult mai aspru decat memoriile: unele discuri au parti mecanice in miscare, care se uzeaza si se pot strica mai usor.
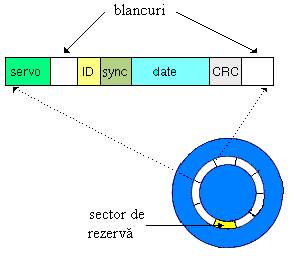
Informatia este stocata pe discurile clasice in sectoare. Un sector este relativ mare (comparat cu un cuvant de memorie), fiind de ordinul a jumatate de kilooctet (512 octeti). Discurile folosesc sectoare mari pentru ca la viteza lor de rotatie (peste 5000 de rotatii pe minut) capetele de citire/scriere nu se pot plasa foarte precis pe suprafata. Astfel, unitatea elementara in care se scrie pe un disc este sectorul: chiar daca vrem sa modificam un singur bit, trebuie sa rescriem tot sectorul.
In figura 2 este prezentat formatul unui sector de disc. Informatia servo este folosita pentru controlul miscarii capului, identificatorul indica numarul sectorului curent, iar informatia de sincronizare este folosita pentru a sincroniza pozitia capului cu inceputul sectorului.
|
|
Fig. 2. Formatul unui sector de disc |
Datele sunt stocate intr-un sir compact si codificate folosind un cod detector de erori. Intre doua sectoare consecutive este un blanc (spatiu liber), care-i da capului ceva libertate cand rescrie sectorul (niciodata nu va rescrie incepand chiar din acelasi loc).
Codurile folosite pentru discuri se numesc CRC, de la Cyclic Redundancy Check: coduri ciclice. Un cuvant de cod consta din chiar cuvantul de date urmat de informatii de control. Decodificarea codurilor CRC este foarte simpla: se extrage direct cuvantul de date, dupa care codul de control verifica daca vreunul dintre bitii stocati e incorect. Un cod ciclic are proprietatea ca orice permutare a datelor este protejata de acelasi cuvant de control.
Cand codul de control indica defectarea unui sector, discurile folosesc in mod automat a doua forma de redundanta spatiala: sectoare de rezerva. Pe disc sunt ascunse sectoare invizibile, care sunt folosite atunci cand sectoarele de date incep sa dea rateuri. In mod transparent software-ul aloca un sector de rezerva in locul unuia defect. Identificatorul de sector este folosit pentru a indica cine pe cine inlocuieste.
Discurile stocheaza o harta de defecte care indica sectoarele inlocuite, acest lucru permitand o functionare corecta si dupa ce apar defectiuni, si permite, de asemenea, un proces de fabricatie mai imperfect si mai ieftin.
Pentru stocarea de inalta fiabilitate a datelor se utilizeaza Flash Disk-uri. Aceste dispozitive au aparut din necesitatea ca in aplicatiile industriale sau de comunicatii portabile, sa fie nevoie de o capacitate de memorie de numai 80 MB sau mai putin, fiind necesara si o foarte buna rezistenta la socuri si vibratii. In astfel de cazuri, solutia folosirii unor unitati de hard-disk conventionale este improprie, fie si numai pentru motivul ca astazi nu se mai fabrica HDD-uri cu capacitati asa de mici. Pana acum singura solutie era utilizarea unui hard-disk cu o capacitate minima de 3-4 GB. In pofida excedentului de memorie, se putea intampla ca acesta sa se defecteze in mai putin de o luna de functionare efectiva, datorita mediului de lucru sever in care se desfasura misiunea. In mod normal, hard-diskurile au o fiabilitate ridicata in mediul de birou sau laborator, MTBF fiind de ordinul a multe zeci de mii de ore (echivalent a 8 ani de functionare continua sau 30 ani de utilizare normala). Insa acestea nu suporta lovituri sau socuri puternice, care le pot scoate definitiv din functiune, iar daca mediul de lucru prezinta vibratii, capetele se vor pozitiona eronat pe pista, generand erori soft (de citire) sau crescand considerabil timpul de acces (dureaza pana cand se repozitioneaza pe pista corecta).
O solutie partiala ar fi HDD-rile pentru notebook-uri, deoarece prezinta o rezistenta mecanica considerabil sporita, fiind compacte si special proiectate pentru o utilizare in medii cu socuri si vibratii. Insa capacitatea este tot excedentara, iar pretul este foarte ridicat.
Odata cu aparitia Flash Disk-urilor, problema pare a fi solutionata. Ideea inlocuirii mediilor magnetice cu memorii semiconductoare nu este noua, dar la inceput pretul era prohibitiv, iar capacitatea redusa. Au aparut apoi memoriile reprogramabile Flash. Initial, acestea erau doar un fel de EEPROM-uri mai performante, nu puteau fi sterse decat de un numar limitat de ori (de circa 10.000). Desigur, aceasta valoare este excelenta pentru o memorie programabila, dar cu totul insuficienta pentru a inlocui un disk magnetic. Ulterior au fost perfectionate, iar acum rezista la un milion de cicluri de scriere/citire. De asemenea, daca la inceput erau disponibile doar sub forma de cartele de memorie, acum emuleaza perfect o unitate de disk IDE, astfel ca ofera o solutie de stocare a datelor cu o mare fiabilitate hardware si software.
Absenta totala a componentelor in miscare face modulele de memorie Flash mai rapide si mai robuste decat mediile magnetice rotative, respectiv unitatile de hard-disk. Principalul dezavantaj il reprezinta pretul mai ridicat, dar pentru capacitati de stocare mici, ele reprezinta o alternativa convenabila la HDD. Termenul "mici" este ceva relativ: daca la inceputul anului 1993 insemna 1-2MB, acum se refera la 100-400MB. In momentul de fata sunt disponibile si Flash Disk-uri de peste 500MB, dar odata cu sporirea capacitatii, pretul creste considerabil.
In continuare se prezinta o comparatie intre Flash Disk-uri si unitatile de hard-disk miniatura (de 1,3 sau 2,5 inch). La capacitati mici, pana la 100MB, modulele Flash sunt categoric competitive. De fapt, la aceste valori mici, principalul concurent al Flash Disk-urilor il reprezinta memoria RAM statica, nu hard-diskurile. Pretul memoriei Flash este proportional cu capacitatea, deoarece capacitatea de stocare este direct proportionala cu numarul de circuite integrate Flash folosite. Unitatile de disk magnetic au un pret de baza ce include pretul componentelor mecanice si al controlerului. Pretul hard-diskului nu poate scade sub aceasta valoare de pornire, dar, marind suprafata mediului magnetic sau numarul de fete, se poate mari capacitatea cu o crestere de pret foarte mica.
In privinta rezistentei la socuri fizice, (cum ar fi simpla cadere a aparatului), modulele Flash sunt clar superioare hard-diskurilor. Gama de temperaturi de lucru este similara la cele doua categorii. Intervine insa, din nou, conceptul de fiabilitate software: in cazul unor variatii rapide de temperatura, HDD-urile clasice nu sunt disponibile imediat. Cand este adus de la o temperatura scazuta intr-o incapere incalzita, unitatea de hard-disk trebuie lasata sa se aclimatizeze, pentru a nu apare probleme cu condensarea umiditatii. Daca temperatura ambianta se modifica rapid si frecvent, sistemul de urmarire a pistelor pierde un timp considerabil cu operatiile de recalibrare. In aceste cazuri, disponibilitatea unitatii de disk este redusa. Flash Disk-urile nu prezinta asemenea probleme.
O comparatie directa a vitezelor este greu de realizat. Scrierea efectiva este mai lenta la Flash, dar hard-diskul necesita un timp pentru atingerea vitezei de rotatie de regim si prezinta intarzieri de rotatie si in trecerea de la o pista la alta.
Intr-o aplicatie tipica, memoria Flash este de 2-10 ori mai rapida decat hard-diskul. "Aplicatie tipica" este cea in care datele sunt citite de 4-5 ori mai des decat sunt scrise, iar transferurile de date tind sa fie scurte si nu foarte frecvente. Debitul de date in cazul unui transfer continuu este mai redus: 0,7-1 Moctet pe secunda la citire si 2-300 Kocteti pe secunda la scriere, fata de valoarea de 5 Mocteti pe secunda in mod rafala (burst).
Alte avantaje ale FlashDisk-urilor sunt nivelul sonor foarte redus in timpul functionarii (unele hard-diskuri pot fi destul de zgomotoase) si posibilitatea lucrului la altitudini foarte ridicate. Hard-diskurile au nevoie de o presiune atmosferica minima pentru a realiza perna de aer pe care plutesc capetele.
Caracteristicile generale ale Flash Disk-urilor sunt prezentate in continuare:
au dimensiunile clasice ale HDD-urilor obisnuite;
sunt Disk-uri cu interfata IDE, bazate pe o tehnologie Flash;
au capacitati de stocare extrem de flexibile: intre 4MB si 512 MB;
sunt mult mai stabile decat HDD-urile conventionale. Ele pot rezista la socuri si vibratii fiind astfel foarte potrivite pentru aplicatii ce se desfasoara in medii cu cerinte severe;
au un consum redus de energie;
sunt 100% compatibile IDE, nefiind necesara instalarea vreunui driver;
folosesc algoritmul de detectie si corectie al erorilor Reed Solomon pe 16 biti;
cu o interfata de 3,3V sau 5V, Flash Disk-urile suporta gestiunea automata a consumului de energie (APM) precum si comenzi ATA de intrerupere a alimentarii si mod "sleep" (atipire).
Cel mai important lucru este ca ofera o stabilitate mult mai buna a aplicatiilor, in medii de lucru dure, cu socuri si vibratii. In astfel de medii, unitatile de hard-disk clasice chiar daca nu se defecteaza, prezinta erori de cautare, astfel ca raspunsul devine lent, iar comportarea - aleatoare. Consumul redus de energie contribuie la cresterea duratei de viata a intregului sistem.
Capacitatea de stocare flexibila inseamna ca se poate utiliza un model cu capacitate foarte apropiata de cea necesara pentru aplicatie, pentru a nu creste costurile aferente cu memoria suplimentara ce nu va fi niciodata folosita. Comenzile interfetei IDE sunt conforme cu standardului industrial ATA-4.
Flash-Disk-urile au fost verificate cu succes sub urmatoarele sisteme de operare: MS-DOS, Windows 95/98/NT, Windows CE, OS2 Warp, Linux, QNX, Unix Ware. Media timpului de buna functionare (MTBF) este de peste 1.000.000 de ore. Fiabilitatea datelor memorate este asigurata prin functii incorporate de detectare si corectie a erorilor.
Flash-Disk-urile au performante foarte bune in ceea ce priveste anduranta: pentru operatii de scriere/citire sunt garantate pentru circa un milion de cicluri, iar pentru operatii de citire se prevede un numar nelimitat de astfel de operatii.
In ceea ce priveste viteza de transfer pe magistrala, aceasta este de peste 700 KB/sec in caz de citire sustinuta si de peste 250 KB/sec la operatii de scriere sustinuta. Flash-Disk-urile se remarca, de asemenea, prin gama temperaturilor de lucru (de la -25oC la +85oC) si prin altitudinea maxima la care pot functiona corect (16.000m).
Valorile prezentate mai inainte sunt valabile pentru FlashDisk-urile tipice. Realizarile de varf, "state of the art", au performante net superioare, insa si costurile de productie sunt mai ridicate. Astfel, firma BiT Microsystems produce seria E-Disk cu performante deosebite si cu o capacitate de stocare foarte ridicata. Se urmareste inlocuirea unitatilor de hard-disk cu module semiconductoare cu viteza de lucru mare, fiabilitate, longevitate si scalabilitate superioare. Rata de transfer este de 40 MB/sec in mod si de 34 MB/sec in mod sustinut, iar capacitatea poate ajunge pana la valoarea de 13.312 MB. Aceste dispozitive nu contin componente in miscare, care reprezinta principala cauza a defectarilor si intarzierilor electromecanice la HDD-urile clasice.
Ca dovada suplimentara a performantelor ridicate, E-Disk sunt prevazute nu cu obisnuita interfata EIDE, ci cu variante avansate de SCSI: SCA Ultra Wide SCSI cu tensiune diferentiala redusa.
Media timpului de buna functionare ajunge la 1,9 milioane de ore, se folosesc coduri detectoare si corectoare de erori foarte performante, astfel ca rata erorilor nedetectate este foarte scazuta. Astfel de dispozitive de stocare de inalta fiabilitate sunt ideale pentru telecomunicatii, transporturi, aplicatii industriale, aerospatiale sau militare, unde sistemele sunt supuse unor conditii de temperaturi extreme, campuri magnetice puternice, vibratii, praf, mizerie si vapori corosivi. Sunt de asemenea potrivite pentru aplicatiile unde este esential un coeficient foarte ridicat de disponibilitate si o viteza mare: depozite de date, multimedia, financiare, furnizori de servicii Internet, comert electronic, servere proxy etc.
In continuare se prezinta un alt tip de echipament fiabil redundant, care, spre deosebire de alte solutii prezentate, are o performanta mai buna decat echipamentul de baza. In plus, acest echipament adauga o dimensiune noua in spatiul optiunilor fiabilitatii, si anume capacitatea de a fi reparat in timp ce functioneaza (maintainability).
Structura este cunoscuta sub numele de RAID, care este o prescurtare de la Redundant Array of Inexpensive Disks, sau set redundant de discuri ieftine. Ideea a fost introdusa in 1987 de cercetatori de la universitatea Berkeley din California.
Ideea centrala a structurii RAID este de a stoca informatie pe mai multe discuri simultan. Informatia este codificata redundant, astfel incat sa poata fi recuperata daca oricare dintre discuri se defecteaza. Aceasta proprietate este foarte utila pentru echipamentele care trebuie sa functioneze continuu.
Exista mai multe tipuri de echipamente RAID, insa in continuare se prezinta unul singur, in care informatia este scrisa pe 5 discuri, din care 4 contin date si unul paritate. Un astfel de echipament RAID se poate afla intr-unul dintre trei moduri de functionare:
Functionare normala: operatiile de citire extrag date de pe cele patru discuri cu date. O operatie de scriere insa strange patru blocuri de informatie si calculeaza un al cincilea bloc de paritate; fiecare bloc este stocat pe alt disc. Acest mod de scriere se numeste "striping", adica "feliere", pentru ca datele sunt scrise in paralel, cate o felie pe fiecare disc.
Functionarea degradata: este inceputa cand un disc se defecteaza. Atunci citirile si scrierile de pe discul stricat trebuie sa acceseze celelalte patru discuri si sa calculeze informatia lipsa. Avantajul paritatii este ca oricare din bitii lipsa poate fi recalculat ca paritate a celorlalti patru biti.
Reconstructia: este inceputa cand un disc defect este inlocuit. Un proces secundar recalculeaza informatia lipsa si o scrie pe noul disc.
In continuare se prezinta un echipament de calcul dezvoltat de cercetatori de la Hewlett-Packard, care demonstreaza o metodologie extrema in tratamentul fiabilitatii echipamentelor. Acest echipament, cunoscut sub numele de Teramac, este construit din componente defecte: mai mult de 70% dintre circuitele sale componente au o malfunctie oarecare. Cu toate acestea, echipamentul functioneaza corect si poate efectua calcule extrem de performante.
Arhitectura echipamentului Teramac tolereaza numai defectiuni permanente, care sunt prezente inca de la fabricatie. Componentele Teramac sunt circuite hardware de un tip anume, numit hardware reconfigurabil. Inainte de a prezenta echipamentul Teramac se va face o prezentare succinta a structurii hardware-ului reconfigurabil, aratand cum un echipament fiabil poate fi construit din componente reconfigurabile nefiabile.
Intr-o prima aproximatie, circuitele digitale obisnuite sunt compuse din elemente computationale simple, numite porti logice, conectate intre ele prin sarme. Portile logice sunt construite din tranzistori. Fiecare poarta logica face calcule pe mai multe valori de 1 bit. Portile logice sunt universale, in sensul ca orice proces calcul poate fi exprimat in termeni de operatii ale portilor logice.
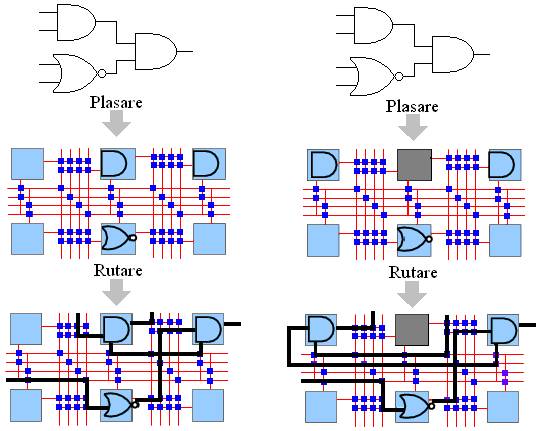
In hardware-ul reconfigurabil portile logice nu au o functionalitate fixata, iar sarmele formeaza o grila. Fiecare poarta este configurabila, adica poate fi fortata sa efectueze orice operatie logica. La fiecare intersectie de sarme se afla un mic comutator configurabil, care poate fi, de asemenea, programat sa conecteze sarmele. Configurarea portilor si a sarmelor se face prin semnale electrice. Fiecare poarta si fiecare comutator are o mica memorie asociata, in care-si stocheaza configurarea. Pentru ca schimband continutul acestor memorii putem schimba functionalitatea hardware-ului, circuitele acestea se numesc "reconfigurabile" (figura 3).
a) b)
Figura 3. Structura unui circuit reconfigurabil
Hardware-ul reconfigurabil este echivalent cu cel obisnuit, in sensul ca orice circuit poate fi implementat folosind ambele tehnologii. Hardware-ul reconfigurabil tinde insa sa fie ineficient: memoriile si portile configurabile ocupa mult mai mult loc decat portile obisnuite. Pe de alta parte, semnalele electrice care traverseaza doar sarme intr-un circuit obisnuit, trebuie sa treaca printr-o serie de comutatoare in hardware-ul reconfigurabil, ceea ce face circuitele mai lente. Un factor de 10, diferenta in viteza si densitate, este de asteptat intre un hardware obisnuit si cel configurabil de aceeasi generatie.
Pentru a programa un circuit reconfigurabil cu functiunea unui circuit obisnuit, trebuie sa asociem fiecare poarta din circuit cu o poarta configurabila; acest proces se numeste "plasare"; de asemenea, fiecare sarma trebuie asociata cu succesiuni de segmente legate prin comutatoare, in procesul de "rutare".
In figura 3-a procesul de plasare asociaza fiecare poarta logica din circuitul de implementat cu o poarta universala. Procesul de rutare conecteaza portile universale folosind segmente de sarma legate cu comutatoare. In cazul defectarii unora dintre portile universale plasarea si rutarea le pot ocoli, sintetizand un circuit perfect functional, situatie ilustrata in figura 3-b.
Calitatea circuitelor reconfigurabile exploatata de Teramac pentru a obtine fiabilitate este faptul ca portile logice configurabile sunt esentialmente interschimbabile. Cercetatorii proiectului Teramac au dezvoltat un program de plasare care foloseste o harta de defecte ale circuitelor reconfigurabile. Aceasta program ocoleste portiunile inutilizabile si ruteaza conexiunile in jurul defectelor, exploatand doar portiunile functionale ale fiecarui circuit (figura 3-b). Cercetatorii au creat si o serie de programe, care descopera si catalogheaza defectele. Programele acestea folosesc chiar programabilitatea circuitelor pentru a le configura ca dispozitive care se auto-testeaza. Fiecare portiune din fiecare circuit este programata sa efectueze calcule simple si sa verifice corectitudinea rezultatelor. Micile programe de test sunt "plimbate" pe suprafata circuitului, acoperind toate portile logice. Proiectarea unor programe de auto-testare este o sarcina mai complicata decat ar putea parea la prima vedere. Programele trebuie sa descopere o multime de defecte posibile si trebuie sa nu poata fi pacalite de defectiuni (de exemplu, daca chiar partea care compara rezultatele cu cele corecte este defecta). Programele de testare aplica in mod repetat calcule care amesteca toti bitii: astfel, aparitia unei singure erori se va propaga rapid la toti bitii din rezultat, fiind usor de depistat.
Proiectul Teramac a avut un succes enorm, principala sa contributie a constat in a demonstra ca defectele din hardware pot fi expuse nivelelor superioare, si pot fi tratate in intregime in software, fara ca costul platit in performanta sa fie prohibitiv. Aceasta metodologie este o schimbare completa de paradigma in arhitectura calculatoarelor, care probabil va avea din ce in ce mai multe aplicatii in viitor.
3. Fiabilitatea programelor
Ne-am putea astepta ca spre deosebire de hardware, software-ul sa nu aiba nici un fel de probleme de fiabilitate deoarece programele nu se uzeaza, si sunt executate intr-un mediu foarte specializat; in plus, programele sunt obiecte deterministe, deci ar trebui sa se comporte de fiecare data in acelasi fel cand proceseaza aceleasi date de intrare. Cu toate acestea, de fapt fiabilitatea programelor este mult mai scazuta decat a echipamentelor hardware; este potrivit sa modelam deci programele ca echipamente cu fiabilitate imperfecta. In aceasta sectiune se prezinta in mod superficial unele dintre motivele lipsei de fiabilitate a programelor si se mentioneaza unele tehnici care pot fi folosite pentru a realiza programe fiabile.
Cea mai importanta cauza a defectelor programelor sunt bug-urile, adica implementari incorecte. Chiar si programatori foarte priceputi produc programe cu defecte. Complexitatea componentelor software este pur si simplu prea mare, in momentul de fata, pentru a putea fi stapanita de catre oameni. Cu tot progresul in tehnici de programare, cum ar fi descompunerea programelor in module mici, folosirea unor limbaje de programare evoluate si a unor scule complexe pentru dezvoltarea, testarea si analiza programelor, rezultatele sunt inca foarte departe de perfectiune, iar productivitatea programatorilor nu a crescut substantial in ultimele doua decenii.
Cel mai adesea problemele rezolvate in software sunt atat de complicate incat nici nu pot fi specificate in mod precis. In consecinta programatorii intalnesc tot felul de incertitudini cand incearca sa implementeze solutiile. O cauza fundamentala a lipsei de fiabilitate a programelor este deci specificatia de proiectare incompleta si imprecisa.
Cele mai imprevizibile defectiuni software se manifesta numai cu ocazia unor anumite combinatii de valori pentru datele de intrare sau pentru anumite succesiuni de evenimente externe, care nu au fost prevazute de programator. Asemenea combinatii apar cu probabilitate foarte mica in timpul procedurilor normale de testare, deci adesea supravietuiesc pana in faza operationala.
A vedea programele software ca pe o entitate monolitica este o aproximare grosolana a realitatii: un program trece prin nenumarate revizii si imbunatatiri. Versiunile noi sunt construite pe scheletul celor vechi, reparand defectiunile descoperite si adaugand noi functionalitati. Cu toate acestea, procesul repararii defectiunilor introduce adesea noi defectiuni, pentru ca efectele unei reparatii au uneori consecinte imprevizibile.
Cresterea continua a performantelor hardware-ului este o motivatie constanta pentru reinnoirea echipamentelor software. Pe masura ce dispozitivele hardware devin mai ieftine si mai compacte, ele pot fi integrate in dispozitive electronice mai "destepte". Toate aceste noi dispozitive au nevoie de un nou software, care sa le manipuleze. Pe masura ce costul dispozitivelor de stocare a informatiei scade, din ce in ce mai complexe si mai bogate tipuri de informatie pot fi stocate si prelucrate. De exemplu, imagini si muzica sunt tipuri curent manipulate de PC-urile contemporane, iar capacitatea lor de prelucrare a devenit de curand suficient de puternica pentru a manipula in mod interactiv chiar filme.
Un fenomen legat de acest ciclu permanent de innoiri este cel cunoscut sub denumirea "putrezirea bitilor" (bit rot). Acest fenomen se manifesta pe doua planuri: datele stocate cu mult timp in urma nu mai pot fi folosite in noile echipamente de calcul, pentru ca dispozitivele periferice invechite nu mai sunt suportate de fabricanti, si programe vechi, care mergeau foarte bine, incep sa manifeste erori. "Boala" programelor este legata de mediul in care programele se executa, si care este in continua schimbare. De exemplu, multe programe vechi faceau anumite presupuneri despre cat de mari vor fi seturile de date pe care le vor prelucra. Cea mai faimoasa astfel de presupunere este cea care a cauzat bug-ul Y2K: programatorii din anii '60 au presupus ca programele lor nu vor manipula niciodata date calendaristice al caror an nu va incepe cu cifrele 19. Chiar daca Y2K a facut mai mult zgomot decat pagube, astfel de presupuneri se intalnesc la tot pasul in programele de astazi. De exemplu, pot apare dificultati in a transporta programe de la procesoare pe 32 de biti la procesoare pe 64 de biti. Din moment ce orice valoare pe 32 de biti se poate reprezenta exact atunci cand folosim 64 de biti, teoretic nu ar trebui sa fie nici o problema, si vechile programe ar trebui sa functioneze corect. In realitate multe programe depind in feluri subtile de precizia datelor pe care le manipuleaza. Cand un astfel de program este mutat pe o platforma noua toate aceste dependinte se transforma in bug-uri.
. Cresterea fiabilitatii produselor software
Domeniul ingineriei programelor (software engineering) se ocupa de metode prin care se poate cuantifica si imbunatati calitatea programelor. Una dintre solutiile studiate este foarte inrudita cu tehnicile de votare folosite pentru toleranta erorilor hardware. Numele acestei solutii in lumea software este "programare cu N versiuni". Votarea foloseste redundanta spatiala: dispozitivul de calcul este replicat de N ori si rezultatul final este obtinut prin votul majoritar al rezultatelor individuale.
Bug-urile software sunt persistente: aflat in aceleasi conditii programul se va comporta in acelasi fel. Tehnicile de votare sunt neputincioase daca toate componentele fac aceeasi eroare in acelasi timp. Votarea este utila pentru tratamentul erorilor tranzitorii. Programarea cu N versiuni se face deci prin executarea in paralel a N programe diferite, scrise de echipe diferite de programatori, daca e posibil, folosind scule si tehnologii diferite. Toate cele N programe rezolva aceeasi problema, dar in moduri diferite. Numai folosind o astfel de strategie tehnica votarii poate functiona in cazul programelor.
Specificatii imprecise ale problemei pot fi detectate cu usurinta de aceasta tehnica, pentru ca implementarile diferite pot lua decizii diferite pentru cazurile nespecificate clar. Din nefericire, programarea cu N versiuni este o metodologie foarte scumpa, folosita numai pentru aplicatii critice, unde siguranta este fundamentala.
Diferenta fundamentala intre hardware si software este aceea ca un program poate avea o stare interna arbitrar de complicata. In general, dispozitivele hardware pot fi aproximate ca fiind automate finite (adica spatiul starilor in care se pot afla, chiar daca este foarte mare, este totusi finit). Chiar si cele mai simple programe au un spatiu de stari infinit, mai exact, nu putem pune nici o limita arbitrara dimensiunii spatiului lor.
Aceasta diferenta este foarte importanta si din punct de vedere teoretic: foarte multe proprietati interesante ale automatelor finite se pot decide, adica se pot scrie algoritmi care atunci cand primesc descrierea unui automat finit, pot raspunde in mod exact la intrebari legate de orice evolutie viitoare a automatului. Din pacate, aceleasi intrebari pentru un echipament cu stare infinita adesea nu pot fi decise. Intr-adevar, matematicienii au aratat in anii '30 ca foarte multe dintre proprietatile unui echipament software, in general, nu pot fi calculate de un alt echipament software.
O consecinta practica a dimensiunii infinite a spatiului de stari ale programelor este ca, pe masura ce un program se executa mai mult timp, cu atat mai complicata poate deveni starea sa interna. Daca un program nu isi intrerupe executia, chiar daca va primi aceleasi date la intrare, ar putea calcula un raspuns diferit. Un bug in program poate corupe starea interna, dar efectele acestei defectari pot deveni vizibile mult mai tarziu in executia programului, cand programul ia o decizie bazata pe elementele de stare incorecte. Un tip faimos de problema, in mod normal benigna, asociata cu programele care se executa un timp indelungat, este scurgerea de memorie (memory leak).
Adesea programele aloca spatiu temporar de memorie, pe care il elibereaza dupa ce au terminat calculele care aveau nevoie de el. Daca programatorul uita sa elibereze aceasta memorie se spune ca memoria se scurge (leak). Aceasta este o eroare frecvent intalnita in programare, relativ greu de descoperit. In mod normal o astfel de eroare nu afecteaza corectitudinea programului: rezultatele produse la final sunt corecte. Cand programul isi termina executia, echipamentul de operare recupereaza automat memoria scursa. In cazul programelor care se executa timp indelungat, cum ar fi echipamentele de operare sau serverele de web, daca o scurgere se intalneste in interiorul unei bucle, cu timpul memoria pierduta va creste pana cand toata memoria echipamentului este pierduta. In astfel de cazuri de obicei echipamentul isi inceteaza executia, sau functionarea sa devine extrem de lenta din cauza ca resursele ramase sunt insuficiente.
Utilizatorii echipamentului de operare Windows de la Microsoft au descoperit si o solutie pentru aceasta problema: reboot-area calculatorului. Numele stiintific pentru aceasta solutie este "reintinerirea programelor" (software rejuvenation). Reintinerirea este cauzata de repornirea periodica a programelor. Repornirea cauzeaza initializarea starii interne la o aceeasi valoare initiala. Tehnica aceasta este aplicabila numai daca starea interna a programului nu este importanta si poate fi pierduta; altfel, intinerirea trebuie sa fie combinata cu "checkpoint"-uri. Un checkpoint salveaza informatia importanta pe un mediu de memorie persistent, si o restaureaza dupa ce programul este repornit.
Reintinerirea se aplica cu precadere programelor de tip server, care executa tot timpul o bucla, acceptand cereri de la clienti si raspunzandu-le. Multe servere sunt lipsite de stare (stateless), adica nu pastreaza nici un fel de informatii despre o tranzactie cu un client dupa ce tranzactia s-a consumat. Reintinerirea este eficace daca costul repornirilor periodice este mai redus decat costul repornirii dupa o cadere catastrofica, care poate sa implice o procedura sofisticata de recuperare a datelor pierdute. Reintinerirea este de asemenea folosita cu succes cand serverele care ofera serviciul au rezerve, astfel incat serverele de rezerva pot raspunde clientilor in timp ce altele se reinitializeaza.
O alta modalitate de crestere a fiabilitatii programelor de calcul consta in utilizarea unei tehnici numita verificare formala. Acesta este un nume generic pentru o serie intreaga de tehnici sofisticate care certifica corectitudinea, mai ales a echipamentelor hardware, dar in ultima vreme si a unor echipamente software. Verificarea formala se ocupa de descoperirea si eliminarea bug-urilor, si in acest sens este o tehnica de crestere a fiabilitatii programelor.
Cheia metodelor de verificare formala este specificarea foarte precisa a comportarii componentelor echipamentului de analizat (folosind formule matematice) si verificarea automata a proprietatilor echipamentului in intregime. Daca stim cum este construit echipamentul, si daca stim comportarea fiecareia dintre componente, putem rationa despre comportarea ansamblului. Rationamentele pot fi facute foarte precise folosind diferite variante de logici matematice. Fiecare rationament este o serie de derivari, in care din fapte stiute ca fiind adevarate deducem alte adevaruri. Verificarea formala studiaza aceste derivari, si verifica faptul ca sunt corecte.
Doua aspecte fac din verificarea formala o tehnica foarte puternica:
1) calculele minutioase sunt efectuate de catre calculatoare, a caror atentie nu oboseste niciodata;
2) certitudinea nu vine din faptul ca demonstram ceva, ci din faptul ca putem verifica daca demonstratia este corecta.
Cand s-a descris echipamentul DIVA s-a facut mentiunea ca a verifica corectitudinea unui rezultat este mult mai simplu decat a demonstra rezultatul insusi. Acest fapt este extrem de folositor in contextul verificarii formale, in care programul care face demonstratiile este extrem de complicat, si ca atare poate contine erori (ca orice alt program complex) si deci poate genera demonstratii eronate. Un program care verifica daca o demonstratie este corecta insa este mult mai simplu, si ca atare ne ofera mai multa incredere.
4. Reteaua internet
Una dintre cele mai uimitoare tehnologii ale secolului douazeci este cu siguranta Internetul. Acesta este o retea de calculatoare, proiectata initial pentru a conecta retele militare de calculatoare si de a le permite sa opereze chiar si in conditiile distrugerii unui mare numar de echipamente din retea, de exemplu in cazul unei conflagratii nucleare. Internetul a evoluat astazi intr-o retea comerciala care acopera toate continentele, cu mai mult de 125 de milioane de calculatoare si peste 1 miliard de utilizatori.
Internetul nu este prima retea de dimensiune globala; cu mai mult de un secol inainte de crearea Internetului a aparut telefonul; retelele telefonice au cu siguranta intaietatea in acoperirea planetei. Ne-am astepta ca proiectantii Internetului sa fi folosit multe din tehnologiile folosite in constructia retelelor telefonice, despre care exista o cantitate mare de informatii si o experienta substantiala. In realitate, nimic nu poate fi mai departe de adevar: arhitectura Internetului pare a fi in mod deliberat opusa retelei de telefonie. Nicaieri nu se vede mai bine diferenta dintre cele doua retele decat in felul in care trateaza fiabilitatea.
Reteaua telefonica a fost proiectata de la inceput pentru o fiabilitate exceptionala. O centrala telefonica trebuie sa insumeze mai putin de trei minute de indisponibilitate in fiecare an. Numai in circumstante absolut exceptionale o conversatie initiata poate fi intrerupta datorita unor probleme din retea. Reteaua telefonica va permite stabilirea unei legaturi numai dupa ce a rezervat toate resursele necesare pentru transmisiunea prompta a semnalelor vocale pe intregul traseu dintre cele doua puncte care comunica. Standarde stricte dicteaza cat de mult timp poate dura faza de constructie a legaturii; daca nu pot fi obtinute toate resursele utilizatorul primeste un ton de ocupat. Capacitatea retelei este planificata atent pe baza unor statistici detaliate despre comportarea vorbitorilor, astfel incat in conditii normale, sansa obtinerii unui ton de ocupat din cauza resurselor insuficiente din retea sa fie extrem de redusa.
Un factor crucial care garanteaza calitatea conexiunilor telefonice este prealocarea tuturor resurselor necesare inainte ca legatura sa fie stabilita. Pornind de la numarul format, prima centrala telefonica calculeaza o secventa de centrale prin care semnalul trebuie sa treaca pentru a lega apelantul cu apelatul; acest calcul se bazeaza pe tabele de rutare pre-calculate cu mare grija si stabilite de catre proiectantii retelei. Fiecare centrala negociaza apoi cu cea succesiva folosind un protocol sofisticat de semnalizare, si aloca capacitate pentru transportul datelor si pentru comutarea acestora (care in centrala leaga circuitul de intrare cu cel de iesire). Cand toate conexiunile punct-la-punct intre centrale sunt stabilite se genereaza un ton de "apel". Cand conversatia a fost initiata, semnalul vocal este esantionat si digitizat in prima centrala. Pentru fiecare bit din acest semnal s-a prealocat deja o cuanta periodica de timp pe fiecare dintre circuitele pe care le va traversa. Bitii sunt transmisi unul cate unul si traverseaza toate trunchiurile in aceeasi ordine in care au fost generati, sosind la destinatie la timp pentru a fi reasamblati si convertiti la loc intr-un semnal auditiv. Din cauza prealocarii, de indata ce un bit intra in retea, cu o probabilitate extrem de ridicata el va ajunge la celalalt capat exact cand trebuie. Cand unul dintre vorbitori inchide telefonul, protocolul de semnalizare intra din nou intr-o faza complicata, prin care elibereaza toate resursele alocate la momentul apelului.
Reteaua Internet are o arhitectura fundamental diferita. Nu numai ca nu exista garantii despre timpul necesar pentru a ajunge de la emitator la receptor, dar nu exista nici o garantie ca datele nu sunt pierdute sau modificate in timpul transferului. Utilizatorii Internetului obtin un serviciu extrem de "slab", care poate fi enuntat pe scurt astfel: "tu pui date in retea si zici unde vrei sa ajunga, iar reteaua o sa incerce sa livreze datele acolo".
Felul in care informatia circula in reteaua Internet este complet diferit de reteaua telefonica: datele sunt divizate in pachete care sunt introduse in retea in ordinea sosirii. Fiecare pachet poate calatori pe o ruta complet diferita pana la destinatie. Unele pachete se pot pierde, alte pot fi duplicate, si ele pot sosi la destinatie in alta ordine decat au fost emise, sau chiar sparte in pachete mai mici.
Pachetele sunt plimbate prin Internet de un protocol numit IP, Internet Protocol. IP functioneaza aproximativ astfel: cand un calculator intermediar primeste un pachet se uita intai la adresa destinatie inscrisa. Apoi el face niste calcule simple pentru a decide in ce directie pachetul trebuie trimis, mai precis, caruia dintre vecinii sai trebuie sa-i dea pachetul. Pachetul este apoi trimis vecinului. Daca la un calculator intermediar pachetele vin mai repede decat apuca sa le trimita mai departe, si daca nici nu are unde sa le stocheze pentru o vreme, are dreptul sa le faca pierdute. Aceasta este principala cauza pentru care datele se pot pierde in Internet.
Spre deosebire de reteaua telefonica, structura Internetului nu este controlata de un numar mic de companii, ci este in continua schimbare, de la zi la zi si de la ora la ora, pe masura ce noi calculatoare se conecteaza, noi utilizatori suna folosind modemuri si noi linii de transmisiune sunt instalate. Calculatoarele responsabile pentru transmiterea datelor, numite rutere, discuta intre ele permanent pentru a afla care este forma curenta aproximativa a retelei. Aceste informatii sunt utilizate in procesul de decizie care selecteaza vecinul folosit pentru transmisiunea fiecarui pachet spre destinatie.
Data fiind aceasta infrastructura, este uimitor ca Internetul functioneaza catusi de putin, si ca informatia ajunge cateodata neperturbata la destinatie. Fiabilitatea aplicatiilor din Internet este construita pe baza acestui mediu extrem de nefiabil, folosind doua ingrediente:
1) Lipsa de stare. Ruterele din Internet nu stocheaza nici un fel de informatii despre traficul care le parcurge. Prin contrast, in reteaua telefonica, comutatoarele stiu despre fiecare bit care le traverseaza de unde vine, unde se duce, si cand va sosi succesorul lui. Un ruter primeste un pachet, calculeaza vecinul caruia sa-i dea pachetul si livreaza pachetul. Starea interna a ruterului dupa livrarea pachetului este aceeasi cu cea de dinainte. Asa cum am vazut in cazul reintineririi programelor, lipsa starii interne face mult mai simpla repornirea unui ruter dupa o defectiune. O defectiune nu pierde informatii vitale, care nu pot fi recuperate prin alte metode. De asemenea, lipsa starii face relativ usoara sarcina altor rutere de a prelua traficul in cazul defectarii unuia.
2) Protocolul TCP. Realizarea unei transmisii fiabile prin reteaua Internet se face utilizand un protocol numit Transmission Control Protocol (TCP), care se executa deasupra protocolului IP. Daca intr-o retea toate nodurile din interior executa IP, numai sursa si destinatia executa TCP. TCP este protocolul care construieste o transmisiune fiabila: el asigura ca toate pachetele trimise ajung la destinatie, fara lipsuri sau duplicate, in ordinea in care au fost trimise. TCP reuseste aceasta performanta folosind urmatoarele mecanisme:
numeroteaza pachetele trimise;
foloseste pachete de confirmare pentru a anunta sosirea datelor la capatul celalalt;
foloseste alarme pentru a detecta pachetele care nu sunt confirmate pentru un timp indelungat;
foloseste retransmisii pentru a retrimite pachetele care se pierd in retea.
Din cauza ca pachetele cu confirmari se pot pierde la randul lor, unele pachete sunt injectate in mod repetat in retea, ceea ce poate duce la livrarea unor duplicate; TCP trebuie sa le elimine folosind numerele de serie ale pachetelor.
Intregul Internet este construit pe nucleul nefiabil oferit de IP: nu numai datele si confirmarile sunt trimise in mod nefiabil, dar chiar si mesajele de control schimbate intre rutere, prin care afla despre schimbarile din topologia retelei si traficul folosit pentru monitorizarea si mentenanta retelei folosesc aceleasi mecanisme nefiabile de transmisiune.
In pofida structurii sale aparent subrede, Internetul este un competitor formidabil al altor forme de distributie a informatiei: radio, televiziune si telefonie. Costul transmisiunii vocii prin Internet este mult mai scazut decat folosind retelele specializate de telefonie. Multe companii importante de telefonie investesc in mod serios in echipamente care transporta voce peste protocolul IP.
Internetul muta problema fiabilitatii la un nivel superior, de la IP la TCP. TCP ofera o fiabilitate perfect adecvata pentru multe aplicatii. TCP este executat numai de catre calculatoarele terminale implicate in comunicatie, si nu de catre rutere. Ca atare algoritmii complicati folositi de acest protocol nu taxeaza resursele retelei, care scaleaza in mod natural la dimensiuni globale.
Mai mult, unele aplicatii care nu au nevoie de livrarea fiabila a datelor nu sunt obligate sa foloseasca protocolul TCP. De exemplu, protocoalele folosite pentru posturile de radio din Internet folosesc coduri puternice de corectie a erorilor si nu au nevoie de retransmisii. Pachete pierdute sau intarziate sunt pur si simplu ignorate. Acest lucru este acceptabil pentru ca utilizatorul final, omul, tolereaza semnale cu zgomot.
5. Concluzii
In acest capitol au fost prezentate unele consideratii privind modul cum fiabilitatea influenteaza constructia echipamentelor de calcul. O concluzie foarte importanta care rezulta din analiza facuta este ca desi fiabilitatea ridicata este dezirabila, un proiectant trebuie intotdeauna sa ia in consideratie si costul platit pentru a o obtine.
Calculatoarele moderne sunt construite dintr-o serie de nivele abstracte, care ofera functionalitati din ce in ce mai puternice. Fiecare nivel are o fiabilitate diferita si foloseste tehnici diferite pentru a oferi nivelelor superioare imaginea unei fiabilitati sporite. In general hardware-ul ofera lumii software aparenta perfectiunii in aceasta privinta, adica o fiabilitate exceptional de ridicata.
Tendintele tehnologiei indica insa ca arhitectura calculatoarelor viitorului va fi supusa unor schimbari radicale, unul dintre motive fiind chiar schimbarea majora a fiabilitatii unora dintre nivele. De exemplu, miniaturizarea continua a componentelor electronice va fi insotita de o degradare a fiabilitatii insotita de aparitia tot mai frecventa a defectiunilor permanente si tranzitorii. Costul platit pentru a masca aceste defecte prin tehnici traditionale creste extrem de rapid: costul extrem de ridicat al unei fabrici de semiconductoare din ultima generatie, de ordinul a cateva miliarde de dolari, este doar primul simptom al acestui fenomen.
In prezent, departamentele de cercetare ale firmelor producatoare de echipamente de calcul lucreaza in mod activ pentru a defini arhitecturile structurilor de calcul al viitorului. Directiile urmarite sunt prezentate in continuare:
Iluzia unui hardware perfect trebuie eliminata, imperfectiunile din nivelul hardware trebuie sa fie expuse nivelului software si rezolvate de acesta. Pentru a face acest lucru, baza echipamentelor de calcul trebuie sa fie hardware-ul reconfigurabil, care este suficient de flexibil pentru a fi reprogramat dupa nevoi.
Microprocesorul trebuie sa fie redus la un rol secundar si inlocuit cu hardware generat specific, pentru fiecare aplicatie, cu ajutorul compilatoarelor.
Numarul de nivele abstracte trebuie sa fie micsorat in mod dramatic, pentru a reduce costul suplimentar platit, care creste exponential.
Trebuie folosite in mod constant tehnici care descopera defecte si folosesc rezerve pentru a ocoli defectele de fabricatie.
Calculele trebuie sa fie efectuate folosind date codificate utilizand coduri robuste, pentru a preveni efectele erorilor tranzitorii.
Utilizarea pe scara larga a metodelor de verificare formala pentru a ne asigura ca echipamentele de calcul pe care le folosim sunt corect construite.
Stiinta calculatoarelor este relativ tanara si, cu siguranta, viitorul ne rezerva o multime de surprize in ceea ce priveste tehnologiile, arhitectura si algoritmii cei mai eficienti.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 2144
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved