| CATEGORII DOCUMENTE |
| Astronomie | Biofizica | Biologie | Botanica | Carti | Chimie | Copii |
| Educatie civica | Fabule ghicitori | Fizica | Gramatica | Joc | Literatura romana | Logica |
| Matematica | Poezii | Psihologie psihiatrie | Sociologie |
Testul t pentru esantioane independente
Testul z (t) pentru un singur esantion este util intr-un model de cercetare in care ne propunem compararea valorii masurate pe un esantion cu media populatiei din care acesta provine. Asa cum am precizat deja, acest tip de cercetare este destul de rar intalnit, ca urmare a dificultatii de a avea acces la media populatiei.
Un model de cercetare mult mai frecvent insa, este acela care vizeaza punerea in evidenta a diferentelor care exista intre doua categorii de subiecti (diferenta asumarii riscului intre barbati si femei, diferenta dintre timpul de reactie al celor care au consumat o anumita cantitate de alcool fata de al celor care nu au consumat alcool etc.). In situatii de acest gen psihologul compara mediile unei variabile (preferinta pentru risc, timpul de reactie etc.), masurata pe doua esantioane compuse din subiecti care difera sub aspectul unei alte variabile (sexul, consumul de alcool, etc.). Variabila supusa comparatiei este variabila dependenta, deoarece presupunem ca suporta "efectul" variabilei sub care se disting cele doua esantioane si care, din acest motiv, este variabila independenta1. In studii de acest gen, esantioanele supuse cercetarii se numesc "independente", deoarece sunt constituite, fiecare, din subiecti diferiti.
Distributia ipotezei de nul pentru diferenta dintre medii independente
Sa ne imaginam ca dorim sa vedem daca un lot de sportivi, tragatori la tinta, care practica trainingul autogen2 (variabila independenta) obtin o performanta (variabila dependenta) mai buna decat un lot de sportivi care nu practica aceasta tehnica de autocontrol psihic. In acest caz, variabila dependenta ia valori prin evaluarea performantei de tragere, iar variabila independenta ia valori conventionale, pe o scala nominala categoriala, dihotomica (practicanti si nepracticanti de sedinte de relaxare).
In acest exemplu avem doua esantioane de cercetare, unul format din sportivi practicanti ai trainingului autogen (TA) si altul format din sportivi nepracticanti ai TA. Ipoteza cercetarii sustine ca media performantei celor doua grupuri este diferita. Sau, cu alte cuvinte, ca cele doua grupuri provin din populatii diferite, respectiv, populatia sportivilor practicanti de TA si cea a nepracticantilor de TA. Trebuie sa acceptam faptul ca perechea de esantioane studiate nu este decat una din perechile posibile. Sa privim figura de mai jos, care ne sugereaza ce se intampla daca, teoretic, am extrage (selecta) in mod repetat de esantioane perechi din cele doua populatii:
Am pus cuvantul "efect" intre ghilimele deoarece, chiar daca este logic sa consideram ca este vorba de o relatie de tip cauza-efect, simpla masurare a diferentelor pe doua esantioane de subiecti nu este suficienta pentru a concluziona o relatie cauzala. Pentru aceasta, ar fi mai potrivit, spre exemplu, sa masuram timpul de reactie la aceiasi subiecti inainte si dupa consumarea unei cantitati de alcool.
O metoda de relaxare psihica
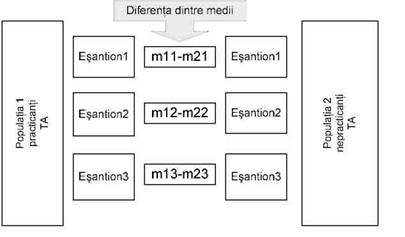
Imaginea arata faptul ca, pe masura ce constituim perechi de esantioane (m11-m21, etc.) cu valori ale performantei la tinta, diferenta dintre medii devine o distributie in sine, formata din valorile acestor diferente. Daca am reusi constituirea tuturor perechilor posibile de esantioane, aceasta distributie, la randul ei, ar reprezenta o noua populatie, populatia diferentei dintre mediile practicantilor si nepracticantilor de training autogen. Si, fapt important de retinut, curba diferentelor dintre medii urmeaza legea distributiei t. Cu alte cuvinte, la un numar mare (tinzand spre infinit) de esantioane perechi, trebuie sa ne asteptam ca cele mai multe medii perechi sa fie apropiate ca valoare, diferenta dintre mediile fiind, ca urmare, mica, tinzand spre 0 si ocupand partea centrala a curbei. Diferentele din ce in ce mai mari fiind din ce in ce mai putin probabile, vor ocupa marginile distributiei (vezi figura de mai jos). Aceasta este ceea ce se numeste "distributia ipotezei de nul" pentru diferenta dintre mediile a doua esantioane independente.
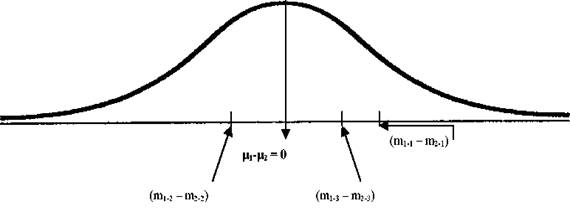
In acest moment este bine sa accentuam din nou semnificatia statistica a notiunii de populatie. Dupa cum se observa, aceasta nu face referire neaparat la indivizi, ci la totalitatea valorilor posibile care descriu o anumita caracteristica (psihologica, biologica sau de alta natura). In cazul nostru, diferentele dintre mediile esantioanelor perechi (fiecare provenind dintr-o "populatie fizica" distincta) devin o noua "populatie", de aceasta data statistica, compusa din totalitatea diferentelor posibile, a carei distributie se supune si ea modelului curbei t.
Procedura statistica pentru testarea semnificatiei diferentei dintre mediile a doua esantioane
Problema pe care trebuie sa o rezolvam este urmatoarea: este diferenta dintre cele doua esantioane suficient de mare pentru a o putea considera ca este in legatura cu variabila independenta, sau este doar una dintre diferentele probabile, generata de jocul hazardului la constituirea perechii de esantioane? Vom observa ca sarcina noastra se reduce, de fapt, la ceea ce am realizat anterior in cazul testului z sau t pentru un singur esantion. Va trebui sa vedem daca diferenta dintre doua esantioane reale se distanteaza semnificativ de diferenta la care ne putem astepta in cazul extragerii absolut aleatoare a unor perechi de esantioane, pentru care distributia diferentelor este normala. Mai departe, daca probabilitatea de a obtine din intamplare un astfel de rezultat (diferenta) este prea mica (maxim 5%) o putem neglija si accepta ipoteza ca intre cele doua variabile este o relatie semnificativa.
Daca avem valoarea diferentei dintre cele doua esantioane cercetate, ne mai sunt necesare doar media populatiei (de diferente ale mediilor) si abaterea standard a acesteia, pentru a calcula testul z (in cazul esantioanelor mari) sau cel t (in cazul esantioanelor mici). In final, nu ne ramane decat sa citim valoarea tabelara pentru a vedea care este probabilitatea de a se obtine un rezultat mai bun (o diferenta mai mare ) pe o baza strict intamplatoare.
Media populatiei de diferente. Diferenta dintre mediile celor doua esantioane ale cercetarii face parte, asa cum am spus, dintr-o populatie compusa din toate diferentele posibile de esantioane perechi. Media acestei populatii este 0 (zero). Atunci cand extragem un esantion aleator dintr-o populatie, valoarea sa tinde sa se plaseze in zona centrala cea mai probabila). Dar aceeasi tendinta o va avea si media oricarui esantion extras din populatia pereche. Ca urmare, la calcularea diferentei dintre mediile a doua esantioane, cele mai probabile sunt diferentele mici, tinzand spre zero. Astfel, ele vor ocupa partea centrala a distributiei, conturand o medie tot mai aproape de zero cu cat numarul esantioanelor extrase va fi mai mare.
Eroarea standard a diferentei (imprastierea), pe care o vom nota cu σm1-m2, se calculeaza pornind de la formula de calcul a erorii standard:
![]()
![]()
Din ratiuni practice, pentru a obtine o formula care sa sugereze diferenta
dintre medii (m1-m2), formula de mai sus
este supusa unor transformari succesive. Prin ridicarea la patrat a ambilor
termeni, si dupa extragerea radicalului din noua expresie, se obtine:
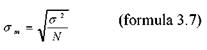
Formula erorii standard a distributiei diferentei dintre medii ne arata cat de mare este imprastierea diferentei "tipice" intre doua medii independente atunci cand esantioanele sunt extrase la intamplare

Formula 3.8 ne indica faptul ca eroarea standard a diferentei dintre medii este data de suma erorii standard a celor doua esantioane. Unul dintre esantioane are N1 subiecti si o dispersie σ12 iar celalalt esantion, N2 subiecti si dispersia σ22. Faptul ca obtinem eroarea standard a diferentei dintre medii ca suma a erorilor standard a celor doua esantioane este fundamentat pe o lege statistica a carei demonstratie nu se justifica aici.
Pentru a calcula scorul z al diferentei, vom utiliza o formula asemanatoare cu formula notei z pe care o cunoastem deja:
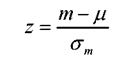
Aceasta va fi:
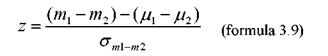
Numaratorul exprima diferenta dintre diferenta obtinuta de noi (m1-m2) si diferenta dintre mediile populatiilor (1-2). Daca ne amintim ca distributia ipotezei de nul (1-2) are media 0, atunci deducem ca expresia (1-2) poate lipsi. De altfel, daca am cunoaste mediile celor doua populatii nici nu ar mai fi necesara calcularea semnificatiei diferentei dintre esantioanele care le reprezinta.
Numitorul descrie eroarea standard a diferentei, calculata cu formula 3.7, adica imprastierea diferentei "tipice" pentru extrageri aleatoare.
In conformitate cu cele spuse pana acum, formula finala pentru scorul z al diferentei dintre doua esantioane devine :

Se observa ca am eliminat (1-2) de la numarator, care este intotdeauna 0 si am inlocuit σm1-m2 cu expresia echivalenta din formula 3.8. Aceasta formula ne da ceea ce se numeste valoarea testului z pentru esantioane mari-independente.
Valoarea astfel obtinuta urmeaza a fi verificata cu ajutorul tabelei z pentru curba normala, iar decizia statistica se ia in acelasi mod ca si in cazul testului z pentru un singur esantion.
In formula 3.9 eroarea standard a diferentelor este calculata pe baza erorii standard a distributiei de esantionare pentru populatiile din care sunt extrase cele doua esantioane ("practicanti" si "nepracticanti" de training autogen). In realitate nu cunoastem cele doua dispersii. Din fericire, daca volumul insumat (N1+N2) al esantioanelor care dau diferenta noastra (m1-m2) este suficient de mare (≥30 dar, de preferat, cat mai aproape de 100) atunci ne amintim ca putem folosi abaterea standard a fiecarui esantion (s1 respectiv s2), care aproximeaza suficient de bine abaterile standard ale celor doua populatii.
Atunci cand esantioanele nu sunt suficient de mari, trebuie sa ne asteptam la erori considerabile in estimarea imprastierii populatiei pe baza imprastierii esantionului. Intr-o astfel de situatie vom apela, desigur, la un test t, avand doua optiuni de calcularea acestuia:
a. Testul t pentru dispersii diferite
Acesta se bazeaza pe considerarea separata a dispersiilor celor doua populatii (estimate prin dispersiile esantioanelor). Formula este foarte asemanatoare cu formula anterioara pentru testul z. Vom retine aceasta formula ca testul t pentru dispersii diferite:
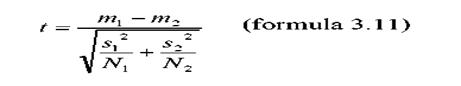
Se observa inlocuirea lui σ (pentru populatie) cu s (pentru esantion). Utilizarea acestei formule este destul de controversata deoarece rezultatul nu urmeaza cu exactitate distributia t, asa cum am introdus-o anterior. Pentru eliminarea acestui neajuns, se utilizeaza o alta varianta de calcul, care ia in considerare dispersia cumulata a celor doua esantioane.
b. Testul t pentru dispersia cumulata
Dispersiile celor doua esantioane pot fi considerate impreuna pentru a forma o singura estimare a dispersiei populatiei (σ2). Obtinem astfel ceea ce se numeste "dispersia cumulata", pe care o vom nota cu s2c si o vom calcula cu formula urmatoare:
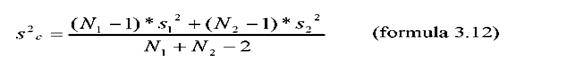
La numarator, formula contine suma dispersiilor multiplicate, fiecare, cu volumul esantionului respectiv (de fapt, gradele de libertate, N-1). In acest fel vom avea o contributie proportionala cu numarul de valori ale imprastierii fiecarui esantion la rezultatul final.
La numitor, avem gradele de libertate (df) pentru cele doua esantioane luate impreuna (N1+N2-2).
Inlocuind-o in formula 3.11, obtinem formula de calcul a testului t pentru dispersii cumulate:
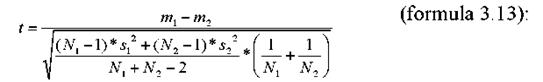
Expresia 3.13 este formula uzuala pentru calcularea diferentei dintre medii pentru doua esantioane independente. Chiar daca a fost introdusa ca utilizabila pentru "esantioane mici", caracteristicile distributiei t ne permit utilizarea ei si pentru esantioane mari, deoarece distributia t tinde spre cea normala la valori din ce in ce mai mari ale gradelor de libertate.
EXEMPLU DE CALCUL:
Sa presupunem ca vrem sa vedem daca practicarea trainingului autogen (variabila independenta) determina o crestere a performantei in tragerea la tinta, manifestata printr-un numar mai mare de lovituri in centru tintei (variabila dependenta). Pentru aceasta selectam un esantion de 6 sportivi care practica trainingul autogen si un esantion de 6 sportivi care nu il practica. Pentru fiecare esantion masuram performanta de tragere.
Formularea ipotezei cercetarii, a ipotezei de nul, si a criteriilor deciziei statistice
Pentru exemplul de mai sus:
Problema cercetarii: Are practicarea trainingului autogen un efect asupra performantei la tirul cu arcul?
Ipoteza cercetarii (H1): "Practicarea trainingului autogen determina un numar mai mare de puncte la sedintele de tragere".
Ipoteza de nul (statistica) (H0): "Numarul punctelor la sedintele de tragere nu este mai mare la cei care practica trainingul autogen". Aceasta varianta este potrivita cu o testare unilaterala a ipotezei (nu avem in vedere decat eventualitatea ca trainingul autogen sa creasca performanta sportiva).
Daca, insa, am dori sa testam in ambele directii, bilateral, atunci am avea urmatoarele versiuni ale ipotezelor:
Ipoteza cercetarii: "Performanta sportiva este diferita la subiectii care practica trainig autogen fata de cei care nu practica"
Ipoteza de nul (statistica): "Performanta nu difera semnificativ in functie de practicarea trainingului autogen".
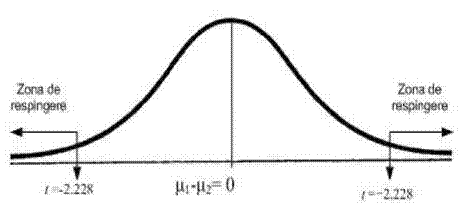
Fixarea lui t critic. Optam pentru efectuarea unui test bilateral, pentru ca nu putem sti dinainte daca TA nu are un efect negativ asupra performantei sportive a tragatorilor la tinta. Alegem nivelul α=0,05. Stabilim gradele de libertate:
df=N1+N2-2=10
Utilizand tabelul distributiei t pentru 10 grade de libertate (adica 12-2) si α=0,05, bilateral, gasim t critic=2.228, la intersectia coloanei 0.025 si cu linia pentru 10 grade de libertate.
Valoarea t calculata va trebui sa fie cel putin egala sau mai mare decat t critic, pentru a putea respinge ipoteza de nul si a accepta ipoteza cercetarii (vezi imaginea de mai jos).
![]()
Variabila independenta (calitatea de practicant-nepracticant Training
Autogen) ia doua valori, sa zicem: "1" pentru practicantii trainingului autogen si "2"
pentru nepracticanti. Valorile "1" si "2"
sunt conventionale si ne indica faptul ca variabila independenta a
cercetarii noastre este masurata pe o scala nominala, categoriala (dihotomica). Variabila dependenta (performanta
de tragere la tinta) ia valori cantitative, exprimata in numar de lovituri in centrul tintei, fiind de tip
cantitativ (raport).
Datele cercetarii
|
practicanti TA ("1") |
ne-practicanti TA ("2") |
|||
|
X1 |
(X1-m1)2 |
X2 |
(X2-m2)2 |
|
|
|
||||
|
N | ||||
|
m | ||||
|
S2 =å(Xi-m)2/N-1 | ||||
|
S= s2 | ||||
Calculam testul t pentru dispersii cumulate:
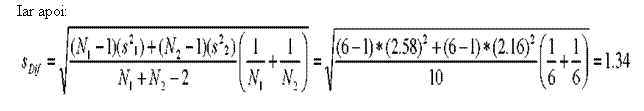
Mai intai, eroarea standard a diferentei (numitorul formulei):

![]()
Comparam t calculat cu t critic din tabelul distributiei t: 3.73 > 2.228 Decizia statistica: Se respinge
ipoteza de nul
Concluzia cercetarii: Se admite ipoteza cercetarii. "Practicarea trainingului autogen este in legatura cu performanta de tragere"
Marimea efectului
Atunci cand calculam testul t, nu valoarea obtinuta este relevanta ci probabilitatea care este asociata acestei valori (p). De exemplu, daca avem in vedere formula de calcul pentru t, atunci intelegem ca o valoare t=3.73 nu inseamna altceva decat faptul ca diferenta dintre mediile comparate este 3.73 ori mai mare decat eroarea standard estimata a acelei diferente. Chiar daca probabilitatea asociata acestei valori t este foarte mica, sub pragul alfa, magnitudinea diferentei dintre medii poate fi mica. Ca urmare, aprecierea "importantei" diferentei dintre mediile grupurilor cercetate are nevoie de informatii suplimentare. Acestea sunt oferite de indicele de marime a efectului.
Pentru a afla "marimea efectului" pentru testul t pentru esantioane independente, se utilizeaza indicele d al lui Cohen. Din pacate, pachetele de programe statistice uzuale (inclusiv SPSS) nu ofera acest valoarea lui d. El poate fi insa obtinut relativ usor cu formula:

![]()
unde numitorul exprima abatarea standard cumulata a celor doua grupuri
comparate.
Pentru exemplul nostru, calculam marimea efectului inlocuind datele in formula 3.14, dupa cum urmeaza:
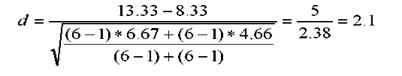
Interpretarea marimii lui d se face utilizand aceleasi praguri propuse de Cohen: 0.20 - efect mic; 0.50 - efect mediu; 0.80 - efect mare. Valoarea obtinuta de noi indica un nivel ridicat al marimii efectului, semn al faptulului ca practicarea sedintelor de relaxare are un "efect" important asupra performantei sportivilor din esantionul cercetarii.
Limitele de incredere ale diferentei dintre medii
Asa cum stim, mediile grupurilor comparate reprezinta doar o estimare a mediei populatiilor din care provin, osciland jurul mediei "adevarate". In mod similar, diferenta dintre mediile celor doua esantioane estimeaza media populatiei de diferente. Cat de precisa este aceasta estimare putem afla prin calcularea intervalului de incredere pentru diferenta mediilor. Principial, limitele de incredere in acest caz se calculeaza la fel ca si limitele de incredere pentru media populatiei, dupa urmatoarea formula:
dif mdiftcritic* sdif (formula
unde:
dif=media populatiei de diferente (1-2)
mdif=diferenta dintre mediile esantioanelor cercetarii (m1-m2 )
tcritic=valoarea lui t pentru nivelul de incredere ales (de regula 95%)
sdif=eroarea standard a diferentei (calculata cu expresia de la numitorul formulei
Inlocuind datele in formula, obtinem urmatoarele limite de incredere pentru media populatiei de diferente:
Limita inferioara dif=5-2.228* 1.34=2.01
Limita superioara dif=5+2.228* 1.34=7.98
Imaginea de mai jos ilustreaza limitele intre care se afla, pe distributia populatiei de diferente, avand media 0, cu un nivel de incredere de 95%, pozitia mediei reale a diferentei dintre grupurile comparate:
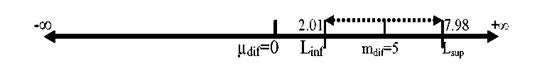
Relevanta intervalului de incredere poate fi discutata din mai multe puncte de vedere:
(a)Faptul ca media populatiei de nul (dif=0) se afla in afara limitelor de increrede subliniaza odata in plus caracterul semnificativ al diferentei dintre mediile grupurilor comparate. Cu cat una dintre limite ar fi mai aproape de valoarea 0, cu atat faptul de a fi obtinut un rezultat semnificativ ar fi mai putin relevant. Daca media distributiei de nul ar fi cuprinsa intre limitele de incredere ipoteza de nul ar trebui acceptata, indiferent de rezultatul testului statistic.
(b)Marimea intervalului de incredere arata precizia estimarii rezultatului cercetarii. Aceasta este legata in mod direct de eroarea standard a diferentei (eroarea de estimare) care, la randul ei, depinde de numarul subiectilor din cele doua esantioane, dar si de omogenitatea valorilor masurate.
(c)In masura in care variabila testata are o utilitate practica, limitele de incredere scot in evidenta daca rezultatul are o semnificatie in raport cu criterii de ordin practic. De exemplu, in cazul nostru, antrenorul sportivilor respectivi poate aprecia in ce masura un progres al performantei care poate fi intre 2 si 7 puncte ar aduce o clasare mai buna la concursurile de profil sau, dimpotriva, este "nerentabil".
(d) Limitele de incredere nu prezinta o utilitate practica atunci cand valorile variabilei nu au o semnificatie prin ele insele. Sa ne imaginam, spre exemplu, un experiment in care un grup priveste un film trist, iar un alt grup priveste un film vesel, dupa care starea de spirit a celor doua grupuri este evaluata prin numararea cuvintelor triste sau vesele pe care subiectii si le pot aminti dintr-o lista citita imediat dupa vizionare. In aceasta situatie este greu de atribuit o utilitate practica limitelor de incredere ale "numarului de cuvinte evocate". Nu acelasi lucru se intampla daca, de exemplu, in cazul unui experiment in care utilizarea unui anumit tip de exercitii la locul de munca se traduce in cresterea productivitatii muncii, masurata prin numarul de produse finite. Este evident ca numarul de produse finite este un indicator cu relevanta practica, usor de interpretat. Cu toate acestea, chiar si atunci cand nu prezinta o relevanta practica directa, calcularea limitelor de incredere ofera o imagine a gradului de precizie a estimarii testului statistic, fapt care face necesara cunoasterea lor si raportarea lor.
Interpretarea rezultatului la testul t pentru esantioane independente
Atunci cand valoarea calculata a testului este egala sau mai mare decat t critic (ceea ce este echivalent cu "p este mai mic sau egal cu alfa"), rezultatul justifica aprecierea ca semnificativa a diferentei dintre mediile celor doua esantioane (adica suficient de mare pentru a respinge ipoteza ca ar putea fi intamplatoare). Modelul de cercetare nu permite formularea acestei concluzii in termenii unei relatii cauzale intre practicarea trainingului autogen si performanta sportiva, oricat de tentata ar fi aceasta concluzie. Cel putin nu in contextul acestui model de de cercetare. Daca acelasi grup de subiecti ar fi fost supus evaluarii performantei de extragere in zile cu training autogen si in zile fara training autogen, concluzia ar fi putut fi de ordin cauzal.
In plus, existenta unei diferente semnificative nu este similara cu existenta unei diferente cu valoare practica. Este posibil ca diferenta dintre cele doua loturi de sportivi, desi semnificativa statistic, sa nu justifice costurile angajate in desfasurarea programului de relaxare psihica. Intr-o asemenea situatie, studiul nu este lipsit de valoare dar concluziile sunt utile doar in plan teoretic.
Publicarea rezultatului
La publicarea testului t pentru diferenta dintre mediile a doua esantioane independente vor fi mentionate: mediile si abaterile standard ale fiecarui esantion, volumul esantioanelor sau gradele de libertate, valoarea testului, nivelul lui p, marimea efectului si limitele de intervalului de incredere pentru diferenta dintre medii.
In forma narativa, rezultatul pentru exemplul de mai sus poate fi formulat astfel: "Sportivii care practica trainingul autogen au fost comparati cu cei care nu practica. Primii au realizat o performanta mai buna (m=13.33, σ=2.58) fata de ceilalti (m=8.33, σ=2.16), t(10)=3.65, p<0.05. Marimea efectului este mare (d=2.1), iar limitele de incredere (95%) pentru diferenta mediilor sunt cuprinse intre 2.01 si 7.98".
Conditiile in care putem calcula testul t pentru esantioane independente
Esantioane aleatoare (ideal), sau neafectate de erori de esantionare (bias);
Esantioane independente (distincte din punctul de vedere al variabilei independente, care determina constituirea grupurilor);
Variabila supusa masurarii sa se distribuie normal in ambele populatii. Aceasta ne garanteaza ca si distributia diferentelor dintre medii se distribuie normal. Totusi, teorema limitei centrale ne permite asumarea normalitatii distributiei mediei de esantionare chiar si in cazul variabilelor care nu se distribuie normal la nivelul populatiei, pentru esantioane mari. Daca insa, analiza distributiilor indica forme aberante, iar volumul grupurilor comparate este foarte mic, se va alege solutia unui test neparametric. Vom mentiona, totusi, ca testele t sunt robuste la incalcarea conditiei de normalitate.
Dispersia celor doua esantioane sa fie omogena. Testul t poate fi aplicat strict in cazurile in care dispersiile celor doua populatii ("practicanti", "nepracticanti") au aceeasi dispersie (omogenitatea dispersiei). Din fericire, exista trei situatii in care aceasta conditie nu trebuie sa ne preocupe:
cand esantioanele sunt suficient de mari (cel putin 100 fiecare)
cand cele doua esantioane au acelasi volum (N1=N2)
cand dispersiile celor doua esantioane nu difera semnificativ (dar, chiar si pentru acest caz, exista formule care tin cont de diferenta dispersiilor).
Cand se utilizeaza testul t pentru esantioane independente?
Generic, acest test statistic se utilizeaza in situatiile in care vrem sa aflam daca o variabila dependenta, masurata pe o scala de interval/raport, difera semnificativ intre doua grupuri (esantioane) diferentiate pe o variabila independenta masurata pe scala de tip nominal (dihotomic), sau bi-categoriala, indiferent de natura ei. Deoarece este unul dintre modelele frecvent intalnite in practica cercetarii psihologice, utilizarea testului t pentru esantioane independente este si ea des intalnita in literatura de specialitate.
EXERCITII
Intr-un studiu asupra efectelor unui nou tratament al fobiei, datele pentru grupul experimental obtinute printr-o scala de evaluare a tendintelor fobice sunt: m1=27.2, s1=4 si N1=15 Datele pentru grupul de control sunt: m2=34.4, s2=14 si N2=15 Formulati:
Problema (intrebarea) cercetarii
Ipoteza cercetarii (H1)
Ipoteza de nul (H0)
Aflati t critic pentru α=0.05; bilateral
Nota: Desi datele din exemplu arata ca m1 este mai mic decat m2, vom alege un test bilateral pentru ca, sa nu uitam, in practica, criteriile deciziei statistice sunt fixate inaintea masurarii experimentale, cand, deci, nu aveam de unde sti care vor fi valorile pe care le vom obtine.
Calculati testul t pentru diferenta dintre cele doua esantioane
Calculati intervalul de incredere (99%) pentru diferenta dintre mediile populatiilor.
Calculati marimea efectului
Formulati si motivati decizia statistica
Formulati concluzia cercetarii, cu respectarea recomandarilor de raportare pentru acest test.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 5187
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved