| CATEGORII DOCUMENTE |
| Bulgara | Ceha slovaca | Croata | Engleza | Estona | Finlandeza | Franceza |
| Germana | Italiana | Letona | Lituaniana | Maghiara | Olandeza | Poloneza |
| Sarba | Slovena | Spaniola | Suedeza | Turca | Ucraineana |
DOCUMENTE SIMILARE |
|
Comme on a pu le voir dans la figure 2.3 le protocole IP (Internet Protocol, RFC 791) est au coeur du fonctionnement d'un Internet. Il assure sans connexion un service non fiable de délivrance de datagrammes IP. Le service est non fiable car il n'existe aucune garantie pour que les datagrammes IP arrivent à destination. Certains peuvent Être perdus, dupliqués, retardés, altérés ou remis dans le désordre. On parle de remise au mieux (best effort delivery) et ni l'émetteur ni le récepteur ne sont informés directement par IP des problÈmes rencontrés. Le mode de transmission est non connecté car IP traite chaque datagramme indépendamment de ceux qui le précÈdent et le suivent. Ainsi en théorie, au moins, deux datagrammes IP issus de la mÊme machine et ayant la mÊme destination peuvent ne pas suivre obligatoirement le mÊme chemin. Le rôle du protocole IP est centré autour des trois fonctionnalités suivantes chacune étant décrite dans une des sous-sections à venir.
- définir le format du datagramme IP qui est l'unité de base des données circulant sur Internet
- définir le routage dans Internet
- définir la gestion de la remise non fiable des datagrammes
Comme cela a déjà été illustré dans la figure 2.6on rappelle qu'un datagramme IP est constitué d'une en-tÊte suivie d'un champ de données.
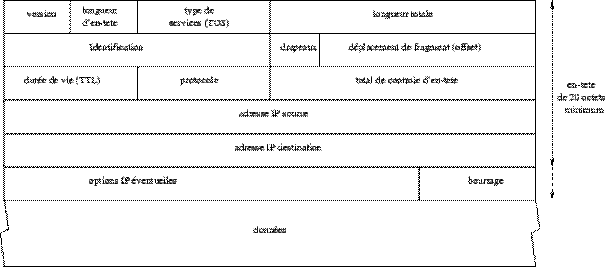
Figure 2.17: Structure d'un datagramme IP.
Sa structure précise est détaillée dans la figure 2.17 et comporte les champs suivants :
- La version code sur 4 bits le numéro de version du protocole IP utilisé (la version courante est la 4, d'oÙ son nom d'IPv4). Tout logiciel IP doit d'abord vérifier que le numéro de version du datagramme qu'il reçoit est en accord avec lui-mÊme. si ce n'est pas le cas le datagramme est tout simplement rejeté. Ceci permet de tester des nouveaux protocoles sans interférer avec la bonne marche du réseau.
- La longueur d'en-tÊte représente sur 4 bits la longueur, en nombre de mots de 32 bits, de l'en-tÊte du datagramme. Ce champ est nécessaire car une en-tÊte peut avoir une taille supérieure à 20 octets (taille de l'en-tÊte classique) à cause des options que l'on peut y ajouter.
- Le type de services (TOS) est codé sur 8 bits, indique la maniÈre dont doit Être géré le datagramme et se décompose en six sous-champs comme suit:
|
priorité |
D |
T |
R |
C |
inutilisé |
||
Le champ priorité varie de 0 (priorité normale, valeur par défaut) à 7 (priorité maximale pour la supervision du réseau) et permet d'indiquer l'importance de chaque datagramme. MÊme si ce champ n'est pas pris en compte par tous les routeurs, il permettrait d'envisager des méthodes de contrôle de congestion du réseau qui ne soient pas affectées par le problÈme qu'elles cherchent à résoudre. Les 4 bits D, T, R et C permettent de spécifier ce que l'on veut privilégier pour la transmission de ce datagramme (nouvel RFC 1455). D est mis à 1 pour essayer de minimiser le délai d'acheminement (par exemple choisir un cable sous-marin plutôt qu'une liaison satellite), T est mis à 1 pour maximiser le débit de transmission, R est mis à 1 pour assurer une plus grande fiabilité et C est mis à 1 pour minimiser les coÛts de transmission. Si les quatre bits sont à 1, alors c'est la sécurité de la transmission qui doit Être maximisée. Les valeurs recommandées pour ces 4 bits sont données dans la table 2.1.
|
Tableau 2.1: Type de service pour les applications standard. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Ces 4 bits servent à améliorer la qualité du routage et ne sont pas des exigences incontournables. Simplement, si un routeur connait plusieurs voies de sortie pour une mÊme destination il pourra choisir celle qui correspond le mieux à la demande.
- La longueur totale contient la taille totale en octets du datagramme, et comme ce champ est de 2 octets on en déduit que la taille complÈte d'un datagramme ne peut dépasser 65535 octets. Utilisée avec la longueur de l'en-tÊte elle permet de déterminer oÙ commencent exactement les données transportées.
- Les champs identification, drapeaux et déplacement de fragment interviennent dans le processus de fragmentation des datagrammes IP et seront décrits ci-aprÈs.
- La durée de vie (TTL) indique le nombre maximal de routeurs que peut traverser le datagramme. Elle est initialisée à N (souvent 32 ou 64) par la station émettrice et décrémenté de 1 par chaque routeur qui le reçoit et le réexpédie. Lorsqu'un routeur reçoit un datagramme dont la durée de vie est nulle, il le détruit et envoie à l'expéditeur un message ICMP. Ainsi, il est impossible qu'un datagramme «tourne» indéfiniment dans un Internet. Ce champ sert également dans la réalisation du programme traceroute
- Le protocole permet de coder quel protocole de plus haut niveau a servi a créé ce datagramme. Les valeurs codées sur 8 bits sont 1 pour ICMP, 2 pour IGMP, 6 pour TCP et 17 pour UDP. Ainsi, la station destinatrice qui reçoit un datagramme IP pourra diriger les données qu'il contient vers le protocole adéquat.
- Le total de contrôle d'en-tÊte (header checksum) est calculé à partir de l'en-tÊte du datagramme pour en assurer l'intégrité. L'intégrité des données transportées est elle assurée directement par les protocoles ICMP, IGMP, TCP et UDP qui les émettent. Pour calculer cette somme de contrôle, on commence par la mettre à zéro. Puis, en considérant la totalité de l'en-tÊte comme une suite d'entiers de 16 bits, on fait la somme de ces entiers en complément à 1. On complémente à 1 cette somme et cela donne le total de contrôle que l'on insÈre dans le champ prévu. A la réception du datagramme, il suffit d'additionner tous les nombres de l'en-tÊte et si l'on obtient un nombre avec tous ses bits à 1, c'est que la transmission s'est passée sans problÈme.
Exemple : Soit le datagramme IP dont l'en-tÊte est la suivante 4500 05dc e733 222b ff11 checksum c02c 4d60 c02c 4d01 La somme des mots de 16 bits en compléments à 1 donne 6e08, son complément à 1 est 91f7. Le datagramme est donc expédié avec cette valeur de checksum.
- Les adresses IP source et destination contiennent sur 32 bits les adresses de la machine émettrice et destinataire finale du datagramme.
- Le champ options est une liste de longueur variable, mais toujours complétée par des bits de bourrage pour atteindre une taille multiple de 32 bits pour Être en conformité avec la convention qui définit le champ longueur de l'en-tÊte. Ces options sont trÈs peu utilisées car peu de machines sont aptes à les gérer. Parmi elles, on trouve des options de sécurité et de gestion (domaine militaire), d'enregistrement de la route, d'estampille horaire, routage strict, etc
Les champs non encore précisés le sont dans la section suivante car ils concernent la fragmentation des datagrammes.
En fait, il existe d'autres limites à la taille d'un datagramme que celle fixée par la valeur maximale de 65535 octets. Notamment, pour optimiser le débit il est préférable qu'un datagramme IP soit encapsulé dans une seule trame de niveau 2 (Ethernet par exemple). Mais, comme un datagramme IP peut transiter à travers Internet sur un ensemble de réseaux aux technologies différentes il est impossible de définir, a priori (lors de la définition du RFC), une taille maximale des datagrammes IP qui permette de les encapsuler dans une seule trame quel que soit le réseau (1500 octets pour Ethernet et 4470 pour FDDI par exemple). On appelle la taille maximale d'une trame d'un réseau le MTU (Maximum Transfert Unit) et elle va servir à fragmenter les datagrammes trop grands pour le réseau qu'ils traversent. Mais, si le MTU d'un réseau traversé est suffisamment grand pour accepter un datagramme, évidemment il sera encapsulé tel quel dans la trame du réseau concerné.
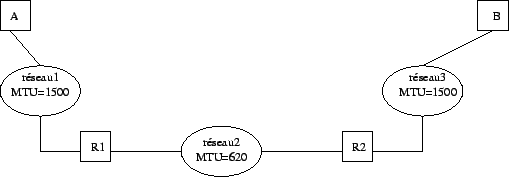
Figure 2.18: Fragmentation d'un datagramme IP.
Comme on peut le voir dans la figure 2.18 la fragmentation se situe au niveau d'un routeur qui reçoit des datagrammes issus d'un réseau à grand MTU et qui doit les réexpédier vers un réseau à plus petit MTU. Dans cet exemple, si la station A, reliée à un réseau Ethernet, envoie un datagramme de 1300 octets à destination de la station B, reliée également à un réseau Ethernet, le routeur R1 va devoir fragmenter ce datagramme de la maniÈre suivante.
|
datagramme initial |
en-tÊte du datagramme |
données1 600 octets |
données2 600 octets |
données3 100 octets |
|
fragment1 |
en-tÊte du fragment1 |
données1 600 octets |
déplacement 0 |
|
|
fragment2 |
en-tÊte du fragment2 |
données2 600 octets |
déplacement 600 |
|
|
fragment3 |
en-tÊte du fragment3 |
données3 100 octets |
déplacement 1200 |
|
La taille d'un fragment est choisie la plus grande possible tout en étant un multiple de 8 octets. Un datagramme fragmenté n'est réassemblé que lorsqu'il arrive à destination finale, mÊme s'ils traversent des réseaux avec un plus grand MTU les routeurs ne réassemblent pas les petits fragments. De plus chaque fragment est routé de maniÈre totalement indépendante des autres fragments du datagramme d'oÙ il provient. Le destinataire final qui reçoit un premier fragment d'un datagramme arme un temporisateur de réassemblage, c'est-à-dire un délai maximal d'attente de tous les fragments. Si, passé ce délai, tous les fragments ne sont pas arrivés il détruit les fragments reçus et ne traite pas le datagramme. Plus précisément, l'ordinateur destinataire décrémente, à intervalles réguliers, de une unité le champ TTL de chaque fragment en attente de réassemblage. Cette technique permet également de ne pas faire coexister au mÊme instant deux datagrammes avec le mÊme identifiant.
Le processus de fragmentation-réassemblage est rendu possible grace aux différents champs suivants. Le champ déplacement de fragment précise la localisation du début du fragment dans le datagramme initial. À part cela, les fragments sont des datagrammes dont l'en-tÊte est quasiment identique à celle du datagramme original. Par exemple, le champ identification est un entier qui identifie de maniÈre unique chaque datagramme émis et qui est recopié dans le champ identification de chacun des fragments si ce datagramme est fragmenté. Par contre, le champ longueur total est recalculé pour chaque fragment. Le champ drapeaux comprend trois bits dont deux qui contrôlent la fragmentation. S'il est positionné à 1 le premier bit indique que l'on ne doit pas fragmenter le datagramme et si un routeur doit fragmenter un tel datagramme alors il le rejette et envoie un message d'erreur à l'expéditeur. Un autre bit appelé fragments à suivre est mis systématiquement à 1 pour tous les fragments qui composent un datagramme sauf le dernier. Ainsi, quand le destinataire reçoit le fragment dont le bit fragment à suivre est à 0 il est apte à déterminer s'il a reçu tous les fragments du datagramme initial grace notamment aux champs offset et longueur totale de ce dernier fragment. Si un fragment doit Être à nouveau fragmenté lorsqu'il arrive sur un réseau avec un encore plus petit MTU, ceci est fait comme décrit précédemment sauf que le calcul du champ déplacement de fragment est fait en tenant compte du déplacement inscrit dans le fragment à traiter.
Le routage est l'une des fonctionnalités principales de la couche IP et consiste à choisir la maniÈre de transmettre un datagramme IP à travers les divers réseaux d'un internet. On appellera ordinateur un équipement relié à un seul réseau et routeur un équipement relié à au moins deux réseaux (cet équipement pouvant Être un ordinateur, au sens classique du terme, qui assure les fonctionnalités de routage). Ainsi un routeur réémettra des datagrammes venus d'une de ses interfaces vers une autre, alors qu'un ordinateur sera soit l'expéditeur initial, soit le destinataire final d'un datagramme.
D'une maniÈre générale on distingue la remise
directe, qui correspond au transfert d'un datagramme entre deux ordinateurs
du mÊme réseau, et la remise indirecte qui est mise en ![]() uvre
dans tous les autres cas, c'est-à-dire quand au moins un routeur sépare
l'expéditeur initial et le destinataire final. Par exemple, dans le cas d'un
réseau Ethernet, la remise directe consiste à encapsuler le datagramme
dans une trame Ethernet aprÈs avoir utilisé le protocole ARP pour faire
la correspondance adresse IP adresse physique et à émettre cette trame
sur le réseau. L'expéditeur peut savoir que le destinataire final partage le
mÊme réseau que lui-mÊme en utilisant simplement l'adresse IP de
destination du datagramme. Il en extrait l'identificateur de réseau et si c'est
le mÊme que celui de sa propre adresse IP alors la remise directe est
suffisante. En fait, ce mécanisme de remise directe se retrouve toujours lors
de la remise d'un datagramme entre le dernier routeur et le destinataire final.
Pour sa part, la remise indirecte nécessite de déterminer vers quel routeur
envoyer un datagramme IP en fonction de sa destination finale. Ceci est rendu
possible par l'utilisation d'une table de routage spécifique à
chaque routeur qui permet de déterminer vers quelle voie de sortie envoyer un
datagramme destiné à un réseau quelconque. À cause de la
structure localement arborescente d'Internet la plupart des tables de routage
ne sont pas trÈs grandes. Par contre, les tables des routeurs
interconnectant les grands réseaux peuvent atteindre des tailles trÈs
grandes ralentissant d'autant le trafic sur ces réseaux.
uvre
dans tous les autres cas, c'est-à-dire quand au moins un routeur sépare
l'expéditeur initial et le destinataire final. Par exemple, dans le cas d'un
réseau Ethernet, la remise directe consiste à encapsuler le datagramme
dans une trame Ethernet aprÈs avoir utilisé le protocole ARP pour faire
la correspondance adresse IP adresse physique et à émettre cette trame
sur le réseau. L'expéditeur peut savoir que le destinataire final partage le
mÊme réseau que lui-mÊme en utilisant simplement l'adresse IP de
destination du datagramme. Il en extrait l'identificateur de réseau et si c'est
le mÊme que celui de sa propre adresse IP alors la remise directe est
suffisante. En fait, ce mécanisme de remise directe se retrouve toujours lors
de la remise d'un datagramme entre le dernier routeur et le destinataire final.
Pour sa part, la remise indirecte nécessite de déterminer vers quel routeur
envoyer un datagramme IP en fonction de sa destination finale. Ceci est rendu
possible par l'utilisation d'une table de routage spécifique à
chaque routeur qui permet de déterminer vers quelle voie de sortie envoyer un
datagramme destiné à un réseau quelconque. À cause de la
structure localement arborescente d'Internet la plupart des tables de routage
ne sont pas trÈs grandes. Par contre, les tables des routeurs
interconnectant les grands réseaux peuvent atteindre des tailles trÈs
grandes ralentissant d'autant le trafic sur ces réseaux.
L'essentiel du contenu d'une table de routage est constitué de quadruplets (destination, passerelle, masque, interface) oÙ :
- destination est l'adresse IP d'une machine ou d'un réseau de destination,
- passerelle (gateway) est l'adresse IP du prochain routeur vers lequel envoyer le datagramme pour atteindre cette destination,
- masque est le masque associé au réseau de destination,
- interface désigne l'interface physique par laquelle le datagramme doit réellement Être expédié.
Une table de routage contient notamment une route par défaut qui spécifie un routeur par défaut vers lequel sont envoyés tous les datagrammes pour lesquels il n'existe pas de route dans la table et l'algorithme général de routage est le suivant :
Procédure RoutageIP(données Dat : datagramme, Tab : Table de routage)
début
D := adresse IP de destination de Dat
si D appartient à l'un des réseaux directement accessibles
alors // remise directe
envoyer Dat vers l'adresse D sur ce réseau
sinon // remise indirecte
pour chaque entrée de Tab faire
N:=résultat du et logique de D et du masque de sous-réseau
si N=l'adresse réseau de la destination de l'entrée alors
router Dat vers cette destination
sortir
finsi
finpour
si aucune correspondance n'est trouvée alors
retourner à l'application d'origine du datagramme une erreur de routage host unreachable ou unreachable network
finsi
finsi
fin
Tous les routeurs mentionnés dans une table de routage doivent bien sÛr Être directement accessibles à partir du routeur considéré. Cette technique, dans laquelle un routeur ne connait pas le chemin complet menant à une destination, mais simplement la premiÈre étape de ce chemin, est appelée routage par sauts successifs (next-hop routing).
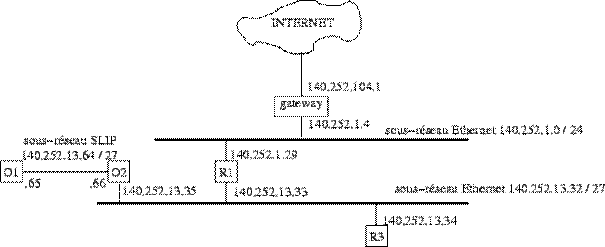
Figure 2.19: Exemple d'interconnexion de réseau.
La figure 2.19 donne un exemple d'interconnexion d'un réseau de classe B 140.252.0.0 subdivisé en 3 sous-réseaux d'adresses respectives 140.252.1.0 / 24 pour l'Ethernet du haut, 14.252.13.32 / 27 pour l'Ethernet du bas et 140.252.13.64 / 27 pour le sous-réseau SLIP. Les masques de sous-réseau sont associés par défaut à chaque interface d'une machine ou sont éventuellement spécifiés sur chaque ligne des tables de routage. Dans l'exemple donné ici, la table de routage simple de l'ordinateur R3 (sous systÈme unix Sun) est la suivante.
|
destination |
gateway |
genmask |
flags |
refcnt |
use |
interface |
|
UGH |
emd0 |
|||||
|
UH |
lo0 |
|||||
|
U |
emdO |
|||||
|
default |
UG |
emd0 |
Les flags ont la signification suivante:
U : La route est en service.
G : La route est un routeur (gateway). Si ce flag n'est pas positionné la destination est directement connectée au routeur, c'est donc un cas de remise directe vers l'adresse IP de destination.
H : La route est un ordinateur (host), la destination est une adresse d'ordinateur. Dans ce cas, la correspondance entre l'adresse de destination du paquet à «router» et l'entrée destination de la table de routage doit Être totale. Si ce flag n'est pas positionné, la route désigne un autre réseau et la destination est une adresse de réseau ou de sous-réseau. Ici, la correspondance des identificateurs de réseaux est suffisante.
D : La route a été créée par une redirection.
M : La route a été modifiée par une redirection.
La colonne compteur de référence (refcnt indique le nombre de fois oÙ la route est utilisée à l'instant de la consultation. Par exemple, TCP conserve la mÊme route tant qu'il l'utilise pour la connexion sous-jacente à une application (telnet, ftp, ). La colonne use affiche le nombre de paquets envoyés à travers l'interface de cette route qui est spécifiée dans la derniÈre colonne de la mÊme ligne.
L'adresse 127.0.0.1 est celle de lo0, l'interface de loopback, qui sert à pouvoir faire communiquer une machine avec elle-mÊme.
La destination default sert à indiquer la destination de tous les datagrammes qui ne peuvent Être « routés » par l'une des autres routes.
L'établissement d'une table de routage est statique lorsqu'elle résulte de la configuration par défaut d'une interface, ou de la commande route à partir d'un fichier de démarrage, ou grace à une redirection ICMP. Mais dÈs que le réseau devient non trivial, on utilise le routage dynamique qui consiste en un protocole de communication entre routeurs qui informent chacun de leurs voisins des réseaux auxquels ils sont connectés. Grace à ce protocole, les tables de routage évoluent dans le temps en fonction de l'évolution des routes.
L'un des protocoles de routage les plus populaires est RIP (Routing Information Protocol) qui est un protocole de type vecteur de distance. C'est-à-dire que les messages échangés par des routeurs voisins contiennent un ensemble de distances entre routeur et destinations qui permet de réactualiser les tables de routage. Ce protocole utilise une métrique simple : la distance entre une source et une destination est égale au nombre de sauts qui les séparent. Elle est comprise entre 1 et 15, la valeur 16 représentant l'«infini». Ceci implique que RIP ne peut Être utilisé qu'à l'intérieur de réseaux qui ne sont pas trop étendus.
Un message RIP est encapsulé dans un datagramme UDP de la maniÈre décrite dans la figure 2.20.
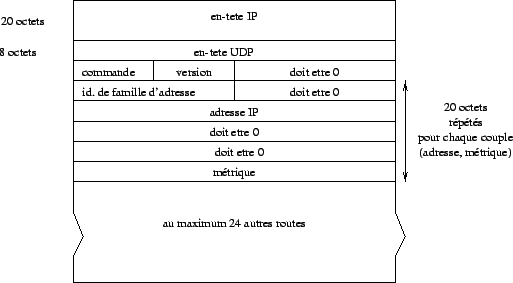
Figure 2.20: Encapsulation d'un message RIP.
Le champ commande fixé à 1 indique une requÊte pour demander tout ou partie d'une table de routage et fixé à 2 pour transmettre une réponse (d'autres valeurs hors normes actuellement existent également). Le champ version est positionné à 1 et à 2 dans la version de RIP2. Pour des adresses IP, le champ identificateur de famille d'adresses est toujours fixé à 2.
À l'initialisation, le démon de routage envoie une requÊte RIP à chaque interface pour demander les tables de routage complÈtes de chacun de ses voisins. Sur une liaison point à point la requÊte est envoyée à l'autre extrémité, sinon elle est envoyée sous forme de broadcast sur un réseau.
Le fonctionnement normal de RIP consiste à diffuser des réponses soit toutes les 30 secondes, soit pour une mise à jour déclenchée par la modification de la métrique d'une route. Une réponse contient une adresse de destination, accompagnée de sa métrique, de l'adresse du prochain routeur,d'un indicateur de mise à jour récente et de temporisations. Le processus RIP met à jour sa table de routage locale en examinant les entrées retournées dont il vérifie d'abord la validité : adresse de classe A,B ou C, numéro de réseau différent de 127 et 0 (sauf pour l'adresse par défaut 0.0.0.0), numéro d'ordinateur différent de l'adresse de diffusion, métrique différente de l'«infini». RIP effectue ensuite les mises à jour propres à l'algorithme «vecteur de distance» suivant :
- Si l'entrée n'existait pas dans la table et si la métrique reçue n'est pas infinie, alors on ajoute cette nouvelle entrée composée de la destination, de l'adresse du prochain routeur (c'est celui qui envoie la réponse), de la métrique reçue. On initialise la temporisation correspondante.
- Si l'entrée était présente avec une métrique supérieure à celle reçue, on met à jour la métrique et le prochain routeur et on réinitialise la temporisation.
- Si l'entrée était présente et que le routeur suivant correspond à l'émetteur de la réponse, on réinitialise la temporisation et on met à jour la métrique avec celle reçue si elles diffÈrent.
- Dans les autres cas on ignore l'entrée.
Cette méthode correspond à l'algorithme de Bellman-Ford de recherche de plus courts chemins dans un graphe.
Un des défauts de RIP est de ne pas gérer les adresses de sous-réseaux. Mais de telles entrées peuvent Être annoncées via une interface appartenant à ce sous-réseau pour pouvoir bénéficier du masque qui y est attaché et Être correctement interprétées. Enfin, RIP met un temps assez long (quelques minutes) pour se stabiliser aprÈs la défaillance d'une liaison ou d'un routeur ce qui peut occasionner des boucles de routage.
RIP2 est un protocole qui étend RIP en utilisant les 4 champs laissés à 0 par RIP dans ses messages. Le premier sert à fixer un domaine de routage identifiant le démon de routage qui a émis le paquet et le quatriÈme l'adresse IP d'un routeur de saut suivant. Ces deux champs ont servi à lancer simultanément plusieurs démons de routage sur un mÊme support leur utilisation a été abandonnée. Le deuxiÈme champ est un identificateur de route pour supporter des protocoles de routes externes et le troisiÈme sert à spécifier un masque de sous-réseau pour chaque entrée de la réponse.
OSPF (Open Shortest Path First) est un autre protocole de routage dynamique qui élimine les limitations de RIP. C'est un protocole d'état de liens, c'est-à-dire qu'ici un routeur n'envoie pas des distances à ses voisins, mais il teste l'état de la connectivité qui le relie à chacun de ses voisins. Il envoie cette information à tous ses voisins, qui ensuite le propagent dans le réseau. Ainsi, chaque routeur peut posséder une carte de la topologie du réseau qui se met à jour trÈs rapidement lui permettant de calculer des routes aussi précises qu'avec un algorithme centralisé.
En fait, RIP et OSPF, sont des protocoles de type IGP (Interior Gateway Protocol) permettant d'établir les tables des routeurs internes des systÈmes autonomes. Un systÈme autonome peut Être défini par un ensemble de routeurs et de réseaux sous une administration unique. Cela peut donc aller d'un seul routeur connectant un réseau local à Internet, jusqu'à l'ensemble des réseaux locaux d'une multinationale. La rÈgle de base étant qu'un systÈme autonome assure la connexité totale de tous les points qui le composent en utilisant notamment un protocole de routage unique. À un niveau plus global, Internet apparait donc comme une interconnexion de systÈmes autonomes comme illustré dans la figure 2.21.
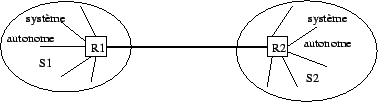
Figure 2.21: Interconnexion de systÈmes autonomes.
Dans chaque systÈme autonome les tables sont maintenus par par un IGP et sont échangées uniquement entre routeurs du mÊme sous-systÈme. Pour obtenir des informations sur les réseaux externes, ceux de l'autre systÈme autonome, ils doivent dialoguer avec les les routeurs externes R1 et R2. Ceux-ci sont des points d'entrée de chaque systÈme et, via la liaison qui les relie, ils échangent des informations sur la connectivité grace à EGP (Exterior Gateway Protocol) ou BGP (Border Gateway Protocol) qui remplace EGP actuellement.
Le protocole ICMP (Internet Control Message Protocol) organise un échange d'information permettant aux routeurs d'envoyer des messages d'erreurs à d'autres ordinateurs ou routeurs. Bien qu'ICMP «tourne» au-dessus de IP il est requis dans tous les routeurs c'est pourquoi on le place dans la couche IP. Le but d'ICMP n'est pas de fiabiliser le protocole IP, mais de fournir à une autre couche IP, ou à une couche supérieure de protocole (TCP ou UDP), le compte-rendu d'une erreur détectée dans un routeur. Un message ICMP étant acheminé à l'intérieur d'un datagramme IP illustré dans la figure 2.22, il est susceptible, lui aussi, de souffrir d'erreurs de transmission.

Figure 2.22: Encapsulation d'un message ICMP.
Mais la rÈgle est qu'aucun message ICMP ne doit Être délivré pour signaler une erreur relative à un message ICMP. On évite ainsi une avalanche de messages d'erreurs quand le fonctionnement d'un réseau se détériore.
Le champ type peut prendre 15 valeurs différentes spécifiant de quelle nature est le message envoyé. Pour certains types, le champ code sert à préciser encore plus le contexte d'émission du message. Le checksum est une somme de contrôle de tout le message ICMP calculée comme dans le cas de l'en-tÊte d'un datagramme IP. Le détail des différentes catégories de messages est donné dans la liste ci-dessous oÙ chaque alinéa commence par le couple (type,code) de la catégorie décrite.
(0,0) ou (8,0)
Demande (type 8) ou réponse (type 0) d'écho dans le cadre de la commande ping
Compte-rendu de destination inaccessible délivré quand un routeur ne peut délivrer un datagramme. Le routeur génÈre et envoie ce message ICMP à l'expéditeur de ce datagramme. Il obtient l'adresse de cet expéditeur en l'extrayant de l'en-tÊte du datagramme, il insÈre dans les données du message ICMP toute l'en-tÊte ainsi que les 8 premiers octets du datagramme en cause. Une liste non exhaustive des différents codes d'erreurs possibles est :
0 : Le réseau est inaccessible.
1 : La machine est inaccessible.
2 : Le protocole est inaccessible.
3 : Le port est inaccessible.
4 : Fragmentation nécessaire mais bit de non fragmentation positionné à 1.
5 : Échec de routage de source.
6 : Réseau de destination inconnu.
7 : Machine destinataire inconnue.
8 : Machine source isolée (obsolÈte)
9 : Communication avec le réseau de destination administrativement interdite.
10 : Communication avec la machine de destination administrativement interdite.
11 : Réseau inaccessible pour ce type de service.
12 : Machine inaccessible pour ce type de service.
13 : Communication administrativement interdite par filtrage.
Demande de limitation de production pour éviter la congestion du routeur qui envoie ce message.
Demande de modification de route expédiée lorsqu'un routeur détecte qu'un ordinateur utilise une route non optimale, ce qui peut arriver lorsqu'un ordinateur est ajouté au réseau avec une table de routage minimale. Le message ICMP généré contient l'adresse IP du routeur à rajouter dans la table de routage de l'ordinateur. Les différents codes possibles ci-aprÈs expliquent le type de redirection à opérer par l'ordinateur.
0 : Redirection pour un réseau.
1 : Redirection pour une machine.
2 : Redirection pour un type de service et réseau.
3 : Redirection pour un type de service et machine.
Avertissement de routeur expédié par un routeur.
Sollicitation de routeur diffusé par une machine pour initialiser sa table de routage.
TTL détecté à 0 pendant le transit du datagramme IP, lorsqu'il y a une route circulaire ou lors de l'utilisation de la commande traceroute
TTL détecté à 0 pendant le réassemblage d'un datagramme.
Mauvaise en-tÊte IP.
Option requise manquante.
RequÊte (13) ou réponse (14) timestamp, d'estampillage horaire.
(15,0) et (16,0)
devenues obsolÈtes.
RequÊte (17) ou réponse (18) de masque de sous-réseau.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1021
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved