| CATEGORII DOCUMENTE |
| Bulgara | Ceha slovaca | Croata | Engleza | Estona | Finlandeza | Franceza |
| Germana | Italiana | Letona | Lituaniana | Maghiara | Olandeza | Poloneza |
| Sarba | Slovena | Spaniola | Suedeza | Turca | Ucraineana |
DOCUMENTE SIMILARE |
|
Les RN abordés dans les chapitres précédants permettent une transformation
F : RnÞRm, en utilisant des couples de forme modÈle d’entrée - modÈle de sortie désiré. Il y a des problÈmes dont on ne dispose pas de modÈles désirés, mais seulement de l’ensemble de modÈles d’entrée.
1 Le principe de l’apprentissage compétitif
L'architecture d'un réseau avec un apprentissage compétitif est présentée dans la Fig.6.1. Dans un RN compétitif tous les neurones sont complets connectés. Tous les neurones reçoivent des entrées excitatrices de la couche précédante et transmettent des signaux inhibiteurs vers les neurones de leur couche. Les vecteurs poids sont initialisés aléatoirement usuellement aux modÈles d’entrée. On suppose que toutes les entrées et tous les poids sont normalisés, ayant le mÊme nombre N des éléments (le nombre des neurones de la couche précédante). Si tous les modÈles d’entrée ont le mÊme nombre des éléments N, ils ont la mÊme longueur. On peut interpréter chaque modelé d’entrée et chaque vecteur poids comme un point sur une sphÈre (N dimensionnelle). Quand on applique un modÈle à l’entrée chaque neurone calcule son activation :
![]() (6.1)
(6.1)
Puis c’est sélectionné le neurone gagnant, celui avec la plus grande (ou petite) activation, ou avec l’intensité d’entrée plus réduite. L’intensité d’entrée est définie comme une distance métrique :
![]() (6.2)
(6.2)
Dans le sous chapitre 6.4 sont introduites quelques distances métriques plus souvent utilisées.
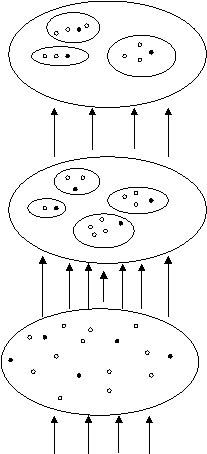
Fig.6.1 L'architecture d'un réseau compétitif
Par une inhibition latérale ( en anglais de type “on center – off sorround”) pendant un procÈs d’apprentissage itératif le neurone avec la plus grande activation initiale reste actif, pendant que tous les autres neurones convergent vers une activation nulle. À la fin un seul neurone reste actif, avec une sortie de 1, et tous les autres sont inactives avec une sortie nulle. Cette stratégie est connue sur le nome de 'le gagneur prend tout'. Ce principe a dénommé les réseaux auto-organisateurs aussi comme des réseaux compétitifs. Pendant les années plusieurs chercheurs élaboraient des modÈles compétitifs, ayant diverses lois d'apprentissage: von der Malsburg (1973), Grossberg (1972,1976), Fukushima (1975), Bienenstock, Cooper et Munro (1980), Rumelhart et Ziepser (1985).
Par exemple, conformément à la rÈgle du Kohonen les poids du neurone gagnant k se modifie avec la rÈgle:
![]() (6.3)
(6.3)
Ainsi le vecteur poids se déplace avec une fractionne h vers le vecteur d’entrée x. C’est recommandable une vitesse d’apprentissage initiale h=0.8 qui décroit vers une valeur h=0.1 ou plus petite. Pour tous les autres neurones les poids restent constants :
![]() (6.4)
(6.4)
Dans les paragraphes suivants on présente des autres lois d’apprentissage.
6.2 L’interprétation géométrique
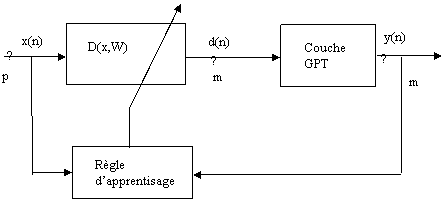
On peut représenter les vecteurs poids et les modÈles d’entrée par des points sur une sphÈre N dimensionnelle, s’ils sont normalisés. La rÈgle d’apprentissage spécifie que chaque fois qu’un neurone gagne la compétition son vecteur poids converge vers le modÈle d’entrée. C’est à dire que son vecteur poids se déplace de la location courante vers la location du vecteur d’entrée sur la sphÈre, comme on voit dans la Fig.6.2.
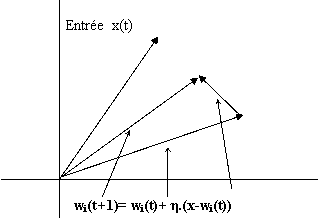 |
Dans Fig.6.3 les modÈles d’entrée (stimuli) sont représentés par des rectangles et les poids par des cercles.. Les stimuli similaires sont situés dans des points proches sur la sphÈre.
Dans la Fig.6.3a on peut voir huit stimuli. Les modÈles similaires d’entrée sont emplasés dans des points proches sur la sphÈre.
Quand a l’entrée s’applique un modÈle, comme dans la Fig.6.3b, le neurone avec le vecteur poids plus proche de modÈle d’entrée gagnera la compétition. Sur la sphÈre, le vecteur poids se dirige vers le modÈle d’entrée.
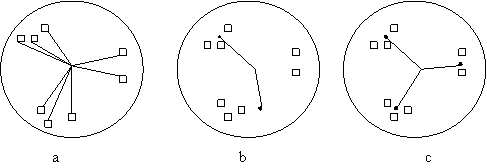 |
S’il y a trois neurones et trois groupes dans l’espace des modÈles d’entrée, chaque neurone gagnera la compétition pour une des trois groupes, comme dans la Fig.6.3c.
Pendant le temps les vecteurs poids deviendront plus denses pour les régions de l’espace d’entrée ou les modÈles sont plus denses et dispersés ou mÊme absents pour les régions avec des modÈles rares. C’est a dire que le RN s’adapte pou mesurer la fonction densité de probabilité des modÈles d’entrée.
6.3 Quelques distances métriques
Quelques distances métriques plus souvent utilisées sont les suivantes :
La norme euclidienne, donnée par l’amplitude du vecteur différence :
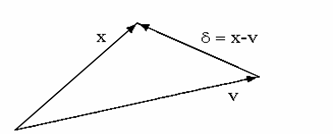
![]() (6.5)
(6.5)
Le carré de l’amplitude du vecteur différence :
![]() (6.6)
(6.6)
Relation (6.7) représente une simplification du cas précÈdent.
Distance Manhattan, qui est la somme des valeurs absolue des coordonnées du vecteur différence :
![]() (6.7)
(6.7)
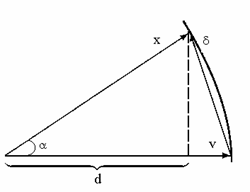
La projection du vecteur d’entrée x sur le vecteur v. Ca c’est la plus simple mesure du rassemblement des deux vecteurs :
![]() (6.8)
(6.8)
ou α est l’ongle entre les deux vecteurs
La distance mesurée comme produit :
![]() (6.9)
(6.9)
On recommande que les deux vecteurs sont normalisés || x ||=|| v ||=1.
Distance Hamming est le nombre des positions dont deux vecteurs sont différents:
![]() (6.10)
(6.10)
La distance arc de sphÈre :
![]() (6.11)
(6.11)
ou α est l’ongle entre le vecteur poids v et x, en considÈrent que le vecteurs v et x ont la mÊme longueur.
Exemples:
On calcule quelques distances, antérieurement présentées pour les vecteurs
x = [1 1 -1 1] si v = [1 -1 -1 -1].
distance euclidien = sqrt(02 + 22 + 02 + 22) = 2.83
distance Manhattan = 0 + 2 + 0 + 2 = 4
distance Hamming = 0 + 1 + 0 + 1 = 2
distance comme produit = [1 1 -1 1] [1 -1 -1 -1]T = 0
Pour le neurone gagnant a été utilisée une rÈgle de type Kohonen :
![]() (6.16)
(6.16)
oÙ aW est la constante d’apprentissage avec une valeur entre 0 et 1.
Les vecteurs poids des autres neurones qui ont perdu la compétition se modifient avec un rÈgle similaire a relation (6.16), mais avec une constante d’apprentissage plus petit que pour le neurone gagnant :
![]() (6.17)
(6.17)
oÙ aW est la constante d’apprentissage des neurones perdants avec valeur entre o et 1.
6.6.1 Des notions théorétiques
Dans ce réseau chaque neurone est couplé excitateur avec lui-mÊme et inhibiteur avec tous les autres :
 (6.18)
(6.18)
oÙ a = ![]() < 1 est une constante
positive petit N le nombre des neurones dans RN.
< 1 est une constante
positive petit N le nombre des neurones dans RN.
On peut écrire la relation (6.18) comme une matrice de dimension NxN:
![]()
 (6.19)
(6.19)
Le vecteur d’entrée est actif seulement pendant le moment initial. Chaque neurone calcule son entrée nette avec la relation (6.1), qui dans une forme matricielle devienne:
![]() (6.20)
(6.20)
Puis on calcule la sortie par l’application de la fonction d’activation:
![]() (6.21)
(6.21)
La fonction d’activation est souvent définie par la relation :
![]() (6.22)
(6.22)
Les sorties des tous neurones au moment t+1 sont utilisées pour déterminer les entrées nettes au moment successif t+2. On peut démontrer que par l’application récurrente des relations (6.20) et (6.21) ce réseau converge vers une situation quand un seul neurone, celui avec la plus élevée activation initiale restera actif, tandis que tous les autres activations convergÈrent vers zéro. C’est pourquoi ce réseau a été dénommé Maxnet, c’est à dire avec une activation NETte MAXimum. Le réseau est connu aussi sur le nome de réseau de type 'le gagneur prend tout' (GPT). Une réseau similaire est MINNET qui a aussi un seul neurone actif, celui avec la plus petite activation initiale.
Typiquement un réseau de neurones compétitif a deux couches de neurones, comme il est représenté dans la Fig.6.8:
la couche qui mesure la distance métrique ;
la couche compétitif de type Maxnet (ou Minnet);
Une fois sélectionné le neurone gagnant k, son vecteur poids change avec une rÈgle d’apprentissage. Soit, par exemple la loi suivante :
![]() (6.22)
(6.22)
oÙ le terme sous fraction assure la normalisation des vecteurs poids.
Le vecteur poids se dirige vers le vecteur d’entrée x. Chaque fois, quand s’applique une entrée x le plus proche vecteur poids se tourne vers lui. En conséquence les vecteurs poids se tournent vers les zones dont il y a beaucoup modÈles d’entrée, c’est à dire vers les groupes des modÈles.
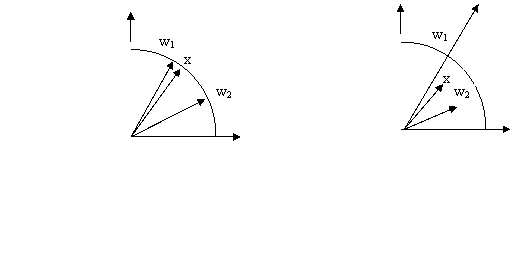
La normalisation est
essentielle pour l’apprentissage du réseau Maxnet. Dans la Fig.6.9 le vecteur
d’entrée et vecteur poids ont la mÊme orientation, mais dans le cas a ils
sont normalisés et dans le cas b ils ne sont pas normalisés.

Pour le cas de Fig.6.9a, le stimulus x est plus proche de w1 , ainsi que si on utilise la distance métrique donnée par le produit, le vecteur w1 gagne la compétition parce que:
![]() (6.23)
(6.23)
Pour le cas de Fig.6.9b le vecteur w2 est plus proche de x. Parce que la relation au-dessus présentée est encore valable, le vecteur w1 gagnera aussi la compétition et l'algorithme ratera la solution.
On désire changer l'algorithme ainsi qu'il peut opérer avec des données d'entrée qui ne sont pas normalisées. Pour choisir le neurone gagnant on peut utiliser la distance euclidienne:
![]() (6.24)
(6.24)
Le neurone gagnant est le neurone k.
En place de se tourner le vecteur poids vers l'entrée (conformément à relation (6.22)), le poids est actualisé pour le neurone k gagnant avec la relation suivante:
![]() (6.25)
(6.25)
4. Une loi d’apprentissage qui évite tous ces problÈmes et des autres qui peuvent apparaitre utilise la relation (6.25) pour le neurone gagnant et pour tous les neurones perdantes une relation similaire:
![]() pour tous les
neurones l¹k (6.27)
pour tous les
neurones l¹k (6.27)
oÙ g <<g est la constante d’apprentissage.
Soit un classificateur de neurones pour quelques caractÈres, réalisé avec une couche de type Hamming suivie d’une couche Maxnet, avec des seuils nulles. Soient les lettres C, I, T les modÈles prototypes. Le RN donnera la classe dont appartient le modelé appliqué à l’entrée, respectivement la classe avec la plus petite distance Hamming du modÈle d’entrée. .
La couche Hamming aura un neurone avec la plus élevée activation si la distance Hamming entre le modÈle d’entrée et la catégorie représentée par le neurone est minimum. Le réseau MAXNET supprime les sorties des tous les autres neurones excluant le neurone avec la plus grande activation initiale. Soit le modÈle prototype pour une classe m :
![]() (6.32)
(6.32)
La matrice des poids pour la couche Hamming qui classifie les modÈles d’entrée dans p classes est donnée par la relation:
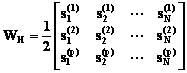 (6.33)
(6.33)
Pour la lettre C, le modÈle prototype est s=[1 1 1 1 -1 -1 1 1 1 1], conformément à la figure suivante:
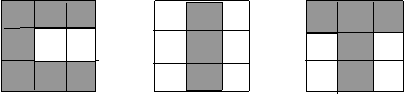
Pour la lettre I le modÈle prototype est s=[-1 1 -1 -1 1 -1 1 -1 1 ] et pour la lettre T le modÈle prototype est s=[1 1 1 -1 1 -1 -1 1 -1 ]. La matrice des poids du réseau Hamming est:
 (6.34)
(6.34)
L’entrée nette dans le réseau Hamming est donnée par la relation :
![]() , pour m=1,2, … , p (6.35)
, pour m=1,2, … , p (6.35)
ou par :
![]() (6.36)
(6.36)
oÙ HD est la distance Hamming, le nombre des positions dont les deux vecteurs diffÈrent. Pratiquement l’entrée nette donne le nombre des positions dont les deux vecteurs rassemblent:
![]() (6.37)
(6.37)
Les entrées nettes du réseau Hamming sont données par :
 (6.38)
(6.38)
 (6.39)
(6.39)
 (6.40)
(6.40)
Les sorties du réseau Hamming sont aussi les entrées dans le réseau Maxnet au moment 0 :
![]() (6.41)
(6.41)
![]()
![]()
Dans une forme vectorielle :
![]() (6.42)
(6.42)
Si on choit ε=0.2 (qui respecte la condition ε<1/3), la matrice WN est :
 (6.43)
(6.43)
L’entrée nette dans le réseau MAXNET est au moment initial :
 (6.44)
(6.44)
Les sorties du réseau MAXNET et les entrées nettes sont successivement :
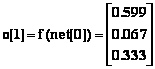 (6.45)
(6.45)
 (6.46)
(6.46)
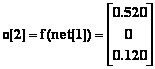 (6.47)
(6.47)
 (6.48)
(6.48)
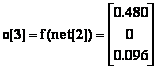 (6.49)
(6.49)
 (6.50)
(6.50)
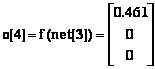 (6.51)
(6.51)
La sortie du réseau MAXNET est pour la quatriÈme itération et pour toutes les itérations ultérieures :
![]() (6.52)
(6.52)
Le plus proche modÈle prototype est celui de la lettre C :
![]()
La décision du réseau est que le modÈle d’entrée distorsioné avec du bruit est la lettre C.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 940
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved