| CATEGORII DOCUMENTE |
| Bulgara | Ceha slovaca | Croata | Engleza | Estona | Finlandeza | Franceza |
| Germana | Italiana | Letona | Lituaniana | Maghiara | Olandeza | Poloneza |
| Sarba | Slovena | Spaniola | Suedeza | Turca | Ucraineana |
DOCUMENTE SIMILARE |
|
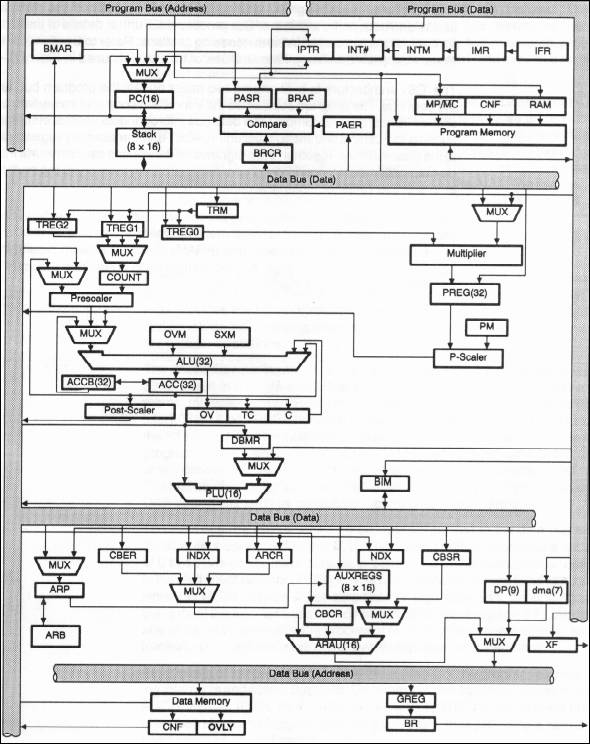
Fig. 10 : Architecture fonctionnelle du C50.
Le TMS320C50 est structuré autour des bus de programme et de données (Cf figure 10).
Le premier bus véhicule les instructions ainsi que les coefficients (constantes) ; le second véhicule les registres et les données présentent en mémoire données. On reconnaitra dans cette architecture :
le CALU (Central ALU) composé principalement de l’ALU et du multiplieur,
la PLU qui permet de faire des opérations logiques sans passer par l’accumulateur,
l’ARAU (Auxiliary Register Arithmetic Unit) qui gère l’adressage indirect et les buffers circulaires,
Les différents registres de contrôle.
Le CALU qui constitue le cœur du DSP comprend :
une ALU 32 bits avec son accumulateur ACC et le buffer d’accumulateur ACCB,
un multiplieur à virgule fixe avec son opérande (registre TREG0) et son registre résultat (PREG) tel que PREG = TREG0*données,
des registres à décalages notés Prescaler, Post-Scaler et P-Scaler.
Le CALU permet de faire une multiplication et une accumulation en un seul cycle machine.
L’ALU peut exécuter en général les opérations arithmétiques et logiques en un seul temps de cycle.
L’ALU travaille sur 2 opérandes 32 bits. Le résultat de l’opération est transféré dans l’accumulateur ACC (32 bits). Un des 2 opérandes vient de l’accumulateur ACC, l’autre peut provenir :
du registre PREG après passage dans le registre à décalage produit P-Scaler,
du registre à décalage Prescaler,
du buffer d’accumulateur noté ACCB.
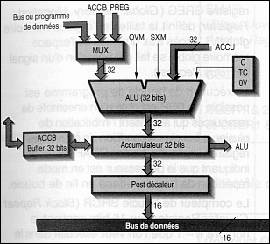
Fig. 11 : ALU.
Le Prescaler est chargé par une donnée 16 bits venant de la mémoire données et fournit un mot de 32 bits à l’ALU. Le Prescaler permet de faire un décalage à gauche de son entrée de 0 à 16 bits. Le nombre de décalages est spécifié dans les deux cas, soit par une constante faisant partie de l’instruction, soit par le registre TREG1.
Remarque : sur le schéma fonctionnel, on remarque que le Prescaler peut aussi avoir comme entrée, l’accumulateur ACC. Cette possibilité est seulement utilisée par l’instruction BSAR pour décaler le contenu de l’accumulateur de 1 à 16 bits à droite en un seul cycle.
Le Post-scaler permet, lors de la sauvegarde de l’accumulateur ACC dans la mémoire donnée, d’effectuer un décalage à gauche de l’accumulateur ACC sans en changer le contenu. Décalage de 0 à 7 bits à gauche spécifié dans l’instruction.
AVANT APRES TEMP1 = XX TEMP1 = 0841h ACC = 04208001h ACC = 04208001h
Exemple : SACH TEMP1, 1
Cet accumulateur 32 bits de sauvegarde, permet d’augmenter la rapidité de traitement. Il est utilisé par certaines instructions et notamment pour la recherche d’un extrémum dans un tableau en comparant ACCB à ACC.
Exemple : CRGT ; Si ACC > ACCB alors ACCB ACC
AVANT APRES ACCB = 4 ACCB = 5 ACC = 5 ACC = 5 C = 0 C = 1
Ainsi
en venant lire les différentes données
et en les plaçant dans ACC, à la fin de lecture du tableau
le maximum se trouvera dans ACCB.
Gestion de débordement : OVM ( registre ST0).
Le C5X permet de gérer les débordements en CA2, ainsi si le résultat d’une opération est en dehors des limites [ 231 - 1 = 7FFF FFFF h ; - 231 = 8000 0000 h ], le C5X garde comme valeur la saturation haute ou basse
( OVM = 1). Si OVM = 0,on désactive la gestion automatique de débordement.
La représentation en CA2 étant circulaire, un débordement positif (ou négatif) se traduit par un basculement de l’accumulateur du maximum vers la valeur minimum. Ce phénomène peut entrainer des oscillations en contrôle moteur ou pour la gestion de filtre numérique.
Dans le cas ou OVM = 1, le C5X se comporte comme tout circuit analogique qui sature lorsque on dépasse sa tension d’alimentation.
Exemple : soit un signal analogique d’amplitude 1V qui est numérisé par un CAN 16 bits de tension de référence Vref+ = 1V et Vref- = -1V. Le signal numérique oscille donc entre les valeurs 8000h et 0FFFh (Vmin et Vmax). On multiplie cette valeur par 1,4285 (1/0,7) et on écrit le résultat dans le CNA 16 bits de tension de référence Vref+ = 0,7V et Vref- = -0,7V. On obtient alors la courbe en trait plein si OVM = 1 (prise en compte de la saturation lors du calcul) ou la courbe en pointillé si OVM = 0 (Cf figure 12).
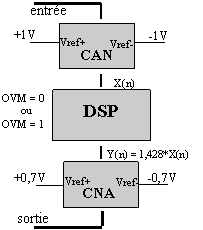
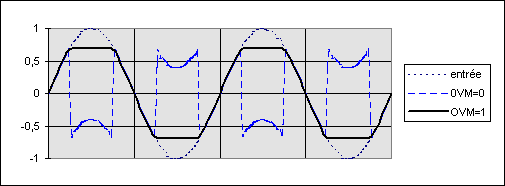
Fig. 12 : Débordement en complément à 2 avec écrêtage (cas où OVM = 1).
Mode d’extension du bit de signe : SXM (registre ST1).
Lors du chargement des données sur 16 bits dans l’accumulateur 32 bits :
si SXM = 1, le bit de signe est étendu,
si SXM = 0, les bits de poids forts sont forcés à 0.
Exemple :
LACC #A821h si SXM = 1 ACC = FFFFA821h
si SXM = 0 ACC = 0000A821h
Le multiplieur
cablé effectue la multiplication signée de 2 nombres 16 bits avec un
résultat sur 32 bits (PREG). Le
multiplieur utilise les registres : TREG0 : registre temporaire 16 bits où est chargée une des 2
opérandes ; PREG : registre résultat sur 32 bits.
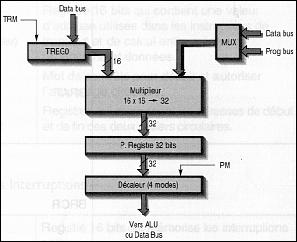
Fig. 13 : Le multiplieur 16*16.
Il est possible de faire des décalages sur le contenu de PREG lors de son transfert vers l’accumulateur ou la mémoire, et ceci grace aux 2 bits notés PM (registre ST1).
|
PM |
Nombre de décalages |
|
1 bit à gauche |
|
|
4 bits à gauche |
|
|
6 bits à gauche |
La plupart des instructions spécifie une opérande à la fois. Si l’on utilise les instructions à un seule opérande, il faut procéder en 2 étapes :
LT OP1 ; TREG0 valeur
MPY OP2 ; PREG OP1 x OP2
Exemple MAC 0FF00h, 24
|
AVANT |
APRES |
||||||
|
memoire données | |||||||
|
302h |
23h |
23h |
|||||
| ||||||||
|
mémoire programme | |||||||
|
FF00h |
4h |
||||||
|
c |
|
|||||||
|
TREG0 |
X |
23h |
|||||
|
c |
|
|||||||
|
PREG |
X |
8Ch |
|||||
|
||||||||
|
ACC |
0723 EC41 h |
0769 75B3 h |
|||||
4 instructions (MAC, MACD, MADD et MADS) utilisent pleinement les possibilités offertes par le CALU : pour ces instructions, les 2 opérandes sont transférés simultanément vers le multiplieur. L’un occupe le bus de données et l’autre le bus de programme. Le bus programme est donc détourné de son usage normal et l’instruction suivante ne peut être lue en avance, ce qui interrompt le pipeline. Ces instructions sont donc surtout intéressantes lorsqu’elles sont utilisées en mode répété (avec les instructions RPTZ et RPT). Il n’est alors pas nécessaire de lire la prochaine instruction puisque l’instruction à exécuter est stockée dans le registre d’instruction tant que dure la répétition.
L’adresse de l’opérande placé sur le bus programme est chargé dans le Compteur Programme. Elle s’incrémentera donc de 1 à chaque répétition. La valeur originelle du PC est sauvegardée automatiquement et restitué à la fin de la répétition.
Lors des répétitions, l’adresse du deuxième opérande peut être modifié par l’ARAU si un adressage indirect est utilisé.
L’instruction RPTZ initialise à 0 ACC et PREG chose que ne fait pas l’instruction RPT.
Exemple : On désire faire le produit d’une ligne d’une matrice avec une colonne de la deuxième matrice. Soit une matrice 10 x 10 avec MTRX1 pointeur sur le début de la matrice. INDX = 10 et AR(ARP) pointe vers le début de la deuxième matrice notée MTRX2.
RPTZ #9 ; For i = 0, i < 10, i++
MAC MTRX1, *0+ ; PREG = (MTRX1 + i) x (MTRX2 + (i x INDX)) ACC += PREG
APAC ; ACC += PREG dernière accumulation
L’instruction MACD (Multiply ACcumulate and Dmov) diffère de l’instruction MAC car elle effectue une opération supplémentaire : elle recopie l’opérande en mémoire données à l’adresse suivante, sans changer le contenu de l’adresse lue. Cette recopie ne peut s’effectuer que dans la mémoire RAM interne configurée en mémoire données. Elle ne peut avoir lieu dans la mémoire externe ou dans le MMR (Memory Map Register). Cette recopie est utilise dans le cas de filtres numériques ou elle correspond au déplacement des donn »es dans un registre à décalage.
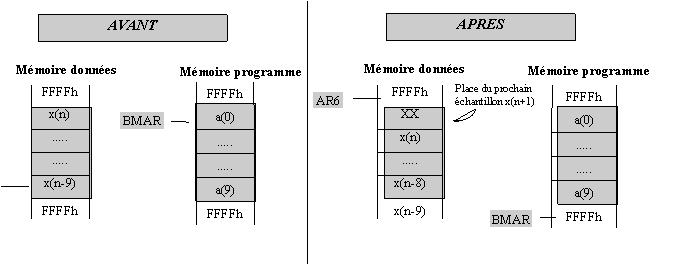
Pour les instructions MADS et MADD, cette adresse est indiquée dans le registre BMAR (Block Move Adress Register) ; ces instructions sont codées sur 16 bits au lieu d’être codées sur 32 bits pour les instructions MAC et MACD.
Exemple : on désire
programmer un filtre numérique FIR de la forme : ![]()
Les conditions initiales sont AR(ARP) pointe sur x(9) et BMAR pointe sur la table des coefficients a(i).
L’instruction RPTZ met à 0, ACC et PREG. Le PC est stocké dans un registre temporaire pendant l’exécution de la boucle. Puis le PC est chargé avec la valeur de BMAR . le bus de programme est utilisé pour véhiculer les coefficients et pendant l’exécution de l’instruction MADD , le PC est incrémenté (comme toujours) ce qui permet de venir lire les coefficients un par un. L’ARAU s’occupe de l’adressage des données x(i). Puisque l’on commence par x(9) et que l’on utilise l’instruction MADD, après avoir récupérer la donnée, celle-ci est recopiée à l’adresse suivante. Puis AR(ARP) est décrémenté pour venir lire x(8) et ainsi de suite. Ce décalage, de tout le bloc de données vers le bloc juste supérieur, permet de pouvoir placer une fois le filtre calculé, le nouvel échantillon à la place de l’échantillon précédent.
RPTZ #9 ; ACC = PREG = 0. For i = 9 to 0 Do
MADD *- ; Somme des ai * xi xi+1 = xi
APAC ; dernière somme
AR6
La PLU opère en parallèle avec l’ALU. Elle effectue des opérations
logiques sur 2 opérandes. L’un des opérandes vient de la mémoire données,
l’autre vient , soit de la mémoire programme (cas de l’adressage immédiat),
soit du registre DBMR qui est
lui-même chargé à partir de la mémoire données. L’avantage de la PLU est qu’il permet une opération
logique sur une donnée sans perturber le CALU.
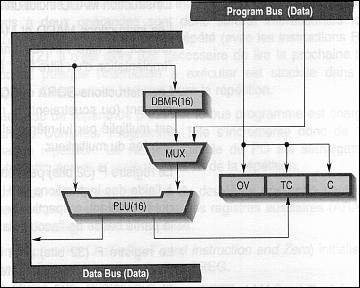
Fig. 14 : Unité Logique Parallèle ou PLU.
La PLU peut effectuer différents types d’opérations :
des opérations logiques à l’aide des instructions OPL (OU logique), APL (ET logique) et XPL( OU exclusif),
des chargements immédiats d’une adresse en mémoire données avec une constante longues de 16 bits, à l’aide de l’instruction SPLK (Store PLU Long Immediat),
des tests sur la valeur de certains bits de mots rangés en mémoire données par l’instruction BIT ou BITT (utilisation de TREG2 pour spécifier le bit à tester),
des comparaisons avec une valeur par l’instruction CPL. La donnée en mémoire est comparée au contenu du registre DBMR ou à une constante de 16 bits.
D’une manière générale, le bit TC est mis à 1 lorsque le résultat de l’instruction dans la PLU est nul. Seule l’instruction NORM utilisée pour le passage d’un nombre à virgules fixes vers un nombre à virgules flottantes utilise l’ALU pour mettre à jour le bit TC.
Exemples :
SPLK #021h, CBCR ; CBCR 021h utilisation du bus données et programme
OPL data ; data data OU DBMR
APL #0FF00h ; data data ET 0FF00h
BCND BIT_MSB_1, NTC ; si DATA = 0FFxxh alors branchement à BIT_MSB_1
BIT_MSB_1
L’ARAU est utilisée pour l’adressage indirect (CF chapitre suivant).
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1402
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2026 . All rights reserved