| CATEGORII DOCUMENTE |
MULTICALCULATOARE CU TRANSFER DE MESAJE
Din capitulul anterior am vazut ca multiprocesoarele ofera programelor un singur spatiu de adrese facand comunicarea si sincronizarea relativ usoare. In plus programatorul nu trebuie sa stie nimic despre topologia interna (in realitatea, totusi, o buna cunoastere l-ar ajuta sa scrie programe mai performante). Dar pe langa avantajul programarii usoare, multiprocesoarele au limitari serioase in ce priveste scalabilitatea. Arhitecturile UMA pot avea maxim 64 de procesoare, dar cu eforturi deosebite, arhitecturile CC-NUMA merg de regula pana la 256 de procesoare, desi exista arhitecturi cum ar fi SGI Origin 2000 care pretind ca pot atinge 1024 de procesoare. Atractivitatea acestui model, numarul mare de aplicatii si portabilitatea lor, vor face ca multiprocesoarele sa domine in continuarea piata sistemelor paralele, si sa cunoasca aceasi evolutie ascendenta de pana acum.
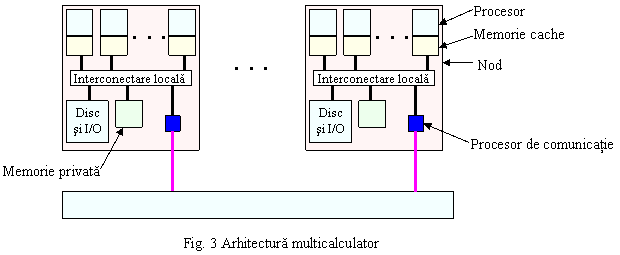
Arhitecturile multicalculator pot depasi cu mult cifra de o 1000 de peocesoare. Principiul de baza al acestor sisteme este ca fiecare procesor are memoria privata, neaccesibila altor procesoare. Acest lucru conduce ca fiecare procesor sau nod (grup de procesoare ce poate fi o arhitectura SMP UMA) are o copie a sistemului de operare. Programele interactioneaza prin intermediul unor primitive de tipul SEND (transmite) si RECEIVE (receptioneaza).
Un exemplu tipic de multicalculator este prezentat in figura 3 Fiecare nod consta din unul sau mai multe procesoare, memorie RAM partajata de procesoarele din nod, echipamente de I/O, discuri magnetice si un procesor de comunicatie ce asigura legatura la o retea de interconecatare foarte rapida. Rtelele pot avea diferite topologii, scheme de comutare si algoritmi de rutare. Comunicarea intre noduri se face prin transfer de mesaje utilizand primitivele SEND si RECEIVE.
Exista o mare varietate de sisteme mulicalculator, dar in general exista moduri de abordare diferite: procesoare masiv paralele (MPP - Massively Parallel Processors) si grupuri de statii de lucru (COW - Cluster of Workstation).
1. Procesoare masiv paralele
Sunt cele mai scumpe calculatoare de pe piata la ora actuala, avand preturi ce depasesc multe milioane de dolari. Ele sunt utilizate in general pentru calcule stiintifice si ingineresti, in industrie si pentru stocarea si prelucrarea de baze de date imense. Ele sunt succesoarele calculatoarelor mari (mainframe) ale anilor 1960 si apoi ale masinilor SIMD (procesoarele matriciale si vectoriale). Majoritatea MPP actuale utilizeaza procesoare comerciale standard, cum ar fi Intel Pentium, DEC Alpha, IBM RS/6000, Sun UltraSPARC. Utilizeaza retele de comunicatie proprietare, de foarte mare performanta, proiectate sa transfere mesaje cu largime de banda mare si o latenta redusa. In general dispun de extensii software proprii si de biblioteci de programe specializate.
MPP dispun de sisteme de intrare/iesire foarte puternice si de capacitati uriase de stocare. Faptul ca dispun de mii de procesoare, au trebuit adoptate solutii hardware si software speciale pentru monitorizarea sistemului, detectarea erorilor si recuperarea lor. Astfel de sisteme nu pot fi concepute decat ca sisteme tolerante la defectari.
In general nu exista principii general acceptate de proiectare a sistemelor MPP.
Este ultimul supecomputer din linia inceputa la mijlocul anilor 1960 de Seymour Cray. Modelele T3E, T3E-900 si T3E-1200 sunt arhitectural identice, difera doar frecventa procesorului si dimensiunea memoriei. In general aplicatiile sunt de tipul: modelarea climatului, proiectarea medicamentelor si exploatarea zacamintelor de petrol.
Utilizeaza procesorul DEC Alpha 21164 (procesor RISC pe 64 de biti, superscalar, 4 instructiuni pe ciclu de ceas, supepipeline) la frecvente de ceas de 300, 450 si 600 MHz. Poate adresa o memorie fizica de pana la 1 TB (40 de biti de adresa) si virtuala de pana la 8 TB. Dispune de cache intern pe doua nivele.
Nodurile sunt formate dintr-un procesor Alpha, pana la 2 GB memorie RAM, procesorul de comunicatie si 512 registre speciale, numite registre E. Aceste registre adrese de memorie de la distanta ce permit citirea/scrierea de blocuri de 8 cuvite de 64 de biti (64 octeti) din memoriile nodurilor de la distanta.
Un sistem poate avea pana la 2048 de noduri. Nodurile sunt conectate in doua moduri:
Interconectarea principala: un tor 3D duplex. Un sistem cu 512 noduri poate fi configurat ca un hipercub 8x8x8. Fiecare nod are 6 legaturi. Rta de transfer pe legatura este de 480 Mbps in fiecare directie.
Interconectarea sistemului de I/O: unul sau mai multe inele GigaRing pe 32 de biti, de banda foarte larga, cu comutare de pachete. Sunt conectate nodurile procesor cu nodurile de I/O. Nodurile de I/O contin sloturi pentru interfete de retea de tipul Ethernet, ATM, FDDI, Fiber Channel, HIPPI sau interfete SCSI pentru discuri, benzi etc.
Toleranta la defecte e asigurata printr-un nod de rezerva la fiecare 128 de noduri si software-ul necesar pentru monitorizarea functionarii, detectarea erorilor si inlocuirea nodului defect fara repornirea sistemului.
Nodurile sunt de doua tipuri: noduri utilizator ce ruleaza o copie simplificata a sistemului de operare si noduri server ce ruleaza sistemul de operare. Sistemul de operare este o versiune de Unix.
Este sistemul care a care a castigat prima licitatie a Departamentului pentru Energie al SUA, conceput special pentru a atinge performanta de 1 Tflops si a fi utilizat in simularile exploziilor nucleare. Nu este un calculator comercial, dar utilizeaza procesoare comerciale Intel Pentium Pro la 200 MHz.
Arhitectura sa cuprinde 4536 de noduri, fiecare cu 2 procesoare si 64 MB memorie RAM. Nodurile sunt conectate printro retea de tip grila 32x38x2 (cu 2 plane). Fiecare punct al grilei are un circuit de comutare cu 6 cai.
Sistemul este impartit in 4 partitii: servicii, calcul, I/O si sistem. Nodurile de servicii sunt masini Unix, cu divizarea timpului. Nodurile de calcul executa sarcinile propriu-zise ale masinii (pentru care ea a fost comandata). Aceste noduri ruleaza o versiune simplificata de Unix. Nodurile de I/O gestioneaza cele 640 de discuri cu peste 1 TB de date. Exista doua seturi independente de noduri de I/O: pentru date secrete si pentru date comune. Selectarea lor este exclusiva si se face manual, pentru a preveni scurgerea de date secrete. Nodurile sistem asigura pornirea sistemului si repartizarea aplicatiilor.
2. Grupurile de statii de lucru (COW - Clauster of Workstations)
Constau din sute de PC-uri sau statii de lucru conectate in retea prin placi de retea disponibile in comert. Daca sistemele MPP sunt in general sisteme care incap intr-un numar oarecare de cabinete si toate aceste cabinete intra intr-o camera, sistemele COW pot fi raspandite pe o arie ce cuprinde de la o cladire, un campus, un oras si chiar un continent. O alta diferenta este ca sistemele MPP utilizeaza retele proprietare de mare viteza, in schimb clusterele utilizeaza retele comerciale.
Cele doua tipuri de sisteme sunt administrate diferit si sunt folosite diferit.
Sistemele COW sunt realizate in intregime din sisteme comerciale (fie ele chiar arhitecturi UMA sau CC-NUMA). Se estimeaza ca in urmatorii 10 ani arhitecturile MPP vor dipare de pe piata. Cauza: preturile foarte mari, raportul pret/performanta extrem de defavorabil si aplicatiile neportabile. In plus arhitecturile cluster incep sa beneficieze tot mai mult de progresele deosebite in domeniul retelelor de calculatoare comerciale obtinute pe parcursul ultimilor 5 ani, care vor depasi performantele retelelor proprietare.
5. CONCLUZII
Din cele doua mari categorii de arhitecturi paralale, SIMD si MIMD, prima categorie este deja de domeniul istoriei. Masinile MIMD domina procesarea paralela. Dar si in aceasta categorie sunt multe diferentieri de facut.
Multiprocesoarele cu memorie partajata, desi au o scalabilitate limitata domina si vor continua sa domine piata calculatoarelor paralele. Principala lor atractivitate este modelul lor de programare care a facut ca aplicatiile sa fie portabile si usor de realizat. Numarul mare de aplicatii, practic nelimitat le asigura un viitor ascendent. Cercetarile actuale vizeaza modele SMP UMA si modelele COMA cu ierarhii de magistrale si nivele sporite de memorie cache care sa permita o scalabilitate dincolo de limita a 256 de procesoare. De asemeni continua sa se investeasca mult in cercetarea arhitecturilor CC-NUMA, in reducerea neuniformitatilor accesului la memorie si in imbunatatirea algoritmilor de asigurare a coerentei prin directoare. Rezultate promitatoare au adus sistemul SGI Origin 2000.
Din categoria arhitecturilor multicalculatoare cu transfer de mesaje, se estimeaza ca sistemele MPP vor disparea de pe piata in urmatorii 10 ani, in schimb arhitecturile cluster vor beneficia de progresele tehnologice deosebite din domeniul retelelor de calculatoare si ajutate de cercetarile deosebit de intense din sfera protocoalelor de implemantare a memoriei partajate distribuite (DSM - Distributed Shared Memory) vor domina piata multicalculatoarelor. Sistemele de operare ce implementeaza DSM vor asigura convergenta arhitecturilor multicalculator cu transfer de mesaje spre modelul memoriei partajate, adica spre un izvor nesecat de aplicatii.
BIBLIOGRAFIE
Hennesy J., Patterson D., Computer Organization and Design, Second Edition, Morgan Kaufmann Publishers, 1998.
Tanenbaum A., Organizarea structurata a calculatoarelor, Editia a patra, Computer Press Agora, 1999.
Moldovan D., Parallel Processing from Applications to System, Morgan Kaufmann Publishers, 1994
Hockeney R., Jesshope C., Calculatoare paralele. Arhitectura, programare si algoritmi, Editia a doua, Editura Tehnica, 1991.
5. Leighton T., Introduction to Parallel Algorithms and Architectures. Arrays, Trees, Hipercubes, Morgan Kaufmann Publishers, 1992
Torrelas J., The performance of the Cedar Multistage Switching Network, IEEE Transactions on Parallel and Distributed Systems, 8(4), April 1997.
Sharma V., Varvarigos E., Circuit switching with Input Queuing: An Analysis for the d-Dimensional Wraparound Mesh and the Hypercube, IEEE Transactions on Parallel and Distributed Systems, 8(4), April 1997.
Tseng Y., Lin T., Gupta S., Bandwidth-Optimal Complete Exchange on Wormhole-Routed 2D/3d Torus Networks: A Diagonal-Prpagation Approach, IEEE Transactions on Parallel and Distributed Systems, 8(4), April 1997.
Kim J., Liu Z., Compressionless Routing: A Framework for Adaptive and Fault-Tolerant Routing, IEEE Transactions on Parallel and Distributed Systems, 8(3), March 1997.
10. Greenberg R., Oh H., Universal Wormhole Routing, IEEE Transactions on Parallel and Distributed Systems, 8(3), March 1997.
11. Wang F., Lin F., On Routing Maskable Messages in Hypercube-Derived Multistage Interconnection Networks, IEEE Transactions on Parallel and Distributed Systems, 8(3), March 1997.
12. Qiao C., Melhem R., Reducing Communication Latency with Path Multiplexing in Optically Interconncted Multiprocessor Systems, IEEE Transactions on Parallel and Distributed Systems, 8(2), Feb. 1997.
13. Day K., Ayyoub A., The Cross Product of Interconnection Networks, IEEE Transactions on Parallel and Distributed Systems, 8(2), Feb. 1997.
1 Bhuyan L., Izer R., Askar T., Performance of Multistage Bus Networks for a Distributed Shared Memory Multiprocessor, IEEE Transactions on Parallel and Distributed Systems, 8(1), Jan. 1997.
15. Koufatty D., Chen X., Data Forwarding in Scalable Shared-Memory Multiprocessors, IEEE Transactions on Parallel and Distributed Systems, 7(12), Dec. 1996.
16. Durand D., Montaut T., Impact of Memory Contention on Dynamic Sheduling on NUMA Multiprocessors, IEEE Transactions on Parallel and Distributed Systems, 7(11), Nov. 1996.
17. Duato J., A Necessary and Sufficient Condition for Deadlock-Free Routing in Cut-Through and Store-and-Forward Networks, IEEE Transactions on Parallel and Distributed Systems, 7(8), Aug. 1996.
18. Steenkiste P., Network-Based Multicomputers: A Practical Supercomputer Architecture, IEEE Transactions on Parallel and Distributed Systems, 7(8), Aug. 1996.
19. Laudon G., Lenoski D., The SGI Origin: A ccNUMA Highly Scalable Server, Internet, 1999.
20. Keriton D., Goosen H., Boyle P., ParaDiGM: A Highly Scalable Shared Memory Multi-Computer Architecture, Internet, 2001.
21. Ravindran G., Stumm M., A Comparison of Blocking and Non-blocking Packet Switching Techniques in Hierarchical Ring Networks, IEICE Trans. Inf. & Syst., vol. E79-D, No. 8, August 1996.
22. Ravindran G., Stumm M., Hierarchical Ring Topologies and the effect of their Bisection Bandwidth Constraints, Proc. Intl. Conf. on Parallel Processing, pp.I/51-55, 1995
23. Mattson T., Henry G., An Overview of Intel TFLOPS Supercomputer, www.intel.com, 2001.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1107
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved