| CATEGORII DOCUMENTE |
| Asp | Autocad | C | Dot net | Excel | Fox pro | Html | Java |
| Linux | Mathcad | Photoshop | Php | Sql | Visual studio | Windows | Xml |
This entire book has been focused on the core programming model that applies to programs written for the CLR. At every step, I have tried to keep the discussion focused on the virtualized world of the CLR, avoiding discussion of OS-isms or memory management whenever possible. It is appropriate that, in this last chapter, we will do a reality check and see how CLR-based programs relate to the world around them.
One of the key characteristics of modern runtime environments such as the CLR is that they raise the level of abstraction from manual memory management to a type-centric model based on types, objects, and values. In such a model, the use of memory is implicit, not explicit. For the lion's share of programs, the resultant increase in productivity far outweighs any inconvenience that the lack of low-level control may impose. However, there is a class of problem for which explicit memory manipulation is vital, the most common of which is the direct access of memory buffers. This sort of direct access is critical in high-performance I/O processing, dealing with memory-mapped devices, and interfacing with existing C-based libraries or system calls.
Most runtimes (including the CLR) provide a way to integrate with C-based libraries through a thunking layer (e.g., J/Direct, P/Invoke, Java Native Interface [JNI]). However, these thunking layers do not come without a cost. In all cases, the transition from 'runtime mode' to 'C mode' incurs a nontrivial performance cost. This leads to unnatural designs that minimize transitions between the two worlds in order to maintain respectable performance. Additionally, in at least one of these thunking layers, JNI, one must write an adapter library in C or C++ to map between the Java VM and the target library.
What makes the CLR unique is that the CLR type system and instruction set allow the use of classic C-style memory manipulation for programs that absolutely require it. The explicit use of memory is fully supported in CIL and does not require machine-dependent native code. The explicit use of memory is completely consistent with the runtime semantics of the CLR and does not require a 'mode switch' to disable the services provided by the CLR. The explicit use of memory does require an understanding of how the CLR distinguishes between object references and pointers.
The CLR treats object references as distinct from pointers, despite the fact that both are ultimately addresses of memory locations. Object references support a set of operations distinct from those of pointers. In particular, object references support assignment, identity comparison, and member access. Period. There is no notion of 'dereferencing' an object reference, nor any notion of 'object reference arithmetic.' Finally, object references are assumed to refer to distinct objects on the garbage-collected heap, and this means that the address contained in an object reference is subject to change when the garbage collector compacts the heap.
The CLR supports pointers as a construct distinct from object references. Unlike object references, pointers are meant to be dereferenced. Unlike object references, pointers are ordered and can be compared using the < and > operators. Also, unlike object references, pointers support arithmetic operations, allowing random access to memory. This last difference imposes problems that bear closer scrutiny.
Because C-style pointers allow programs to access arbitrary memory, the use of C-style pointers makes program verification intractable. Program verification is a key feature of the CLR that is used to ensure that components do not compromise the security of the CLR or the host environment. Programs that do not use C-style pointers can be verified because all accesses to objects and values can be verifiably type-safe. However, in the presence of random memory access, it is possible to spoof the system into believing that arbitrary memory is in fact an instance of a highly trusted component. For this reason, the CLR supports two types of pointer: one that does not compromise verifiability, and one that does.
CLR-based programs routinely use pointers that are verifiable. These kinds of pointers are referred to as managed pointers. The C# and VB.NET compilers use managed pointers whenever a method parameter is declared as pass-by-reference. Unlike C-style pointers, managed pointers do not support arithmetic operations. Additionally, the initialization and assignment of a managed pointer are constrained to ensure that there is no compromise of the CLR type system. To that end, managed pointers are strongly typed and are themselves instances of a type. For example, a managed pointer to System.Int32 is an instance of type System.Int32&. The ultimate reason that managed pointers are called 'managed' is that the garbage collector is capable of adjusting the pointer value when the referent is moved during heap compaction.
Managed pointers exist largely to implement pass-by-reference for method parameters. The CLR also supports a second style of pointer that behaves exactly like a C-style pointer. This style of pointer is called an unmanaged pointer. The adjective unmanaged is used because the garbage collector ignores unmanaged pointers during heap compaction. Like managed pointers, unmanaged pointers are instances of a type. For example, an unmanaged pointer to System.Int32 is an instance of type System.Int32*.
Unlike managed pointers, unmanaged pointers support pointer arithmetic and unchecked type casts. With unmanaged pointers, it is completely legal to write code that looks like this:
int x = 0x12345678;The C# compiler is perfectly happy to turn this very dangerous code into CIL. Moreover, the CLR is happy to turn the CIL into native code and then execute it. However, neither of these things will happen without an explicit action on the part of the developer and the system administrator or user.
The use of unmanaged pointers results in code that is not verifiably type-safe. The ability to execute code that is not verifiably type-safe is a highly trusted security permission that, by default, the CLR denies to all code not originating from the local file system. In particular, the assembly containing the nonverifiable code must request (and be granted) the SecurityPermissionFlag.SkipVerification permission in its assembly manifest. On a default installation of the CLR, this permission is not granted to code loaded from remote file systems, so the only way to get nonverifiable code to execute is to dupe a user into copying it to an executable area of the local file system. Of course, the administrator or end user may explicitly grant permission to run code that is known to be trusted, but this as well requires that someone with trusted access to the deployment machine take a deliberate action.
Because of the role of C-style pointers in C++ programs, the C++ compiler emits only nonverifiable code. In contrast, VB.NET emits only verifiable code. C# supports both verifiable and nonverifiable code. By default, the C# compiler emits verifiable code. This allows one to deploy C# code easily from remote file systems or Web servers. To keep programmers from randomly generating nonverifiable code, the C# compiler forces them to explicitly state that they intend to use unmanaged pointers in their programs. This statement takes the form of a compiler switch and of a language keyword.
To compile C# programs that use unmanaged pointers, one must use the /unsafe or /unsafe+ command-line switch. This switch causes the compiler to emit the permission set requesting the SkipVerification permission. This switch also allows the use of unmanaged pointers in the source code of the program.
To discourage the use of unmanaged pointers, C# requires that any use of an unmanaged pointer appear inside a surrounding scope (e.g., method, type) that is declared as unsafe. For example, the following code will not compile because of the absence of the unsafe keyword:
public class BobThe following code would compile:
public class BobThis code would also compile:
public unsafe class BobOf course, these latter two programs will compile only if the /unsafe or /unsafe+ command-line switch is used.
The use of unmanaged pointers requires even more attention to detail than the use of pointers in classic C. This is because unmanaged pointers need to be respectful of the memory that is 'owned' by the CLR. This issue is especially contentious when one is dealing with memory on the garbage-collected heap.
The CLR can (and will) relocate objects on the garbage-collected heap. This means that taking the address of a field in an object requires great care because the garbage collector does not adjust unmanaged pointers when compacting the heap. To allow unmanaged pointers to refer to fields in objects, the CLR allows unmanaged pointers to be declared as pinned. A pinned pointer prevents the surrounding object from being relocated for as long as the pinned pointer is in scope. Each programming language exposes pinned pointers differently. In C++, one uses the __pin pointer modifier. In C#, one uses the fixed statement as shown here:
public unsafe class BobFor the duration of the fixed statement, the object referred to by b is guaranteed not to move, even if Console.WriteLine blocks for a significant duration of time. However, the object may move prior to the execution of the last statement of the Hello method. If this happens, the garbage collector will adjust the b reference accordingly. Note, however, that if a garbage collection occurs while a pinned pointer is in scope, the CLR cannot relocate the underlying object. For this reason, programmers are encouraged to hold pinned pointers for as short a time as possible to avoid heap fragmentation.
It is important that programmers not cache unmanaged pointers to memory on the garbage-collected heap. For example, the following program is a crash waiting to happen:
unsafe class BobThis program will compile without warning or error. However, the assignment of a pinned pointer (p) to a nonpinned pointer (pi) should give experienced C# programmers concern. In this example, the use of pi after the fixed statement will result in random behavior. This is exacerbated by the explicit call to System.GC.Collect, but by no means would the program be valid in the absence of such a call because garbage collection can happen at any time because of library calls, work done by secondary threads, or the use of the concurrent garbage collector.
It is important to note that you do not need to use pinned pointers when accessing memory on the stack. This means that taking the address of a local variable (or the field of a local variable of value type) does not require any special treatment. In fact, the following code will result in a compiler error because the CLR never relocates values declared as local variables:
public class TargetC++ and C# support scaled addition and subtraction only on unmanaged pointers. To perform arbitrary numeric operations, one must first cast to a numeric type. The CLR supports two generic numeric types for this purpose that are guaranteed to be large enough to hold a pointer. One usually exposes these types (native int and native uint) to programmers via the System.IntPtr and System.UIntPtr type, respectively. Because different architectures use different pointer sizes, the size of these two types is indeterminate and not known until runtime. The following code demonstrates the use of native int to round a pointer up to an 8-byte boundary.
static IntPtr RoundPtr(IntPtr ptr)Note that this code uses the System.IntPtr.Size property to select the appropriate numeric type. Also note that this code takes advantage of the fact that one can freely cast System.IntPtr to and from System.Int32, System.Int64, or void*. This also makes System.IntPtr the most appropriate type to use when one is representing Win32 handle types such as HANDLE or HWND.
It is difficult to look at pointer use without dealing with the layout of types. Consider the following C# program:
using System;Had the equivalent program been written in classic C or C++, the three assertions would succeed because C and C++ guarantee that the in-memory layout of a type is based on order of declaration. As discussed in Chapter 3, the CLR uses a virtualized layout system and will lay out types based on performance characteristics. For most programs, this is ideal. However, for programs that explicitly manipulate memory based on the in-memory format of a type, one needs some mechanism to override the automatic layout rules and explicitly control the layout of a type.
There are three metadata attributes that control the layout of a type: auto, sequential, or explicit. Each type has exactly one of these attributes set. The CLR calculates the layout of types marked auto at runtime, and these types are said to have 'no layout.' The CLR guarantees that types marked as sequential will be laid out in order of declaration using the default packing rules for the host platform (on Win32, this is the equivalent to Microsoft C++'s #pragma pack 8 option). One specifies the precise format of types marked as explicit via additional metadata entries that indicate the offset of each individual field of the type. Types marked as sequential or explicit are sometimes called formatted types because their format is under the control of the programmer.
When emitting the metadata for a type, compilers are free to use whichever attribute the language designer prefers. In C# and VB.NET, classes are marked auto and structs are marked sequential by default. To allow programmers to express the layout attributes in a consistent manner, the CLR defines two pseudo-custom attributes: System.Runtime.InteropServices.StructLayout and System.Runtime.InteropServices.FieldOffset. These attributes simply inform the compiler how to emit the metadata and do not appear as custom attributes in the target executable.
To understand the impact of these attributes, consider the following three C# type definitions:
using System.Runtime.InteropServices;The three types are logically equivalent, but each has a different in-memory representation. On the author's machine, Jane's fields will be ordered , Helen's fields will be ordered , and Betty's fields will be ordered . Because C# assumes sequential for structs by default, the StructLayout attribute on Helen is superfluous.
It is important to note that when using the explicit layout option, one must take care to maintain the platform-agnostic nature of the CLR. Specifically, the sizes of object references, managed pointers, and unmanaged pointers are all indeterminate and cannot be known until the code is loaded on the deployment machine. For that reason, one should use explicit layout with care on types that contain object references or pointers to ensure that ample space is available for each field. Failure to do so will result in a type initialization error at runtime (specifically, a System.TypeLoadException). As an aside, it is legal to have overlapping fields that are not object references. This is one way to implement C-style unions in CLR-based programs. The following C# type illustrates this technique:
using System.Runtime.InteropServices;Note that instances of Number have enough storage for either a System.Double or a System.Int64 but not both.
There is one final topic related to types and layout that needs to be addressed. As just discussed, the explicit metadata attribute completely sacrifices the virtualized layout provided by the CLR. However, even types that are marked explicit have rich metadata, and the CLR is aware of the fields, methods, and other members of the type. This is perfectly acceptable for types that adhere to the CLR's common type system. However, to allow compilers to support constructs that are not part of the CLR's common type system, such as multiple inheritance or templates, the CLR provides a mechanism for indicating that a type is opaque. Opaque types are just that: opaque. The metadata for an opaque type consists of nothing other than the size of an instance in memory. There is no metadata to indicate the fields or methods of the type. Additionally, opaque types are always value types, and that frees the implementation from needing to support the CLR's runtime type infrastructure or garbage collector.
C# and VB.NET do not support opaque types. In contrast, C++ supports opaque types by default. When one uses the /CLR switch, all C++ classes and structs are emitted as opaque types. The CLR does this to maintain strict C++ semantics, which allows any C++ program to be recompiled to a CLR module and just work. To indicate that a type is not opaque (sometimes called a managed type), the C++ type definition must use either the __gc or the __value modifier, depending on whether one desires a reference type or a value type. When one uses either of these modifiers, the resultant type will no longer have pure C++ semantics. Rather, issues such as order of construction, finalization, and other CLR-isms will apply to the type.
To understand the difference between opaque types and non-opaque types in C++, consider the following C++ type definitions:
template <typename T>Because neither Bob nor Steve is marked __gc or __value, the C++ compiler will compile these types as opaque types, and they will have full C++ semantics (deterministic destruction and base-to-derived construction). However, because these types are opaque, none of the fields of Bob or Steve will appear in the metadata. In fact, the methods of Bob and Steve will appear as module-scoped methods using mangled names. Also, because the CLR does not support generics, the C++ compiler must explicitly instantiate the types Bob<int> and Bob<double> as distinct types in the metadata.
The fact that the CLR does not know the fields of opaque types presents a problem when one is dealing with object references. Because the CLR must know the location of every object reference in order to implement garbage collection, opaque types cannot have object references as fields. To get around this limitation, the CLR provides a type, System.Runtime.InteropServices.GCHandle, that supports treating object references as integers. To use a GCHandle, one must first explicitly allocate one using the static GCHandle.Alloc method. This method creates a rooted object reference and stores a handle to that reference in the new GCHandle instance, as shown in Figure 10.1. Any program can convert a GCHandle to and from an IntPtr (which is safe to store in an opaque type). The allocated GCHandle (and its rooted reference) will exist until the program makes an explicit call to GCHandle.Free.
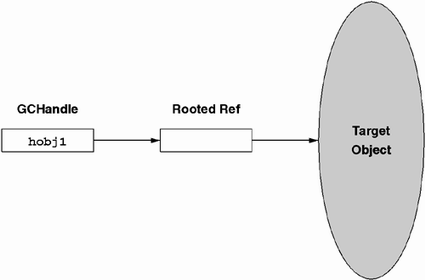
The following opaque C++ class demonstrates how to use a GCHandle to cache an object reference as a field:
#using <mscorlib.dll>Readers with a COM background will likely notice the similarity between the GCHandle type and COM's global interface table. To that end, the Visual C++ include directory contains a file, gcroot.h, that defines a smart pointer to simplify the use of GCHandle in opaque types. Given that header file, one could rewrite the previous example as follows:
#using <mscorlib.dll>C++ programmers familiar with smart pointers should feel right at home with this usage.
The previous discussion regarding explicit access to memory illustrates how rich the CLR type system and instruction set are. The availability of managed and unmanaged pointers allows programs to gain efficient access to memory without sacrificing the services of the CLR. It is now time to turn our attention to exactly how the CLR supports those services and when (and why) one may need to bypass those services.
The CLR is based on a simple premise-that is, that the CLR is omniscient and omnipotent. The CLR needs the ability to know everything about a running program. This is one more reason why metadata is so important, because metadata is the key to the CLR's understanding the relationships between objects and values in memory. Moreover, the CLR needs the ability to manage and control all aspects of a running program. This is where managed execution comes into play.
The CLR supports two modes of execution: managed and unmanaged mode. In managed execution mode, the CLR is capable of interrogating every stack frame of every thread. This capability includes being able to inspect local variables and parameters. This capability includes being able to find the code and metadata for each stack frame's method. This capability includes being able to detect which object references on the stack are 'live' and which are no longer needed, as well as to adjust the live object references after heap compaction. In short, managed execution mode makes your program completely transparent to the CLR.
In contrast, unmanaged execution mode renders the CLR blind and powerless. When running in unmanaged execution mode, the CLR cannot glean any meaningful information from the call stack, nor can it do much to the executing code other than simply suspend the running thread altogether. As far as the CLR is concerned, unmanaged code is an opaque black box that the CLR respectfully must ignore.
One alters the mode of execution based on method invocation. One can mark each method for which the CLR has metadata as managed or unmanaged. The VB.NET and C# compilers can emit only managed methods. The C++ compiler emits managed methods by default when one uses the /CLR switch. However, the C++ compiler also supports emitting unmanaged methods. The compiler automatically emits unmanaged methods when a method body contains either inline IA-32 assembler or setjmp/longjmp calls, both of which make managed execution impractical. You can explicitly control the mode of a method using the #pragma managed and #pragma unmanaged directives in your source code.
The CLR is blind to unmanaged methods, so methods that are unmanaged may not use CLR object references because the CLR garbage collector cannot detect their existence nor adjust them during heap compaction. That means that the following C++ code will not compile:
void f()To get this program to work, one would need to separate the two regions of code into separate methods whose mode would reflect the needs of the code.
#pragma managedNote that the use of #pragmas is optional because the C++ compiler will set the mode based on whether or not the method body uses __asm or setjmp/longjmp.
There is no fundamental difference between the method body of a managed method and that of an unmanaged method. The methods' prologs and epilogs will look the same, as will the actual native code that will execute. What distinguishes managed from unmanaged methods is that the CLR can infer everything it needs to know about a stack frame for a managed method. In contrast, the CLR cannot infer much at all about a stack frame for an unmanaged method. It is important to note that the ability to infer rich information about a managed stack frame does not require additional instructions during method invocation. Rather, a call from one managed method to another managed method is indistinguishable from a classic C function call. However, because the CLR controls the method prologs and epilogs for managed methods, the CLR can reliably traverse the managed regions of the call stack, often (but not always) using the IA-32 ebp register used by most debuggers. Because the CLR needs this stack inspection only during relatively rare occurrences such as security demands, garbage collection, and exception handling, the common-case code path for managed code looks indistinguishable from the code generated by the classic C compiler.
As just described, homogeneous, same-mode invocation is indistinguishable from normal C-style function invocation. In contrast, cross-mode, heterogeneous invocation is not so simple. Cross-mode invocation happens when a managed method calls an unmanaged method or when an unmanaged method calls a managed method. In either case, the emitted code for the call looks considerably different from that of a normal same-mode call.
Cross-mode invocations need to perform extra work to signal the change of execution semantics. For one thing, the caller needs to push a sentinel on the stack marking the beginning of a new chain of stack frames. The CLR partitions the stack frame into chains. Each chain represents a series of same-mode method invocations. When the JIT compiler compiles a cross-mode call, it emits additional code that pushes an extra transition frame on the stack as a sentinel. As shown in Figure 10.2, each transition frame contains a back-pointer to the transition frame that began the previous chain. These transition frames allow the CLR to efficiently skip regions of the stack it doesn't care about-namely, the frames in unmanaged chains. After the transition frame is pushed on the stack, the caller then forms the normal stack frame that is expected by the target method. Note that this technique results in two stack frames for a cross-mode method call, one for each mode.
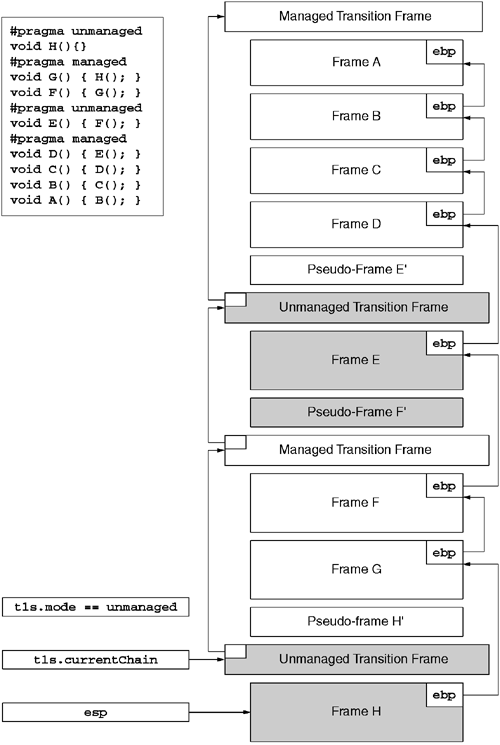
After the transition thunk prepares the stack for the cross-mode target method, the thunk must then adjust the execution state of the current thread to reflect the change in execution mode. Part of this preparation involves caching a pointer to the newly formed transition frame in thread local storage. Additionally, the transition thunk must toggle the bit in thread local storage that indicates which execution mode the thread is currently executing in. When this bit is set, the thread is running in managed execution mode. When the bit is clear, the thread is running in unmanaged execution mode. After the transition thunk has prepared the thread state, the thunk then jumps to the target method body. When the target method returns, it returns to additional transition code that resets the thread state and pops the transition frame from the stack. For calls with simple method signatures, the overall cost of making the transition is about 32 IA-32 instructions. Because making a cross-mode call requires setting up a second stack frame after the transition frame, the cost of cross-mode calls is dependent on the number and type of parameters passed to the method. The greater the number of parameters, the greater the cost of making the transition.
The discussion of unmanaged methods in the previous section assumed that the methods resided in an otherwise managed module and assembly. The CLR also supports calling code in unmanaged modules to allow the use of legacy C DLLs and API functions. One exposes this capability via a technology called P/Invoke.
P/Invoke is a superset of the managed and unmanaged transitions just described. P/Invoke provides a rich set of type conversion facilities to deal with the inherent differences between legacy C DLLs and the CLR. In addition to implementing the execution mode switch just described, P/Invoke performs a security permission demand to ensure that the security of the system is not compromised. Like the ability to execute nonverifiable code, the ability to call classic C DLLs is considered a highly privileged operation. To that end, the P/Invoke engine will demand the UnmanagedCode permission. Components that make any use of P/Invoke must be explicitly granted this permission. Moreover, components that make extensive use of P/Invoke should call IStackWalk.Assert prior to calling P/Invoke routines. This needs to be done not only to improve performance but also to guarantee that the P/Invoke call will succeed no matter what code path caused the current method to be called. An even better optimization would be to add the System.Security.SuppressUnmanagedCodeSecurity attribute to the type or method in question. The presence of this attribute suppresses the CLR's security demand altogether (provided that the assembly in fact has the UnmanagedCode permission). However, one should use this attribute with caution because it is a fairly coarse-grained solution, and careless use could weaken the overall security of the system.
Using P/Invoke is rather simple. P/Invoke allows one to mark methods as imported from a classic pre-CLR DLL. P/Invoke requires C functions exported from unmanaged modules to be redeclared in a managed module using special metadata directives. These directives indicate the file name of the DLL as well as the symbolic name of the entry point in the DLL. The P/Invoke engine then uses these two strings to call LoadLibrary and GetProcAddress, respectively, just prior to invoking the annotated method.
One can prepare methods for use with P/Invoke by using the language-neutral System.Runtime.InteropServices.DllImport pseudo-custom attribute. One must mark methods that use the DllImport attribute as extern and declare them with a method signature that matches the target function in the external DLL. Ultimately, every P/Invoke method has two signatures: the explicit one that is seen by managed code making the call, and the implicit one that is expected by the external DLL function. It is the job of the P/Invoke engine to infer the unmanaged signature based on default mapping rules and custom attributes.
The DllImport attribute takes a variety of parameters that customize how the external method and signature are to be imported and resolved. As shown in Table 10.1, the DllImport attribute requires that one provide at least a file name. The runtime uses this file name to call LoadLibrary prior to dispatching the method call. The string to use for GetProcAddress will be the symbolic name of the method unless the EntryPoint parameter is passed to DllImport. The following C# fragment shows two ways to call the Sleep method in kernel32.dll.
using System.Runtime.InteropServices;The first example relies on a match between the name of the C# function and the name of the symbol in the DLL. The second example relies on the EntryPoint attribute parameter instead.
Independent of how the entry point name is specified, one has to deal with the variety of name mangling schemes used to indicate calling convention and character sets. Unless one sets the ExactSpelling parameter to true, the P/Invoke engine will use several heuristics to find a matching entry point in the external DLL. When a P/Invoke method that uses strings is called, the entry point name will automatically have a W or A suffix appended if needed, depending on whether the underlying platform is Unicode or ANSI-based. If the entry point still cannot be found, the runtime will mangle the name using the stdcall conventions (e.g., Sleep becomes _Sleep@4).
Table 10.1. DllImport Attribute Parameters |
|||
|
Parameter Name |
Type |
Description |
Default |
|
Value |
System.String |
Path for LoadLibrary |
<mandatory> |
|
EntryPoint |
System.String |
Symbol for GetProcAddress |
<methodname> |
|
Calling Convention |
Calling Convention |
Stack cleanup/order |
Winapi |
|
CharSet |
CharSet |
WCHAR/CHAR/TCHAR |
Ansi |
|
ExactSpelling |
System.Boolean |
Don't look for name with A/W/@ |
false |
|
PreserveSig |
System.Boolean |
Don't treat as [out,retval] |
true |
|
SetLastError |
System.Boolean |
GetLastError valid for call |
false |
The P/Invoke engine has special facilities for dealing with errors raised by external DLLs. Because the P/Invoke engine itself makes system calls, it is possible that the error code returned by GetLastError may not be accurate. To preserve this error code, P/Invoke methods that map to functions that call SetLastError must be marked SetLastError=true. To recover the error code after making the P/Invoke call, managed code should use the System.Runtime.InteropServices.Marshal.GetLastWin32Error method. Consider the following C# program, which calls CloseHandle via P/Invoke:
using System;Note the use of SetLastError=true in the DllImport attribute. In this example, the program will print the following message:
Error: 6This message corresponds to the Win32 error code ERROR_INVALID_HANDLE. Had the SetLastError=true parameter not been set, the program would have printed the following:
Error: 126This message corresponds to the Win32 error code ERROR_MOD_NOT_FOUND. Unless one marks the method SetLastError=true, the P/Invoke engine will not preserve the value set by the CloseHandle function (ERROR_INVALID_HANDLE).
Another popular error-reporting technique from the past was to use numeric HRESULTs. P/Invoke supports two options for dealing with functions that return HRESULTs. By default, P/Invoke treats the HRESULT as a 32-bit integer that is returned from the function, requiring the programmer to manually test for failure. A more convenient way to call such a function is to pass the PreserveSig=false parameter to the DllImport attribute. This tells the P/Invoke layer to treat that 32-bit integer as a COM HRESULT and to throw a COMException in the face of a failed result.
To understand the PreserveSig option, consider a legacy C DLL that exposes the following function (shown in pseudo-IDL):
HRESULT __stdcall CoSomeAPI([in] long a1,One could import this function either with or without PreserveSig. The following import uses PreserveSig=true, which is the default for P/Invoke:
// returns HRESULT as function resultWith this declaration, the caller must manually check the result of the method for failure. In contrast, the following import suppresses PreserveSig:
// throws COMException on failed HRESULTThis code informs the P/Invoke engine to automatically check the HRESULT and map failed calls to exceptions of type COMException. Note that in the case of OLE32Wrapper.CoSomeAPI2, the method returns a short that corresponds to the underlying function's final [out,retval] parameter. Had the P/Invoke method been declared to return void, then the P/Invoke layer would have assumed that the specified parameter list matches the underlying native definition exactly. This mapping takes place only when the PreserveSig parameter is false.
As mentioned previously, each P/Invoke method has two method signatures: a managed signature and one that is expected by the external DLL. This is illustrated in Figure 10.3. Depending on the type of parameter, the P/Invoke engine may (or may not) need to perform an in-memory conversion. Types that can be copied without conversion are called blittable types. Types that require conversion are called nonblittable types. To risk stating the obvious, the performance of a P/Invoke call is considerably faster when one uses only blittable parameters because setting up the second stack frame typically requires only one IA-32 instruction per parameter. The same cannot be said when one uses nonblittable types.
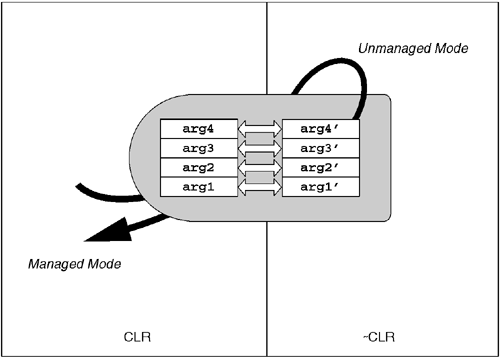
Table 10.2 shows a list of the basic blittable and nonblittable types as well as their default mappings in C/IDL. You are free to override these default mappings on a parameter-by-parameter (or field-by-field) basis using the System.Runtime.InteropServices.MarshalAs attribute. This attribute indicates which unmanaged type to use when marshaling a stack frame using P/Invoke. As shown in Table 10.3, the MarshalAs attribute requires one parameter of type UnmanagedType. The UnmanagedType is an enumerated type whose values correspond to the types the P/Invoke marshaler knows how to handle. By applying the MarshalAs attribute to a parameter of field, you are specifying which external type should be used by P/Invoke. One can use additional parameters to MarshalAs to tailor the handling of arrays, including support for COM-style [size_is] using the SizeParamIndex parameter. Additionally, one can extend the P/Invoke marshaler by specifying a custom marshaler using the MarshalType parameter. This custom marshaler must implement the ICustomMarshaler interface, which allows the marshaler to do low-level conversions between instances of managed types and raw memory.
To grasp how the MarshalAs attribute is used, consider the following P/Invoke method declaration:
[ DllImport('foobar.dll') ]This method declaration implies the following unmanaged C function declaration:
void _stdcall DoIt(LPCWSTR s1, LPCSTR s2,Note that the C function prototype uses const parameters. This is critically important given the semantics of System.String, which is that all instances of System.String are immutable. To that end, the CLR provides no mechanisms to change the contents of a System.String object. To understand how this impacts P/Invoke, consider the internal representation of a System.String. As shown in Figure 10.4, System.String is a reference type, so all strings are compatible with the CLR internal object format. Additionally, all strings are prefixed with both a capacity and a length field. In almost all cases, these two fields are the same. Finally, the string object ends with a null-terminated array of System.Char, which is a 16-bit Unicode character.
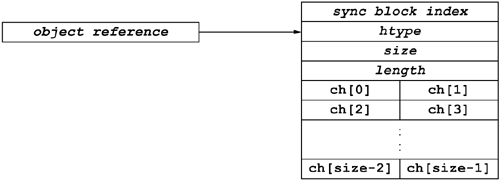
Table 10.2. Blittable and Nonblittable Types |
||
|
CLR Type |
IDL/C Type |
|
|
Blittable |
Single |
float |
|
Double |
double |
|
|
SByte |
signed char |
|
|
Byte |
unsigned char |
|
|
Int16 |
short |
|
|
Uint16 |
unsigned short |
|
|
Int32 |
long |
|
|
Uint32 |
unsigned long |
|
|
Int64 |
__int64 |
|
|
Uint64 |
unsigned __int64 |
|
|
IntPtr |
INT_PTR |
|
|
UIntPtr |
UINT_PTR |
|
|
Formatted type containing only blittable types |
Euivalent C-style struct |
|
|
One-dimensional array of blittable type |
Equivalent C-style array |
|
|
Nonblittable |
All other arrays |
SAFEARRAY or C-style array |
|
Char |
wchar_t (blittable) or char |
|
|
String |
LPCWSTR(blittable) or LPCSTR or BSTR |
|
|
Boolean |
VARIANT_BOOL or BOOL |
|
|
Object |
VARIANT |
|
Table 10.3. MarshalAs Attribute Parameters |
||
|
Parameter Name |
Type |
Description |
|
Value |
Unmanaged Type |
Unmanaged type to marshal to (mandatory) |
|
ArraySubType |
Unmanaged Type |
Unmanaged type of array elements |
|
SafeArraySubType |
VarType |
Unmanaged VARTYPE of safearray elements |
|
SizeConst |
int |
Fixed size of unmanaged array |
|
SizeParamIndex |
short |
0-based index of [size_is] parameter |
|
MarshalType |
String |
Fully qualified type name of custom marshaler |
|
MarshalCookie |
String |
Cookie for custom marshaler |
Because the CLR does not allocate System.String objects using the SysAllocString API call, they are not valid BSTRs, and passing a string as a BSTR causes the P/Invoke engine to create a copy of the string. Similarly, because a System.String object contains Unicode characters, strings are considered nonblittable when passed as an ANSI string. These temporary copies of the string live only for the duration of the call, and the CLR will not propagate any changes back to the original string object. However, if one passes the string as a Unicode string (UnmanagedType.LPWStr), the P/Invoke engine actually passes a pointer to the beginning of the string's character array. This means that for the duration of the call, the external DLL has a raw pointer to the string's actual buffer. Because CLR strings are immutable, any changes made by the external DLL to the string will result in random and unpredictable errors. To avoid this, one should declare the external DLL's parameter as const wchar_t*. If one needs to pass a string to an external DLL for modification, one should instead use the System.Text.StringBuilder type. For example, consider the following Win32 API function:
BOOL __stdcall GetModuleFileName(HMODULE hmod,This function would require a P/Invoke prototype that looks like this:
[DllImport('kernel32.dll',To use this function, one would need to preallocate a string buffer using the StringBuilder class as follows:
static string GetTheName(IntPtr hmod)Note that the StringBuilder object keeps a private string object to use as the underlying character buffer. Calling ToString returns a reference to this private string object. Any future use of the StringBuilder object will trigger a new copy of the string, and it is this copy that the StringBuilder object modifies in subsequent operations. This technique avoids further corruption of the last string returned from the ToString method.
The DllImport attribute allows one to specify the default string format on a method-wide basis, eliminating the need for the MarshalAs attribute on each parameter. One can set the Unicode/ANSI policy for a method using the CharSet parameter. The CharSet parameter to DllImport allows you to specify whether Unicode (CharSet.Unicode) or ANSI (CharSet.Ansi) should be used. This is equivalent to manually marking each string parameter with a MarshalAs(UnamanagedType.LPWStr) or MarshalAs(UnamanagedType.LPStr) attribute, respectively.
The DllImport attribute supports a third setting, CharSet.Auto, which indicates that the underlying platform (Windows NT/2000/XP versus Windows 9x/ME) should dictate the external format of string parameters. Using CharSet.Auto is similar to writing Win32/C code using the TCHAR data type, except that the CLR determines the actual character type and API at load time, not compile time, allowing a single binary to work properly and efficiently on all versions of Windows.
When one passes object references other than System.String or System.Object, the default marshaling behavior is to convert between CLR object references and COM object references. As shown in Figure 10.5, when one marshals a reference to a CLR object across the P/Invoke boundary, the CLR creates a COM-callable wrapper (CCW) to act as a proxy to the CLR object. Likewise, when one marshals in a reference to a COM object through the P/Invoke boundary, the CLR creates a runtime-callable wrapper (RCW) to act as a proxy to the COM object. In both cases, the proxy will implement all of the interfaces of the underlying object. Additionally, the proxy will try to map COM and CLR idioms such as IDispatch, object persistence, and events to the corresponding construct in the other technology.
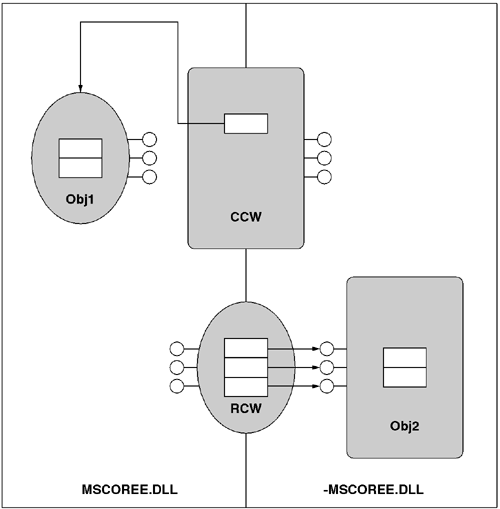
It is important to note that the presence of CCWs or RCWs (or both) can wreak havoc on the lifecycle management of the CLR and of COM. For example, the RCW holds AddRefed interface pointers to the underlying COM object. The CLR does not release these interface pointers until the RCW is finalized. Moreover, the CCW holds a rooted reference to the underlying CLR object, and that prevents the object from being garbage-collected as long as there is at least one outstanding COM interface pointer. This means that if cycles in an object graph contain CCWs or RCWs, one needs some mechanism to break the cycle. You can preemptively release an RCW's interface pointer by calling the Marshal.ReleaseComObject static method. You can also convert the rooted reference inside a CCW to a weak reference by calling Marshal.ChangeWrapperHandleStrength.
Like any other call to or from unmanaged code, a call to an RCW or a CCW triggers a mode transition. However, as was the case with P/Invoke, calls to an RCW also force a security demand because calling to unmanaged DLLs is a privileged operation. When one calls an RCW, the type conversion rules used for method parameters differ slightly from those used in P/Invoke calls. In particular, strings default to BSTRs, Booleans default to VARIANT_BOOL, and PreserveSig is assumed to be false, not true. To suppress the automatic translation of HRESULTs to exceptions, one must apply the System.Runtime.InteropServices.PreserveSig attribute to the interface method of interest.
For interfaces that straddle the P/Invoke boundary via RCWs or CCWs, the CLR relies on a set of annotations to the managed interface definition to give the underlying marshaling layer hints as to how to translate the types. These hints are a superset of those just described for P/Invoke. Additional aspects that need to be defined include UUIDs, vtable versus dispatch versus dual mappings, how IDispatch should be handled, and how arrays are translated. One adds these aspects to the managed interface definition using attributes from the System.Runtime.InteropServices namespace. In the absence of these attributes, the CLR makes conservative guesses as to what the default settings for a given interface and method should be. For new managed interfaces that are defined from scratch, it is useful to use the attributes explicitly if you intend your interfaces to be used outside of the CLR.
One can translate native COM type definitions (e.g., structs, interfaces, etc.) to the CLR by hand, and, in some cases, this is necessary, especially when no accurate TLB is available. Translating type definitions in the other direction is simpler given the ubiquity of reflection in the CLR, but, as always, one is better off using a tool rather than resorting to hand translations. The CLR ships with code that does a reasonable job of doing this translation for you provided that COM TLBs are accurate enough. System.Runtime.InteropServices.TypeLibConverter can translate between TLBs and CLR assemblies. The ConvertAssemblyToTypeLib method reads a CLR assembly and emits a TLB containing the corresponding COM type definitions. Any hints to this translation process (e.g., MarshalAs) must appear as custom attributes on the interfaces, methods, fields, and parameters in the source types. The ConvertTypeLibToAssembly method reads a COM TLB and emits a CLR assembly containing the corresponding CLR type definitions. The SDK ships with two tools (TLBEXP.EXE and TLBIMP.EXE) that wrap these two calls behind a command-line interface suitable for use with NMAKE. Figure 10.6 shows the relationship between these two tools.
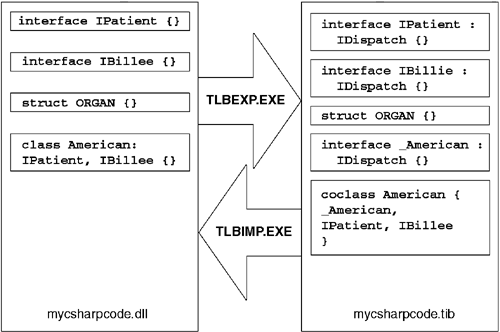
In general, it is easier to define types first in a CLR-based language and then emit the TLB. For example, consider the C# code shown in Listing 10.1. If we were to treat this code as a 'pseudo-IDL' file, we could run it through CSC.EXE and TLBEXP.EXE to produce a TLB that is functionally identical to the one produced by the 'real' IDL file shown in Listing 10.2. The advantage to using the C# approach is that the type definitions are extensible and readily machine-readable, neither of which could be said for the TLB or IDL file.
In an ideal world, there would be only one definition of a given type. Unfortunately, the realities of the COM installed base require two definitions to exist: one in CLR metadata and one in a COM TLB. If the COM TLB is the 'authoritative' version of the type, there is a risk that multiple developers will import the TLB. Unfortunately, each of these imported assemblies will be different to the CLR, and this means that object references to COM components cannot be shared among multiple CLR-based components. This is especially problematic for shared COM components such as ActiveX Data Objects (ADO) because passing ADO recordsets as parameters was one of the defining acts of a VB programmer in the 1990s. To ensure that only one imported CLR assembly is used for each type library, the CLR supports the notion of a primary interop assembly.
One registers a primary interop assembly in the COM registry as the authoritative version of the TLB. When loading the CLR type for a type in a COM TLB, the CLR will defer to the type definition in the primary interop assembly. This ensures that only one version of a given COM type exists in memory at once. One sets the primary interop assembly using the /primary command-line switch to TLBIMP.EXE. When an administrator or user registers the resultant assembly using REGASM.EXE, REGASM.EXE will place additional registry entries under HKEY_CLASSES_ROOTTypeLib that indicate that the imported assembly is the primary interop assembly for the COM TLB. To maintain consistency, all type libraries referenced by a primary interop assembly's TLB must also have primary interop assemblies. When the CLR is installed, REGASM.EXE creates a primary interop assembly for STDOLE.TLB, which is referenced by all TLBs.
The discussion of P/Invoke illustrated how one can access the classic Win32 loader transparently from CLR-based programs. The discussion of P/Invoke neglected to discuss another classic loader that dominated the 1990s-that is, COM's CoCreateInstance.
The COM loader translated location-neutral type names in the form of CLSIDs into DLLs that exposed the DllGetClassObject entry point. One exposed this functionality via a variety of API functions; however, the most popular was easily CoCreateInstance. Although it is completely legal to call CoCreateInstance via P/Invoke, most CLR-based programs will elect to use the System.Runtime.InteropServices.ComImport attribute.
The CLR treats CLR-based classes specially that are marked with the ComImport attribute. In particular, when a newobj CIL instruction is performed on a type marked ComImport, the CLR will read the type's globally unique identifier (GUID) from the metadata and will translate the newobj request into a call to CoCreateInstance. Types that use ComImport invariably use the System.Runtime.InteropServices.Guid attribute to explicitly control the type's GUID.
The following program uses ComImport to map a CLR-based type named Excel to the COM class for Microsoft Excel.
using System;Note that the CLR's TLB importer will automatically generate ComImport types for each coclass in the TLB.
COM programmers often used monikers to place a level of indirection between the client and the target class and object. Programmers usually accessed this capability via COM's CoGetObject or VB's GetObject function. CLR-based programs can access this same functionality using the Marshal.BindtoMoniker static method.
Getting the CLR to call LoadLibrary or CoCreateInstance is fairly trivial and extremely straightforward. Going in the other direction-that is, allowing CLR-based code to be loaded from legacy code-is considerably more interesting.
Ultimately, the CLR is implemented as a family of Win32/COM-based DLLs. Although one can load these DLLs directly using LoadLibrary or CoCreateInstance, these are not the preferred techniques to use when one is loading the CLR into a new process. Instead, unmanaged programs are encouraged to use the CLR's explicit facilities for loading and hosting the runtime. The CLR exposes these facilities via a DLL called MSCOREE.DLL.
MSCOREE.DLL is sometimes called the 'shim' because it is simply a facade in front of the actual DLLs that the CLR comprises. As shown in Figure 10.7, MSCOREE.DLL sits in front of one of two DLLs: MSCORWKS.DLL and MSCORSVR.DLL. The MSCORWKS.DLL DLL is the uniprocessor build of the CLR; MSCORSVR.DLL is the multiprocessor build of the CLR. The primary difference between the two builds is that the multiprocessor build uses one heap per CPU per process to reduce contention; the uniprocessor build has one heap per process. It is the job of MSCOREE.DLL to select the appropriate build based on any number of factors, including (but not limited to) the underlying hardware.
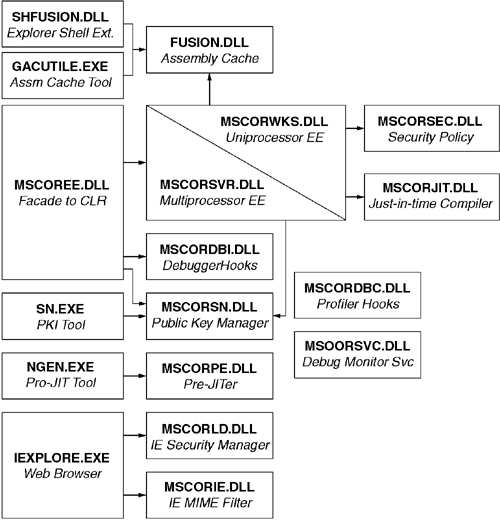
Of all the DLLs shown in Figure 10.7, only MSCOREE.DLL can be found in the %SYSTEM_ROOT% directory. To support side-by-side installation of multiple versions of the CLR, Microsoft has placed all other DLLs in a version-specific subdirectory. The CLR determines which version is selected based on a number of configuration options. The Everett release of the CLR (tentatively to be called the.NET framework Version 1.1) will be the first version of the CLR to actually support side-by-side versions of the CLR itself.
Several aspects of the CLR use a well-known registry key for global configuration information. The machine-wide settings are stored under HKEY_LOCAL_MACHINESoftwareMicrosoft.NETFramework. Per-user settings are stored under HKEY_CURRENT_USERSoftwareMicrosoft.NETFramework. Additionally, one can override many of the settings stored in the registry by setting OS-level environment variables. For example, one specifies the default version of the runtime using the Version named value. That means that the following.REG file would set the default CLR version number to 'v1.0.3215' for all users:
[HKEY_LOCAL_MACHINESoftwareMicrosoft.NETFramework]In contrast, the following CMD.EXE command would set the default version to 'v1.0.3500' for all subsequent programs run from a particular command shell:
set COMPlus_Version=v1.0.3500Note that one must prefix the name of the registry value with COMPlus_ when one is using it as an environment variable. One uses this convention for most registry settings used by the CLR.
When trying to determine the name and location of the DLL that implements the CLR, MSCOREE.DLL looks at both the Version setting and the InstallRoot setting. The latter points to the base directory in which the various versions of the CLR are installed. For example, on the author's machine, the default settings are as follows:
[HKEY_LOCAL_MACHINESoftwareMicrosoft.NETFramework]When looking for the CLR DLLs, MSCOREE.DLL simply catenates the two values and looks in the C:windowsMicrosoft.NETFrameworkv1.0.3705 directory. You can programmatically construct this path by calling the System.Runtime.InteropServices.RuntimeEnvironment.GetRuntimeDirectory static method. Similarly, you can fetch the Version property used to load the runtime by calling the System.Runtime.InteropServices.RuntimeEnvironment.GetSystemVersion static method.
To determine the actual file name of the CLR DLL, MSCOREE.DLL looks for one more configuration property. If the BuildFlavor property is present in either the registry or the process environment variable, MSCOREE.DLL will take that string as the suffix of the file name and catenate it with MSCOR, producing either MSCORWKS or MSCORSVR. Note, however, that MSCOREE.DLL will never load MSCORSVR.DLL on a uniprocessor machine.
MSCOREE.DLL also supports the silent loading of newer versions of the CLR that are known to be compatible. The.NETFramework registry key contains a policy subkey that indicates which range of build numbers a given version of the CLR is compatible with. When loading the CLR, MSCOREE.DLL will consult this subkey and silently promote the requested version number if possible.
The Version setting just described is installation-specific. It is also possible to use configuration files to control which version of the runtime is loaded. If an application's config file contains a <startup> element, the version number found there overrides the version specified in the registry or in environment variables. Consider the following configuration file:
<?xml version='1.0' encoding='utf-8' ?>This file indicates that version v1.0.2605 should be used. The safemode='false' attribute indicates that it is acceptable to apply version policy to select a higher (or lower) version number. To suppress this version policy mapping, one should set the safemode attribute to true. In this mode, the exact version of the CLR must be available; otherwise, MSCOREE.DLL will fail to load the runtime.
It is important to note that even though the CLR supports side-by-side installation of multiple versions of the CLR, one can use only one version within a single OS process. In fact, after the CLR has been loaded into a process, that process can use no other versions even after the original instance of the CLR is completely torn down. To support side-by-side execution of multiple CLR versions, one must use multiple OS processes, one per CLR version.
One additional process-wide setting that needs to be discussed is whether or not the concurrent garbage collector will be used. By default, the garbage collector always runs on the thread that triggered the collection. In contrast, the concurrent garbage collector will avoid this situation by allowing garbage collection to occur on other threads as well. The concurrent collector is suited to interactive applications in which the latency of running the garbage collector on the primary thread of the application is unacceptable. One specifies the use of the concurrent collector using the following configuration file entry:
The absence of this element (or setting the enabled attribute to false) will cause the CLR to use the normal garbage collector.
The discussion so far has focused on how MSCOREE.DLL determines which CLR DLL to load. What has yet to be discussed is how to instruct MSCOREE.DLL to perform this feat.
One can use MSCOREE.DLL in any number of ways. Managed executables implicitly reference it in their PE/COFF headers. In particular, a managed.EXE will forward its Win32-level main entry point to MSCOREE.DLL's _CorExeMain. After loading the CLR, _CorExeMain simply traverses the program's metadata and executes the program's CLR-level main entry point. Similarly, DLLs forward their Win32-level main entry point to _CorDllMain. In either case, MSCOREE.DLL will change execution modes from unmanaged to managed prior to executing the main entry point of the target executable.
For COM compatibility, MSCOREE.DLL also exports a DllGetClassObject. When MSCOREE.DLL is registered as an InprocServer32, MSCOREE.DLL expects to find additional registry entries that indicate the assembly and type name of the corresponding COM class. The REGASM.EXE tool writes these automatically. For example, consider the following C# class:
using System.Runtime.InteropServices;This class would cause REGASM.EXE to generate the following registry entries:
[HKEY_CLASSES_ROOTCLSID ]Notice that the Class and Assembly specify the fully qualified type name of the target class. Also note that the CodeBase entry provides the necessary codebase hint used by the assembly resolver. This codebase hint is critical because the COM client will not have a configuration file of its own. This codebase hint will be inserted into the registry only if the call to REGASM.EXE specifies the /codebase command-line option.
It is also possible to register a CLR-based type with the COM+ 1.x catalog manager. CLR-based types that wish to be configured with COM+ must directly or indirectly extend the System.EnterpriseServices.ServicedComponent base type. This base type ensures that the CLR-based object will have a COM+ 1.x context associated with it. For version 1 of the CLR, COM+ 1.x services are still implemented in unmanaged COM code. The use of ServicedComponent acts as a signal to the CLR to ensure that both a CLR and a COM+ 1.x context are available for the new object. When the CLR creates an instance of a serviced component, it ensures that there are proper COM+ 1.x catalog entries for the class. To that end, most of the COM+ 1.x catalog attributes are available as custom metadata attributes to allow developers to specify their COM+ 1.x service requirements at development time.
Finally, to avoid the need to use COM interop, the CLR makes available the facilities of CoGetObjectContext via the System.EnterpriseServices.ContextUtil type. At the time of this writing, the lone compelling feature of COM+ 1.x that would warrant the use of this plumbing is to ease the use of the distributed transaction coordinator (DTC). Applications that do not need DTC probably do not need COM+ 1.x either. See Tim Ewald's book Transactional COM+ (Addison-Wesley, 2001) on why this is so.
The uses of MSCOREE.DLL just described all take advantage of the CLR implicitly. It is also possible to use the CLR explicitly from unmanaged programs. When you use the CLR explicitly, your unmanaged program has considerably more control over how the CLR is configured within the process. To facilitate this, the CLR exposes a family of COM-based hosting interfaces that can be accessed from any COM-compatible environment. The most critical of these interfaces is ICorRuntimeHost.
ICorRuntimeHost is the primary hosting interface of the CLR. This interface allows programs to manage the AppDomains of the CLR as well as control how OS threads and fibers interact with the CLR. The simplest way to acquire an ICorRuntimeHost interface is to call CoCreateInstance on the CorRuntimeHost coclass. Consider the following VBA 6.0 code:
Private Sub Form_Load()Assuming that this code is in a project that references both MSCOREE.TLB and MSCORLIB.TLB, the new statement will cause MSCOREE.DLL to be loaded into the process. Note that there is an explicit Start method that one must call prior to using the CLR. This two-phase initialization allows the container to configure the default AppDomain's loader properties using an AppDomainSetup object. After the Start method has been called, the default domain of the process will have been initialized and made available via the GetDefaultDomain method. After the default domain is available, programming the CLR from the host application is extremely similar to programming the CLR from within. The primary difference is that the host application is unmanaged code, so the reference returned by GetDefaultDomain is a CCW to the underlying CLR-based object.
Using CoCreateInstance to load the CLR has two pitfalls. For one thing, you cannot explicitly control the version of the CLR that will be loaded. Rather, the CLR will use the Version property as described earlier. Moreover, using CoCreateInstance requires that you initialize COM in process. There are actually processes that do not use OLE32.DLL. To allow the CLR to be hosted in these processes, MSCOREE.DLL exposes a set of API functions that load the correct runtime without resorting to COM. The most flexible of these API calls is CorBindToRuntimeHost.
CorBindToRuntimeHost allows the caller to specify several parameters that control which build of the CLR is loaded as well as how it will be initialized. Here is the signature for CorBindToRuntimeHost:
HRESULTThe first parameter overrides the Version property that may appear in the registry or an environment variable. The second parameter indicates whether the uniprocessor or multiprocessor build is desired. However, be aware that MSCOREE.DLL will ignore requests for svr when running on a uniprocessor machine. The third parameter is the file name of the application configuration file. This allows the host application to use whatever name it chooses for the configuration file. Finally, the fifth parameter is a bitmask taken from the following enumeration:
typedef enum STARTUP_FLAGS;The loader optimization flags correspond to the System.LoaderOptimization enumeration described in Chapter 8. The STARTUP_LOADER_SAFEMODE flag serves the same function as the safemode configuration file attribute and suppresses the default version policy applied by MSCOREE.DLL. Finally, the STARTUP_CONCURRENT_GC flag informs the CLR to use the concurrent garbage collector a la the gcConcurrent configuration file element. Finally, the last three parameters of CorBindToRuntimeHost match those found in a CoCreateInstance call and indicate which coclass and interface to use.
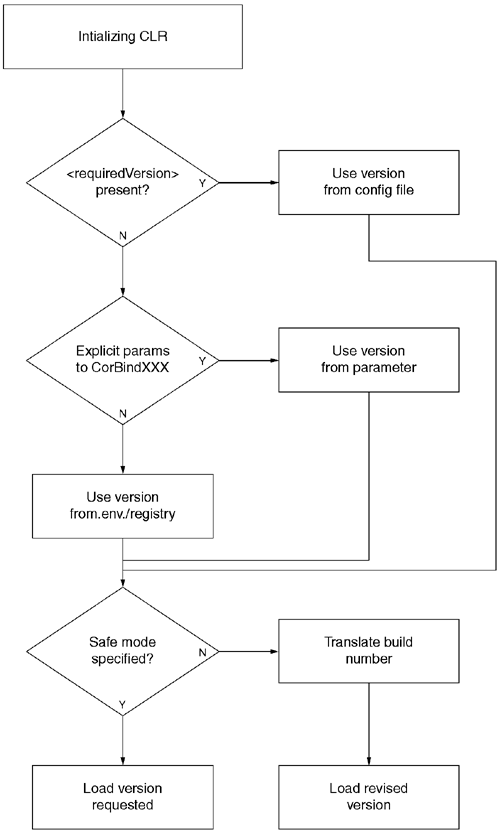
The presence of a configuration file influences the parameters to CorBindToRuntimeHost. In particular, the settings in the configuration file will take precedence over any parameters passed to CorBindToRuntimeHost. This is reflected in the overall version policy used to load the CLR, which is shown in Figure 10.8.
MSCOREE.DLL exports several variations on CorBindToRuntimeHost that accept fewer parameters. However, there are two functions that MSCOREE.DLL exports that bear further scrutiny: CorBindToCurrentRuntime and ClrCreateManagedInstance. The former function allows unmanaged code to access the ICorRuntimeHost reference to the runtime that is already initialized in the process. The latter function takes a fully qualified CLR type name and wraps the underlying calls to CorBindToRuntimeHost, ICorRuntimeHost.GetDefaultDomain, and AppDomain.CreateInstance.
The object returned by CorBindToRuntimeHost provides additional functionality beyond what has already been discussed. In particular, it gives host applications fairly fine-grained control over how the garbage collector and threads are managed. Figure 10.9 shows the overall object model. Be aware that none of these interfaces is documented; however, one can easily infer their usage through experimentation. The ICorThreadpool interface allows unmanaged code to access the CLR's process-wide thread pool. The methods of ICorThreadpool mirror those of its managed counterpart, System.Threading.ThreadPool. The IGCHost interface allows one to set various thresholds for the garbage collector's heap manager as well as allows one to examine heap usage information. The IValidator interface exposes the PE/COFF validation functionality of the CLR to allow arbitrary tools (such as peverify.exe) to verify CLR-based modules. The IMetaDataConverter interface exposes the TLB-to-CLR metadata conversion facilities to tools such as TLBEXP.EXE.
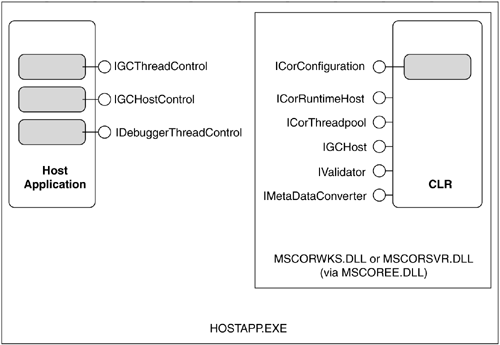
The CLR also allows the host application to register several callback interfaces to gain better control over how the garbage collector and thread manager work. The IGCThreadControl interface allows the CLR to notify the host application when the garbage collector is suspending or resuming execution of a given thread. The IGCHostControl interface allows the host application to control how fast and how far the garbage collector can allocate virtual memory for its heap. Finally, the IDebuggerThreadControl interface allows the CLR to notify the host when the CLR debugger is about to suspend execution of a given thread.
Independent of the hosting interfaces just described, the CLR provides a family of unmanaged COM interfaces that allow instrumentation, inspection, and intrusion into the CLR's execution engine. These interfaces are broken into two suites: one suite that is tailored to debuggers and another that is tailored to profilers. Between the two, however, one can expose virtually all aspects of the CLR to unmanaged code running just outside the CLR.
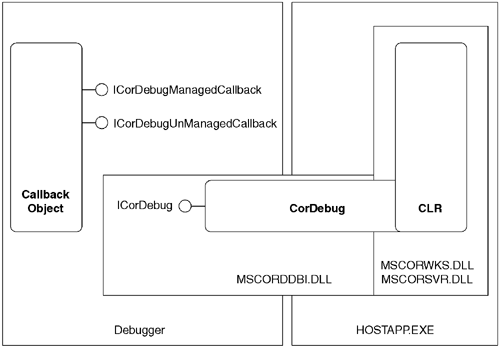
Figure 10.10 shows the CLR debugger object model. One can acquire the ICorDebug interface by calling CoCreateInstance on CLSID_CorDebug. This COM class is exposed by MSCORDBI.DLL and will hook up to the CLR running in any process. After being attached to a CLR instance, the debugger can register up to two callback interfaces. The CLR uses one of the interfaces, ICorDebugManagedCallback, to inform the debugger of relatively coarse-grained events that occur in the running program (e.g., loader activity, AppDomain creation and unloading) as well as debugger-specific events such as breakpoints encountered. The CLR uses the second event interface, ICorDebugManagedCallback, to signal classic Win32 debugger events. The CLR uses this interface only when the CLR debugger is also attached as the native Win32 debugger.
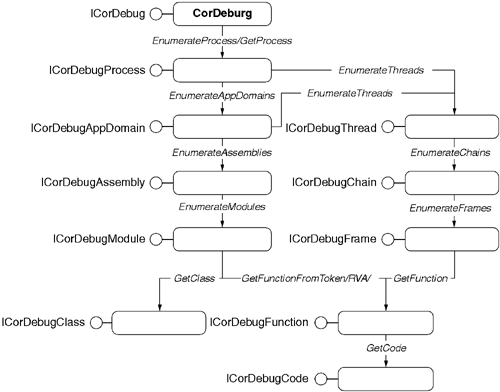
After your program attaches to a CLR as its debugger, the entire state of the running program is made available. Figure 10.11 shows the object model of the CLR as viewed through the lens of the debugging interfaces. This object model remains true to the conceptual model of the CLR but allows extremely fine-grained access to the execution state of a running program, down to the register level.
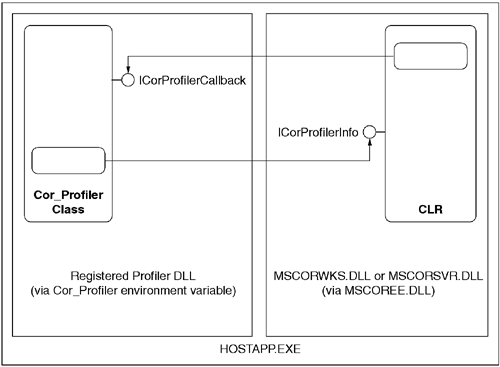
The events fired by the CLR debugging infrastructure are fairly coarse-grained. Programs that need finer granularity need to use the profiler interface suite. Upon initialization, the CLR looks for two configuration properties either in the registry or in process environment variables. One of the properties, Cor_Enable_Profiling, controls whether or not the CLR will load a profiler DLL to instrument the CLR. The second property, Cor_Profiler, indicates the COM CLSID of the profiler DLL to be loaded. As shown in Figure 10.12, this DLL must implement the ICorProfilerCallback interface. Upon initialization, the profiler DLL must provide a bitmask to indicate which event notifications it wishes to receive. Each possible event type has a distinct flag in this bitmask, allowing the profiling DLL to control how intrusive the instrumentation will be. Table 10.4 shows the family of profiler event notifications. Note that the finest-grained notification is MethodEnter and MethodLeave, allowing the profiling DLL to intercept literally every method call that occurs in the CLR.
It is difficult to talk about the profiling infrastructure without discussing method inlining. CLR modules carry a metadata attribute that controls how code will be generated. This metadata attribute is System.Diagnostics.DebuggableAttribute and is controlled via the /debug and /optimize command-line switches to your compiler. The attribute has two properties: IsJITTrackingEnabled and IsJITOptimizerDisabled.
IsJITTrackingEnabled informs the JIT compiler to emitper-instruction tables for the debugging infrastructure. This allows the debugger to do a better job of stepping through source code; however, it increases the in-memory size of the program. One sets this property to true using the /debug or the /debug+ compiler switch. The property defaults to false, but one can explicitly set it to false using the /debug- or the /debug:pdbonly switch. The latter of these two options generates symbolic debugging information despite causing the JIT compiler to emit slightly less accurate debugging information.
IsJITOptimizerDisabled informs the JIT compiler to suppress inline expansion of method bodies. This allows the profiler to get a more accurate picture of which method bodies are actually the hotspots of a program. However, disabling inlining increases the impact of method invocation cost, which, for small method bodies, can be the dominant cost of a method. The IsJITOptimizerDisabled property defaults to true, but one can set it to false using the /optimize or the /optimize+ compiler switch.
Finally, one can override the per-module settings just described using a per-application configuration file. This file uses the classic Windows INI syntax and must look like this:
[.NET Framework Debugging Control]
Table 10.4. Profiler Notifications |
||
|
MethodEnter |
MethodReturn |
MethodTailCall |
|
AppDomainCreation |
AssemblyLoad |
ModuleLoad |
|
AppDomainShutdown |
AssemblyUnload |
ModuleUnload |
|
ModuleAttachedToAssembly |
ClassLoad |
ClassUnload |
|
FunctionCompilation |
FunctionUnload |
JITCachedFunctionSearched |
|
JITInlining |
JITFunctionPitched |
COMClassicVTableCreated |
|
COMClassicVTable-Destroyed |
UnmanagedToManaged-Transition |
ManagedToUnmanaged-Transition |
|
ThreadCreated |
ThreadDestroyed |
ThreadAssignedToOSThread |
|
RuntimeSuspend |
RuntimeResume |
RuntimeThreadSusend |
|
RuntimeThreadResume |
MovedReferences |
OBjectsAllocated |
|
ObjectsAllocatedByClass |
ObjectReferences |
RootReferences |
|
ExceptionThrown |
ExceptionSearchFunction |
ExceptionSearchFilter |
|
ExceptionSearchCatcher |
ExceptionOSHandler |
ExceptionUnwindFunction |
|
ExceptionUnwindFinally |
ExceptionCatcher |
ExceptionCLRCatcher |
If the target executable is called application.exe, this file must have the name application.INI and reside in the same directory.
The CLR is ultimately just a family of Win32/COM DLLs that one can load into any Win32 process. The primary facade to the CLR is MSCOREE.DLL, which acts as a lightweight shim in front of the actual runtime, which is implemented (primarily) in MSCORWKS.DLL or MSCORSVR.DLL. After the CLR loads your program, it is encouraged to stay within the confines of the CLR's managed execution model; however, you are free to leave at any time simply by invoking an unmanaged method.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1965
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved