| CATEGORII DOCUMENTE |
| Bulgara | Ceha slovaca | Croata | Engleza | Estona | Finlandeza | Franceza |
| Germana | Italiana | Letona | Lituaniana | Maghiara | Olandeza | Poloneza |
| Sarba | Slovena | Spaniola | Suedeza | Turca | Ucraineana |
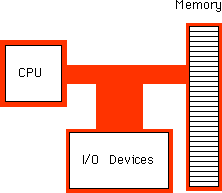
80x86 Processor Data Bus Sizes |
|
Processor |
Data Bus Size |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
80386sx |
|
80386dx |
|
|
|
|
80586 class/ Pentium (Pro) |
|
80x86 Family Address Bus Sizes |
|||
Processor |
Address Bus Size |
Max Addressable Memory |
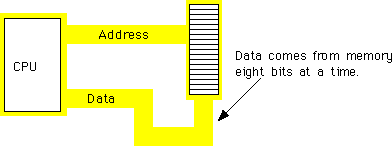
In English! |
|
|
|
|
One Megabyte |
|
|
|
|
One Megabyte |
|
|
|
|
One Megabyte |
|
|
|
|
One Megabyte |
|
|
|
|
Sixteen Megabytes |
80386sx |
|
|
Sixteen Megabytes |
80386dx |
|
|
Four Gigabytes |
|
|
|
|
Four Gigabytes |
80586 / Pentium (Pro) |
|
|
Four Gigabytes |
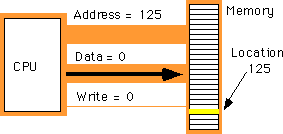
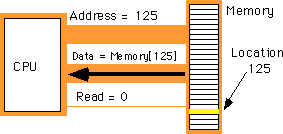
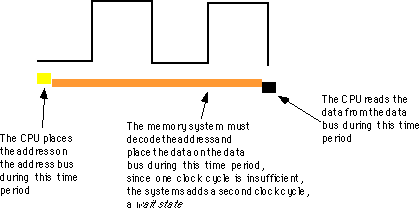
I:=I*5+2; before
I:=J; in the following sequence: J into I takes a
certain amount of time. Likewise, multiplying I by five
and then adding two and storing the result back into I takes
time. As you might expect, the second Pascal statement above takes quite a bit
longer to execute than the first. For those interested in writing fast
software, a natural question to ask is, 'How does the processor execute
statements, and how do we measure how long they take to execute?'


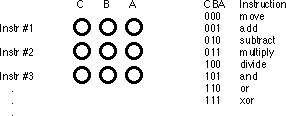
move
instruction is a command that moves data from one location in the computer to
another (e.g., from one register to another). Therefore, the move instruction
requires two operands: a source operand and a destination operand. The CPU's
designer usually encodes these source and destination operands as part of the
machine instruction, certain sockets correspond to the source operand and
certain sockets correspond to the destination operand. The figure below shows
one possible combination of sockets to handle this. The move
instruction would move data from the source register to the destination
register, the add instruction would add the value
of the source register to the destination register, etc.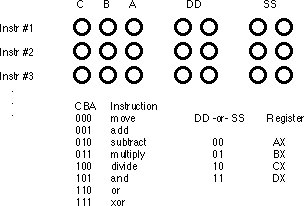
COP |
d |
MOD |
REG |
RM |
|
|
|
|
|
|
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1467
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved