| CATEGORII DOCUMENTE |
PROTOCOLUL DE CONTROL AL TRANSMISIEI (TCP)
Introducere
Acest capitol introduce al doilea important si extrem de cunoscut serviciu al nivelului retea, si anume distributia sigura de fluxului si acel protocol de control al transmisiei (TCP) care il defineste. Vom vedea cum acest TCP adauga functionalitati substantiale fata de protocoalele discutate anterior dar implementarea sa este mult mai complexa.
Cu toate ca TCP-ul este prezentat aici ca o parte a suitei TCP/IP el este independent, fiind acel protocol de uz general ce poate fi adaptat pentru folosirea cu alte sisteme de distributie. De exemplu, deoarece TCP/IP face prea putine presupuneri referitoare la reteaua fundamentala, el poate fi folosit atat pentru o singura retea precum Ethernetul cat si pentru o retea complexa asa cum este Internetul.
Necesitatea unei distributii de flux
La nivelul cel mai scazut, retele de comunicatii intre calculatoare furnizeaza o distributie nesigura de pachete. Acestea pot fi distruse sau pierdute cand erorile de transmisie interfera cu datele, hardware-ul de retea greseste sau cand retele devin prea incarcate pentru a mai putea accepta un trafic suplimentar. Retele care ruteaza pachetele dinamic le pot distribui intr-o ordine aleatoare, cu intarzieri substantiale sau duplicate. Mai mult, tehnologia retelei fundamentale poate impune o dimensiune optimala pentru pachete sau sa impuna alte constrangeri necesare pentru a obtine o rata de transfer eficienta.
La nivelul cel mai ridicat, programele de aplicatie doresc adesea sa trimita cantitati mari de date de la un calculator la altul. Folosind un sistem de distributie nesigur, cu pierdere de conexiune, transferul cantitatilor mari de informatii devine prea lung, enervant si cere detectia erorilor si recuperari de structuri pentru fiecare program de aplicatie. Deoarece este dificil de proiectat, inteles sau modificat acel software care furnizeaza siguranta, putine programe de aplicatie au background-ul tehnic necesar. In consecinta o tinta a cercetarilor in domeniul protocoalelor de retea a fost gasirea unei solutii cu caracter general la problema distributiei sigure de flux. Existenta unui singur protocol de uz general ajuta la izolarea programelelor de aplicatie de la detaliile retelisticii si face posibila definirea unei interfete uniforme pentru serviciul de transfer al fluxului.
Proprietatile serviciului de distributie sigura.
Interfata dintre programele de aplicatie si TCP/IP se caracterizeaza prin:
Orientarea pe flux. Cand doua programe de aplicatii transfera volume mari de date, noi gandim datele ca un sir de biti divizat in grupuri de 8 biti (un octet). Serviciul de distributie al fluxului de pe masina destinatie paseaza la receptie exact aceeasi secventa de octeti pe care emitatorul o trimite spre el de pe masina sursa.
Conexiune virtuala de circuit. Un transfer de flux este similar cu un apel telefonic local. Inainte ca transferul sa fie pornit, programele de aplicatie emitatoare si receptoare interactioneaza cu sistemul lor de operare informandu-le ca doresc sa faca un transfer. Teoretic, o aplicatie transmite un "apel" care trebuie sa fie receptat de alta. Modulele protocolului software din cele doua sisteme de operare comunica prin trimiterea de mesaje prin retea, verificand daca transferurile sunt autorizate si daca ambele parti sunt pregatite. Odata ce toate detaliile au fost stabilite, modulele de protocol informeaza programele de aplicatie ca o conexiune a fost stabilita si ca transferul poate incepe. In timpul transferului, protocoalele software de pe cele doua masini continua sa comunice pentru a verifica daca comunicatia nu a fost intrerupta dintr-un motiv oarecare (de exemplu hardware-ul de retea s-a defectat), ambele masini detectand eroarea si raportand-o programului de aplicatie corespunzator. Se foloseste termenul de circuit virtual pentru a desemna asemenea conexiuni deoarece desi programele de aplicatie vad conexiunea ca un circuit hardware dedicat, siguranta este doar o iluzie furnizata prin serviciul de distributie a fluxului.
Transfer bufferat. Programele de aplicatie trimit un fluxuri de date prin circuitul virtual prin pasari repetate a octetilor constituienti la protocolul software. Cand transfera date, ficare aplicatie foloseste orice dimensiune de pachete considerata a fi avantajoasa, care poate fi si de un singur octet. La receptie, protocolul software distribuie octetii fluxului de date in exact aceeasi ordine in care ei au fost trimisi, facandu-i disponibili programelor de aplicatie receptor indata ce au fost receptati si verificati. Protocolul software este liber sa imparta fluxul in pachete independente de piesele transferate de programul de aplicatie. Pentru a face transferul cat mai eficient ai pentru a minimiza traficul prin retea, implemetarile uzuale colecteaza suficiente date dintr-un flux pentru a completa o datagrama admisibil de mare inaintea transmiterii ei prin retea. Astfel, chiar daca programul de aplicatie genereaza un flux de un octet in unitatea de timp, transferul prin retea poate fi facut foarte eficient. Similar, daca programul de aplicatie alege sa genereze blocuri foarte mari de date, protocolul software poate alege sa imparta fiecare bloc in piese de mici dimensiuni pentru transmisie.
Pentru acele aplicatii in care datele trebuie distribuite regulat de la un capat la celalalt fara a umple un buffer, serviciul de flux furnizeaza un mecanism de tip "push" aplicatiilor folosite pentru a forta un transfer. La expediere, acest mecanism forteaza protocolul software sa transfere toate datele care au fost generate fara a astepta umplerea unui buffer. La receptie acelasi mecanism obliga TCP-ul sa faca datele disponibile catre aplicatie fara nici o intarziere.
Nota: Mecanismul de "push" doar garanteaza ca toate acele date vor fi transferate imediat, dar nu furnizeaza o limita asupra dimensiunii lor. Astfel, chiar daca distribuirea este fortata protocolul software poate alege sa divida blocurile in modurile cele mai neasteptate.
Fluxuri nestructurate. Este important de stiut ca serviciul de flux TCP/IP nu respecta structura fluxurilor de date. Programele de aplicatie folosind serviciul de flux trebuie sa inteleaga continutul fluxului si sa fie de acord cu formatul lui inainte ca ele sa initieze o comunicatie.
Comunicatie full-duplex. Conexiunile furnizate de serviciul de flux TCP/IP permite transfer paralel in ambele sensuri. Asemenea conexiuni sunt numite full-duplex. Din punctul de vedere al unui proces de tip aplicatie, o conexiune full-duplex este formata din doua fluxuri mergand in sensuri opuse, fara ca ele sa interactioneze vizibil. Serviciul de flux permite unui proces aplicatie sa opreasca datele dintr-un sens in timp ce datele calatoresc in cealalt sens, facand conexiunea half-duplex. Avantajul conexiunii full-duplex este ca acel protocol software fundamental poate trimite informatie de control pentru un flux inapoi la sursa datagramelor ce transporta date in directia opusa. Asemenea"piggybacking" reduce traficul retelei.
Asigurarea sigurantei
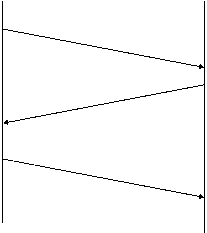
Am afirmat ca serviciul sigur de distributie a fluxului garanteaza distributia unui flux de date de la o masina la alta fara a-l duplica sau pierde date. Se naste intrebarea: "Cum poate un protocol software sa furnizeze un transfer sigur daca sistemul de comunicatie fundamental ofera doar distributie nesigura de pachete?" Raspunsul este complicat, dar majoritatea protocoalelor folosesc o tehnica fundamentala cunoscuta sub numele de "confirmare pozitiva cu retransmisie" (positive acknowledgement with retransmision). Tehnica necesita un receptor care sa comunice cu sursa, trimitand inapoi un mesaj de confirmare (ACK) la receptia datelor. Emitatorul pastreaza o inregistrare a fiecarui pachet si asteapta o confirmare inaintea transmiterii urmatorului pachet. Emitatorul porneste totodata un timer cand trimite un pachet si il retransmite daca timerul a expirat inainte de a primi confirmarea.
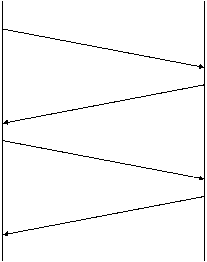
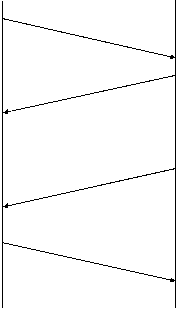
Figura 37 prezinta un protocol cu simpla confirmare pozitiva care transfera date In figura, evenimentele de la emitator sunt prezentate in stanga iar cele de receptor in dreapta. Fiecare linie diagonala traversand mediul intruchipeaza transferul unui mesaj prin retea.
|
Evenimente la un Mesajele din retea Evenimente la un
Expediere pachet 1 Receptie pachet 1 Expediere ACK1 Receptie ACK1 Expediere pachet 2 Receptie pachet 2 Expediere ACK2 Receptie ACK2 Figura 37 Un protocol folosind confirmarea cu retransmisie in care emitatorul asteapta o confirmare pentru fiecare pachet |
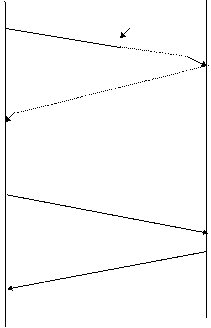
Figura urmatoare prezinta ce se intampla cand un pachet este pierdut sau stricat. Emitatorul porneste timerul dupa transmisia unui pachet. Cand timerul a expirat emitatorul presupune ca pachetul a fost pierdut si il retransmite.
|
Evenimente la un Mesajele din retea Evenimente la un
Expediere pachet 1 Pachet pierdut Pachetul ar fi trebui sa vina ACK ar trebui sa fie trimis Receptie ACK1 Timerul expira Reexpediere pachet 1 Receptie pachet 1 Expediere ACK1 Receptie ACK1 Eliminare timer Figura 38 Depasirea de timp si acea retransmisie ce apare cand un pachet este pierdut |
Ultima problema a nesigurantei apare cand sistemul fundamental de distributie duplica pachetele. Duplicatele pot apare cand reteaua prezinta intarzieri mari care determina retransmisii premature. Rezolvarea duplicarii implica o atenta observatie deorece atat pachetele cat si confirmarile pot fi duplicate. Obisnuit, protocoalele sigure detecteaza duplicatele prin asignarea fiecarui pachet a unui numar de secventa si cere receptorului sa stie ce numere de secventa au fost receptionate. Pentru a evita confuzia determinata prin intarzierea sau duplicarea confirmarilor, protocolul cu confirmare pozitiva trimite inapoi prin confirmari numerele de secventa receptionate, astfel incat receptorul poate asocia corect confirmarile cu pachetele.
Ideea de fereastra glisanta
Inaintea examinarii serviciului de flux TCP, trebuie sa exploram un concept suplimentar care sustine transmiterea de flux, cunoscut sub numele de fereastra glisanta (sliding window) care face transmisia de flux sa fie eficienta. Pentru a intelege necesitatea existentei unei ferestre glisante reamintim secventa de evenimente din figura 37. Pentru a realiza siguranta, emitatorul transmite un pachet si apoi asteapta o confirmare inainte de a trimite altul. Dupa cum indica si figura 37, datele calatoresc intre masini doar intr-o singura directie la unmoment de timp chiar daca reteaua este capabila sa sustina o comunicatie simultana in ambele directii. Reteaua poate fi complet nefolosita in timpul in care masina asteapta raspunsul (de exemplu in timpul in care masina receptoare calculeaza suma de control). Daca ne imaginam o retea ce prezinta intarzieri mari, problema devine clara:
Un protocol cu simpla confirmare pozitiva iroseste o substantiala cantitate din largimea de banda a unei retele deoarece el trebuie sa intarzie trimiterea unui nou pachet pana cand receptioneaza o confirmare pentru pachetul anterior.
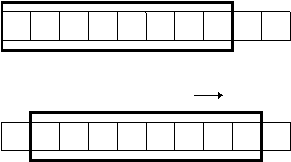
Tehnica ferestrei glisante este o forma mult mai complexa a confirmarii pozitive si retransmisiei fata de metoda simpla discutata anterior. Protocoalele cu fereastra glisanta folosesc mai bine largimea de banda deoarece ele permi utilizatorilor sa transmita multiple pachete inaintea primirii unei confirmari. Cea mai simpla cale de a observa operatia de alunecare a ferestrei este sa ne imaginam o secventa de pachete ce vor fi transmise (figura 39). Protocolul produce o mica fereastra de dimensiune fixa si transmite toate pachetele care se afla in interiorul ei.
|
fereastra initiala
1 2 3 4 5 6 7 8 9 10 (a) fereastra gliseaza 1 2 3 4 5 6 7 8 9 10 (b) Figura 39: (a) Un protocol cu fereastra glisanta avand 8 pachete in fereastra (b) Fereastra gliseaza astfel inact pachetul 9 poate fi trimis doar cand a fost receptionate confirmarea pentru pachetul 1. Doar pachetele neconfirmate sunt retransmise |
Noi am afirmat ca un pachet este neconfirmat daca el a fost transmis dar nu a fost confirmata receptia lui. Din punct de vedere tehnic, numarul de pachete ce pot fi neconfirmate este constrans prin dimensiunea ferestrei si este limitat la un numar fix. De exemplu, intr-un protocol cu fereastra glisanta cu o dimensiune a ferestrei de 8, emitatorului ii este permis sa trimita 8 pachete inainte de a receptiona o confirmare.
Odata ce emitatorul a primit o confirmare pentru primul pachet (figura 39, b) fereastra poate aluneca si el trimite urmatorul pachet. Fereastra continua sa alunece atat cat confirmarile sunt receptionate.
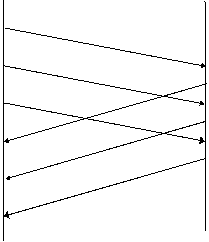
Performantele protocoalelor cu fereastra glisanta depind de dimensiunea ferestrei si de viteza cu care reteaua accepta pachete. Figura 40 prezinta un exemplu de functionare a unui protocol cu fereastra glisanta ce trimite 3 pachete. Se observa ca emitatotul trimite 3 pachete inainte de a receptiona orice confirmare.
Cu o fereastra de dimensiune unitara, protocolul cu fereastra glisanta devine un protocol cu simpla confirmare. Prin cresterea dimensiunii ferestrei este posibila eliminarea completa a timpului de neutilizare a retelei. Astfel in stare activa, emitatorul poate transmite pachete cu viteza cu care reteaua este capabila sa le transmita. Ideea de baza este:
Deoarece un protocol cu fereastra glisanta adecvat pastreaza reteaua complet incarcata cu pachete, el obtine o crestere substantiala de viteza fata de un protocol cu simpla confirmare pozitiva.
|
Evenimente la un Mesajele din retea Evenimente la un
Expediere pachet 1 Expediere pachet 2 Receptie pachet 1 Expediere ACK1 Expediere pachet3 Receptie pachet 2 Expediere ACK2 Receptie ACK 1 Receptie pachet 3 Expediere ACK3 Receptie ACK2 Receptie ACK3 Figura 40 Exemplu de transmisie a 3 pachete utilizand protocolul cu fereastra glisanta |
Teoretic, un protocol cu fereastra glisanta intotdeauna stie care pachete au fost confirmate si pastreaza un timer separat pentru fiecare pachet neconfirmat. Daca un pachet este pierdut, timerul expira si emitatorul retransmite acel pachet. Cand un emitator gliseaza fereastra sa, ea trece peste toate pachetele confirmate. La receptorul final, protocolul software foloseste o fereastra identica cu cea a emitatorului, acceptand si confirmand pachetele sosite. Astfel, o fereastra imparte o secventa de pachete in trei grupe: acele pachete aflate in stanga ferestrei (toate sunt transmise, receptionate si confirmate), acelea din dreapta ce n-au inca trimise si cele aflate in interiorul ferestrei ce sunt in transmise in prezent. Pachetul cu numarul cel mai mic din fereastra este primul pachet din acea secventa care nu a fost inca confirmat.
Protocolul de control al transmisie
Serviciul care asigura siguranta fluxului, fiind cel mai important din suita TCP/IP se numeste protocolul de control al transmisiei (TCP). Este foarte important sa intelegem ca TCP-ul este un protocol de comunicatie si nu subansamblu software, desi foarte multa lume face aceasta confuzie.
Nota: Diferenta dintre un protocol si acel software care il implementeaza este similara cu diferenta dintre un limbaj de programare si un compilator.
Acest protocol specifica formatul datelor si a confirmarilor schimbate de doua calculatoare in vederea realizarii unui transfer sigur, precum si procedurile folosie de calculatoare pentru a garanta ca datele sosite sunt corecte. El specifica cum un software TCP distinge intre multiplele destinatii masina dorita si cum comunica masinile pentru a scapa de erori precum pierderea si duplicarea. Protocolul specifica deasemenea cum initiaza doua calculatoare un flux de transfer si cum il accepta cand acesta este complet.
Deoarece TCP-ul interactioneaza foarte putin cu sistemul de comunicatie fundamental, TCP-ul poate folosi o mare varietate de sisteme de distributie de pachete printre care si IP-ul. De exemplu TCP-ul poate folosi liniile telefonice de abonat (dial-up), LAN-uri, retele de fibre optice sau retele de foarte mica viteza.
Porturi, conexiuni si puncte finale
Protocolul TCP se afla deasupra IP-ului in stiva de protocoale. Figura 41 prezinta organizarea conceptuala a acestei structuri. TCP permite multiplelor programe de aplicatii de pe o masina specificata sa comunice curent si sa demultiplexeze traficul TCP care soseste de la mai multe programele de aplicatie. TCP foloseste numere de port de protocol pentru a identifica ultima destinatie dintr-o masina. Fiecare port are asignat un mic intreg folosit la identificarea lui.
|
Aplicatie TCP UDP IP Interfata de retea Figura 41 Asezarea conceptuala a TCP-ului intre programul de aplicatie si IP |
Nota: TCP-ul furnizeaza un serviciu ce garanteaza siguranta fluxului in timp ce UDP-ul furnizeaza un serviciu nesigur de distributie de datagrame. Programele de aplicatie le folosesc deopotriva pe amandoua.
Porturile TCP sunt mult mai comlexe decat cele UDP, deoarece un numar de port specificat nu corespunde unui singur obiect. In schimb TCP-ul foloseste o conexiune abstracta in care pentru a fi indentificate sunt conectate la circuite virtuale, nu la porturi individuale. Notiunea de conexiune folosita de TCP este foarte importanta intrucat ea explica sensul si utilizarea unui numar de port TCP:
TCP-ul foloseste conexiunea, nu portul de protocol, ca abstractie fundamentala; conexiunile sunt identificate printr-o pereche de puncte finale (endpoints).
Ce sunt mai exact punctele finale ale unei conexiuni? Am spus ca o conexiune formeaza un circuit virtual intre doua programe de aplicatie, astfel inact poate ti s-ar parea natural sa presupui ca un program de aplicatie este un punct final de conexiune. Nu este. In schimb TCP-ul defineste un punct final ca fiind o pereche de intregi de forma (gazda, port), unde gazda este adresa IP pentru o gazda si port este un port TCP de pe acea gazda. De exemplu punctul final (128.10.2.3,25) specifica portul TCP 25 al masinii cu adresa 128.10.2.3.
Acum ca avem definita notiune de punct final, va fi usor sa intelegem conexiunile. Reamintim ca o conexiune este definita prin doua puncte ale sale. Astfel, daca exista o conexiune intre masina (128.26.0.36) si masina (128.10.2.3) ea poate fi definita prin punctele finale:
(128.26.0.36,1069) si (128.10.2.3,53)
alta conexiune poate in curs de stabilire intre masina(128.9.0.32) si una dintre masinile anterioare (128.10.2.3), fiind identificata prin punctele sale finale:
(128.9.0.32,1184) si (128.10.2.3,53)
Deocamdata, exemplele noastre de conexiuni au fost simple deoarece porturile folosite de toate punctele finale au fost unice. In orice caz, conexiunile abstracte permit mai multor conexiuni sa imparta acelasi port. De exemplu, noi am putea adauga o alta conexiune la una din masinile prezentate mai sus; de la masina (128.2.254.139) la masina (128.10.2.3):
(128.2.254.139,1184) si (128.10.2.3,53)
Poate parea ciudat ca doua conexiuni sa poata folosi portul TCP cu numarul 53 de pe masina (128.10.2.3) simultan. Acolo nu va apare nici o problema deoarece TCP-ul asociaza sosirea mesajelor cu o conexiune in loc sa-l asocieze cu port de protocol; el foloseste ambele puncte finale pentru a identifica conexiunea corespunzatoare. Ideea care trebuie retinuta este:
Deoarece TCP-ul identifica o conexiune printr-o pereche de puncte finale, numarul de port TCP specificat poate fi impartit intre mai multe conexiuni la aceeasi masina.
Din punctul de vedere al programatorilor, conexiunea abstracta este importanta. Ea ajuta un programator sa poata scrie un program ce furnizeaza servicii concurente pentru multiple conexiuni simultane fara a dori un numar unic de port pentru fiecare conexiune. De exemplu majoritatea sistemelor furnizeaza acces concurent la serviciul lor de posta electronica, permitand mai multor calculatoare sa trimita posta lor folosind TCP-ul pentru comunicatie. Deoarece programul care accepta e-mail-urile sosite foloseste TCP-ul pentru a comunica, utilizeaza doar un port TCP local chiar daca permite ca multiple conexiuni sa lucreze concurent.
Deschideri active si pasive
Spre deosebire de UDP, TCP-ul este un protocol orientat pe conexiune care necesita ca ambele puncte finale sa accepte comunicarea. Astfel, inainte ca TCP-ul sa plaseze trafic intr-o retea, programele de aplicatie de la ambele puncte finale ale conexiunii trebuie sa fie de acord ca acea conexiune este dorita. Pentru aceasta, programul de aplicatie de la unul din capete realizeaza o functie de deschidere pasiva contactand sistemul sau de operare si indicandu-i ca el va accepta o conexiune. In acest timp, sitemul de operare asociaza un numar de port TCP pentru capatul sau de conexiune. Programul de aplicatie de la celalalt capat trebuie sa contacteze sistemul sau de operare folosind o cerere de deschidere activa pentru a stabili o conexiune. Cele doua module software TCP comunica apoi pentru a stabili si verifica conexiunea. Odata ce o conexiune a fost creata, programele de aplicatie pot incepe sa transfere date; in timpul acesta modulele software TCP de la fiecare capat schimba mesaje care garanteaza siguranta distributiei.
Segmente, fluxuri si numere de secventa
TCP-ul vede fluxul de date ca o secventa de octeti pe care el o imparte in segmente in vederea transmiterii acestora. De obicei, fiecare segment traverseaza reteaua intr-o singura datagrama IP.
TCP-ul foloseste un mecanism specializat cu fereastra glisanta pentru a rezolva doua probleme: eficienta transmisiei si controlul fluxului. La fel ca si protocolul cu fereastra glisanta descris anterior, mecanismul de fereastra al TCP-ului face posibila trimiterea de mai multe segmente inainte de a primi o confirmare. Acest mecanism creste la maxim viteza deoarece ea pastreaza reteaua ocupata. Forma protocolului cu fereastra glisanta a TCP-ului rezolva deasemenea problema controlului fluxului pe o conexiune, prin permiterea receptorului sa restrictioneze transmisia pana cand va avea spatiu suficient in buffer pentru a accepta mai multe date.
Mecanismul cu fereastra glisanta a TCP-ului functioneaza la nivel de octet, nu la nivel de segment sau pachet. Octetii fluxului de date sunt numarati secvential si un emitator pastreaza trei pointeri asociati pentru fiecare conexiune in parte. Pointerii definesc o fereastra glisanta dupa cum indica figura 42. Primul pointer indica partea stanga a ferestrei glisante separand octetii care au trimisi si confirmati de cei care nu au inca trimisi. Al doilea pointer marcheaza partea dreapta a ferestrei glisante indicand octetul cel mai mare din secventa aflata in fereastra care poate fi trimis inainte ca mai multe confirmari sa fie receptionate. Al treilea pointer indica granita cu interiorul ferestrei care separa toti acei octeti care au fost trimisi de cei care n-au fost trimisi. Protocolul software trimite toti octetii din fereastra fara intarzieri astefel incat fereastra se deplaseaza foarte repede de la stanga la dreapta.
|
Fereastra curenta
1 2 3 4 5 6 7 8 9 10 11 Figura 42 Un exemplu de fereastra glisanta TCP Primii 2 octeti au fost trimisi si confirmati, octetii de la 3 la 6 au fost trimisi dar sunt neconfirmati, octetii de la 7 la 9 nu au fost trimisi dar vor fi trimisi fara intarziere, iar de al octetul 10 incolo nu pot fi trimisi pana cand nu se deplaseaza fereastra. |
Noi am descris descris cum fereastra TCP a emitatorului aluneca inainte si mentionam ca si receptorul trebuie sa aiba o fereastra similara. Deoarece TCP-ul are o conexiune full-duplex, doua procese de transfer pot lucra simultan prin fiecare conexiune, cate unul in fiecare directie. Noi gandim ca transferurile fiind complet independente deoarece la orice moment de timp datele pot traversa conexiune intr-o directie sau in ambele directii. Astfel, software-ul TCP de la fiecare capat utilizeaza doua ferestre pentru o conexiune full-duplex (vor fi in total patru), una alunecand de-a lungul fluxului de date trimise actual in timp ce cealalta aluneca cand datele sunt receptionate.
Ferestre cu dimensiuni variable si controlul fluxului
O diferenta intre protocolul TCP cu fereastra glisanta si protocolul simplificat cu fereastra glisanta ce a fost prezentat anterior, apare deoarece TCP-ul permite ca dimensiunea ferestrei sa varieze in timp. Fiecare confirmare care specifica cum au fost receptionati octetii contine o fereastra de avertisment care indica cati octeti suplimentari pot fi acceptati de receptor. Gandim fereastra de avertisment ca specificand dimensiunea curenta a bufferului receptorului. Ca raspuns la o fereastra de avertisment ce indica o valoare crescatoare, emitatorul creste dimensiunea ferestrei sale si trimite octeti care n-au fost confirmati. Ca raspuns la o fereastra care indica o valoare descrescatoare emitatorul isi scade dimensiunea ferestrei sale si opreste trimiterea octetilor care in urma modificarii se afla in acum in afara ferestrei. In schimb micile anunturi insotind confirmarile determina ferestrele sa-si modifice dimeniunea tot timpul determinand o distributie variabila (din punctul de vedere al cantitatii de informatie trimisa).
Avantajul folosirii unei ferestre cu dimensiune variabla este ca furnizeaza un control al fluxului precum si siguranta transportului. Daca bufferul receptorului incepe sa se umple, el nu poate accepta mai multe pachete, asa ca el trimite un avertisment de micsorare a ferestrei. In cazul extrem, receptorul anunta o dimensiune de fereastra zero pentru a opri intreaga transmisie. Mai tarziu cand bufferul incepe sa aiba spatiu disponibil, receptorul anunta o dimensiune de fereastra corespunzatoare pentru a reporni fluxul.
Existenta unui mecanism pentru controlul fluxului este esential intr-o retea ca Internetul, unde masinile au viteze variate si vehicularea informatiilor prin retele si rutere se face la viteze si capacitati diferite. Acolo sunt doua probleme reale. Prima, protocoalele de retea doresc un control al fluxului pe conexiuni, intre sursa si ultima destinatie. De exemplu, cand un minicalculator comunica cu un mainframe, minicalculatorul doreste sa se regleze fluxul de date catre el sau in caz contrar software-ul va fi rapid supraincarcat. Astfel, TCP-ul trebuie sa implementeze controlul fluxului pe o conexiune pentru a garanta siguranta distributiei. A doua, protocoalele de retea doresc un mecanism de control al fluxului care sa permita sistemelor intermediare (de exemplu ruterelor) sa controleze o sursa care transmite mai mult trafic decat poate accepta o masina.
Cand masinile intermediare devin supraincarcate, pare o problema numita congestie, iar mecanismul care o solutioneaza este numit controlul congestiei . TCP-ul foloseste schema sa cu fereastra glisanta pentru a solutiona problema controlului fluxului pe o conexiune.
Nota: O atenta programare a implemetarii TCP-ului poate detecta si remedia congestia in timp ce o implementare slaba poate face mai mult rau. In particular, o alegere atenta a schemei de retransmisie poate ajuta la evitarea congestie in timp ce o schema prost aleasa poate sa o complice.
Formatul unui segment TCP
|
0 8 16 24 31
SOURCE PORT DESTINATION IP ADDRESS SEQUUENCE NUMBER ACKNOWLEDGEMENT NUMBER HLEN RESERVED CODE BITS WINDOW CHECKSUM URGENT POINTER OPTIONNS PADDIND DATA Figura 43 Formatul segmentului TCP cu un header urmat de date. Segmentele sunt folosite pentru stabilirea conexiunilor precum si la transportul datelor si confirmarilor. |
Unitatea de transfer dintre software-ul TCP a doua masini este nuimit segment. Segmentele sunt schimbate pentru stabilirea unei conexiuni, pentru transferul de date, pentru trimiterea confirmarilor, pentru anuntul dimendiunii ferestrei si pentru inchiderea conexiunii. Deoarece TCP-ul foloseste metoda piggybacking, o confirmare de la masina A la masina B poate calatori in acelasi segment ca si datele ce calatoresc de al masina A la masina B, chiar daca confirmarea era pentru datele trimise de la B la A. Figura 43 prezinta forma segmentului.
Fiecare segment este impartit in doua parti: header si date. Headerul este cunoscut sub numele de header TCP transportand identificarile asteptate si informatii de control. Campurile SOURCE PORT si DESTINATION PORT contin numerele de port TCP ce identifica programele de aplicatie de la capetele conexiunii. Campul SEQUENCE NUMBER identifica pozitia fluxului de octeti trimisi de un emitator in zona de date a unui segment. Campul ACKNOWLEDGEMENT NUMBER identifica numarul octetului receptionat si pe care sursa il asteapta pentru a-l putea trimite pe urmatorul. Observam ca numarul de secventa indica fluxul calatorind in aceeasi directie ca si segmentul in timp ce numarul de confirmare indica fluxul calatorind in directia opusa segemetului.
Campul HLEN contine un intreg ce specifica lungimea headerului segmentului masurat in multipli de 32 de biti. El este necesar deoarece campul OPTIONS are o lungime variabila, corespunzator optiunilor care le include. Astfel, dimensiunea headerului TCP depinde de optiunile selectate. Campul de 6 biti marcat RESERVED este rezervat pentru utilizari de catre versiuni ulterioare.
|
Bit (de la stanga la dreapta) Scopul (daca bitul este in 1)
ACK Campul de confirmare este valid PSH Acest segment cere un "push" RST Resetarea conexiunii SYN Sincronizarea numerelor de secventa FIN Emitatotul a atins sfarsitul fluxului de octeti |
Unele segmente transporta o confirmare in timp ce unele trasporta date. Astele contin doar cereri de stabilire sau inchidere conexiuni. Software-ul TCP foloseste campul de 6 biti etichetat CODE BITS (biti de cod) pentru a determina scopul si continutul unui segment. Cei 6 biti spun cum sa interpretezi celelalte campuri din header dupa indica urmatorul tabel:
Software-ul TCP anunta cat de mute date doreste sa accepte la fiecare moment de timp el trimitand un segment ce specifica dimensiunea bufferului sau in campul WINDOW. Campul contine un intreg fara semn reprezentat pe 16 biti conform formatului standard de retea. Fereastra de anunt constituie un alt exemplu de piggybackig deoarece ea insoteste toate segmentele, inclusiv acelea trasportand date precum si cele transportand doar o confirmare.
Date suplimentare (out of band)
Desi TCP-ul este un protocol orientat pe flux, este uneori important pentru programul de la un capat al conexiunii sa trimita date suplimentare, fara a astepta ca programul de la celalalt capat al conexiunii sa preia octetii deja existenti in flux. De exemplu, cand TCP-ul este folosit pentru o sesiune de conectare la distanta, utilizatorul se poate hotara sa trimita o secventa de comenzi care intrerupe sau anuleaza programul de la celalalt capat. Asemenea semnale sunt de cele mai multe ori dorite cand un program de pe o masina indepartata greseste anumite operatii. Semnalele trebuie trimise fara a astepta ca programul sa citeasca octetii deja existenti in fluxul TCP.
Ca sa accepte date in afara benzii, TCP-ul permite emitatorului sa specifice datele ca fiind urgente, indicand ca programului receptor va fi anuntat de sosirea lor cat mai rapid posibil, fara a lua in consideratie pozitia lor in cadrul fluxului. Protocoalele specifica ca atunci cand datele urgente sunt gasite, receptorul TCP trebuie sa anunte orice program de aplicatie ce este asociat cu acea conexiune sa treaca in "modul urgent". Dupa ce toate datele urgente au fost folosite, TCP-ul indica programului de aplicatie sa se intoarce in modul normal de functionare.
Detaliile exacte ale modului in care TCP-ul informeaza programul de aplicatie de existenta datelor urgente depind de sistemele de operare folosite de calculatoare. Mecanismul folosit pentru a indica date urgente cand ele sunt transmise prin intermediul unui segment este constituit din bitul de cod URG si campul URGENT POINTER. Cand bitul URG este setat, pointerul urgent indica pozitia din segment in care datele urgente se termina.
Optiunea de dimensiune maxima pentru un segment
Nu toate segementele trimise printr-o conexiune vor fi de aceeasi dimensiune. In orice caz, ambele extremitati trebuie sa accepte o dimensiune maxima pentru segmentele care le vor trasfera. Software-ul TCP foloseste campul OPTIONS pentru a negocia cu software-ul TCP de la celalalt capat al conexiunii;.una din optiuni permite software-ului TCP sa specifice dimensiunea maxima a segementului (MMS) pe care doreste sa-l receptioneze. De exemplu, cand un sistem fix care are un buffer de doar cateve sute de octeti se conecteaza la un supercalculator, el poate negocia un MMS care restrictioneaza segmentele astfel incat ele sa incapa in buffer. Este extrem de important pentru calculatoarele conectate prin LAN-uri de mare viteza sa aleaga o dimensiune maxima de segment care sa umple pachetele, in caz contrar ele nefolosind la maxim largimea de banda disponibila. Mai mult, daca doua puncte finale sunt in aceeasi retea fizica, TCP-ul calculeaza o dimensiune maxima pentru segment astfel incat dimensiunile datagramelor IP rezultate vor coincide cu MTU-ul retelei. Daca punctele finale nu sunt in aceeasi retea fizica, ele pot incerca sa descopere MTU-ul minim de-a lungul drumului dintre ele sau sa aleaga o dimensiune maxima de segment de 536 ( dimensiunea implicita a unei datagrame este 576 minus dimensiunea standard a headerelor IP si TCP luate impreuna).
Intr-un mediu general ca Internetul, o alegere buna a dimensiunii maxime de segment poate fi dificila, deoarece performantele pot fi slabe in cazurile extreme in care dimensiunile de segment sunt foarte mari sau foarte mici. Cand dimensiunea de segment este mica, utilizare retelei este suboptimala. Pentru a vedea de ce, reamintim ca segmentele TCP calatoresc incapsulate indatagarame IP care la randul lor sunt incapsulate in datagrame fizice de retea fizica. Astfel, fiecare segment are cel putin 40 de octeti pentru headerele TCP si IP in completare la date, iar daca datagrama transporta doar un octet de date se va folosi cel mult 1/41 din largimea de banda disponibila pentru utilizator. In practica, pauzele dintre pachete si bitii de incadrare ai hardware-ului retelei fac rata de transfer chiar mai mica.
La cealalta extrema, dimensiunile de segment foarte mari pot conduce deasemenea la rezultate foarte slabe. Segmentele mari implica datagrame IP mari. Cand asemenea datagrame trec pintr-o retea cu un MTU mai mic, IP-ul trebuie sa le fragmenteze. Spre deosebire de un segment TCP, un fragment nu poate fi confirmat sau retransmis independent; toate fragmentele trebuie sa fie receptionate sau intrega datagrama va trebui retrasmisa. Intrucat probabilitatea probabilitatea pierderii unui fragment este diferita de zero, o crestere a dimensiunii segmentului peste pragul de fragmentare scade probabilitatea ca datagrama sa soseasca, care la randul ei contribuie la scaderea productivitatii.
In teorie, dimensiunea optima de segment S, apare cand datagramele IP transportand segmente folosesc intreaga largime de banda disponibila fara a fi necesara fragmentarea acestora oriunde de-a lungul drumului dintre sursa si destinatie. In practica gasirea lui S este dificila din mai multe motive. Primul, majoritatea implementarilor TCP-ului nu includ un mecanism pentru astfel de probleme. Al doilea, deoarece ruterele dintr-o retea de tip Internet pot schimba dinamic rutele se va modifica si dimensiunea la care poate survine fragmentarea. Al treilea, dimensiunea optima depinde de headerele protocoalelor de nivele inferioare (de exemplu, dimensiunea segmentului trebuie sa fie redusa in conformitate cu optiunile IP). Cercetarile in probleme gasirii unei dimensiuni optime continua.
Calculul sumei de control TCP
Campul CHECKSUM din headerul TCP contine suma de control de tip intreg pe 16 biti folosita la verificarea integritatii datelor precum si a headerului TCP. Pentru a calcula suma de control, software-ul TCP de pe masina emitatoare urmareste o procedura identica cu cea descrisa in capitolul anterior pentru UDP. El contruieste un pseudo-header pentru segment, adauga biti suplimentari (toti in zero) pentru a face segmentul un multiplu de 16 si calculeaza suma de control pentru intrega structura obtinuta. TCP-ul nu include la estimarea lungimii, pseudo-headerul si bitii suplimentari introdusi pentru compltare si nici nu ii transmite. Astfel, el presupune ca, campul propriei sume de control este zero in scopul calcularii sumei de control. Ca si in cazul sumelor de control anterioare, TCP-ul foloseste operatiile aritmetice pe 16 biti, facand complemetul fata de 1 al sumei complementelor fata de 1 al tuturor grupelor de 16 biti. La site-ul receptor, software-ul TCP face aceleasi calcule pentru a verifica daca segmentul sosit este intact.
Scopul folosirii pseudo-headerului este acelasi ca si in cazul UDP-ului. El permite receptorului sa verifice daca segmentul a ajuns la destinatia sa corecta, care include adresa IP a gazdei precum si numarul portului de protocol. Adresele IP ale sursei si destinatiei sunt importante pentru TCP deoarece el trebuie sa le foloseasca pentru a identifica conexiunea pentru care segmentul este destinat. Mai mult, ori de cate ori soseste o datagrama transportand un segment TCP, IP-ul trebuie sa furnizeze TCP-ului adresele IP ale sursei si destinatiei extrase din datagrama precum si segmentul propriu-zis. Figura 44 prezinta formatul pseudo-headerului utilizat in calculul sumei de control.
|
SOURCE ADDRESS IP DESTINATION ADDRESS IP ZERO PROTOCOL TCP LENGTH Figura 44 Formatul pseudo-headerului TCP utilizat la calculul sumei de control |
TCP-ul emitator asigneaza campului PROTOCOL valoarea pe care sistemul fundamental de distributie o va folosi in campul sau ce indica tipul de protocol. Pentru datagramele IP trasportand TCP valoarea este 6. Campul TCP LENGTH specifica lungimea totala a segmentului TCP incluzand si headerul TCP. La receptorul final, informatia necesara refacerii pseudo-headerului este extrasa din datagrama IP care transporta segmentul si il include in calculul sunei de control pentru a verifica daca segmentul a sosit la destinatia corecta intact.
Confirmari si retransmisii
Deoarece TCP-ul trimite date in segmente de lungime variabila, iar retransmiterea segmentelor poate include mai multe date decat cele originale, comfirmarile nu se pot referi usor la datagrame sau segmente. In schimb, ele indica pozitia in flux folosind numerele de secventa de flux. Receptorul colecteaza octetii de date din segmentele sosite si reconstituie o copie exacta a fluxului trimis. Deoarece segmentele calatoresc in datagrame IP, ele pot fi pierdute sau distribuite intr-o ordine aleatoare; receptorul foloseste numerele de secventa pentru a reordona segmentele. La orice moment de timp, receptorul va avea reconstituiti zero sau mai multi octeti consecutivi de la inceputul fluxului, dar mai pot exista si o serie de piese aditionale ale fluxului din datagrame sosite intr-o alta ordine. Receptorul confirma intotdeauna cel mai lung prefix consecutiv al fluxului care a fost receptionat corect. Fiecare confirmare specifica o valoare a secventei mai mare cu o unitate ca pozitia ultimului octet din prefixul consecutiv receptionat de el. Astfel, emitatorul se afla intr-o relatie continua cu receptorul. Ideea importanta este:
O schema de confirmare TCP specifica numarul de secventa al urmatorului octet, pe care receptorul asteapta sa-l receptioneze.
Schema de confirmare TCP este cumulativa deoarece ea indica cat din fluxul de date a fost receptionat. Acest tip de schema de confirmare are avantaje si dezavantaje. Un avantaj este acela ca, confirmarile sunt deopotriva usor de generat si neambigue. Un alt avantaj este ca, piederea confirmarilor nu face necesara fortarea retransmisie intregului flux de date. Un dezavantaj major este acela ca emitatorul nu receptioneaza informatie referitoare la succesul trasmisiilor tuturor, ci doar despre o singura pozitie din flux care care a fost receptionata.
Pentru a intelege de ce lipsa informatiilor despre toate trasmisiile reusite fac schema confirmarilor cumulative mai putin eficienta, ne imaginam o fereastra ce include un bloc de 5000 de octeti care incep din pozitia 101 in flux si presupunem ca emitatorul are transmise toate datele din fereastra prin trimiterea a 5 segmente. Presupunem ca primul segment este pierdut, dar toate celelalte au ajuns intacte. Dupa fiecare segment sosit, receptorul trimite o confirmare, dar fiecare specifica octetul 101, urmatorii octeti consecutivi el asteptandu-i spre receptie. Nu exista o modalitate pentru ca receptorul sa poata spune emitatorului ca majoritatea datelor din fereastra curenta au sosit.
Cand apare depasirea de timp la site-ul emitator, acestal trebuie sa aleaga intre doua potentiale scheme ineficiente. El poate sa retransmita un segment sau toate cele 5 segmente. In acest caz retransmiterea celor 5 segmente este ineficienta . Cand primul segment soseste, receptorul va avea toate datele in fereastra si poate confirma 5101. Daca emitatorul foloseste standardul acceptat si retransmite numai primul segment neconfirmat, el trebuie sa astepte confirmarea acestuia inainte de a putea decide ce si cat de mult trebuie sa trimita. Astfel, el devine un simplu protocol cu confirmare pozitiva si poate pierde avantajele date de o fereastra mare.
Expirarea timpului si retransmisia
Una dintre cele mai importante si complexe idei din TCP este continuta in modul de manipulare a depasirii de timp si a retransmisiei. Ca si celelalte protocoale, TCP-ul asteapta destinatia sa trimita confirmari ori de cate ori ea receptioneaza cu succes un nou octet din fluxul de date. De cate ori trimite un segment, TCP-ul porneste un timer si asteapta pentru confirmare. Daca timpul expira inainte ca datele din segment sa fie confirmate, TCP-ul presupune ca segmentul acela a fost pierdut sau stricat si-l retrimite.
Pentru a intelege de ce algoritmul de retransmisie TCP difera de algoritmul folosit in majoritatea protocoalelelor de retea, trebuie sa reamintim ca TCP-ul a fost proiectat pentru folosire intr-un mediu precum reteaua Internet. Intr-o astfel de retea, un segment calatorind intre doua masini pereche poate traversa multiple retele intermediare, trecand prin ultiple rutere sau poate traversa un singur LAN de mare viteza. Astfel, este imposibil sa cunosti dinainte cat de repede se vor intoarce confirmarile la sursa. Mai mult, intarzierea la fiecare ruter depinde de trafic, astfel ca timpul total necesar pentru ca un segment sa ajunga la destinatie si ca o confirmare sa se intoarca la sursa variaza dramatic de la un caz la altul. Software-ul TCP trebuie sa se acomodeze atat cu varietatea diferentelor de timp necesare pentru a atinge o destinatie cat si cu schimbarile de timp necesare pentru a atinge o destinatie specificata cand incarcarea cu trafic variaza.
TCP-ul se impaca cu aceasta mare diversitate de intarzieri ce apar intr-o retea de tip Internet prin utilizarea unui algoritm adaptiv de retransmisie. In esenta, TCP-ul monitorizeaza performantele fiecarei conexiuni si deduce o valoare corespunzatoare pentru intervalul de timp in care se asteapta o confirmare. Astfel daca performantele unei conexiuni se modifica, TCP-ul reevalueaza valoare intervalului de timp.
Pentru a aduna datele necesare pentru un algoritm adaptiv, TCP-ul inregistreaza timpul la care fiecare segment este trimis si timpul la care o confirmare soseste pentru datele din acel segment. Din cele doua valori de timp TCP-ul calculeaza timpul scurs cunoscut sub numele de "esantion de timp complet de calatorie" sau "esantion complet de calatorie". Ori de cate ori el obtine un nou esantion de timp, TCP-ul modifica isi modifica valoarea mediei pentru timpul complet de calatorie al unei conexiuni. De obicei TCP-ul memoreaza estimarea timpului complet de calatorie (RTT), ca o medie ponderata si foloseste noul esantion de timp pentru a modifica putin valoarea mediei. De exemplu, cand calculeaza o noua medie ponderata, o tehnica de mediere simpla este cea de utilizare a unui factor de constant de podere (a), unde 0 a 1, la ponderarea vechii medii cu ultimul esantion de timp:
RTT = (a*Vechiul_RTT) + ((1-a)*Noul_eantion)
Alegerea unei valori pentru a apropiata de 1 face media ponderata imuna la schimbarile care dureaza perioade mici de timp, in timp ce alegerea unei valori apropiata de 0 pentru a face media poderarata sa raspunda foarte rapid la intarzieri.
Cand trimite un pachet, TCP-ul calculeaza valoarea pentru intervalul de timp in care asteapta confirmarea ca o functie de estimarea curenta a timpului complet de calatorie. Implementarile simple ale TCP-ului folosesc un factor de podere constant (b), cu b>1 si obtine un timp de asteptare mai mare decat valoarea curenta a estimarii timpului complet de calatorie:
Timp de asteptare = b*RTT
Alegerea unei valori pentru b poate fi dificila. La o extremitate, pentru a detecta rapid pachetul pierdut valoarea timpului de asteptare trebuie sa fie foarte apropiata de valoarea curenta a timpului complet de calatorie (de exemplu b trebuie sa fie foarte aproape de 1). Detectarea rapida a pachetului pierdut implica productivitate deoarece TCP-ul nu va astepta un timp inutil de lung inaintea retransmisiei. La cealalta extremitate daca b=1, TCP-ul este prea rapid si orice mica intarziere poate determina o retransmitere inutila, care micsoreaza largimea de banda disponibila. Specificatiile originale recomandau setarea b=2; dar metoda descrisa mai jos conduce la o buna tehnica de ajustarea timpului de asteptare. Aceasta poate fi concluzionata astfel:
Pentru acomodarea la diversitatea intarzierilor ce apar intr-o retea de tip Internet, TCP-ul foloseste un algoritm de retransmisie adaptiv care monitorizreaza intarzierile pentru fiecare conexiune si isi modifica in consecinta parametrul timpului de asteptare.
Masurarea precisa a timpului complet de calatorie
In teorie, masurarea unui esantion de timp este banala - el este obtinut prin scaderea timpului in care segmentul este trimis din timpul in care o confirmare soseste. In orice caz, complicatii apar deoarece TCP-ul foloseste o schema de confirmare cumulativa in care confirmarile se refera datele receptionate si nu la instanta unei datagrame specifice care transporta date. Consideram o retransmisie. TCP-ul formeaza un segment, il plaseaza in datagrama si-l trimite; timerul expira si TCP-ul trimite din nou segmentul intr-o a doua datagrama. Deoarece ambele datagrame transport aceleasi date, emitatorul nu are posibilitatea sa afle daca confirnarea corespunde datagramei originale sau celei retransmise. Acest fenomen a fost numit neclaritatea datagramei, iar despre confirmarile TCP se spune ca sunt neclare.
TCP-ul trebuie sa presupuna ca, confirmarea apartine transmisiei originale sau uneia retransmisii (cum ar fi de pilda cea mai recenta retransmisie)? Surprinzator, fiecare presupunere este functionala. Asocierea confirmarii cu transmisia originala poate face valoarea estimarii de timp mare fara a include cazul in care reteaua a pierdut datagrama. Daca confirmarea vine dupa una sau mai multe retransmisii, TCP-ul va masura esantionul de timp fata de transmisia originala si va calcula un nou RTT utilizand un esantion cu o valoare excesiv de mare. Astfel , RTT-ul va creste intr-o oarecare masura. La momentul urmator TCP-ul trimite un segment, RTT-ul de valoare mare va determina un timp de asteptare ceva mai lung si daca confirmarea soseste dupa una sau mai multe retransmisii, urmatorul esantion de timp va fi chiar mai mare si asa mai departe.
Asocierea confirmarii cu cea mai recenta retransmisie, poate deasemenea gresi. Consideram ca apare o crestere busca a intarzierii pe o conexiune. Cand TCP-ul trimite un segment, el foloseste vechea estimare pentru a calcula timpul de asteptare, care acum este prea mic. Segmentul soseste si o confirmare porneste inapoi, dat si TCP-ul retransmite segmentul. La scurt timp dupa retransmisie soseste si confirmarea si ea este asociata cu retransmisia. Noul esantion de timp va fi cu mult prea mic si va rezulta o scadere a RTT. Din nefericire un RTT scazut garanteaza ca TCP-ul va seta o valoare pentru timpul de asteptare prea mica pentru urmatorul segment. In cele din urma, estimarea timpului complet de calatorie se poate stabiliza la o valoare T, inact timpul complet de calatorie este putin mai lung decat cativa multipli ai lui T. Implementarile TCP-ului care asociaza confirmarile cu cea mai recenta retransmisie - observarile fiind facute in stari stabile - au RTT-ul putin mai mic ca din valoarea corecta (ca de pilda TCP-ul trimite fiecare segment exact de doua ori chiar daca piederea nu survine).
Algoritmul lui Karn si reducerea timerului
Deoarece atat transmisia originala cat si cea mai recenta greseste in a furniza un timp complet de calatorie exact, TCP-ul nu trebuie sa modifice estimarea de timp pentru segmentele retransmise. Aceasta idee este cunoscuta sub numele de algoritmul lui Karn si solutioneaza probleme confirmarilor neclare, prin modificarea estimarii de timp doar pentru confirmarile clare (confirmarile care au sosit pentru segmentele ce au fost transmise o singura data).
Desigur, o implementare simplista a algoritmului lui Karn care pur si simpu ignora timpii pentru segmentele retransmise, poate duce foarte bine la erori. Presupunem ca se intampla ca dupa ce TCP-ul trimite un segment sa apara o crestere busca a intarzierii pe conexiune. In acest caz timpul de asteptare va fi prea mic pentru noua intarziere si va forta retransmiterea. Daca TCP-ul ignora confirmarile pentru segmentele retransmise, el nu va reusi sa reinnoiasca estimare niciodata deoarece a intrat intr-o bucla.
Pentru eliminarea acestei situatii, algortimul lui Karn cere emitatorului sa conbine timpul de asteptare pentru retransmisie cu o stategiede tip backoff. Aceasta tehnica calculeaza un timp de asteptare initial folosind schema prezentata mai sus. In orice caz , daca timerul expira deteminand o retransmisie, TCP-ul ca creste valoarea timpului de asteptare. De fapt, de fiecare data cand el trebuie sa retransmita un segment, TCP-ul incrementeaza timpul de asteptare (pentru ca timpul de asteptare sa nu devina ridicol de lung, majoritatea implementarilor limiteaza cresterea la o valoare care este mai mare ca orice intarziere care poate apare de-a lungul oricarui drum prin Internet).
Implementarile folosesc o varietate de tehnici pentru a calcula backoff-ul. Majoritatea aleg un factor de multiplicare g si noua valoare va fi:
noul_timp_de_aspteptare = g*timpul_de_asteptare
Valoarea tipica pentru g este 2.(a fost argumentat prin faptul ca o valoare a lui g mai mica ca 2 conduce la instabilitate). Alte implemetari folsesc un tabel de factori multiplicativi, permitand backoff-uri arbitrare la fiecare pas.
Algoritmul lui Karn combina tehnica backoff cu estimarea tipului complet de calatorie pentru a solutiona problema neincrementarii RTT:
Algoritmul lui Karn: Cand calculeaza estimarea timpului complet, ignora esantioanele care corespund segmentelor retransmise, dar foloseste o strategie de tip backoff si pastreaza valoarea timpului de asteptare pentru fiecare pachet retransmis pentru pachetele ulterioare pana cand un esantion valid este obtinut.
In general vorbind, cand reteaua se poarta rau, algoritmul lui Karn separa calculul timpului de asteptare de estimarea curenta a timpului complet de calatorie. El foloseste RTT-ul pentru a calcula o valoare initiala pentru timpul de asteptare, dar apoi face un backoff al timpului de asteptare pentru fiecare retransmisie pana poate transfera cu succes un singur segement. Cand el trimite segmentele ulterioare, retine valoarea timpului de asteptare care rezulta din backoff. In final, cand soseste o confirmare corespunzatoare unui segment care nu a necesitat retransmisie, TCP-ul va calcula estimarea timpului complet de caltorie (RTT) si modifica in consecinta vechea valoare. Experientele au aratat ca algoritmul lui Karn lucreaza bine chiar si in retele cu pierderi mari de pachete.
Raspunsul la schimbari mari ale valorii intarzierii
Cercetarile asupra estimarilor timpului complet de calatorie au evidentiat ca schemele de calcul prezentate pana acum nu sunt utilizabile in cazul in care variatia intarzierilor are o dispersie mare. Teoria cozilor sugereaza ca variatia timpului complet de calatorie (s) variaza proportional cu 1/1-L, unde L este incarcarea curenta a retelei (0 L 1). Daca reteaua lucreaza la 50% din capacitate, ne asteptam ca intarzierea timpului complet de calatorie sa varieze in gama s (sau 4). Cand incarcarea creste la 80% ne asteptam la o varietie de 10. Standardul TCP original specifica tehnica de estimare a timpului complet de calatorie descrisa la inceput. Folosind aceasta tehnica si limitand valoare lui b la cea sugerata obtinem un RTT care se adpateaza la o incarcare de cel mult 30%.
Specificatiile din 1989 pentru TCP cere implementarilor sa estimeze atat media timpului total de calatorie cat si vatiatia si sa foloseasca variatia estimata in locul constantei b. Ca rezultat , noile implementari ale TCP-ului pot sa se adapateze la o mare gama de variatii ale intarzierilor si generand o important crestere a productivitatii. Din fericire, aproximatiile necesita mici calcule; programe extrem de eficiente pot fi obtinute utilizand urmatoarele ecuatii simple:
DIFF = ESANTION - Vechiul_RTT
Smoothed_RTT = Vechiul_RTT + d*DIFF
DEV = Vechiul_DEV + r DIFF - Vechiul_DEV)
Timpul_de_asteptare = Smoothed_RTT + h*DEV
unde DEV este estimarea deviatiei medii, d este o factor intre 0 si 1 care controleaza cat de repede noile estimari afecteaza media poderata, r este un factor care controleaza cat de rapid noul esantion afecteaza deviatie medie si h este un factor care controleaza cat de mult deviatia afecteaza RTT. Cercetarile sugereaza ca valorile r d = 3, vor lucra foarte bine. Valoarea originala pentru h in 4.3 BSD UNIX a fost 2; ea a fost schimbata in 4 la 4.4 BSD UNIX.
Raspunsul la congestie
In practica, TCP-ul trebuie sa raspunda la congestiile din retea. Congestia este o conditie de intarziere grava determinata de supraincarcarea cu datagrame a unuia sau a mai multor puncte de comutare (cum ar fi de pilda ruterele). Cand apare o congestie, intarzierile cresc si ruterul incepe sa puna datagramele intr-o coada pana ce va putea sa le ruteze. Trebuie reamintit faptul ca fiecare ruter are o capacitate finita de stocare si ca datagramele concureaza pentru acea stocare (de exemplu, intr-o retea bazata pe datagrame nu exista o prealocare de resurse pentru o conexiune TCP individuala). In cazul cel mai defavorabil, numarul total al datagramelor venite la ruterul congestionat creste pana cand ruterul atinge capacitatea maxima de stocare dupa care incepe sa piarda datagrame care mai apar.
In mod obisnuit un punct final nu cunoaste detaliile locului in care a aparut congestia si nici de ce a aparut. Din nefericire, majoritatea protocoalelor de transport folosesc timpul de asteptare si retransmisia, asa ca ele contribuie la cresterea intarzierilor prin retransmisia datagramelor. Aceasta agraveaza congestia in loc s-o usureze. Daca nu se verifica incarcarea cu trafic a retelei si se continua retransmisia, intazierile cresc pana cand reteaua devine nefolosibila. Aceasta problema este cunoscuta sub numele de colapsul congestiei.
Ca sa evite colapsul congestiei, TCP-ul trebuie sa reduca rata de transfer cand congestia apare. Ruterele supravegheaza lungimea cozilor si folosesc o tehnica asemanatoare mesajului ICMP care indica o sursa prea rapida, pentru a informa gazdele ca o congestie este pe cale sa apara; protocoalele de nivel transport precum TCP-ul pot ajuta la evitarea congestiei prin reducerea automata a ratei de transfer ori de cate ori apar intarzieri.
Ca sa evite congestia, standardul TCP recomanda acum doua tehnici: pornire usoara si descresterea multiplicativa. Am spus ca pentru fiecare conexiune, TCP-ul trebuie sa stie dimensiunea ferestrei receptorului (de exmplu utilizand fereastra de anunt). Ca sa controleze congestia TCP-ul foloseste o a doua limita, numita limita de congestie a ferestrei sau fereastra de congestie. La orice moment de timp, TCP-ul reactioneaza ca si cum marimea ferestrei este:
Fereastra_permisa = min(dimensiune_fereastra_receptor, freastra_congestie)
In starea normala a unei conexiuni necongestionate fereastra de congestie are aceeasi dimensiune ca si fereastra receptorului. Reducand fereastra de congestie se reduce traficul pe care TCP-ul il injecteaza in conexiune. Pentru estimarea dimensiunii ferestrei de congestie, TCP-ul presupune ca majoritatea datagramelor se pierd intr-o congestie si foloseste urmatoarea strategie:
Evitarea congestiei prin descrestere multiplicativa: Dupa pierderea unui segment, reduce la jumatate dimensiunea ferestrei de congestie (poate cobora pana la cel mult un segment). Pentru toate segmentele care raman in fereastra permisa, reduce exponential timpul de retransmisie.
Deoarece TCP-ul reduce fereastra de congestie la jumatate pentru fiecare pierdere, el va descreste exponential fereastra daca aceastea continua. Cu alte cuvinte, daca congestia este posibila, TCP-ul reduce exponential volumul traficului si rata retransmisiei. Daca piederile continua, TCP-ul limiteaza transmisia la o singura datagrama si continua sa dubleze timpul de asteptare inaintea retransmisiei. Ideea este sa furnizezi o reducere rapida si consistenta a traficului pentru ca ruterele sa aiba suficient timp pentru a sterge datagramele exitente in cozile lor.
Cum sesizeaza TCP-ul cand s-a terminat congestia? O ideea ar fi ca TCP-ul sa inverseze descresterea multiplicativa si sa dubleze fereastra de congestie cand traficul reporneste. O astfel de actiuni sunt nerecomandate deoarece au ca rezultat un sistem instabil ce oscileaza aiurea intre un trafic oprit si congestie. In schimb TCP-ul foloseste o tehnica numita pornire usoara ce gradeaza cresterea transmisiei:
Redresarea prin pornire usoara (de tip aditiv): Ori de cate ori se porneste traficul intr-o conexiune noua sau traficul creste dupa o perioada de congestie, se porneste cu o fereastra de congestie avand dimensiunea unui singur segment si creste aceasta dimensiune cu o unitate (segment) la fiecare moment de timp in care soseste o confirmare.
Acest mecanism evita inundarea retelei cu un trafic suplimentar imediat dupa eliminarea unei congestii sau cand noi conexiuni pornesc deodata.
Termenul de pornire usoara poate fi impropriu deoarece fata de conditiile ideale, pornirea nu este foarte lenta. TCP-ul initializeaza fereastra de congestie cu valoarea 1., trimite un segment initial si asteapta. Cand confirmarea soseste, el creste dimensiunea ferestrei de congestie la 2 si asteapta. Cand cele 2 confirmari sosesc fiecare dintre ele va incrementa fereastra de congestie cu 1 astfel incat TCP-ul va trimite 4 segmente. Confirmarile sosite pentru acele ferestre vor creste la 8 dimensiunea ferestrei de congestie si asa mai departe ajungandu-se foarte aproape de limita ferestrei receptorului. Chiar pentru ferestre foarte mari, el necesita doar log2N calatorii complete inainte ca TCP-ul sa poata trimite N segmente.
Ca sa se evite cresterea prea rapida a dimensiunii ferestrei si sa se determine o congestie suplimentara, TCP-ul aduga o restrictie suplimentara. Odata ce fereastra de congestie ajunge la jumatate din dimeniunea ferestrei avute inaintea aparitiei congestiei, TCP-ul intra intr-o faza de evitare a congestiei si incetineste rata de incrementare. In timpul fazei de evitare a congestiei, el creste dimensiunea ferestrei de congestie cu 1 doar daca toate segmentele din fereastra au fost confirmate.
Stabilirea unei conexiuni TCP
Ca sa stabileasca o conexiune, TCP-ul foloseste trei moduri handshake. Intr-un caz simplu, handshake-ul procedeaza dupa cum indica figura 45.
Primul segemnt al handshake poate fi identificat deoarece are setat bitul SYN din campul de cod. Al doilea mesaj are bitii SYN si ACK setati, indicand ca el confirma primul segment SYN precum si continuarea handshake-ului. Mesajul final este doar o confirmare si este folosit doar pentru informarea destinatiei ca ambele site-uri accepta ca acea conexiune sa fie stabilita.
De obicei, software-ul TCP de pe o masina asteapta pasiv initierea handshake-ului si software-ul TCP de pe cealalta masina il initiaza. In orice caz, handshake-ul este proiectat sa lucreze chiar daca ambele masini incearca sa initieze simultan o conexiune. Odata ce conexiunea a fost stabilita, datele pot calatori la fel de bine in ambele directii.
|
Evenimente la Mesajele din retea Evenimente la
Trimite SYN seq=x Receptie segment SYN Trimite SYN seq=y, ACK x+1 Receptie SYN + + segment ACK Expediere ACK y+1 Receptie segment ACK Figura 45 Secventa de mesaje pentru stabilirea unei conexiuni simple |
Acesti trei moduri handshake sunt deopotriva necesare si suficiente pentru o sincronizare intre doua puncte finale ale unei conexiuni. Pentru a intelege de ce, reamintim ca TCP-ul este un serviciu nesigur de distributie de pachete, astfel ca mesajele pot fi pierdute, intarziate, duplicate sau distribuite intr-o ordine oarecare. Astfel, protocolul trebuie sa foloseasca un mecanism cu timp de asteptare si retransmisie a cererilor pierdute. O problema apare daca retransmitem si cererea initiala, aceasta sosind in timp ce conexiunea de-abia a fost stabilita sau daca cererile retransmise sunt intarziate pana cand o conexiune a fost stabilita, folosita si terminata. Aceste trei moduri handshake (plus acea regula TCP ce ignora cererile suplimentare de conexiune dupa ce o conexiune a fost stabilita) rezolva aceste probleme.
Numerele secventei initiale
Aceste trei moduri handshake indeplinesc doua functii importante. Ele garanteaza ca ambele site-uri sunt gata pentru transferul de date (si ca ele cunosc ca sunt deopotriva pregatite) si permite ambelor site-uri sa accepte de numerele secventei initiale. Numerele secventei sunt trimise si confirmate in timpul handshake-ului. Fiecare masina trebuie sa aleaga un numar aleator pentru secventa initiala care va fi utilizat pentru pentru identificarea octetilor in fluxul trimis de el. Numerele de secventa nu pot porni intotdeauna de la aceeasi valoare. In particular, TCP-ul nu poate alege de fiecare data secventa 1 ori de cate ori creaza o conexiune. Desigur, este important ca ambele site-uri sa accepte un numar initial, asa incat numerele octetilor folositi in confirmari sa se inteleaga cu acelea folosite in segmentele de date.
Ca sa vedem cum doua masini pot accepta numerele de secventa pentru doua fluxuri doar dupa trei mesaje, reamintim ca fiecare segment contine deopotriva un camp pentru numarul secventei si un camp pentru confirmare. Masina care initiaza un handshake (A), paseaza numarul initial de secventa (x) in campul de secventa al primului segment SYN. A doua masina (B) receptioneaza primul segment SYN, inregistreaza numarul de secventa si raspunde prin trimiterea numarului sau initial de secventa (y) in campul de secventa precum si o confirmare care indica ca B asteapta octetul x+1. In mesajul final al handshake-ului, A confirma receptarea de la B a tuturor octetilor prin y. In toate cazurile, confirmarile urmaresc conventia utilizarii numarului urmatorului octet asteptat.
Am descris cum TCP-ul in mod normal, initiaza o conexiune utilizand trei moduri handshake, prin schimbul unor segmente ce contin o minima cantitate de informatii. Deoarece conceptia protocolului permite, este posibil sa trimiti date inainte odata cu numerele de secventei initiale, in segmentele handshake. In astfel de cazuri, software-ul TCP trebuie sa pastreze datele pana cand handshake-urile se termina. Odata ce o conexiune a fost stabilita, software-ul TCP poate elibera datele pastrate si sa le distribuie rapid programului care le asteapta.
Inchiderea conexiunii TCP
Doua programe care folosesc TCP-ul pentru comunicare pot incheia conversatia elegant folosind operatia close. Intern, TCP-ul foloseste un trei-moduri handshake modificate pentru a inchide conexiunea. Trebuie reamintit faptul ca TCP-ul este full-duplex. Cand un program de aplicatie indica ca nu mai are date de trimis, TCP-ul va inchide conexiunea intr-o directie. Ca sa inchida partea sa de conexiune, TCP-ul emitator termina transmiterea datelor ramase, asteapta confirmarea receptiei lor si apoi trimite un segment cu bitul FIN setat. TCP-ul receptor confirma segmentul FIN si informeaza programul de aplicatie ca celalalt capat nu mai are date disponibile.
Odata ce o conexiune a fost inchisa intr-o directie specificata. TCP-ul nu va mai accepta date din acea directie. Intre timp, datele pot continua sa circula in directia opusa pana cand emitatorul o va inchide. Desigur, confirmarile continua sa soseasca la emitator chiar daca conexiunea inversa (receptor-emitator) a fost inchisa. Cand ambele cai au fost inchise, software-ul TCP de la fiecare punct final sterge inregistrarile sale pentru acea conexiune.
Detaliile inchiderii unei conexiuni sunt chiar mai subtile ca cele sugetate mai inainte deoarece TCP-ul foloseste un algoritm modificat ca sa inchida o conexiune. Figura 46 prezinta procedura.
|
Evenimente la Mesajele din retea Evenimente la site-ul 1 site-ul 2 (aplicatia inchide conexiunea)
Trimite FIN seq=x Receptie segment FIN Trimite ACK x+1 (informarea aplicatiei) Receptie segmen ACK (aplicatia inchide conexiunea) Trimite FIN seq=y ACK x+1 Receptie FIN+ +segment ACK Trimite ACK y+1 Receptie segmen ACK Figura 46 Secventa de mesaje folosita pentru inchiderea unei conexiuni |
Diferenta dintre algoritmul folosit la stabilirea conexiunii si cel care o intrerupe, apare dupa ce o masina receptioneaza sementul FIN initial. In loc sa genereze imediat un al doilea segment FIN, TCP-ul trimite o confirmare si apoi informeaza aplicatia de cererea de intrerupere. Informarea programului de aplicatie de cererea de intrerupere si obtinerea unui raspuns pot lua un timp destul de mare (deoarece poate implica o actiune cu utilizatorul). Confirmarea previne retransmiterea segmentului FIN initial in timpul asteptarii. In final, cand programul de aplicatie pregateste TCP-ul pentru oprirea completa a conexiunii, TCP-ul trimite un al doilea segment FIN si site-ul original raspunde cu un mesaj de confirmare (ACK).
Resetarea conexiunii TCP
In mod normal, un program de aplicatie foloseste instructiunea close pentru a inchide o conexiune dupa ce termina folosirea ei. Uneori, pot apare si situatii anormale care sa forteze programul de aplicatie sau un software de retea sa intrerupa o conexiune. TCP-ul furnizeaza o facilitate de reset pentru asemenea deconectari anormale.
Ca sa reseteze o conexuine, unul dintre site-uri initiaza terminarea prin trimiterea unui segment cu bitul RST din campul CODE setat. Celalalt site raspunde imediat la segmentul de reset prin inchiderea conexiunii. TCP-ul informeaza deasemenea programul de aplicatie ca a aptur un reset. Un reset este o inchidere instantanee avand ca rezultat incetarea transferului in ambele directii; resursele si bufferele sunt totodata eliberate.
Fortarea distributiei datelor
Am afirmat anterior ca TCP aste liber sa divida fluxul de date in segmente pentru transmisie fara a avea importanta dimensiunea cu care sunt transferate datele de catre programul de aplicatie. TCP-ul face aceasta diviziune din motive de eficienta. Astfel, el poate strange intr-un buffer suficienti octeti pentru a obtine un segment suficient de lung prevenind supraincarcarea retelei ca apare cand segmentele contin doar cativa octeti.
Consideram o conexiune TCP folosita pentru transferul caracterelor de la un terminal interactiv la o masina indepartata. Utilizatorul solicita un raspuns instantaneu la fiecare apasare de taste. Daca el trimite date bufferului TCP, raspunsul poate fi intarziat, pentru a se aduna poate 0 suta de apasari de aste. Similar, deoarece TCP-ul receptor buffereaza datele inainte ca el sa le faca disponibile pentru programul sau de aplicatie, o fortare a emitatorului sa trimita date poate nu va fi suficienta pentru a garanta rapiditatatea distributiei.
Ca sa se acomodeze cu utilizatorii interactivi, TCP-ul furnizeaza o operatie push pe care un program de aplicatie poate sa-l foloseasca pentru a forta distribuitia octetilor curenti din flux fara a astepta umplerea bufferului. Aceasta operatie nu face altceva decat sa forteze TCP-ul sa transmita un segment. TCP-ul trebuie sa seteze bitul PSH din campul de cod al segmentului si apoi il va distribui catre programul de aplicatie de la celalalt capat. In acest fel, cand se transmit date de la un terminal interactiv, aplicatia foloseste functia push pentru a trimite fiecare apasare de taste. Similar, programele de aplicatie pot forta ca un rezultat sa fie trimis si afisat rapid la un terminal prin apelarea functiei push dupa scrierea unui caracter sau a unei linii.
Numere de port TCP rezervate
Similar cu UDP-ul, TCP-ul combina asocierea de porturi dinamica cu cea statica, folosind porturile de asignare rezervate pentru programe de larga raspandire (cum ar fi de pilda posta electronica) dar lasand majoritatea numerelor de port disponibile alocarii lor de catre sistemul de operare pentru programele de aplicatie. Desi standardul original rezerva numarele de port mai mici ca 256 pentru porturile foarte cunoscute, numerele mai mari ca 1024 nu au fost inca asignate. Cu toate ca numerele de port UDP si TCP sunt independente, proiectantii au ales sa foloseasca aceleasi numere de port pentru acele servicii ce sunt accesibile atat prin UDP cat si prin TCP. Anexa B listeaza cateva din numerele de port TCP. De exemplu, numele serverului de domeniu poate fi accesat fie cu TCP-ul fie cu UDP-ul. In fiecare protocol numarul 53 a fost rezervat pentru serverele din sistemul numelui de domeniul.
Sindromul "silly window" si pachetele mici
Probleme serioase apar cand aplicatiile receptoare si emitoare functioneaza la viteze diferite. Ca sa intelegem problema reamiontim ca TCP-ul buffereaza datele, si sa vedem ce se intampla daca aplicatia receptoare alege sa citeasca datele sosite cu viteva de un octet la un moment de timp. Cand o conexiune este prima data stabilita, TCP-ul receptor aloca un buffer de K octeti si foloseste campul WINDOW din segmentele de confirmare pentru a avertiza emitatorul de dimensiunea bufferului sau. Daca programul de aplicatie genereaza rapid datele, TCP-ul va transmite segmentul de date avand o dimensiune egala cu dimensiunea maxima a ferestrei. Eventual emitatorul poate receptiona o confirmare care indica ca intregul continut al ferestrei a fost receptionat dar bufferul nu mai are spatiu suplimentar.
Cand aplicatia receptoare citeste un octet de date din buffer, un octet din spatiul bufferului va deveni liber. Deoarece TCP-ul de pe masina receptoare genereaza o confirmare care foloseste campul WINDOW pentru a informa emitatorul ca a fost eliberat spatiu in bufferul sau, receptorul va anunta in cazul nostru o fereastra de un octet. In consecinta TCP-ul emitator va raspunde prin trimiterea unui segment care contine un singur octet de date.
Desi fereastra de avertisment de un octet lucreaza corect (pentru a pastra bufferul plin) rezultatul va fi o serie de segmente mici de date. TCP-ul emitator trebuie sa formeze un segment ce contine un singur octet de date plasandu-l intr-o datagrama IP. Cand aplicatia receptoare citeste un alt octet, TCP-ul va genera o alta confirmare ce va determina emitatorul sa trimita un alt segment care sa contina doar un octet de date. Rezultatul acestei interactiuni poate fi o stare stabila in care TCP-ul trimite cate un singur segment pentru fiecare octet de date.
Un astfel de tip de transfer ocupa inutil din largimea de banda a retelei deoarece fiecare datagrama contine doar un octet de date generand si o supraincarcare inutila cu calcul intrucat atat emitatorul cat si receptorul trebuie sa proceseze fiecare segment (cu tot ceea ce implica: incapsulare, verificarea sumei de control, examinarea numarului de secventa, etc).
Am vazut cum o mica fereastra disponibila determina segmente mici, emitatorul fiind obligat sa trimita segmente se contin doar mici cantitati de date. Sa ne imaginam o implementare TCP agresiva, care trimite date ori de cate ori exista spatiu disponibil in bufferul receptorului, si sa vedem ce se intampla daca o aplicatie genereaza un singur octet de date la un moment de timp. Dupa ce genereaza un octet de date, TCP-ul creaza si transmite un segment. Deasemenea, TCP-ul poate sa trimita un mic segment daca o aplicatie genereaza date in blocuri de dimensiune fixa formate din B octeti, iar TCP-ul emitator extrage date din buffer in blocuri avand dimensiunea maxima a unui segment (M), unde M B, deoarece ultimul bloc din buffer poate fi mai mic.
Cunoscut sub numele de sindromul "silly window" (SDS), problema prezentata chinuie implementarile TCP. Ea poate fi sitetizata astfel:
Implementarile initiale ale TCP-ului prezinta o problema cunoscuta sub numele de sindromul "silly window" in care ficare confirmare anunta un mic spatiu disponibil si fiecare segment trasporta o mica cantitate de date.
Evitare aparitiei sindromului "silly window"
Specificatiile actuale ale TCP-ului includ metode heuristice de prevenire a sindromului "silly window". Una se foloseste pe masina emitatoare pentru a evita transmiterea unor cantitati mici de date in fiecare segment in timp ce alta se foloseste pe masina receptoare pentru a evita transmiterea de valori mici prin fereastra de avertisment ceea ce ar detrmina transmiterea de pachete mici de date. Metodele lucreza bine impreuna, asa ca este bine ca atat receptorul cat si emitatorul sa aiba o implementare care ca ajute la evitarea aparitiei sindromului deoarece oricand este posibil ca una dintre masini sa greseasca implementarea corecta a metodei avand ca rezultat compromiterea performantelor.
In practica, software-ul TCP de pe ambele masini (receptoare si emitatoare) trebuie sa contina un cod de evitare a sindromului. Ca sa intelegem de ce, reamintim ca o conexiune TCP este full-duplex. Astfel, o implementare a TCP-ului contine un cod pentru trimiterea datelor precum si un cod pentru receptia lor.
Evitarea sindromului de catre partea receptoare
In general, un receptor intretine o inregistrare interne a dimensiunii ferestrei disponibile, dar intarzierile indica pentru emitator necesitate unei crestere in dimensiunea ferestrei pana cand fereastra poate injecta o cantitate de date mai mare. Definitia "cantitatii importante" depinde de dimensiunea maxima a segmentului. TCP-ul o defineste ca fiind minim o jumatate din dimensiunea bufferului receptorului sau numarul octetilor de date dintr-un segment de dimensiune maxima.
Masina receptoare previne aparitia sindromului impiedicand anuntul unei ferestre de dimeniuni mici in cazul in care aplicatia receptoare extrege incet octetii de datde. De exemplu, cand un buffer receptor este plin, el trimite o confirmare ce indica o fereastra de dimensiune zero. Aplicatia receptoare extrage octetii din buffer iar TCP-ul receptor calculeaza spatiul de curand disponibilizat in buffer. In loc sa trimita imediat o fereastra de avertisment, receptorul asteapta pana cend spatiul disponibil ajunge la jumatate din capacitatea intregului buffer sau la dimensiunea maxima a unui segment. Astfel, emitatorul receptioneaza intotdeauna o valoare mare pentru fereastra curenta, permitandu-i sa transfere segmente mari. Metoda poate fi sintetizata astfel:
Evitarea sindromului "silly window" de catre partea receptoare: Inainte sa trimiti o fereastra de avertizare modificata dupa anuntarea unei ferestre de dimensiune zero, asteapta ca spatiul disponibil sa devina cel putin egal cu 50% din dimesiunea totala a bufferului sau cu dimensiunea maxima a segmentului.
Intarzierea confirmarilor
Doua metode de abordare pot fi prezentate pentru implementarea metodei de evitare a sindromului de catre partea receptoare. In prima, TCP-ul confirma fiecare segment care vine, dar nu anunta o crestere a ferestrei sale pana cand fereastra atinge limita specificata prin metoda heuristica. In a doua abordare, TCP-ul intarzie trimiterea unei confirmari cand metoda indica ca fereastra nu este suficient de mare pentru a fi anuntata. Standardele recomanda intarzierea confirmarilor
Pentru evitarea potentialelor probleme, standardele TCP introduc o limita pentru timpul cat poate fi intarziata o confirmare. Astfel, implementarile nu pot intarzia o confirmare mai mult de 500 ms. Mai mult ca sa garanteze acelui TCP receptionarea unui numar suficient de estimari de timp complet de calatorie, standardul recomanda acelui receptor sa confirme obligatoriu fiecare segment diferit de date.
Evitarea sindromului de catre partea emitatoare
Metoda folosita de TCP-ul emitator pentru evitarea aparitiei sindromului este deopotriva surprinzatoare si eleganta. Reamintim ca scopul este evitarea trimiterii pachetelor mici. Totodata reamintim ca aplicatia emitatoare poate genera date in mici blocuri (de exemplu un octet la un moment de timp). Astfel, pentru a atinge scopul, un TCP emitator trebuie sa permita aplicatiei sa faca apeluri multiple de tip write si sa colecteze data tranferata prin fiecare apel inainte de a le trimite intr-un singur segment de dimensiune mare. Deci, TCP-ul emitator trebuie sa intarzie transmiterea unui segment pana cand el strange o cantitate rezonabila de date, tehnica cunoscuta sub numele de clumping.
Intrebarea care apare este: "Cat de mult trebuie sa astepte TCP-ul inainte sa trimita datele?" Daca TCP-ul asteapta prea mult aplicatia va functiona cu mari intarzieri, iar daca nu asteapta un timp suficient de lung, segmentele vor fi mici si productivitatea scazuta. Mai mult, TCP-ul nu stie daca sa astepte deoarece nu stie daca aplicatia ca genera mai multe date in viitorul apropiat.
Ca si algoritmul TCP folosit pentru retransmisie si algoritmul de pornire usoara folosit pentru evitarea congestiei, tehnica folosita de TCP pentru a evita transmiterea pachetelor mici este adaptiva - intarzierea depinde de performantele curente ale retelei. Mecanismul de evitare a sindromului folosit de catre partea emitatoare este numit self clocking deoarece el nu face calculul intarzierilor. In schimb, TCP-ul foloseste sosirea unei confirmari pentru a cere transmiterea unor pachete suplimentare. Metoda poate fi sintetizata astfel:
Evitarea sindromului de catre partea emitatoare: Cand o aplicatie emitatoare genereaza date suplimentare pentru a fi trimise printr-o conexiune prin care datele anterioare au fost transmise dar n-au fost confirmate, pune datele intr-un buffer de iesire ca de obicei, dar nu trimite segmentele suplimentare pana cand nu sunt sufieciente date pentru a completa un segment de dimensiune maxima. Aplica regula chiar daca utilizatorul cere o operatie de tip push.
Daca aplicatia genereaza un octet de date la un moment, TCP-ul va trimite primul octet imediat. In orice caz, pana cand va sosi ACK, TCP-ul va acumula octeti suplimentari in bufferul sau. Astfel, daca aplicatia este mai rapida ca reteaua (cum ar fi de pilda transferul unui fisier), segmente succesive vor contine fiecare multi octeti. Daca aplicatia este mai lenta in comparatie cu reteaua (cum ar fi de pilda un utilizator ce trimite caractere de la tastatura), mici segmente vor fi trimise fara mari intarzieri.
Cunoscut sub numele de algoritmul lui Nagle dupa numele inventatorului sau, tehnica este foarte eleganta deoarece necesita un efort de calcul mic. O gazda nu doreste sa pastreze timere pentru fiecare conexiune si nici sa examineze un ceas cand o aplicatie genereaza date. Mult mai important este faptul ca, desi tehnica se adapteaza la combinatii arbitrare ale intarzierilor retelei, dimensiunilor maxime de segmente si vitezei aplicatiilor el nu face o scadere a productivitatii in cazurile conventionale.
Ca sa intelegem de ce productivitatea ramane mare pentru comunicatiile conventionale, observam ca aplicatiile optimizate pentru productivitate mare nu genereaza un octet de date la un moment de timp. In schimb, asemenea aplicatii scriu blocuri mari de date la fiecare apel. Astfel, bufferul de iesire TCP va fi umplut de la inceput cu date suficiente pentru cel putin un segment de dimensiune maxima. Mai mult, deoarece aplicatia produce date mai rapid decat TCP-ul poate tranfera, bufferul emitatorului ramane aproape plin in permanenta. Ca urmare, TCP-ul continua sa trimita pachete la orice rata pe care reteaua o permite in timp ce aplicatia continua sa incarce bufferul. Ca sa concluzionam:
TCP-ul cere acum receptorului si emitatorului sa implenteze metode heuristice pentru a evita sindromul "silly window". Un receptor evita anuntarea unei ferestre mici si un emitator foloseste o schema adaptiva pentru a intarzia transmisia astfel incat el poate strange date pentru a forma segemente de dimensiune mare.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 2363
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2026 . All rights reserved