| CATEGORII DOCUMENTE |
| Asp | Autocad | C | Dot net | Excel | Fox pro | Html | Java |
| Linux | Mathcad | Photoshop | Php | Sql | Visual studio | Windows | Xml |
Many programming technologies and environments define their own unique models for scoping the execution of code and the ownership of resources. For an operating system, the model is based on processes. For the Java VM, it is based on class loaders. For Internet Information Services (IIS) and Active Server Pages (ASP), the scoping model is based on a virtual directory. For the CLR, the fundamental scope is an AppDomain, which is the focus of this chapter.
AppDomains fill many of the same roles filled by an operating system process. AppDomains, like processes, scope the execution of code. AppDomains, like processes, provide a degree of fault isolation. AppDomains, like processes, provide a degree of security isolation. AppDomains, like processes, own resources on behalf of the programs they execute. In general, most of what you may know about an operating system process probably applies to AppDomains.
AppDomains are strikingly similar to processes, but they are ultimately two different things. A process is an abstraction created by your operating system. An AppDomain is an abstraction created by the CLR. Whereas a given AppDomain resides in exactly one OS process, a given OS process can host multiple AppDomains. Figure 8.1 shows this relationship.
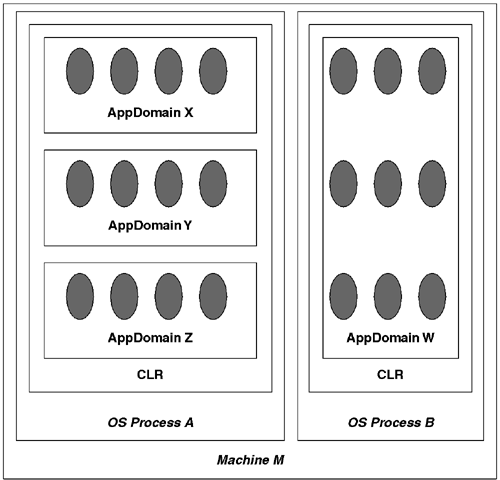
It is less costly to create an AppDomain than it is to create an OS process. Similarly, it is cheaper to cross AppDomain boundaries than it is to cross OS process boundaries. However, as is the case with OS processes, it is difficult (but not impossible) to share data between AppDomains. One reason that sharing is difficult is due to the way that objects and AppDomains relate.
An object resides in exactly one AppDomain, as do values. Moreover, object references must refer to objects in the same AppDomain. In this respect, AppDomains behave as if each one has its own private address space. However, this behavior is only an illusion because all it takes is an unverifiable method to start walking over memory to shatter this illusion. If only verifiable code is executed, then this illusion is in fact the rule of the land. The ability of nonverifiable code to shatter the illusion of the CLR AppDomain is analogous to kernel-mode code's ability to shatter the illusion of an OS process.
Like objects, types reside in exactly one AppDomain. If two AppDomains need to use a type, one must initialize and allocate the type once per AppDomain. Additionally, one must load and initialize the type's module and assembly once for each AppDomain the type is used in. Because each AppDomain in a process maintains a separate copy of the type, each AppDomain has its own private copy of the type's static fields. Figure 8.2 shows the relationship among AppDomains, objects, and types.
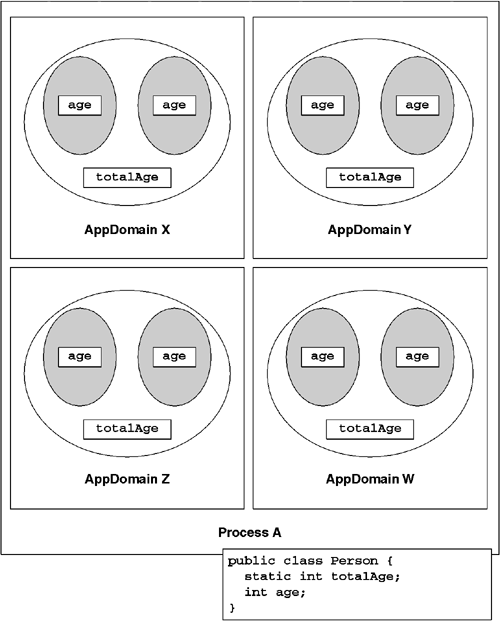
Like processes, AppDomains are a unit of ownership. The resources that are owned by an AppDomain include loaded modules, assemblies, and types. These resources are held in memory as long as the owning AppDomain is loaded. Unloading an AppDomain is the only way to unload a module or assembly. Unloading an AppDomain is also the only way to reclaim the memory consumed by a type's static fields.
It is difficult to talk about processes without quickly steering the conversation to the topic of threads. The CLR has its own abstraction for modeling the execution of code that is conceptually similar to an OS thread. The CLR defines a type, System.Threading.Thread, that represents a schedulable entity in an AppDomain. A System.Threading.Thread thread object is sometimes referred to as a soft thread because it is a construct that is not recognized by the underlying operating system. In contrast, OS threads are referred to as hard threads because they are what the OS deals with.
There is no one-to-one relationship between hard threads and CLR soft thread objects. However, certain realities are known to be true based both on the programming model and empirical analysis of the current CLR implementation. For one thing, a CLR soft thread object resides in exactly one AppDomain. This is a byproduct of how AppDomains work and what they mean and must be true no matter how the CLR's implementation changes over time. Second, a given AppDomain may have multiple soft thread objects. In the current implementation, this happens when two or more hard threads execute code in a single AppDomain. All other assumptions about the relationship between hard and soft threads are implementation-specific. With that disclaimer in place, there are a few other observations worth noting.
In the current implementation of the CLR, a given hard thread will have at most one soft thread object affiliated with it for a given AppDomain. Also, if a hard thread winds up executing code in multiple AppDomains, each AppDomain will have a distinct soft thread object affiliated with that thread. However, if a hard thread never enters a given AppDomain, then that AppDomain will not have a soft thread object that represents the hard thread. Figure 8.3 illustrates these observations.
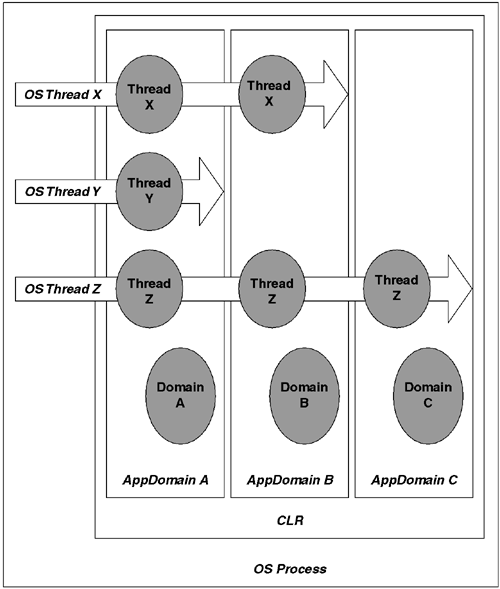
Finally, each time a given hard thread enters an AppDomain, it gets the same soft thread object. Again, please note that these observations are based on the behavior of the current CLR implementation. In particular, when the CLR is hosted in a fiber-based environment (such as SQL Server), it is likely that one or more of these assumptions may break, most likely the assumption that a hard thread has at most one soft thread object per AppDomain.
The CLR maintains a fair amount of information in the hard thread's thread local storage (TLS). In particular, one can find hard TLS references to the current AppDomain and soft thread object. When a hard thread crosses over from one AppDomain to another, the CLR automatically adjusts these references to point to the new 'current' AppDomain and soft thread. The current implementation of the CLR maintains a per-AppDomain thread table to ensure that a given hard thread is affiliated with only one soft thread object per AppDomain.
It is worth noting that a soft thread object has its own private thread local storage that is accessible via the Thread.GetData and Thread.SetData methods. Because this TLS is bound to the soft thread object, when a hard thread crosses AppDomain boundaries, it cannot see the soft TLS that was stored while the hard thread was executing in the previous AppDomain.
One exposes AppDomains to programmers via the System.AppDomain type. Listing 8.1 shows a subset of the public signature of System.AppDomain. The most important member of this type is the CurrentDomain static property. This property simply fetches the AppDomain reference that is stored in the hard thread's TLS. As a point of interest, one can extract the current soft thread object from the hard thread's TLS via the Thread.CurrentThread property.
After you have a reference to an AppDomain, there are a variety of things you can do with it. For one thing, each AppDomain has its own set of environmental properties that is accessible via the SetData and GetData methods. These properties act like the environment variables of an OS process, but, unlike process environment variables, these properties are scoped to a particular AppDomain. These properties are functionally equivalent to static fields; however, unlike static fields, they are not duplicated per assembly or assembly version, and that makes them a handy replacement for static fields in side-by-side versioning scenarios.
One can create and destroy AppDomains programmatically. Although this is normally done by hosting environments such as ASP.NET, your application can access these same facilities to spawn new AppDomains. The AppDomain.CreateDomain method creates a new AppDomain in the current process and returns a reference to the new domain. The domain will remain in memory until a call to AppDomain.Unload causes it to be removed from memory. After you have created an AppDomain, you can force it to load and execute code using a variety of techniques. The most direct way to do this is to use the AppDomain.ExecuteAssembly method.
AppDomain.ExecuteAssembly causes the target AppDomain to load an assembly and execute its main entry point. ExecuteAssembly will not load or initialize the specified assembly in the parent AppDomain; rather,ExecuteAssembly will first switch AppDomains to the child domain and will load and execute the code while running in the child domain. If the specified assembly calls AppDomain.CurrentDomain, it will get the child AppDomain object. If the specified assembly uses any of the same assemblies as the parent program, the child AppDomain will load its own independent copies of the types and modules, including its own set of static fields.
Listing 8.2 shows an example of the ExecuteAssembly method in action. ExecuteAssembly is a synchronous routine. That means that the caller is blocked until the child program's Main method returns control to the runtime. One can use the asynchronous method invocation mechanism discussed in Chapter 6 if nonblocking execution is desired.
It is also possible to inject arbitrary code into an AppDomain. The AppDomain.DoCallBack method allows you to specify a method on a type that will be executed in the foreign domain. The specified method should be static and should have a signature that matches the CrossAppDomainDelegate's signature. Additionally, one will have to load the specified method's type, module, and assembly in the foreign AppDomain in order to execute the code. If the specified method needs to share information between the AppDomains, it can use the SetData and GetData methods on the foreign AppDomain. Listing 8.3 shows an example of this technique.
The AppDomain type supports a handful of events that allow interested parties to be notified of significant conditions in a running program. Table 8.1 lists these events. Four of these events are related to the assembly resolver and loader. Three of these events are related to terminal conditions in the process. DomainUnload is called just prior to the unloading of an AppDomain. ProcessExit is called just prior to the termination of the CLR in a process. UnhandledException acts as the last-chance exception handler to deal with threads that do not handle their own exceptions.
The runtime eventually handles unhandled exceptions. If the thread that caused the exception to be raised does not have a corresponding exception handler on the stack, then the CLR invokes its own global exception handler. This global exception handler is a last chance for the application to recover from the error. It is not good design to rely on the global exception handler, if for no other reason than the offending thread is long gone and very little execution scope may be left to recover.
Table 8.1. AppDomain Events |
||
|
Event Name |
EventArg Properties |
Description |
|
AssemblyLoad |
Assembly LoadedAssembly |
Assembly has just been successfully loaded |
|
AssemblyResolve |
string Name |
Assembly reference cannot be resolved |
|
TypeResolve |
string Name |
Type reference cannot be resolved |
|
ResourceResolve |
string Name |
Resource reference cannot be resolved |
|
DomainUnload |
None |
Domain is about to be unloaded |
|
ProcessExit |
None |
Process is about to shut down |
|
UnhandledException |
bool is Terminating, object ExceptionObject |
Exception escaped thread-specific handlers |
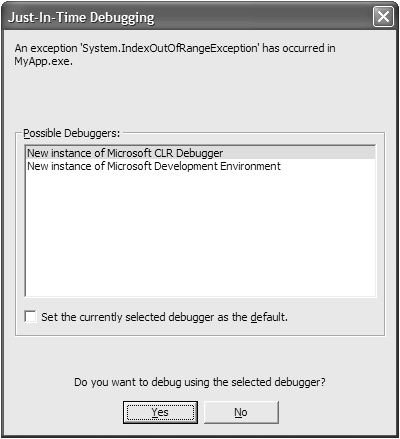
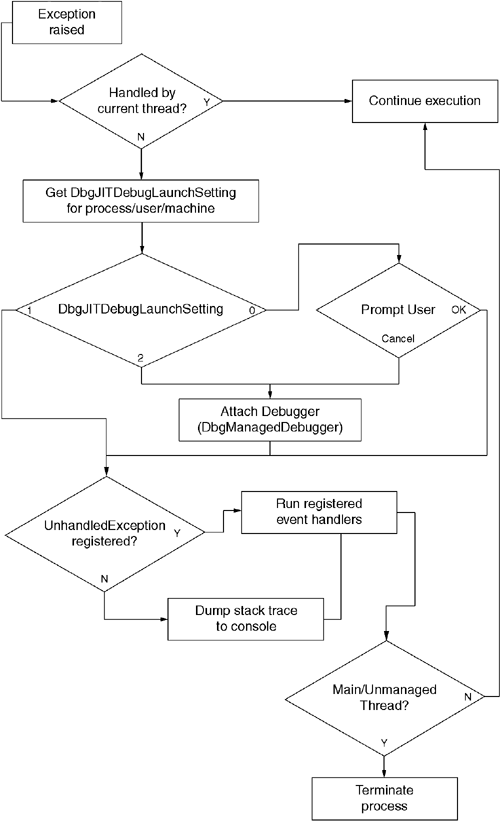
The CLR's global exception handler first checks a configuration setting to see whether a debugger needs to be attached. One can make this setting on a per-process, per-user, and per-machine basis. Under Windows NT, the CLR picks up the per-process setting from a process-wide environment variable (COMPLUS_DbgJITDebugLaunchSetting). For per-user and per-machine settings, the CLR reads the value from a registry key. As shown in Figure 8.4, the value of DbgJITDebugLaunchSetting is either 0, 1, or 2. If the DbgJITDebugLaunchSetting is 1, then the CLR will not attach a debugger. If the DbgJITDebugLaunchSetting is 2, then the CLR attaches the JIT debugger. The CLR reads the exact debugger that will be used from the registry. By default, the DbgManagedDebugger registry value points to VS7JIT.EXE, which starts by giving the user the choice of debuggers to use. Figure 8.5 shows the initial prompt of VS7JIT.EXE. If the DbgJITDebugLaunchSetting is 0, then the CLR will prompt the user to find out whether a debugger should be attached. Figure 8.6 shows this dialog box. If the user selects Cancel, then processing continues as if DbgJITDebugLaunchSetting were 2. If the user selects OK, then processing continues as if DbgJITDebugLaunchSetting were 1.

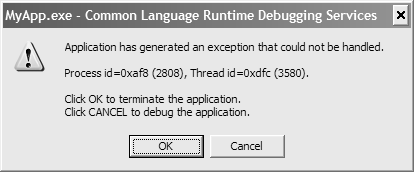
After the user has indicated the decision about attaching a debugger, the CLR then checks to see whether the application has registered an UnhandledException event handler. The exception handler must be registered from the default domain, which is the initial domain created by the CLR. Registering the event handler from child domains will have no effect.
Listing 8.4 shows the use of an UnhandledException event handler. The CLR will run our handler prior to terminating the process. Had no UnhandledException event handler been registered, then the stack dump from the exception would be printed to the console. Figure 8.7 shows the overall process of unhandled exception processing.
There are four AppDomain events related to assembly resolution and loading. One uses one of the events (AssemblyLoad) to notify interested parties when a new assembly has successfully been loaded. The assembly resolver uses the other three of these events when it cannot resolve a type (TypeResolve), assembly (AssemblyResolve), or manifest resource (ResourceResolve). For these three events, the CLR gives the event handler the opportunity to produce a System.Reflection.Assembly object that can be used to satisfy the request. It is important to note that the resolver calls these three methods only after it has gone through its standard techniques for finding the desired assembly. These events are useful primarily for implementing an application-specific 'last-chance' assembly resolver that uses some app-specific policy for converting the requested AssemblyName into a codebase that can be passed to Assembly.LoadFrom.
Listing 8.5 shows an example that uses the AssemblyResolve event to supply a backup policy for finding assemblies. In this example, the CLR munges the simple name of the requested assembly into an absolute pathname into the windowssystem32 directory. After the new pathname is constructed, the event handler uses the Assembly.LoadFrom method to pass control to the low-level loader.
AppDomains play a critical role in controlling the behavior of the assembly resolver. The AppDomain's properties control most of the assembly resolver's behavior. In fact, one stores the properties used by the assembly resolver in a single data structure of type AppDomainSetup, which is maintained on a per-AppDomain basis. The CLR exposes this data structure via the AppDomain.SetupInformation property.
Each AppDomain can have its own APPBASE and configuration file. By virtue of this fact, each AppDomain can have its own probe path and version policy. One can set the properties used by the assembly resolver either by using the AppDomain's AppDomainSetup property or by calling SetData and GetData with the right well-known property name. Listing 8.6 shows an example of three ways to access the same property.
Table 8.2 shows the properties of an AppDomain that are used by the assembly resolver. This table shows both the AppDomainSetup member name and the well-known name to use with AppDomain.SetData and GetData. Chapter 2 has already discussed several of the properties shown in this table. However, there are two sets of properties that have not yet been discussed. One set alters the probe path; the other set controls how code is actually loaded.
Recall that when an assembly is not found in the GAC or via a codebase hint, the assembly resolver looks in the probe path of the application. One sets this path using the probing element in the configuration file, and it is visible programmatically via the AppDomain.RelativeSearchPath. Also recall that this relative search path is in fact it cannot refer to directories that are not children of the APPBASE directory.
Now consider the case in which an application needs to generate code dynamically. If that code is to be stored on disk, then it is an open question as to where it should be stored. If the generated assembly is to be loaded via probing (something that is likely if the code is specific to the generating application), then the application must have write access to a directory underneath APPBASE. However, there are many scenarios in which it is desirable to execute an application from a read-only part of a file system (e.g., a secured server or CD-ROM), and this means that one must use some alternative location for dynamically generated code. This is the role of the AppDomain.DynamicDirectory property.
Table 8.2. AppDomain Environment Properties |
||
|
AppDomainSetup Property |
Get/SetData Name |
Description |
|
ApplicationBase |
APPBASE |
Base directory for probing |
|
ApplicationName |
APP_NAME |
Symbolic name of application |
|
ConfigurationFile |
APP_CONFIG_FILE |
Name of.config file |
|
DynamicBase |
DYNAMIC_BASE |
Root of codegen directory |
|
PrivateBinPath |
PRIVATE_BINPATH |
Semicolon-delimited list of subdirs |
|
PrivateBinPathProbe |
BINPATH_PROBE_ONLY |
Suppress probing at APPBASE ('*' or null) |
|
ShadowCopyFiles |
FORCE_CACHE_INSTALL |
Enable/disable shadow copy (Boolean) |
|
ShadowCopyDirectories |
SHADOW_COPY_DIRS |
Directories to shadow-copy from |
|
CachePath |
CACHE_BASE |
Directory th shadow-copy to |
|
LoaderOptimization |
LOADER_OPTIMIZATION |
JIT-compile per-process or per-domain |
|
DiablePublisherPolicy |
DISALLOW_APP |
Suppress component-supplied version policy |
|
AppDomain Property |
Description |
|
|
BaseDirectory |
Alias to AppDomainSetup.ApplicationBase |
|
|
RelativeSearchPath |
Alias to AppDomainSetup.PrivateBinPath |
|
|
DynamicDirectory |
Directory for dynamic assemblies (<DynamicBase>/<ApplicationName>) |
|
|
FriendlyName |
Name of AppDomain used in debugger |
|
Each AppDomain can have at most one dynamic directory. The CLR searches the dynamic directory during probing prior to looking in the probe path specified by the probing element in the configuration file. One derives the name of the dynamic directory is derived by catenating two other properties of the AppDomain: APP_NAME (a.k.a. AppDomainSetup.ApplicationName) and DYNAMIC_BASE (a.k.a. AppDomainSetup.DynamicBase). ASP.NET, which is one of the more notorious generators of code, uses this feature extensively. On the author's machine, the DYNAMIC_BASE property for the default virtual directory is currently
C:WINDOWSMicrosoft.NETFrameworkv1.0.3705The APP_NAME for the Web application running in the default virtual directory is currently
8d69a834This means that the resultant DynamicDirectory for that Web application is
C:WINDOWSMicrosoft.NETFrameworkv1.0.3705The CLR stores in this directory every DLL that the ASP.NET engine generates for that Web application. Because the CLR searches this directory as part of the probing process, DLLs found in that directory can be successfully loaded, despite the fact that they are not under the APPBASE for the AppDomain (which in this case is C:inetpubwwwroot). As a point of interest, ASP.NET sets the BINPATH_PROBE_ONLY property to suppress probing in the APPBASE directory itself. This is why you cannot simply put a DLL into your virtual directory and get ASP.NET to find it. Rather, ASP.NET sets the probe path to bin, which is where you must store any prebuilt DLLs used by an ASP.NET application.
The second set of AppDomain properties that warrant discussion relates to a feature known as shadow copying. Shadow copying addresses a common (and annoying) problem related to server-side development and deployment. Prior to.NET, developing and deploying DLLs that load into server-side container environments (e.g., IIS, COM+) was somewhat problematic because of the way the classic Win32 loader works. When the Win32 loader loads a DLL, it takes a read lock on the file to ensure that no changes are made to the underlying executable image. Unfortunately, this means that after a DLL is loaded into a server-side container, there is often no way to overwrite the DLL with a new version without first shutting down the container to release the file lock. Shadow copying solves this problem. When the CLR loads an assembly using shadow copying, a temporary copy of the underlying files is made in a scratch directory and the temporary copies are loaded in lieu of the 'real' assembly files. When shadow copying is enabled for an AppDomain, you must specify two directory paths: SHADOW_COPY_DIRS and CACHE_BASE. The SHADOW_COPY_DIRS path (a.k.a. AppDomainSetup.ShadowCopyDirectories) indicates the parent directories of the assemblies that you want to be shadow-copied. CACHE_BASE (a.k.a. AppDomainSetup.CachePath) indicates the root of the scratch directory where you want the assemblies to be copied to. As shown in Figure 8.8, the actual directory used is a mangled pathname beneath CACHE_BASE. To avoid collisions between applications, the pathname takes into account the APP_NAME.
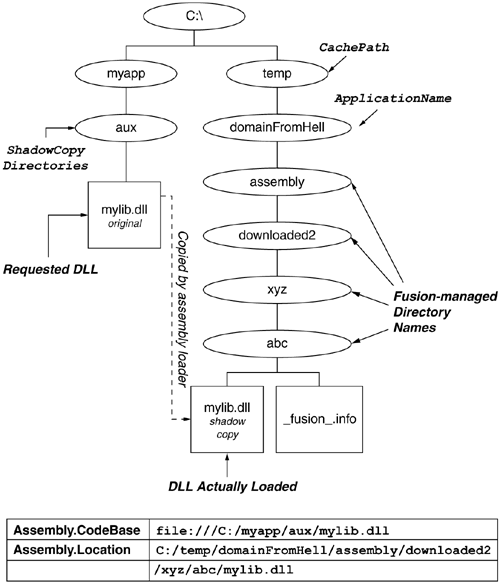
Again, ASP.NET is a heavy user of this feature, and that is appropriate given its status as the de facto server-side container for the CLR. On the author's machine, the SHADOW_COPY_DIRS property simply points to the Web application's bin directory (C:inetpubwwwrootbin, to be exact). The CACHE_BASE points to the same directory as the DYNAMIC_BASE property.
When one uses shadow copying, the assembly's CodeBase property will still match the original location of the assembly manifest. This is important for code-access security, which will be discussed in Chapter 9. To discover the actual path used to load the assembly, one can use the Assembly.Location property, as is shown in Figure 8.8.
Each AppDomain has its own private copy of a type's static data. An AppDomain may or may not need a private copy of the type's executable code, depending on any number of factors. To understand why this is the case, we first must look at how the CLR manages code.
AppDomains influence the way the JIT compiler works. In particular, the JIT compiler can generate code on either a per-process or a per-AppDomain basis. When all AppDomains in a process share machine code, the impact on the working set is reduced; however, raw invocation speed suffers slightly whenever a program accesses static fields of a type. In contrast, when the CLR generates machine code for each AppDomain, static field access is faster, but the working set impact is much greater. For that reason, the CLR allows the developer to control how JIT-compiled code is managed.
When the CLR first initializes an AppDomain, the CLR accepts a loader optimization flag (System.LoaderOptimization) that controls how code is JIT-compiled for modules loaded by that AppDomain. As shown in Table 8.3, this flag has three possible values.
The SingleDomain flag (the default) assumes that the process will contain only one AppDomain and therefore that the machine code should be JIT-compiled separately for each domain. This makes static field access faster, and, because only one AppDomain is expected, there is no impact on the working set because only one copy of the machine code will be required. Of course, if multiple AppDomains are created, each will get its own copy of the machine code, and that is why the MultiDomain flag exists.
The MultiDomain flag assumes that the process will contain several AppDomains running the same application and therefore that only one copy of the machine code should be generated for the entire process. This makes static field access slightly slower but significantly reduces the memory impact of having multiple AppDomains.
Figure 8.9 shows the effects of the loader optimization setting. This figure shows a simple C# type definition and the JIT-compiled IA-32 machine code that would be generated for each setting. Note that when one uses SingleDomain, the JIT compiler literally injects the addresses of the static fields (e.g., ds:[3E5110h]) into the native code stream. This is reasonable because each AppDomain will have its own copy of the method code, each with a different field address. When one uses the MultiDomain loader optimization, methods that access static fields have an additional prolog that calls the internal GetCurrentDomainData routine inside the CLR. This routine loads the base address of the AppDomain's static data from hard TLS. This extra step adds roughly 15 IA-32 instructions to every method that uses static fields. However, the code is generic, and only one copy needs to be in memory no matter how many AppDomains are in use.
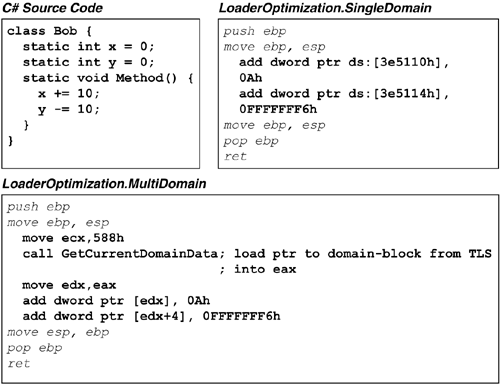
Table 8.3. LoaderOptimization Enumeration/Attribute |
|||||
|
Value |
Expected Domains in Process |
Each Domain Expected to Run |
Code for MSCORLIB |
Code for Assemblies in GAC |
Code for Assemblies not in GAC |
|
SingleDomain |
One |
N/A |
Per-process |
Per-domain |
Per-domain |
|
MultiDomain |
Many |
Same Program |
Per-process |
Per-process |
Per-process |
|
MultiDomainHost |
Many |
Different Programs |
Per-process |
Per-process |
Per-domain |
Clearly, there are costs and benefits to both loader optimization policies. For many applications, there is a compromise that yields the best of both worlds. That compromise is the MultiDomainHost flag.
The MultiDomainHost flag assumes that the process will contain several AppDomains, each of which will run different application code. In this hybrid mode, only assemblies loaded from the global assembly cache share machine code (a la MultiDomain). Assemblies not loaded from the GAC are assumed to be used only by the loading AppDomain and use private machine code for each AppDomain that loads them (a la SingleDomain).
It is important to note that no matter which loader optimization one uses, all AppDomains in a process always share the machine code for mscorlib. The LoaderOptimization has no impact on the way mscorlib is treated.
When mscoree
first initializes the runtime in an OS process, the host application can
specify which of the three loader optimization policies to use for the default
domain. For managed executables that the OS process loader loads directly
(e.g., CreateProcess under Windows NT), the main entry
point method (
As a point of interest, worker processes in ASP.NET use the MultiDomainHost option. In an ASP.NET worker process, the code from each (private) Web application directory uses the faster per-AppDomain code; but common code that all Web applications use (e.g., the data access and XML stacks) is JIT-compiled only once per process, reducing the size of the overall working set.
This chapter began by framing AppDomains as scopes of execution. A large part of that discussion was dedicated to portraying an AppDomain as a 'home' for objects and types. In particular, an object is scoped to a particular AppDomain, and object references can refer only to objects in the same AppDomain. However, there is a slight inconsistency in the AppDomain interface that has yet to be discussed. That slight inconsistency is the SetData and GetData mechanism.
Listing 8.3 showed an example of injecting code into a foreign AppDomain. In that example, the code used the SetData and GetData mechanism to pass the number of loaded assemblies from one AppDomain to another. When one reviews the signatures of the following two methods, however, it appears that one can store an object reference into a common property from one AppDomain and fetch (and use!) it from another.
static public void SetData(string name, object value);In fact, that is exactly what the code in Listing 8.3 did. One might ask how an object reference from one AppDomain can be smuggled into another domain given that object references are AppDomain-specific. The answer is marshaling.
The CLR scopes all objects, values, and object references to a particular AppDomain. When one needs to pass a reference or value to another AppDomain, one must first marshal it. Much of the CLR's marshaling infrastructure is in the System.Runtime.Remoting namespace. In particular, the type System.Runtime.Remoting.RemotingServices has two static methods that are fundamental to marshaling: Marshal and Unmarshal.
RemotingServices.Marshal takes an object reference of type System.Object and returns a serializable System.Runtime.RemotingServices.ObjRef object that can be passed in serialized form to other AppDomains. Upon receiving a serialized ObjRef, one can obtain a valid object reference using the RemotingServices.Unmarshal method. When calling AppDomain.SetData on a foreign AppDomain, the CLR calls RemotingServices.Marshal. Similarly, calling AppDomain.GetData on a foreign AppDomain returns a marshaled reference, which is converted via RemotingServices.Unmarshal just prior to the method's completion.
When one marshals an object reference, the concrete type of the object determines how marshaling will actually work. As shown in Table 8.4, there are three possible scenarios.
By default, types are remote-unaware and do not support cross-AppDomain marshaling. Attempts to marshal instances of a remote-unaware type will fail.
If a type derives from System.MarshalByRefObject either directly or indirectly, then it is AppDomain-bound. Instances of AppDomain-bound types will marshal by reference. This means that the CLR will give the receiver of the marshaled object (reference) a proxy that remotes (forwards) all member access back to the object's home AppDomain. Technically, the proxy remotes only access to instance members back to the object's home AppDomain. Proxies never remote static methods.
Types that do not derive from MarshalByRefObject but do support object serialization (indicated via the [System.Serializable] pseudo-custom attribute) are considered unbound to any AppDomain. Instances of unbound types will marshal by value. This means the CLR will give the receiver of the marshaled object (reference) a disconnected clone of the original object. Figure 8.10 shows all three behaviors.
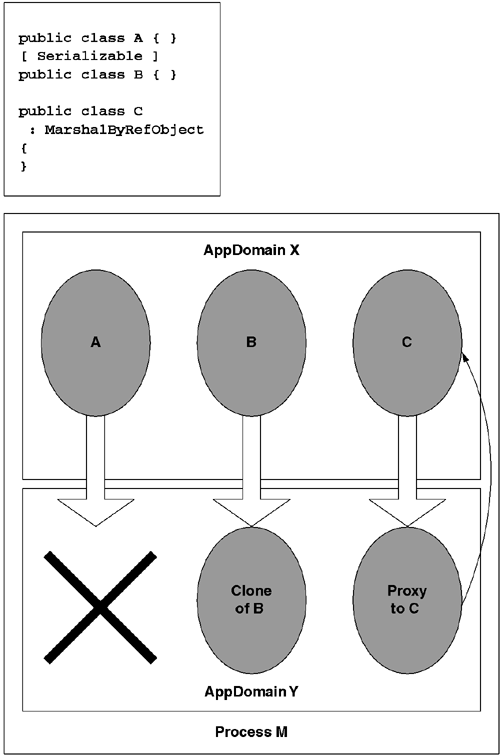
Table 8.4. Agility and Objects |
|||
|
Category |
AppDomain-Bound |
Unbound |
Remote-Unaware |
|
Applicable types |
Types derived from MarshalbyRefObject |
Types marked [Serializable ] |
All other types |
|
Cross-domain marshaling behavior |
Marshal-by-reference across AppDomain |
Marshal-by-value across AppDomain |
Cannot leave AppDomain |
|
Inlining behavior |
Inlining disabled to support proxy access |
Inlining enabled |
Inlining enabled |
|
Proxy behavior |
Cross-domain proxy Same-domain direct |
Never has a proxy |
Never has a proxy |
|
Cross-domain identity |
Has distributed identity |
No distributed identity |
No distributed identity |
Marshaling typically happens implicitly when a call is made to a cross-AppDomain proxy. The CLR marshals the input parameters to the method call into a serialized request message that the CLR sends to the target AppDomain. When the target AppDomain receives the serialized request, it first deserializes the message and pushes the parameters onto a new stack frame. After the CLR dispatches the method to the target object, the CLR then marshals the output parameters and return value into a serialized response message that the CLR sends back to the caller's AppDomain where the CLR unmarshals them and places them back on the caller's stack.
Figure 8.11 shows the cross-AppDomain remoting architecture. It is the job of the CrossAppDomainChannel to take the BLT-ed stack frame and serialize it into a buffer that is sent to the channel plumbing in the target AppDomain. The channel infrastructure in the target AppDomain deserializes the message and passes it onto the appropriate message sink, which will ultimately form the stack frame and invoke the method on the target object. Each AppDomain maintains an identity table that maps a unique identifier (called a URI) onto the appropriate message sink for the marshaled object. This URI appears in the marshaled object reference, and the proxy sets it in every outbound request message.
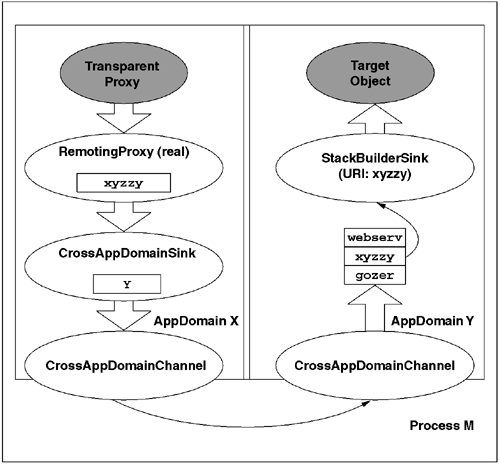
When one use cross-AppDomain proxies, it is important to note that the CLR must load in both AppDomains the metadata for all types used by the proxy. This means that both AppDomains must have access to the same assemblies. Moreover, when the two AppDomains reside on different machines, both machines must have access to the shared types' metadata.
For example, consider the following program, which creates an object in a child AppDomain:
using System;Because the proxy needs the metadata for Bob, both the child domain and the parent domain need access to the someassm assembly that contains Bob's metadata.
Observant readers may have noted the call to Unwrap in the previous example. The AppDomain.CreateInstance method does not return a normal object reference. Rather, it returns an object handle. Object handles are similar to marshaled object references. AppDomain.CreateInstance returns an object handle rather than a real object reference to avoid requiring metadata in the caller's AppDomain. For example, consider the following variation on the previous program:
using System;In this program, because the result of AppDomain.CreateInstance is never unwrapped in the parent domain, the CLR never needs to load the 'someassm' assembly in the parent. That is because the metadata is not needed until the call to Unwrap, which the CLR will perform only in the second child domain.
AppDomains scope types and objects at runtime. One uses AppDomains to model independent applications that may or may not share an OS process. AppDomains interact extensively with the assembly resolver and loader and support a fairly rich marshaling layer to support controlled interapplication communication
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1666
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved