| CATEGORII DOCUMENTE |
| Asp | Autocad | C | Dot net | Excel | Fox pro | Html | Java |
| Linux | Mathcad | Photoshop | Php | Sql | Visual studio | Windows | Xml |
Chapter 2 described how CLR-based programs are built out of one or more molecules called assemblies. Furthermore, these assemblies are themselves built out of one or more atoms called modules. This chapter attempts to split the atom of the module into subatomic particles called types. The focus of this chapter is the CLR's common type system (CTS), which transcends specific programming languages. However, to make the CTS real, one typically uses a programming language. To that end, this chapter illustrates CTS concepts and mechanisms through the lens of C#. That said the reader is encouraged not to get too enamoured with language syntax and instead focus on the core concepts of the CTS.
Types are the building block of every CLR program. Once developers decide how to partition a project into one or more assemblies, most of their time is spent thinking about how their types will work and how their types will interrelate. Programming languages such as C# and VB.NET may have several constructs for expressing types (e.g., classes, structs, enums, etc.), but ultimately all of these constructs map down to a CLR type definition.
A CLR type is a named, reusable abstraction. The description of a CLR type resides in the metadata of a CLR module. That module will also contain any CIL or native code required to make the type work. CLR type names have three parts: an assembly name, an optional namespace prefix, and a local name. One controls the assembly name by using the custom attributes described in Chapter 2. One controls the namespace prefix and the local name by using various programming language constructs. For example, the C# code shown in Listing 3.1 defines a type whose local name is Customer and whose namespace prefix is AcmeCorp.LOB. As discussed in Chapter 2, the namespace prefix often matches the name of the containing assembly, but this is simply a convention, not a hard requirement.
|
This chapter describes the common type system, which is much broader than most programming languages can handle. In addition to the CTS, the ECMA CLI submission carves out a subset of the CTS that all CLI-compliant languages are expected to support. This subset is called the Common Language Specification (CLS). Component writers are strongly encouraged to make their components' functionality accessible through CLS-compliant types and members. To that end, the CLI defines an attribute, System.CLSCompliant, that instructs compilers to enforce CLS compliance for all public members. The primary limitations of the CLS are the lack of support for unsigned integral types or pointers, and restrictions on how overloading may be used. |
A CLR type definition consists of zero or more members. The members of a type control how the type can be used as well as how the type works. Each member of a type has its own access modifier (e.g., public, internal) that controls access to the member. The accessible members of a type are often referred to collectively as the contract of the type.
In addition to controlling access to a given member, developers can control whether an instance of the type is needed to access the member. Most kinds of members can be defined as either per instance or per type. A per-instance member requires an instance of the type in order to access it. A per-type member does not have this requirement. In C# and VB.NET, members default to per instance. One can change this to per type using the static keyword in C# or the Shared keyword in VB.NET.
There are three fundamental kinds of type members: fields, methods, and nested types. A field is a named unit of storage that is affiliated with the declaring type. A method is a named operation that can be invoked and executed. A nested type is simply a second type that is defined as part of the implementation of the declaring type. All other type members (e.g., properties, events) are simply methods that have been augmented with additional metadata.
The fields of a type control how memory is allocated. The CLR uses the field declarations of a type to determine how much storage to allocate for the type. The CLR will allocate memory for static fields once: when the type is first loaded. The CLR will allocate memory for non-static (instance) fields each time it allocates an instance of the type. The CLR initializes all static fields to a default value upon allocation. For numeric types, the default value is zero. For Booleans, the default value is false. For object references, the default value is null. The CLR will also initialize the fields of heap-allocated instances to the default values just described.
The CLR guarantees the initial state of static fields and fields in heap-allocated instances. The CLR treats local variables allocated on the stack differently. By adding an attribute to its metadata, a given method can indicate that its local variables should be auto-initialized to their default values. Languages such as VB.NET add this attribute, so the CLR auto-initializes local variables in Visual Basic as part of the method prolog. The C# compiler also adds this attribute; however, C# requires local variables to be explicitly initialized. To avoid introducing security holes, the CLR's verifier requires that this attribute be present on verifiable methods.
To see an example of fields in use, consider the C# code in Listing 3.2. The comments next to the field declarations indicate the initial values that the CLR will use when allocating the memory for the fields. In the case of customerCount, the storage will be allocated and initialized once prior to the type's first use. In the case of all of the other fields, the storage will be allocated and initialized each time a new instance of AcmeCorp.LOB.Customer is allocated on the heap. This is illustrated in Figure 3.1. Note that in this example, there are multiple copies of the balance field, but only one copy of the customerCount field. To access the customerCount field, simply qualify the field name with the declaring type name, as follows:
AcmeCorp.LOB.Customer.customerCount = 3;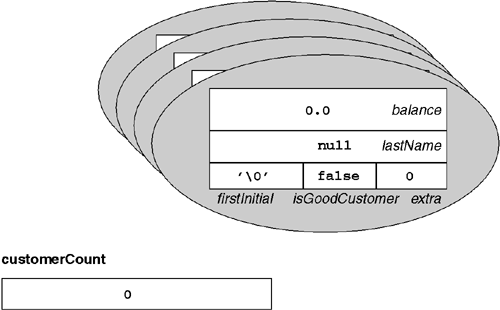
To access one of the instance fields, one needs a valid instance of the type:
AcmeCorp.LOB.Customer o = new AcmeCorp.LOB.Customer();Note that this example uses the C# new operator to allocate a new instance on the heap.
By default, the exact memory layout of a type is opaque. The CLR uses a virtualized layout scheme and will often reorder the fields to optimize memory access and usage, as in Figure 3.1. Note that the order of declaration was isGoodCustomer, lastName, balance, and extra, followed by firstInitial. If the CLR laid out the type's fields in order of declaration, it would have to insert a good deal of padding between fields in order to avoid unaligned access to individual fields-something that would kill performance. To avoid this, the CLR reorders the fields so that no packing is necessary. On the author's 32-bit IA-32 machine, that means that the following order is used: balance, lastName, firstInitial, and isGoodCustomer, followed by extra. This layout results in no wasted padding as well as perfectly aligned data. Be aware, however, that the exact layout policy used by the CLR is undocumented, and one should not rely on a specific policy for all versions of the CLR.
It is sometimes desirable to constrain a field to a constant value that cannot change for the lifetime of the field. The CLR supports two ways of declaring fields whose value is constant. The first technique-used for fields whose constant value can be calculated at compile time-is the most efficient: The field's static value is only stored as a literal in the metadata of the type's module, it is not a true field at runtime. Rather, compilers are required to inline away any access to literal fields, in essence embedding the literal value into the instruction stream. To declare a literal field in C#, one must use the const keyword. This will also require an initialization expression whose value can be calculated at compile time. The following is an example of such a field declaration:
public sealed class CustomerAny attempts to modify the field will be caught as compile-time errors.
The initial value of literal fields must be known at compile time. In the second technique, the CLR allows programmers to declare fields as immutable yet dynamically initializable by declaring a field initonly. Applying the initonly attribute to a field disallows modification of the field's value once the constructor has completed execution. To specify an initonly field in C#, one must use the readonly keyword. One can specify the initial value either by using an initialization expression or simply by assigning to the field inside the type's constructor method. In either case, the value used can take into account dynamic aspects of the program's execution state. The following shows the canonical example of an initonly field in C#:
public sealed class CustomerNote that this code dynamically generates the initial value of the created field based on the current time. That stated, once the value of created is set, one cannot change it after the new instance's constructor has completed execution.
Developers use the fields of a type to specify the state of an object. They specify an object's behavior using methods. Methods are named operations that are affiliated with a type. One can declare a method to return a typed value or to return no value. In C# and C++, one indicates the latter by using the void keyword as the return type. In VB.NET, one declares methods that return no value by using the Sub keyword; one defines methods that return a typed value by using the Function keyword.
As with fields, one can restrict access to methods using access modifiers such as private or public. As with fields, one can designate methods as per instance or per type (static). One can access a static method without an instance of the type. A non-static method requires an instance in order to be invoked (however, languages such as C++ allow a null reference to be used to invoke non-virtual, non-static methods). Consider the following type declaration:
namespace AcmeCorp.LOBThis type has four methods declared. Two of the methods (GetCount and ResetCount) are static and do not require an instance to invoke. One accesses these methods using the type name for qualification, as follows:
int c = AcmeCorp.LOB.Customer.GetCount();The other two methods (ClearStatus and GetExtraInfo) require a valid instance to invoke against:
AcmeCorp.LOB.Customer oSome programming languages (e.g., C++) allow programmers to invoke static methods using either an instance or the type name as a qualification. Other programming languages (e.g., C#) do not allow programmers to use the instance name when accessing static members. Consult the language reference for your language of choice.
In addition to returning a typed value, a method can also accept parameters. Method parameters act as additional local variables for the method body. One specifies the type and name of each parameter statically as part of the method declaration. The caller provides the value of each parameter dynamically at invocation time. By default, the method's parameters are independent copies of the values provided by the caller, and changes made to the parameter value inside the method body do not affect the caller. This parameter passing style is called pass-by-value. If only one copy of the parameter value is to be shared between the caller and callee (i.e., the method body), then one must explicitly declare the parameter as pass-by-reference using a programming language-specific construct. In VB.NET, one specifies the mode using either the ByVal or ByRef parameter modifier. In C#, the default is pass-by-value, and adding either the ref or the out parameter modifier changes the mode to pass-by-reference. Both keywords indicate pass-by-reference; the out keyword also indicates that the initial value of the parameter is undefined. This extra bit of information is useful both to the CLR verifier and to RPC-style marshaling engines.
Consider the C# type definition shown in Listing 3.3. In this example, the Recalc method accepts three parameters. The first parameter (initialBalance) is passed by value, and this means that the method body has its own private copy of the value. The other two parameters are declared as pass-by-reference, and this means that any changes the method body makes to the parameters will be reflected in the caller's version of the parameter. In the CheckJohnSmith method shown in this example, that means that the Recalc method can modify the two local variables current and sol. The local variable that was passed by value (initial), however, will not see any changes made in the Recalc method body.
In general, the number of parameters for a given method is fixed. To allow the usage characteristics of variable argument lists, the CLR allows the last parameter of a method to use the [System.ParamArrayAttribute] attribute. One can apply the ParamArrayAttribute only to the last parameter of a method, and one must declare the type of that parameter as an array type. As far as the CLR is concerned, the caller must provide the last parameter as the declared array type. That stated, the [System.ParamArrayAttribute]acts as a hint to compilers that the intended use is to support a variable number of arguments whose types match the element type of the array. In C#, the params keyword adds the [System.ParamArrayAttribute] attribute:
public sealed class DialerNotice that this example declares the DialEm method as having a ParamArray parameter, something that allows the caller (in this case, the CallFred method) to pass as many strings as it desires as if they were individual parameters. The callee (in this case, the DialEm method), however, sees that part of the parameter list as a single array.
The body of a method has unrestricted access to the declaring type's members. It also has unrestricted access to members of the declaring type's base type that are declared as protected or public. Most programming languages allow methods to access the members of the declaring type without explicit qualification, although explicit qualification is typically allowed. To qualify static member names, the type name can be used. To qualify instance member names, each language provides a keyword that corresponds to the instance used to invoke the method. In C# and C++, the keyword is this. In VB.NET, the keyword is the somewhat friendlier-sounding Me. In either case, this or Me is a valid expression whose type corresponds to the declaring type, thereby allowing programmers to pass this or Me as a parameter or assign it to a variable or field. Note, however, that static methods do not have a this or Me variable and cannot access non-static members without first acquiring a valid instance.
Many programming languages support the overloading of a method name to accept somewhat different lists of parameters. To support this feature, a CLR type can contain multiple method definitions that use the same name provided that the parameter list for each definition differs either in the count of the parameters or in the type of one or more of the parameters. The CLR allows you to overload based on return type; however, few languages support this and therefore it is prohibited by the CLS. The CLS does allow overloading based on pass-by-reference versus pass-by-value. However, you cannot overload based on the difference between the C# ref and out keywords because they are not part of the method signature proper. Rather, both ref and out simply indicate that the parameter is passed as a managed pointer (more on this in Chapter 10). The additional metadata attribute that distinguishes between ref and out is not part of the method signature but rather is an out-of-band hint regarding the intended usage of the parameter.
The CLR makes no attempt to prohibit overloads that may result in ambiguity. For example, if an overload is to be selected based on the type of a given parameter, it is possible that, via numeric promotion or type relationships (or both), multiple overloads might be legal. The CLR is happy to let you define such a type; that stated, not every compiler will use the same rules for selecting which overload to use for a given call site. Some compilers will use language-specific heuristics. Other compilers may simply give up and return a compile-time error. This is one reason (among many) why one should use overloading judiciously, especially when the language of the type's consumer cannot be known a priori.
The third and final kind of type member to look at is the nested type. A nested type is simply a type that is declared in the scope of another type. Nested types are typically used to build auxiliary helper objects (e.g., iterators, serializers) that support instances of the declaring type. Listing 3.4 shows an example of a nested type in C#.
Nested types have two fundamental advantages over 'top-level' types. For one thing, the name of the nested type is scoped by the surrounding type name, a practice that reduces namespace pollution. More importantly, one can protect access to a nested type using the same access modifiers used to protect fields and methods.
Unlike Java's inner classes, nested types in the CLR are always considered static members of the declaring type and are not affiliated with any particular instance. The name of the nested type is qualified by the surrounding type name. For purposes of CLR reflection, one uses a '+' to delimit the declaring type's name and the nested type's name. In the example shown in Listing 3.4, the CLR type name of the Helper type is AcmeCorp.LOB.Customer+Helper. That stated each programming language has its own delimiter characters. In C++, the delimiter is ' . In VB.NET and C#, the delimiter is '.', and this means that in this C#-based example, the Helper type can be referenced using the AcmeCorp.LOB.Customer.Helper symbol (note the period between Customer and Helper).
Perhaps the most important benefit of nested types is the way their methods relate to the members of the declaring type. Because a nested type is considered part of the implementation of the declaring type, the methods of a nested type are given special privileges. A nested type's methods have unrestricted access to the private members of the declaring type. The converse is not the case; the declaring type has no special access to members of the nested type. Note that in this example, the Helper.IncIt method can freely access the private nextid field of the declaring type. In contrast, the Customer.DoWork method cannot access the private incAmount field of the nested type.
Before we conclude the discussion of type members, there are two methods that bear special discussion. Types are allowed to provide a distinguished method that is called when the type is first initialized. This type initializer is simply a static method with a well-known name (.cctor). A type can have at most one type initializer, and it must take no parameters and return no value. Type initializers cannot be called directly; rather, they are called automatically by the CLR as part of the type's initialization. Each programming language provides its own syntax for defining a type initializer. In VB.NET, you simply write a Shared (per type) subroutine named New. In C#, you must write a static method whose name is the same as the declaring type name but has no return type. The following shows a type initializer in C#:
namespace AcmeCorp.LOBThis code is semantically equivalent to the following type definition, which uses a C# field initializer expression rather than an explicit type initializer:
namespace AcmeCorp.LOBIn both cases, the resultant CLR type will have a type initializer. In the former case, you can put arbitrary statements into the initializer. In the latter case, you can use only initializer expressions. In both cases, however, the resultant types will have identical .cctor methods, and the t field will be properly initialized prior to its access.
As a point of interest, it is legal for a single C# type to have both an explicit type initializer method and static field declarations with initializer expressions. When both are present, the resultant .cctor method will begin with the field initializers (in order of declaration), followed by the body of the explicit type initializer method. Consider the following C# type definition:
namespace AcmeCorp.LOBGiven this type definition, the fields will be initialized in the following order: t2, t3, t1.
The CLR is somewhat flexible with respect to when a type initializer will actually be run. Type initializers are always guaranteed to execute prior to the first access to a static field of the type. Beyond that guarantee, the CLR supports two policies. The default policy is to execute the type initializer at the first access to any member of the type, and not one moment earlier. A second policy (indicated by the beforefieldinit metadata attribute) gives the CLR more flexibility. Types marked beforefieldinit differ in two ways from those that are not so marked. For one thing, the CLR is free to aggressively call the type initializer before the first member access. Second, the CLR is free to postpone invocation of the type initializer until the first access to a static field. This means that calling a static method on a beforefieldinit type does not guarantee that the type initializer has run. It also means that instances can be created and used freely before the type initializer executes. That stated, the CLR guarantees that the type initializer will have executed before any method touches a static field.
The C# compiler sets the beforefieldinit attribute for all types that lack an explicit type initializer method. Types that do have an explicit type initializer method will not have this metadata attribute set. The presence of initializer expressions in static field declarations does not impact whether the C# compiler uses the beforefieldinit attribute.
The previous discussion looked at the distinguished method that the CLR invokes as part of type initialization. There is another distinguished method that the CLR will call automatically each time an instance of the type is allocated. This method is called a constructor and must have the distinguished name .ctor. Unlike the type initializer, a constructor can accept as many parameters as desired. Additionally, a type can provide multiple overloaded constructor methods using the same guidelines as method overloading. The constructor method that accepts no parameters is often called the default constructor of the type. To grant or deny access to individual members, constructor methods can use the same access modifiers used by fields and normal methods. This is in sharp contrast to the type initializer method, which is always private.
Each programming language provides its own syntax for writing constructors. In VB.NET, you write a (non-Shared) subroutine called New. In C# and C++, you write a (non-static) method whose name is the same as the declaring type name and returns no value. The following is an example of a C# type with two constructors:
namespace AcmeCorp.LOBThe C# compiler will inject any non-static field initialization expressions into the generated .ctor method before the explicit method body. In the case of the default constructor, the t2 and t3 initialization statements will precede the initialization of t1.
The C# compiler also supports chaining constructors by allowing one constructor to call another. The following type definition, which uses constructor chaining, is semantically identical to the previous example:
namespace AcmeCorp.LOBNote that the syntax for chaining constructors is language-specific. Consult the language reference for languages other than C#.
So far, the discussion of type has been largely structural, focusing on how a CLR type is held together. Issues of type semantics have largely been ignored. It is now time to look at how types convey semantics, starting with type categorization.
It is often desirable to partition types into categories based on common assumptions made by two or more types. Such categorization can serve as additional documentation for a type because only the types that explicitly declare affiliation with the category are known to share the assumptions implicit in that category. In the CLR, these categories of types are referred to as interfaces. Interfaces are type categories that are integrated into the type system. Because categories represented by interfaces are themselves types, one can declare fields (and variables and method parameters) simply to require category affiliation rather than hard-code the actual concrete type to be used. This looser requirement enables substitution of implementation, which is the cornerstone of polymorphism.
Structurally, an interface is just another type to the CLR. Interfaces have type names. Interfaces can have members, with the restriction that an interface cannot have instance fields nor instance methods with implementation. Structurally, all that really distinguishes an interface from any other type is the presence or absence of the interface attribute on the type's metadata. However, the semantics of the use of interfaces in the CLR are highly specialized.
Interfaces are abstract types that form categories or families of types. It is legal to declare variables, fields, and parameters of interface type. That stated, it is not legal to instantiate new objects based solely on an interface type. Rather, variables, fields, and parameters of interface type must refer to instances of concrete types that have explicitly declared compatibility with the interface.
The following example illustrates why interfaces are important.
public sealed class AmericanPersonIn this example, the Quack.OperateAndTransfuseBlood method accepts a single parameter of type System.Object. The type System.Object is the universal type in the CLR; this means that one can pass instances of any type as the parameter value. In this example, that means that one can legally pass instances of AmericanPerson, CanadianPerson, and Turnip to the method. However, given the method name, one might assume that there is little the method could do if a Turnip were to be passed. Because the parameter type does not discriminate against Turnips, this error will not be discovered until runtime.
The following example shows how interfaces solve this problem.
public interface IPatientIn this example, there is a category of types called IPatient. That category is declared as an interface. Types that are compatible with IPatient explicitly declare this compatibility as part of their type definition. Both AmericanPerson and CanadianPerson do exactly this. The OperateAndTransfuseBlood method now declares its parameter to disallow types that are not compatible with IPatient. Because the Turnip type did not declare compatibility with IPatient, attempts to pass Turnip objects to this method will fail at compile time. This solution is preferable to simply providing two explicit overloads of the method-one for AmericanPerson and one for CanadianPerson-because this approach lets one define new types that one can pass to the Doctor.OperateAndTransfuseBlood method without having to explicitly define new overloads.
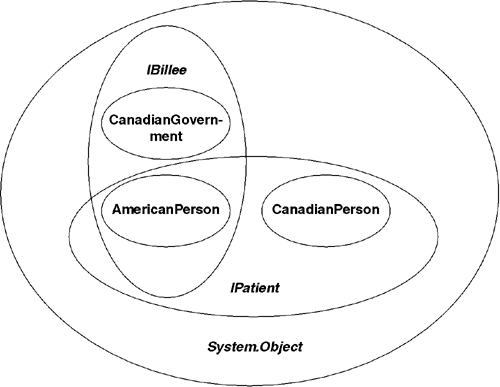
It is legal for a type to declare compatibility with more than one interface. When a concrete type (e.g., a class) declares compatibility with multiple interfaces, it is stating that instances of the type can be used in multiple contexts. For example, in Listing 3.5 the type AmericanPerson declares compatibility with both IPatient and IBillee, indicating its willingness to participate as either a patient or a billee. In this example, CanadianPerson declares compatibility only with IPatient and requires an instance of a second type (either CanadianGovernment or AmericanPerson) if a billee is also required.
One can view interfaces as partitioning the set of all possible objects into subsets. Which subsets an object belongs to depends on which interfaces the object's type has declared compatibility with. Figure 3.2 shows the types defined in Listing 3.5 as viewed from this perspective. Along these lines, it is also possible for an interface type to declare compatibility with one or more other interfaces. In doing so, the new interface is stating that all types that declare compatibility with the new interface are required to be compatible with the additional interfaces. Most languages (e.g., C#, VB.NET) will make this assertion implicitly when you declare compatibility with the new interface.
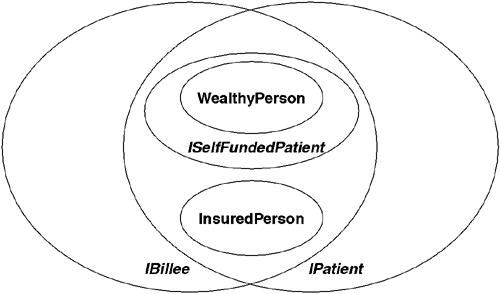
Consider the example shown in Listing 3.6. In this example, the interface ISelfFundedPatient has declared compatibility with both IPatient and IBillee. That means that types that declare compatibility with ISelfFundedPatient (such as WealthyPerson) must be compatible with IPatient and IBillee. This is not to say, however, that all types that are compatible with both IPatient and IBillee are in turn compatible with ISelfFundedPatient. In the example shown here, instances of type InsuredPerson are explicitly not allowed as parameters to the OperateAndTransfuseBlueBlood method. This is illustrated in Figure 3.3.
Interfaces can also impose explicit requirements on types that claim compatibility. Specifically, an interface can contain abstract method declarations. These declarations act as requirements for all types that claim to support the interface. If a concrete type claims to be compatible with interface I, that concrete type must provide method implementations for each abstract method declared in interface I.
To see how an interface can force types to implement methods, consider the following interface definition in C#:
public interface IPatientAll concrete types that claim compatibility with IPatient must now provide implementations of the AddLimb and RemoveLimb methods that match the signatures declared in IPatient.
The following is a concrete type that implements the IPatient interface just defined:
public sealed class AmericanPerson : IPatientIn this example, the IPatient interface's methods are part of the concrete type's public contract. The CLR also allows the concrete type to declare the methods as private provided that one uses some mechanism to indicate that the methods are used to satisfy the requirements of the interface. For example, the following implementation hides the RemoveLimb method from its public contract:
public sealed class CanadianPerson : IPatientIn this example, only the AddLimb method is accessible through references of type CanadianPerson. To access the RemoveLimb method, one must use a reference of type IPatient, which can access both methods.
When invoking a method through an interface-based reference, the CLR determines at runtime which method to actually call based on the concrete type of the referenced object. This dynamic method dispatch is a necessary feature to enable polymorphism and is discussed in great detail in Chapter 6.
In addition to declaring compatibility with multiple interfaces, a type can also specify at most one base type. A base type cannot be an interface, and, strictly speaking, the set of supported interfaces are not considered base types of the declaring type. Moreover, interfaces themselves have no base type. Rather, at most an interface has a set of supported interfaces just like those of a concrete type.
Non-interface types that do not specify a base type get System.Object as their base type. Base types sometimes trigger different runtime semantics from the CLR (e.g., reference vs. value type, marshal by reference, delegates). Base types can also be used to package common members into a single type that multiple types can then leverage. When defining a type, you can control whether the type can or will be used as a base type. Declaring a type as sealed prohibits the use of the type as a base type. Declaring a type as abstract, on the other hand, disallows direct instantiation of the type and makes it useful only as a base type. Interfaces are always implicitly abstract. If a type is neither abstract nor sealed, then programmers can use it as a base type or to instantiate new objects. Types that are not abstract are often referred to as concrete types.
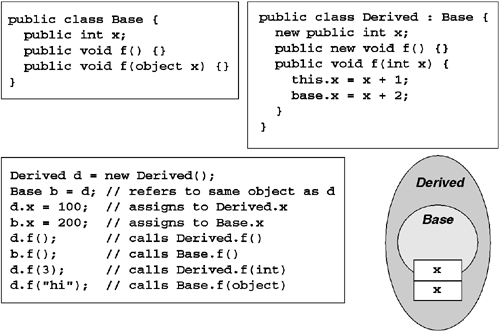
The non-private members of a base type implicitly become part of the contract of the derived type modulo cross-assembly accessibility. The derived type's methods can access non-private members of the base type as if they were explicitly declared in the derived type. It is possible (either by accident or deliberate design) for a member name in the derived type to collide with a non-private member name in the base. When this occurs, the derived type has both members. If the member is static, one can use the type name to disambiguate. If the member is non-static, then one can use language-specific keywords such as this or base to select either the derived member or the base member, respectively. For example, consider the following pair of types defined in C#:
public abstract class MammalIn this example, both the base and the derived types have age and count fields. To select the derived age field, one uses the this keyword. To select the base age field, one uses the base keyword. In the case of statics, one uses the explicit type name. Things get much more interesting when one looks at the type from the outside. Consider the following usage:
Human h = new Human();In this example, both h and m refer to the same object. However, because the type of each variable is different, the two variables see different public contracts. In the case of h, the Human's definition of age hides the definition in the base, so the Human's age field is affected. If, however, the m variable is used instead, it does not take into account the public contract of any derived types. Rather, all it knows about is Mammal, and it will access the Mammal's age field.
Note that in the example just shown, the C# compiler will emit a warning indicating that the derived fields hide the visibility of the base fields. You can suppress this warning by adding the new keyword to the derived field definitions as follows:
new public double age;Note that the presence (or absence) of the new keyword in no way affects the metadata or the executable code. As a point of interest, VB.NET uses the more demonstrative Shadows keyword for the same purpose rather than overloading the meaning of the new keyword, as is done in C#.
The previous discussion of name collisions illustrated what happens when one reuses a field name in a derived type. The policy for dealing with collisions when method names are reused is somewhat different because method names may already be reused due to overloading.
The CLR supports two basic policies to use when the base and derived types have a method of the same name: hide-by-name and hide-by-signature. Every CLR method declaration indicates which policy to use via the presence or absence of the hidebysig metadata attribute on the derived type's method. When one declares a method using hide-by-signature, only the base method with the same name and the same signature will be hidden. Any other same-named methods in the base will remain a visible part of the derived type's contract. In contrast, when one declares a method using hide-by-name, the derived method hides all methods in the base type that have the same name, no matter what their signature may be. Types defined in C++ use hide-by-name by default because that is the way the C++ language was originally defined. Types defined in C#, in contrast, always use hide-by-signature. Types defined in VB.NET can use either policy, based on whether the method uses the Overloads (hide-by-signature) or Shadows (hide-by-name) keyword.
Figure 3.4 shows an example in C# of two types that overload both a field name and a method name. Note that because C# uses hide-by-signature, the f method that accepts an int does not hide the base's f method that accepts an object. This is illustrated when the example calls the f method with a string argument. If the derived type had used hide-by-name, the base's f methods would not be visible, and this would mean that the derived contract would have no f method that could accept a string parameter. However, because the derived type was defined in C#, the method is marked hidebysig, and that allows the other methods in the base to seep through to the derived type's public contract.
It is important to note that with overloading, the exact method to be invoked is determined at compile time. No runtime tests are performed to determine which overload to choose. The CLR does support dynamic binding to method code at runtime, a topic covered in Chapter 6.
One last topic to address with respect to base types is related to constructors. When the CLR allocates a new object, it calls the constructor method from the most-derived type. It is the job of the derived type's constructor to explicitly call the base type's constructor. This means that at all times, the actual type of the object is the most-derived type, even when the base type's constructor is executing.
The behavior just described is similar to the way Java works but extremely different from the way C++ works. In C++, an object is constructed 'from the inside out'-that is, from base to derived type. Additionally, the type affiliation of a C++ object during the base type's constructor is that of the base type and not the derived type. That means that any virtual methods that may be invoked during the base type's constructor will not dispatch to a derived type's implementation. For a CLR-based type, this is not the case. Instead, if a base type constructor causes a virtual method call to be invoked, the most-derived type's method will be dispatched even though the derived type's constructor has probably not completed execution.
To avoid this problem, you are strongly encouraged to avoid virtual method calls in a constructor of a non-sealed type. This includes eschewing seemingly innocuous things such as passing your this or Me reference to a WriteLine method.
The C# language adds its own twist to how derived and base construction works, as shown in Figure 3.5. In the face of instance field declarations with initializer expressions, the compiler-generated .ctor will first call all field initializers in order of declaration. Once the derived type's field initializers have been called, the derived constructor calls the base type constructor, using the programmer-provided parameters if the base construct was used. Once the base type's constructor has completed execution, the derived constructor resumes execution at the body of the constructor (i.e., the part of the constructor in braces). This means that when the base type's constructor executes, the derived type's constructor body has not even begun to execute.
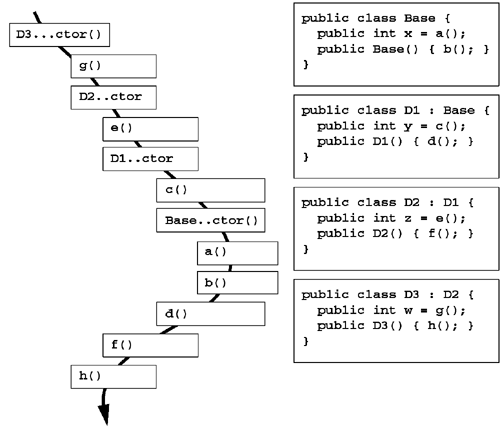
In general, designing a type to be used as a base type is considerably more difficult than defining a type that will simply be used to instantiate objects. For that reason, it is good practice to mark all types as sealed unless you are willing to ensure that your type is safe to use as a base. In a similar vein, it is easier to ensure that a type is safe as a base type if you are in control of all types that may use it as a base type. You can restrict a type's use as a base type by marking all of its constructors as internal. This technique makes all constructors inaccessible to types outside the assembly, thereby prohibiting them from using the type as a base type. However, types within the same assembly can safely use the type as a base without restriction.
Types are the fundamental building blocks of a CLR program and make up the lion's share of a module's metadata. Each programming language maps its local constructs onto CLR types in language-specific ways. CLR types consist primarily of fields and methods; however, developers can call out the intended usage of a method in the metadata through the use of properties and events. To support object-oriented programming languages, developers can factor CLR types into hierarchies using both interfaces and base types. Developers spend most of their time defining new types in terms of existing types.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1421
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved