| CATEGORII DOCUMENTE |
| Bulgara | Ceha slovaca | Croata | Engleza | Estona | Finlandeza | Franceza |
| Germana | Italiana | Letona | Lituaniana | Maghiara | Olandeza | Poloneza |
| Sarba | Slovena | Spaniola | Suedeza | Turca | Ucraineana |
Number theory was once viewed as a beautiful but largely useless subject in pure mathematics. Today number-theoretic algorithms are used widely, due in part to the invention of cryptographic schemes based on large prime numbers. The feasibility of these schemes rests on our ability to find large primes easily, while their security rests on our inability to factor the product of large primes. This chapter presents some of the number theory and associated algorithms that underlie such applications.
Section 1 introduces
basic concepts of number theory, such as divisibility, modular equivalence, and
unique factorization. Section 2 studies one of the world's oldest algorithms:
Euclid's algorithm for computing the greatest common divisor of two integers.
Section 3 reviews concepts of modular arithmetic. Section 4 then studies the
set of multiples of a given number a, modulo n, and shows how to
find all solutions to the equation ax ![]() b (mod n)
by using Euclid's algorithm. The Chinese remainder theorem is presented in
Section 5. Section 6 considers powers of a given number a, modulo n,
and presents a repeated-squaring algorithm for efficiently computing ab
mod n, given a, b, and n. This operation is at the
heart of efficient primality testing. Section 7 then describes the RSA
public-key cryptosystem. Section 8 describes a randomized primality test that
can be used to find large primes efficiently, an essential task in creating
keys for the RSA cryptosystem. Finally, Section 9 reviews a simple but
effective heuristic for factoring small integers. It is a curious fact that
factoring is one problem people may wish to be intractable, since the security
of RSA depends on the difficulty of factoring large integers.
b (mod n)
by using Euclid's algorithm. The Chinese remainder theorem is presented in
Section 5. Section 6 considers powers of a given number a, modulo n,
and presents a repeated-squaring algorithm for efficiently computing ab
mod n, given a, b, and n. This operation is at the
heart of efficient primality testing. Section 7 then describes the RSA
public-key cryptosystem. Section 8 describes a randomized primality test that
can be used to find large primes efficiently, an essential task in creating
keys for the RSA cryptosystem. Finally, Section 9 reviews a simple but
effective heuristic for factoring small integers. It is a curious fact that
factoring is one problem people may wish to be intractable, since the security
of RSA depends on the difficulty of factoring large integers.
Size of inputs and cost of arithmetic computations
Because we shall be working with large integers, we need to adjust how we think about the size of an input and about the cost of elementary arithmetic operations.
In this chapter, a 'large input typically means an input containing large integers' rather than an input containing 'many integers (as for sorting). Thus, we shall measure the size of an input in terms of the number of bits required to represent that input, not just the number of integers in the input. An algorithm with integer inputs a1, a2, . . . , ak is a polynomial-time algorithm if it runs in time polynomial in lg a1, lg a2, . . . , lg ak, that is, polynomial in the lengths of its binary-encoded inputs.
In most of this book, we
have found it convenient to think of the elementary arithmetic operations
(multiplications, divisions, or computing remainders) as primitive operations
that take one unit of time. By counting the number of such arithmetic
operations an algorithm performs, we have a basis for making a reasonable
estimate of the algorithm's actual running time on a computer. Elementary
operations can be time-consuming, however, when their inputs are large. It thus
becomes convenient to measure how many bit operations a number-theoretic
algorithm requires. In this model, a multiplication of two ![]() -bit integers
by the ordinary method uses
-bit integers
by the ordinary method uses ![]() (
(![]() 2)
bit operations. Similarly, the operation of dividing a
2)
bit operations. Similarly, the operation of dividing a ![]() -bit integer
by a shorter integer, or the operation of taking the remainder of a
-bit integer
by a shorter integer, or the operation of taking the remainder of a ![]() -bit integer
when divided by a shorter integer, can be performed in time
-bit integer
when divided by a shorter integer, can be performed in time ![]() (
(![]() 2)
by simple algorithms. (See Exercise 1-11.) Faster methods are known. For
example, a simple divide-and-conquer method for multiplying two
2)
by simple algorithms. (See Exercise 1-11.) Faster methods are known. For
example, a simple divide-and-conquer method for multiplying two ![]() -bit
integers has a running time of
-bit
integers has a running time of ![]() (
(![]() lg ), and the fastest known method has a running time of
lg ), and the fastest known method has a running time of ![]() (
(![]() lg
lg ![]() lg lg
lg lg ![]() ). For
practical purposes, however, the
). For
practical purposes, however, the ![]() (
(![]() 2)
algorithm is often best, and we shall use this bound as a basis for our
analyses.
2)
algorithm is often best, and we shall use this bound as a basis for our
analyses.
In this chapter, algorithms are generally analyzed in terms of both the number of arithmetic operations and the number of bit operations they require.
This section provides a brief review of notions from elementary number theory concerning the set Z = of integers and the set N = of natural numbers.
The notion of one integer being divisible by another
is a central one in the theory of numbers. The notation d | a (read
'd divides a') means that a = kd
for some integer k. Every integer divides 0. If a > 0 and d
| a, then |d| ![]() |a|. If d
| a, then we also say that a is a multiple
of d. If d does not divide a, we write
|a|. If d
| a, then we also say that a is a multiple
of d. If d does not divide a, we write ![]() .
.
If d | a and d
![]() 0, we say that
d is a divisor of a. Note that d | a
if and only if -d | a, so that no generality is lost by
defining the divisors to be nonnegative, with the understanding that the
negative of any divisor of a also divides a. A divisor of an
integer a is at least 1 but not greater than |a|. For example,
the divisors of 24 are 1, 2, 3, 4, 6, 8, 12, and 24.
0, we say that
d is a divisor of a. Note that d | a
if and only if -d | a, so that no generality is lost by
defining the divisors to be nonnegative, with the understanding that the
negative of any divisor of a also divides a. A divisor of an
integer a is at least 1 but not greater than |a|. For example,
the divisors of 24 are 1, 2, 3, 4, 6, 8, 12, and 24.
Every integer a is divisible by the trivial divisors 1 and a. Nontrivial divisors of a are also called factors of a. For example, the factors of 20 are 2, 4, 5, and 10.
An integer a > 1 whose only divisors are the trivial divisors 1 and a is said to be a prime number (or, more simply, a prime). Primes have many special properties and play a critical role in number theory. The small primes, in order, are
Exercise 1-1 asks you to prove that there are infinitely many primes. An integer a > 1 that is not prime is said to be a composite number (or, more simply, a composite). For example, 39 is composite because 3 | 39. The integer 1 is said to be a unit and is neither prime nor composite. Similarly, the integer 0 and all negative integers are neither prime nor composite.
Given an integer n, the integers can be partitioned into those that are multiples of n and those that are not multiples of n. Much number theory is based upon a refinement of this partition obtained by classifying the nonmultiples of n according to their remainders when divided by n. The following theorem is the basis for this refinement. The proof of this theorem will not be given here (see, for example, Niven and Zuckerman [151]).
Theorem 1
For any integer a
and any positive integer n, there are unique integers q and r
such that 0 ![]() r < n
and a = qn + r.
r < n
and a = qn + r.
The value q = ![]() a/n
a/n![]() is the quotient of the division. The value r = a
mod n is the remainder (or residue) of the
division. We have that n | a if and only if a mod n
= 0. It follows that
is the quotient of the division. The value r = a
mod n is the remainder (or residue) of the
division. We have that n | a if and only if a mod n
= 0. It follows that
or
a mod n = a -Given a well-defined notion of the remainder of one
integer when divided by another, it is convenient to provide special notation
to indicate equality of remainders. If (a mod n) = (b mod
n), we write a ![]() b (mod n)
and say that a is equivalent to b, modulo n.
In other words, a
b (mod n)
and say that a is equivalent to b, modulo n.
In other words, a ![]() b (mod
n) if a and b have the same remainder when divided by n. Equivalently,
a
b (mod
n) if a and b have the same remainder when divided by n. Equivalently,
a ![]() b (mod n)
if and only if n | (b - a). We write a
b (mod n)
if and only if n | (b - a). We write a ![]() b (mod n)
if a is not equivalent to b, modulo n. For example, 61
b (mod n)
if a is not equivalent to b, modulo n. For example, 61 ![]() 6 (mod 11).
Also, -13
6 (mod 11).
Also, -13 ![]() 22
22 ![]() 2 (mod 5).
2 (mod 5).
The integers can be divided into n equivalence classes according to their remainders modulo n. The equivalence class modulo n containing an integer a is
[a]n = .For example, [3]7
= ; other denotations for this set are [-4]7
and [10]7. Writing a ![]() [b]n
is the same as writing a
[b]n
is the same as writing a ![]() b (mod n).
The set of all such equivalence classes is
b (mod n).
The set of all such equivalence classes is
One often sees the definition
Znwhich should be read as
equivalent to equation (3) with the understanding that 0 represents [0]n,
1 represents [1]n, and so on; each class is represented by
its least nonnegative element. The underlying equivalence classes must be kept
in mind, however. For example, a reference to - 1 as a member of Zn
is a reference to [n - 1]n, since - 1 ![]() n - 1
(mod n).
n - 1
(mod n).
If d is a divisor of a and also a divisor of b, then d is a common divisor of a and b. For example, the divisors of 30 are 1, 2, 3, 5, 6, 10, 15, and 30, and so the common divisors of 24 and 30 are 1, 2, 3, and 6. Note that 1 is a common divisor of any two integers.
An important property of common divisors is that
d | a and d | b implies d | (a + b) and d | (a - b).More generally, we have that
d | a and d | b implies d | (ax + by)for any integers x and
y. Also, if a | b, then either |a| ![]() |b| or b
= 0, which implies that
|b| or b
= 0, which implies that
The greatest common divisor of two integers a and b, not both zero, is the largest of the common divisors of a and b; it is denoted gcd(a, b). For example, gcd(24, 30) = 6, gcd(5, 7) = 1, and gcd(0, 9) = 9. If a and b are not both 0, then gcd(a, b) is an integer between 1 and min(|a|, |b|). We define gcd(0, 0) to be 0; this definition is necessary to make standard properties of the gcd function (such as equation (11) below) universally valid.
The following are elementary properties of the gcd function:
gcd(a,b) = gcd(b,a),Theorem 2
If a and b are any integers, not both zero, then gcd(a, b) is the smallest positive element of the set of linear combinations of a and b.
Proof Let s be the smallest positive such linear combination of a
and b, and let s = ax + by for some x, y ![]() Z. Let q
=
Z. Let q
= ![]() a/s
a/s![]() . Equation (2) then implies
. Equation (2) then implies
and thus a mod s
is a linear combination of a and b as well. But, since a
mod s < s, we have that a mod s = 0, because s
is the smallest positive such linear combination. Therefore, s | a
and, by analogous reasoning, s | b. Thus, s is a
common divisor of a and b, and so gcd(a, b) ![]() s.
Equation (6) implies that gcd(a, b) | s, since gcd(a, b)
divides both a and b and s is a linear combination of a
and b. But gcd(a, b) | s and s > 0 imply
that gcd(a, b)
s.
Equation (6) implies that gcd(a, b) | s, since gcd(a, b)
divides both a and b and s is a linear combination of a
and b. But gcd(a, b) | s and s > 0 imply
that gcd(a, b) ![]() s.
Combining gcd(a, b)
s.
Combining gcd(a, b) ![]() s and
gcd(a, b)
s and
gcd(a, b) ![]() s
yields gcd(a, b) = s; we conclude that s is the greatest
common divisor of a and b.
s
yields gcd(a, b) = s; we conclude that s is the greatest
common divisor of a and b.
Corollary 3
For any integers a and b, if d | a and d | b then d | gcd(a, b) .
Proof This corollary follows from equation (6), because gcd(a, b) is a linear combination of a and b by Theorem 2.
Corollary 4
For all integers a and b and any nonnegative integer n,
gcd(an, bn) = n gcd(a, b).Proof If n = 0, the corollary is trivial. If n > 0, then gcd(an, bn) is the smallest positive element of the set , which is n times the smallest positive element of the set .
Corollary 5
For all positive integers n, a, and b, if n | ab and gcd(a, n) = 1, then n | b.
Proof The proof is left as Exercise 1-4.
Two integers a, b are said to be relatively prime if their only common divisor is 1, that is, if gcd(a, b) = 1. For example, 8 and 15 are relatively prime, since the divisors of 8 are 1, 2, 4, and 8, while the divisors of 15 are 1, 3, 5, and 15. The following theorem states that if two integers are each relatively prime to an integer p, then their product is relatively prime to p.
Theorem 6
For any integers a, b, and p, if gcd(a, p) = 1 and gcd(b, p) = 1, then gcd(ab, p) = 1.
Proof It follows from Theorem 2 that there exist integers x, y, x', and y' such that
ax + py = 1,Multiplying these equations and rearranging, we have
ab(xx') + p(ybx' + y'ax + pyy') = 1.Since 1 is thus a positive linear combination of ab and p, an appeal to Theorem 2 completes the proof.
We say that integers n1,
n2, . . ., nk are pairwise relatively
prime if, whenever i ![]() j, we
have gcd(ni, nj) = 1.
j, we
have gcd(ni, nj) = 1.
An elementary but important fact about divisibility by primes is the following.
Theorem 7
For all primes p and all integers a, b, if p | ab, then p | a or p | b.
Proof Assume for the purpose of contradiction that p | ab but
that ![]() . Thus, gcd(a,
p) = 1 and gcd(b, p) = 1, since the only divisors of p are 1
and p, and by assumption p divides neither a nor b.
Theorem 6 then implies that gcd(ab, p) = 1, contradicting our assumption
that p | ab, since p | ab implies gcd(ab, p)
= p. This contradiction completes the proof.
. Thus, gcd(a,
p) = 1 and gcd(b, p) = 1, since the only divisors of p are 1
and p, and by assumption p divides neither a nor b.
Theorem 6 then implies that gcd(ab, p) = 1, contradicting our assumption
that p | ab, since p | ab implies gcd(ab, p)
= p. This contradiction completes the proof.
A consequence of Theorem 7 is that an integer has a unique factorization into primes.
Theorem 8
A composite integer a can be written in exactly one way as a product of the form
![]()
where the pi are prime, p1 < p2 < . . . < pr, and the ei are positive integers.
Proof The proof is left Exercise 1-10.
As an example, the number 6000 can be uniquely factored as 24.3.53.
Prove that there are infinitely many primes. (Hint: Show that none of the primes p1, p2, . . . , pk divide (p1p2 . . . pk) + 1.)
Prove that if a | b and b | c, then a | c.
Prove that if p is prime and 0 < k < p, then gcd (k, p) = 1.
Prove Corollary 5.
Prove that if p is
prime and 0 < k < p, then ![]() . Conclude
that for all integers a, b, and primes p,
. Conclude
that for all integers a, b, and primes p,
Prove that if a and b are any integers such that a | b and b > 0, then
(x mod b) mod a = x mod afor any x. Prove, under the same assumptions, that
xfor any integers x and y.
For any
integer k > 0, we say that an integer n is a kth power
if there exists an integer a such that ak = n.
We say that n > 1 is a nontrivial power if it is a kth
power for some integer k > 1. Show how to determine if a given ![]() -bit
integer n is a nontrivial power in time polynomial in
-bit
integer n is a nontrivial power in time polynomial in ![]() .
.
Prove equations (8)--(12).
Show that the gcd operator is associative. That is, prove that for all integers a, b, and c,
gcd(a, gcd(b, c)) = gcd(gcd(a, b), c) .
Prove Theorem 8.
Give efficient algorithms
for the operations of dividing a ![]() -bit
integer by a shorter integer and of taking the remainder of a
-bit
integer by a shorter integer and of taking the remainder of a ![]() -bit
integer when divided by a shorter integer. Your algorithms should run in time O(
-bit
integer when divided by a shorter integer. Your algorithms should run in time O(![]() 2).
2).
In this section, we use Euclid's algorithm to compute the greatest common divisor of two integers efficiently. The analysis of running time brings up a surprising connection with the Fibonacci numbers, which yield a worst-case input for Euclid's algorithm.
We restrict ourselves in this section to nonnegative integers. This restriction is justified by equation (10), which states that gcd(a,b) = gcd(|a|, |b|).
In principle, we can compute gcd(a, b) for positive integers a and b from the prime factorizations of a and b. Indeed, if

with zero exponents being used to make the set of primes p1, p2, . . . , pr the same for both a and b, then
![]()
As we shall show in Section 9, the best algorithms to date for factoring do not run in polynomial time. Thus, this approach to computing greatest common divisors seems unlikely to yield an efficient algorithm.
Euclid's algorithm for computing greatest common divisors is based on the following theorem.
Theorem 9
For any nonnegative integer a and any positive integer b,
gcd(a,b) = gcd(b,a mod b) .Proof We shall show that gcd (a, b) and gcd (b, a mod b) divide each other, so that by equation (7) they must be equal (since they are both nonnegative).
We first show that gcd (a,
b) | gcd(b, a mod b). If we let d = gcd (a,
b), then d | a and d | b. By equation (2), (a
mod b) = a - qb, where q = ![]() a/b
a/b![]() . Since (a mod b) is thus a linear combination of a
and b, equation (6) implies that d | (a mod b).
Therefore, since d | b and d | (a mod b),
Corollary 3 implies that d | gcd(b, a mod b) or,
equivalently, that
. Since (a mod b) is thus a linear combination of a
and b, equation (6) implies that d | (a mod b).
Therefore, since d | b and d | (a mod b),
Corollary 3 implies that d | gcd(b, a mod b) or,
equivalently, that
Showing that gcd (b,
a mod b) | gcd(a, b) is almost the same. If we now
let d = gcd(b, a mod b), then d | b
and d | (a mod b). Since a = qb + (a
mod b), where q = ![]() a/b
a/b![]() , we have that a is a linear combination of b and (a
mod b). By equation (6), we conclude that d | a. Since d
| b and d | a, we have that d | gcd(a, b)
by Corollary 3 or, equivalently, that
, we have that a is a linear combination of b and (a
mod b). By equation (6), we conclude that d | a. Since d
| b and d | a, we have that d | gcd(a, b)
by Corollary 3 or, equivalently, that
Using equation (7) to combine equations (16) and (17) completes the proof.
The following gcd algorithm is described in the Elements of Euclid (circa 300 B.C.), although it may be of even earlier origin. It is written as a recursive program based directly on Theorem 9. The inputs a and b are arbitrary nonnegative integers.
EUCLID (a, b)As an example of the running of EUCLID, consider the computation of gcd (30,21):
EUCLID(30, 21) = EUCLID(21, 9)In this computation, there are three recursive invocations of EUCLID
The correctness of EUCLID follows from Theorem 9 and the fact that if the algorithm returns a in line 2, then b = 0, so equation (11) implies that gcd(a, b) = gcd(a, 0) = a. The algorithm cannot recurse indefinitely, since the second argument strictly decreases in each recursive call. Therefore, EUCLID always terminates with the correct answer.
We analyze the worst-case
running time of EUCLID as a function of the size of a and b. We assume with
little loss of generality that a > b ![]() 0. This
assumption can be justified by the observation that if b > a
0. This
assumption can be justified by the observation that if b > a ![]() 0, then Euclid (a, b)
immediately makes the recursive call EUCLID (b, a). That is, if the first argument is less than the
second argument, EUCLID spends one recursive call swapping its arguments and then proceeds.
Similarly, if b = a > 0, the procedure terminates after one
recursive call, since a mod b = 0.
0, then Euclid (a, b)
immediately makes the recursive call EUCLID (b, a). That is, if the first argument is less than the
second argument, EUCLID spends one recursive call swapping its arguments and then proceeds.
Similarly, if b = a > 0, the procedure terminates after one
recursive call, since a mod b = 0.
The overall running time of EUCLID is proportional to the number of recursive calls it makes. Our analysis makes use of the Fibonacci numbers Fk, defined by the recurrence (2.13).
Lemma 10
If a > b ![]() 0 and the
invocation Euclid(a,
b) performs k
0 and the
invocation Euclid(a,
b) performs k ![]() 1 recursive
calls, then a
1 recursive
calls, then a ![]() Fk+2
and b
Fk+2
and b ![]() Fk+l.
Fk+l.
Proof The proof is by induction on k. For the basis of the induction,
let k = 1. Then, b ![]() 1 = F2,
and since a > b, we must have a
1 = F2,
and since a > b, we must have a ![]() 2 = F3.
Since b > (a mod b), in each recursive call the first
argument is strictly larger than the second; the assumption that a > b
therefore holds for each recursive call.
2 = F3.
Since b > (a mod b), in each recursive call the first
argument is strictly larger than the second; the assumption that a > b
therefore holds for each recursive call.
Assume inductively that
the lemma is true if k - 1 recursive calls are made; we shall then prove
that it is true for k recursive calls. Since k > 0, we have b
> 0, and EUCLID
(a, b) calls EUCLID (b, a mod b) recursively, which in turn makes k
- 1 recursive calls. The inductive hypothesis then implies that b ![]() Fk+
1 (thus proving part of the lemma), and (a mod b)
Fk+
1 (thus proving part of the lemma), and (a mod b) ![]() Fk.
We have
Fk.
We have
since a > b
> 0 implies ![]() a/b
a/b![]()
![]() 1. Thus,
1. Thus,
The following theorem is an immediate corollary of this lemma.
Theorem 11
For any integer k ![]() 1, if a
> b
1, if a
> b ![]() 0 and b
< Fk+1, then the invocation EUCLID (a, b)
makes fewer than k recursive calls.
0 and b
< Fk+1, then the invocation EUCLID (a, b)
makes fewer than k recursive calls.
We can show that the
upper bound of Theorem 11 is the best possible. Consecutive Fibonacci numbers
are a worst-case input for EUCLID. Since Euclid (F3, F2) makes exactly one
recursive call, and since for k ![]() 2 we have Fk+1
mod Fk = Fk-1, we also have
2 we have Fk+1
mod Fk = Fk-1, we also have
Thus, Euclid(Fk+1,Fk) recurses exactly k - 1 times, meeting the upper bound of Theorem 11.
Since Fk
is approximately ![]() , where
, where ![]() is the golden
ratio
is the golden
ratio ![]() defined by
equation (2.14), the number of recursive calls in EUCLID is O(lg b).
(See Exercise 2-5 for a tighter bound.) It follows that if EUCLID is applied to two
defined by
equation (2.14), the number of recursive calls in EUCLID is O(lg b).
(See Exercise 2-5 for a tighter bound.) It follows that if EUCLID is applied to two ![]() -bit numbers,
then it will perform O(
-bit numbers,
then it will perform O(![]() ) arithmetic
operations and O(
) arithmetic
operations and O(![]() 3)
bit operations (assuming that multiplication and division of
3)
bit operations (assuming that multiplication and division of ![]() -bit numbers
take O(
-bit numbers
take O(![]() 2)
bit operations). Problem 33-2 asks you to show an O(
2)
bit operations). Problem 33-2 asks you to show an O(![]() 2)
bound on the number of bit operations.
2)
bound on the number of bit operations.
We now rewrite Euclid's algorithm to compute additional useful information. Specifically, we extend the algorithm to compute the integer coefficients x and y such that
d = gcd(a,b) = ax + by .Note that x and y may be zero or negative. We shall find these coefficients useful later for the computation of modular multiplicative inverses. The
a bprocedure EXTENDED EUCLID takes as input an arbitrary pair of integers and returns a triple of the form (d, x, y) that satisfies equation (18).
EXTENDED-EUCLID(a, b)Figure 1 illustrates the execution of EXTENDED EUCLID with the computation of gcd(99,78).
The EXTENDED-EUCLID procedure is a variation
of the EUCLID
procedure. Line 1 is equivalent to the test 'b = 0' in line 1
of EUCLID.
If b = 0, then EXTENDED EUCLID
returns not only d = a in line 2, but also the coefficients x =
1 and y = 0, so that a = ax + by. If b ![]() 0, EXTENDED EUCLID first computes (d',
x', y') such that d' = gcd(b, a mod b)
and
0, EXTENDED EUCLID first computes (d',
x', y') such that d' = gcd(b, a mod b)
and
As for EUCLID, we have in this case d = gcd(a, b) = d' = gcd(b, a mod b). To obtain x and y such that d = ax + by, we start by rewriting equation (19) using the equation d = d' and equation (2):
d = bx' + (a -Thus, choosing x =
y' and y = x' - ![]() a/b
a/b![]() y' satisfies the equation d = ax + by,
proving the correctness of EXTENDED EUCLID
y' satisfies the equation d = ax + by,
proving the correctness of EXTENDED EUCLID
Since the number of recursive calls made in EUCLID is equal to the number of recursive calls made in EXTENDED EUCLID, the running times of EUCLID and EXTENDED EUCLID are the same, to within a constant factor. That is, for a > b > 0, the number of recursive calls is O(lg b).
Prove that equations (13)--(14) imply equation (15).
Compute the values (d, x, y) that are output by the invocation EXTENDED-EUCLID
Prove that for all integers a, k, and n,
gcd(a, n) = gcd(a + kn, n).
Rewrite EUCLID in an iterative form that uses only a constant amount of memory (that is, stores only a constant number of integer values).
If a > b
![]() 0, show that
the invocation EUCLID(a, b) makes at most 1 + log
0, show that
the invocation EUCLID(a, b) makes at most 1 + log![]() b
recursive calls. Improve this bound to 1 +log
b
recursive calls. Improve this bound to 1 +log![]() (b/gcd(a, b)).
(b/gcd(a, b)).
What does EXTENDED EUCLID(Fk + 1, Fk) return? Prove your answer correct.
Verify the output (d, x, y) of EXTENDED EUCLID(a, b) by showing that if d a, d b, and d = ax + by, then d = gcd(a, b).
Define the gcd function for more than two arguments by the recursive equation gcd(a0, al, . . . , n) = gcd(a0, gcd(a1, . . . , an)). Show that gcd returns the same answer independent of the order in which its arguments are specified. Show how to find x0, x1, . . . . , xn such that gcd(a0, a1, . . . , an) = a0x0 + a1x1 + . . . + anxn. Show that the number of divisions performed by your algorithm is O(n + 1g(maxi, ai)).
Define lcm(a1, a2, . . . , an) to be the least common multiple of the integers a1, a2, . . . , an, that is, the least nonnegative integer that is a multiple of each ai. Show how to compute lcm(a1, a2, . . . , an) efficiently using the (two-argument) gcd operation as a subroutine.
Prove that n1,
n2, n3, and n4 are
pairwise relatively prime if and only if gcd(n1n2,
n3n4) = gcd(n1n3,
n2n4) = 1. Show more generally that n1,
n2, . . . , nk are pairwise relatively
prime if and only if a set of ![]() lg k
lg k![]() pairs of numbers derived from the ni
are relatively prime.
pairs of numbers derived from the ni
are relatively prime.
Informally, we can think of modular arithmetic as arithmetic as usual over the integers, except that if we are working modulo n, then every result x is replaced by the element of that is equivalent to x, modulo n (that is, x is replaced by x mod n). This informal model is sufficient if we stick to the operations of addition, subtraction, and multiplication. A more formal model for modular arithmetic, which we now give, is best described within the framework of group theory.
A group (S, ![]() ) is a set S
together with a binary operation
) is a set S
together with a binary operation ![]() defined on S
for which the following properties hold.
defined on S
for which the following properties hold.
1. Closure: For all a, b ![]() S, we
have a
S, we
have a ![]() b
b ![]() S.
S.
2. Identity: There is an element e
![]() S such that
e
S such that
e ![]() a = a
a = a
![]() e = a
for all a
e = a
for all a ![]() S.
S.
3. Associativity: For all a, b,
c ![]() S, we
have (a
S, we
have (a ![]() b)
b) ![]() c = a
c = a
![]() (b
(b ![]() c).
c).
4. Inverses: For each a ![]() S,
there exists a unique element b
S,
there exists a unique element b ![]() S such
that a
S such
that a ![]() b = b
b = b
![]() a = e.
a = e.
As an example, consider the
familiar group (Z, +) of the integers Z under the operation of
addition: 0 is the identity, and the inverse of a is -a. If a
group (S, ![]() ) satisfies
the commutative law a
) satisfies
the commutative law a ![]() b = b
b = b
![]() a for
all a, b
a for
all a, b ![]() S, then
it is an abelian group. If a group (S,
S, then
it is an abelian group. If a group (S, ![]() ) satisfies |S|
<
) satisfies |S|
< ![]() , then it is a
finite group.
, then it is a
finite group.
We can form two finite abelian groups by using addition and multiplication modulo n, where n is a positive integer. These groups are based on the equivalence classes of the integers modulo n, defined in Section 1.
To define a group on Zn,
we need to have suitable binary operations, which we obtain by redefining the
ordinary operations of addition and multiplication. It is easy to define
addition and multiplication operations for Zn, because
the equivalence class of two integers uniquely determines the equivalence class
of their sum or product. That is, if a ![]() a' (mod
n) and b
a' (mod
n) and b ![]() b'
(mod n), then
b'
(mod n), then
Thus, we define addition and multiplication modulo n, denoted +n and .n, as follows:
(Subtraction can be similarly defined on Zn by [a]n - n [b]n = [a - b]n, but division is more complicated, as we shall see.) These facts justify the common and convenient practice of using the least nonnegative element of each equivalence class as its representative when performing computations in Zn. Addition, subtraction, and multiplication are performed as usual on the representatives, but each result x is replaced by the representative of its class (that is, by x mod n).
Using this definition of addition modulo n, we define the additive group modulo n as (Zn, + n). This size of the additive group modulo n is |Zn| = n. Figure 2(a) gives the operation table for the group (Z6, + 6).
Theorem 12
The system (Zn, + n) is a finite abelian group.
Proof Associativity and commutativity of +n follow from the associativity and commutativity of +:
([a]n + n[b]n) +n[c]n = [(a + b) + c]nThe identity element of (Zn,+n) is 0 (that is, [0]n). The (additive) inverse of an element a (that is, [a]n) is the element -a (that is, [-a]n or [n - a]n), since [a]n +n [-a]n=[a - a]n=[0]n.
Using the definition of multiplication
modulo n, we define the multiplicative group modulo n as ![]() . The elements
of this group are the set
. The elements
of this group are the set ![]() of elements in
Zn that are relatively prime to n:
of elements in
Zn that are relatively prime to n:
![]()
To see that ![]() is well
defined, note that for 0
is well
defined, note that for 0 ![]() a < n,
we have a
a < n,
we have a ![]() (a+kn)
(mod n) for all integers k. By Exercise 2-3, therefore, gcd(a,
n) = 1 implies gcd(a+kn, n) = 1 for all integers k.
Since [a]n = , the
set
(a+kn)
(mod n) for all integers k. By Exercise 2-3, therefore, gcd(a,
n) = 1 implies gcd(a+kn, n) = 1 for all integers k.
Since [a]n = , the
set ![]() is well
defined. An example of such a group is
is well
defined. An example of such a group is
![]()
where the group operation
is multiplication modulo 15. (Here we denote an element [a]15
as a.) Figure 2(b) shows the group ![]() . For example,
8
. For example,
8 ![]() 11
11 ![]() 13 (mod 15),
working in
13 (mod 15),
working in ![]() . The identity
for this group is 1.
. The identity
for this group is 1.
Theorem 13
The system ![]() is a finite
abelian group.
is a finite
abelian group.
Proof Theorem 6 implies that ![]() is closed.
Associativity and commutativity can be proved for .n
as they were for +n in the proof of Theorem 12. The identity
element is [1]n. To show the existence of inverses, let a
be an element of
is closed.
Associativity and commutativity can be proved for .n
as they were for +n in the proof of Theorem 12. The identity
element is [1]n. To show the existence of inverses, let a
be an element of ![]() and let (d,
x, y) be the output of EXTENDED EUCLID(a,
n). Then d = 1, since a
and let (d,
x, y) be the output of EXTENDED EUCLID(a,
n). Then d = 1, since a ![]()
![]() , and
, and
or, equivalently,
axThus, [x]n is a multiplicative inverse of [a]n, modulo n. The proof that inverses are uniquely defined is deferred until Corollary 26.
When working with the
groups (Zn,+n) and (Zn,
![]() n) in the remainder of this chapter, we follow the convenient practice
of denoting equivalence classes by their representative elements and denoting
the operations +n and .n by the
usual arithmetic notations + and
n) in the remainder of this chapter, we follow the convenient practice
of denoting equivalence classes by their representative elements and denoting
the operations +n and .n by the
usual arithmetic notations + and ![]() (or juxtaposition) respectively. Also, equivalences modulo n may
also be interpreted as equations in Zn. For example,
the following two statements are equivalent:
(or juxtaposition) respectively. Also, equivalences modulo n may
also be interpreted as equations in Zn. For example,
the following two statements are equivalent:
As a further convenience,
we sometimes refer to a group (S, ![]() ) merely as S
when the operation is understood from context. We may thus refer to the groups
(Zn, + n) and
) merely as S
when the operation is understood from context. We may thus refer to the groups
(Zn, + n) and ![]() as Zn
and
as Zn
and ![]() respectively.
respectively.
The (multiplicative)
inverse of an element a is denoted (a-1 mod n).
Division in ![]() is defined by
the equation a/b
is defined by
the equation a/b ![]() ab-1
(mod n). For example, in
ab-1
(mod n). For example, in ![]() we have that 7-1
we have that 7-1
![]() 13 (mod 15),
since 7 . 13
13 (mod 15),
since 7 . 13 ![]() 91
91 ![]() 1 (mod 15), so
that 4/7
1 (mod 15), so
that 4/7 ![]() 4 . 13
4 . 13 ![]() 7 (mod 15).
7 (mod 15).
The size of ![]() is denoted
is denoted ![]() (n).
This function, known as Euler's phi function, satisfies the
equation
(n).
This function, known as Euler's phi function, satisfies the
equation

where p runs over all the primes dividing n (including n itself, if n is prime). We shall not prove this formula here. Intuitively, we begin with a list of the n remainders and then, for each prime p that divides n, cross out every multiple of p in the list. For example, since the prime divisors of 45 are 3 and 5,
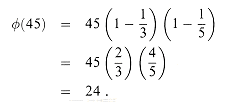
If p is prime,
then ![]() , and
, and
If n is composite,
then ![]() (n)
< n - 1.
(n)
< n - 1.
Theorem 14
If (S, ![]() ) is a finite
group and S' is any subset of S such that a
) is a finite
group and S' is any subset of S such that a ![]() b
b ![]() S' for
all a, b
S' for
all a, b ![]() S',
then (S',
S',
then (S',![]() ) is a
subgroup of (S,
) is a
subgroup of (S, ![]() ).
).
Proof The proof is left as Exercise 3-2.
For example, the set forms a subgroup of Z8,since it is closed under the operation + (that is, it is closed under +8).
The following theorem provides an extremely useful constraint on the size of a subgroup.
Theorem 15
If (S, ![]() ) is a finite
group and (S,
) is a finite
group and (S, ![]() ) is a
subgroup of (S,
) is a
subgroup of (S, ![]() ), then |S'|
is a divisor of |S|.
), then |S'|
is a divisor of |S|.
A subgroup
S' of a group S is said to be a proper subgroup if S'
![]() S. The
following corollary will be used in our analysis of the Miller-Rabin primality
test procedure in Section 8.
S. The
following corollary will be used in our analysis of the Miller-Rabin primality
test procedure in Section 8.
Corollary 16
If S' is a proper
subgroup of a finite group S, then |S'| ![]() |S|/2.
|S|/2.
Theorem 14 provides an
interesting way to produce a subgroup of a finite group (S, ![]() ): choose an
element a and take all elements that can be generated from a
using the group operation. Specifically, define a(k) for k
): choose an
element a and take all elements that can be generated from a
using the group operation. Specifically, define a(k) for k
![]() 1 by
1 by
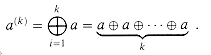
For example, if we take a = 2 in the group Z6, the sequence a(1), a(2), . . . is
In the group Zn, we have a(k)
= ka mod n, and in the group ![]() , we have a(k)
= ak mod n. The subgroup generated by a,
denoted
, we have a(k)
= ak mod n. The subgroup generated by a,
denoted ![]() a
a![]() or (
or (![]() a
a![]() ,
, ![]() ), is defined
by
), is defined
by
![]() a
a![]() is closed and
therefore, by Theorem 14,
is closed and
therefore, by Theorem 14, ![]() a
a![]() is a subgroup
of S. For example, in Z6,we have
is a subgroup
of S. For example, in Z6,we have
Similarly, in ![]() , we have
, we have
The order of a (in the group S), denoted ord(a), is defined as the least t > 0 such that a(t) = e.
Theorem 17
For any finite group (S,
![]() ) and any a
) and any a
![]() S, the
order of an element is equal to the size of the subgroup it generates, or ord(a)
= |
S, the
order of an element is equal to the size of the subgroup it generates, or ord(a)
= |![]() a
a![]() |.
|.
Proof Let t = ord(a). Since a(t) = e
and a(t+k) = a(t) ![]() a(k)
= a(k) for k
a(k)
= a(k) for k ![]() 1, if i > t,
then a(i) = a(j) for some j
< i. Thus, no new elements are seen after a(t),
and
1, if i > t,
then a(i) = a(j) for some j
< i. Thus, no new elements are seen after a(t),
and ![]() a
a![]() = .
To show that
= .
To show that ![]()
![]() a
a![]()
![]() = t,
suppose for the purpose of contradiction that a(i)
= a(j) for some i, j
satisfying 1
= t,
suppose for the purpose of contradiction that a(i)
= a(j) for some i, j
satisfying 1 ![]() i < j
i < j
![]() t. Then, a(i+k)
= a(j+k) for k
t. Then, a(i+k)
= a(j+k) for k ![]() 0. But this
implies that a(i+(t-j)) = a(j+(t-j))
= e, a contradiction, since i + (t - j) < t but t
is the least positive value such that a(t) = e.
Therefore, each element of the sequence a(1),a(2),
. . . , a(t) is distinct, and
0. But this
implies that a(i+(t-j)) = a(j+(t-j))
= e, a contradiction, since i + (t - j) < t but t
is the least positive value such that a(t) = e.
Therefore, each element of the sequence a(1),a(2),
. . . , a(t) is distinct, and ![]()
![]() a
a![]()
![]() = t.
= t.
Corollary 18
The sequence a(1),
a(2), . . . is periodic with period t = ord(a);
that is, a(i) = a(j) if and
only if i ![]() j (mod t).
j (mod t).
It is consistent with the above corollary to define a(0) as e and a(i) as a(i mod t) for all integers i.
Corollary 19
If (S, ![]() ) is a finite
group with identity e, then for all a
) is a finite
group with identity e, then for all a ![]() S,
S,
Proof Lagrange's theorem implies that ord(a) | |S|, and so |S|
![]() 0 (mod t),
where t = ord(a).
0 (mod t),
where t = ord(a).
Draw the group operation
tables for the groups (Z4, +4) and ![]() . Show that
these groups are isomorphic by exhibiting a one-to-one correspondence
. Show that
these groups are isomorphic by exhibiting a one-to-one correspondence ![]() between their
elements such that a + b
between their
elements such that a + b ![]() c (mod 4)
if and only if
c (mod 4)
if and only if ![]() (a).
(a). ![]() (b)
(b) ![]()
![]() (c)
(mod 5).
(c)
(mod 5).
Prove Theorem 14.
Show that if p is prime and e is a positive integer, then
Show that for any n
> 1 and for any ![]() , the
function fa:
, the
function fa: ![]() defined by fa(x)
= ax mod n is a permutation of
defined by fa(x)
= ax mod n is a permutation of ![]() .
.
List all of the subgroups
of Z9 and of ![]() .
.
We now consider the problem of finding solutions to the equation
axwhere n > 0, an important practical problem. We assume that a, b, and n are given, and we are to find the x's, modulo n, that satisfy equation (22). There may be zero, one, or more than one such solution.
Let ![]() a
a![]() denote the
subgroup of Zn generated by a. Since
denote the
subgroup of Zn generated by a. Since ![]() a
a![]() = = , equation (22) has
a solution if and only if b
= = , equation (22) has
a solution if and only if b ![]()
![]() a
a![]() . Lagrange's
theorem (Theorem 15) tells us that |
. Lagrange's
theorem (Theorem 15) tells us that |![]() a
a![]() | must be a
divisor of n. The following theorem gives us a precise characterization
of
| must be a
divisor of n. The following theorem gives us a precise characterization
of ![]() a
a![]() .
.
Theorem 20
For any positive integers a and n, if d = gcd(a, n), then
and thus
|Proof We begin by showing that d ![]()
![]() a
a![]() . Observe that
EXTENDED EUCLID(a,
n) produces integers x' and y' such that ax' + ny' = d. Thus, ax'
. Observe that
EXTENDED EUCLID(a,
n) produces integers x' and y' such that ax' + ny' = d. Thus, ax' ![]() d (mod n), so
that d
d (mod n), so
that d ![]()
![]() a
a![]() .
.
Since d ![]()
![]() a
a![]() , it follows
that every multiple of d belongs to
, it follows
that every multiple of d belongs to ![]() a
a![]() , because a
multiple of a multiple of a is a multiple of a. Thus,
, because a
multiple of a multiple of a is a multiple of a. Thus, ![]() a
a![]() contains
every element in .
That is,
contains
every element in .
That is, ![]() d
d![]()
![]()
![]() a
a![]() .
.
We now show that ![]() a
a![]()
![]()
![]() d
d![]() . If m
. If m ![]()
![]() a
a![]() , then m =
ax mod n for some integer x, and so m = ax + ny for
some integer y. However, d | a and d | n, and so
d | m by equation (6). Therefore, m
, then m =
ax mod n for some integer x, and so m = ax + ny for
some integer y. However, d | a and d | n, and so
d | m by equation (6). Therefore, m ![]()
![]() d
d![]() .
.
Combining these results,
we have that ![]() a
a![]() =
= ![]() d
d![]() . To see that |
. To see that |![]() (a
(a![]() | = n/d,
observe that there are exactly n/d multiples of d between
0 and n - 1, inclusive.
| = n/d,
observe that there are exactly n/d multiples of d between
0 and n - 1, inclusive.
Corollary 21
The equation ax ![]() b (mod n)
is solvable for the unknown x if and only if gcd(a, n) | b.
b (mod n)
is solvable for the unknown x if and only if gcd(a, n) | b.
Corollary 22
The equation ax ![]() b (mod n)
either has d distinct solutions modulo n, where d = gcd(a,
n), or it has no solutions.
b (mod n)
either has d distinct solutions modulo n, where d = gcd(a,
n), or it has no solutions.
Proof If ax ![]() b (mod n)
has a solution, then b
b (mod n)
has a solution, then b ![]()
![]() a
a![]() . The sequence
ai mod n, for i = 0,1, . . . , is periodic with period |
. The sequence
ai mod n, for i = 0,1, . . . , is periodic with period |![]() a
a![]() | = n/d,
by Corollary 18. If b
| = n/d,
by Corollary 18. If b ![]()
![]() a
a![]() , then b
appears exactly d times in the sequence ai mod n, for i
= 0,1, . . . , n - 1, since the length-(n/d) block of values
( a) is repeated exactly d times as i increases from 0 to n
- 1. The indices x of these d positions are the solutions of the
equation ax
, then b
appears exactly d times in the sequence ai mod n, for i
= 0,1, . . . , n - 1, since the length-(n/d) block of values
( a) is repeated exactly d times as i increases from 0 to n
- 1. The indices x of these d positions are the solutions of the
equation ax ![]() b (mod
n).
b (mod
n).
Theorem 23
Let d = gcd(a, n), and
suppose that d = ax' + ny' for some integers x' and y' (for example, as
computed by EXTENDED EUCLID).
If d | b, then the equation ax ![]() b (mod n) has
as one of its solutions the value x0, where
b (mod n) has
as one of its solutions the value x0, where
Proof Since ax' ![]() d (mod n),
we have
d (mod n),
we have
and thus x0
is a solution to ax ![]() b (mod n).
b (mod n).
Theorem 24
Suppose that the equation
ax ![]() b (mod
n) is solvable (that is, d | b, where d = gcd(a, n))
and that x0 is any solution to this equation. Then, this
equation has exactly d distinct solutions, modulo n, given by xi
= x0 + i(n/d) for i = 1, 2, . . . , d
- 1.
b (mod
n) is solvable (that is, d | b, where d = gcd(a, n))
and that x0 is any solution to this equation. Then, this
equation has exactly d distinct solutions, modulo n, given by xi
= x0 + i(n/d) for i = 1, 2, . . . , d
- 1.
Proof Since n/d > 0 and 0 ![]() i( n/d)
< n for i = 0, 1, . . . , d - 1, the values x0,x1,
. . . , xd-1 are all distinct, modulo n. By
the periodicity of the sequence ai mod n (Corollary 18), if x0
is a solution of ax
i( n/d)
< n for i = 0, 1, . . . , d - 1, the values x0,x1,
. . . , xd-1 are all distinct, modulo n. By
the periodicity of the sequence ai mod n (Corollary 18), if x0
is a solution of ax ![]() b (mod n),
then every xi is a solution. By Corollary 22, there are
exactly d solutions, so that x0,xl,
. . . , xd-1 must be all of them.
b (mod n),
then every xi is a solution. By Corollary 22, there are
exactly d solutions, so that x0,xl,
. . . , xd-1 must be all of them.
We have now developed the
mathematics needed to solve the equation ax ![]() b (mod n);
the following algorithm prints all solutions to this equation. The inputs a
and b are arbitrary integers, and n is an arbitrary positive
integer.
b (mod n);
the following algorithm prints all solutions to this equation. The inputs a
and b are arbitrary integers, and n is an arbitrary positive
integer.
As an example of the operation
of this procedure, consider the equation 14x ![]() 30 (mod 100)
(here, a = 14, b = 30, and n = 100). Calling EXTENDED EUCLID in line 1, we obtain (d,
x, y) = (2,-7,1). Since 2
30 (mod 100)
(here, a = 14, b = 30, and n = 100). Calling EXTENDED EUCLID in line 1, we obtain (d,
x, y) = (2,-7,1). Since 2 ![]() 30, lines 3-5
are executed. In line 3, we compute x0 = (-7)(15) mod 100 =
95. The loop on lines 4-5 prints the two solutions: 95 and 45.
30, lines 3-5
are executed. In line 3, we compute x0 = (-7)(15) mod 100 =
95. The loop on lines 4-5 prints the two solutions: 95 and 45.
The procedure MODULAR LINEAR EQUATION SOLVER works as follows. Line 1
computes d = gcd(a, n) as well as two values x'' and y''
such that d = ax' + ny', demonstrating that x'' is a
solution to the equation ax' ![]() d (mod n).
If d does not divide b, then the equation ax
d (mod n).
If d does not divide b, then the equation ax ![]() b (mod n)
has no solution, by Corollary 21. Line 2 checks if d
b (mod n)
has no solution, by Corollary 21. Line 2 checks if d ![]() b; if
not, line 6 reports that there are no solutions. Otherwise, line 3 computes a
solution x0 to equation (22), in accordance with Theorem 23.
Given one solution, Theorem 24 states that the other d - 1 solutions can
be obtained by adding multiples of (n/d), modulo n. The for
loop of lines 4-5 prints out all d solutions, beginning with x0
and spaced (n/d) apart, modulo n.
b; if
not, line 6 reports that there are no solutions. Otherwise, line 3 computes a
solution x0 to equation (22), in accordance with Theorem 23.
Given one solution, Theorem 24 states that the other d - 1 solutions can
be obtained by adding multiples of (n/d), modulo n. The for
loop of lines 4-5 prints out all d solutions, beginning with x0
and spaced (n/d) apart, modulo n.
The running time of MODULAR LINEAR EQUATION SOLVER is O(lg n + gcd(a,n)) arithmetic operations, since EXTENDED EUCLID takes O(lg n) arithmetic operations, and each iteration of the for loop of lines 4-5 takes a constant number of arithmetic operations.
The following corollaries of Theorem 24 give specializations of particular interest.
Corollary 25
For any n > 1,
if gcd(a,n) = 1, then the equation ax ![]() b (mod
n) has a unique solution modulo n.
b (mod
n) has a unique solution modulo n.
If b = 1, a common case of considerable interest, the x we are looking for is a multiplicative inverse of a, modulo n.
Corollary 26
For any n > 1, if gcd(a, n) = 1, then the equation
axhas a unique solution, modulo n. Otherwise, it has no solution.
Corollary 26 allows us to
use the notation (a-1 mod n) to refer to the
multiplicative inverse of a, modulo n, when a and n
are relatively prime. If gcd(a, n) = 1, then one solution to the
equation ax ![]() 1 (mod n)
is the integer x returned by EXTENDED EUCLID,
since the equation
1 (mod n)
is the integer x returned by EXTENDED EUCLID,
since the equation
implies ax ![]() 1 (mod n).
Thus, (a-1 mod n) can be computed efficiently
using EXTENDED EUCLID
1 (mod n).
Thus, (a-1 mod n) can be computed efficiently
using EXTENDED EUCLID
Find all solutions to the
equation 35x ![]() 10 (mod 50).
10 (mod 50).
Prove that the equation ax
![]() ay (mod
n) implies x
ay (mod
n) implies x ![]() y (mod n)
whenever gcd(a, n) = 1. Show that the condition gcd(a, n) = 1 is
necessary by supplying a counterexample with gcd(a, n) > 1.
y (mod n)
whenever gcd(a, n) = 1. Show that the condition gcd(a, n) = 1 is
necessary by supplying a counterexample with gcd(a, n) > 1.
Consider the following change to line 3 of MODULAR LINEAR EQUATiON SOLVER
3 then x0Will this work? Explain why or why not.
Around A.D. 100, the Chinese mathematician ![]() solved the
problem of finding those integers x that leave remainders 2, 3, and 2
when divided by 3, 5, and 7 respectively. One such solution is x = 23;
all solutions are of the form 23 + 105k for arbitrary integers k.
The 'Chinese remainder theorem' provides a correspondence between a
system of equations modulo a set of pairwise relatively prime moduli (for
example, 3, 5, and 7) and an equation modulo their product (for example, 105).
solved the
problem of finding those integers x that leave remainders 2, 3, and 2
when divided by 3, 5, and 7 respectively. One such solution is x = 23;
all solutions are of the form 23 + 105k for arbitrary integers k.
The 'Chinese remainder theorem' provides a correspondence between a
system of equations modulo a set of pairwise relatively prime moduli (for
example, 3, 5, and 7) and an equation modulo their product (for example, 105).
The Chinese remainder theorem has two major uses. Let the integer n = nl n2 . . . nk, where the factors ni are pairwise relatively prime. First, the Chinese remainder theorem is a descriptive 'structure theorem' that describes the structure of Zn as identical to that of the Cartesian product Zn1 XZn2 X . . . X Znk with componentwise addition and multiplication modulo ni in the ith component. Second, this description can often be used to yield efficient algorithms, since working in each of the systems Zni can be more efficient (in terms of bit operations) than working modulo n.
Theorem 27
Let n = n1 n2 . . . nk, where the ni are pairwise relatively prime. Consider the correspondence
awhere a ![]() Zn, ai
Zn, ai ![]() Zni, and
Zni, and
for i = 1, 2, . . . , k. Then, mapping (25) is a one-to-one correspondence (bijection) between Zn and the Cartesian product ZniXZn2 X . . . X Znk. Operations performed on the elements of Zn can be equivalently performed on the corresponding k-tuples by performing the operations independently in each coordinate position in the appropriate system. That is, if
athen
(a + b) mod nProof Transforming between the two representations is quite straight-forward.
Going from a to (al, a2, . . . , ak)
requires only k divisions. Computing a from inputs (al,
a2, . . . , ak) is almost as easy, using
the following formula. Let mi = n/ni
for i = 1,2, . . . , k. Note that mi =
nln2 . . . ni-lni+l
. . . nk, so that mi ![]() 0
(mod nj) for all j
0
(mod nj) for all j ![]() i.
Then, letting
i.
Then, letting
for i = 1, 2, . . . , k, we have
aEquation 29 is well
defined, since mi and ni are
relatively prime (by Theorem 6), and so Corollary 26 implies that (mi-l
mod ni) is defined. To verify equation (30), note that cj
![]() mj
mj
![]() 0 (mod
ni) if j
0 (mod
ni) if j ![]() i, and that
ci
i, and that
ci ![]() 1 (mod
ni). Thus, we have the correspondence
1 (mod
ni). Thus, we have the correspondence
a vector that has 0's everywhere except in the ith coordinate, where it has a 1. The ci thus form a 'basis' for the representation, in a certain sense. For each i, therefore, we have
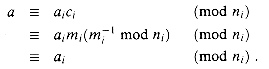
Since we can transform in both directions, the correspondence is one-to-one. Equations (26)--(28) follow directly from Exercise 1-6, since x mod ni = (x mod n) mod ni for any x and i = 1, 2, . . . , k.
The following corollaries will be used later in this chapter.
Corollary 28
If n1, n2, . . . , nk are pairwise relatively prime and n = n1n2nk, then for any integers a1, a2, . . . , ak, the set of simultaneous equations
xfor i = 1, 2, . . . , k, has a unique solution modulo n for the unknown x.
Corollary 29
If n1, n2, . . . , nk are pairwise relatively prime and n = n1 n2 . . . nk, then for all integers x and a,
for i = 1, 2, . . . , k if and only if
xAs an example of the Chinese remainder theorem, suppose we are given the two equations
aso that a1
= 2, n1 = m2 = 5, a2 = 3,
and n2 = m1 = 13, and we wish to compute a
mod 65, since n = 65. Because 13-1 ![]() 2 (mod 5) and
5-1
2 (mod 5) and
5-1 ![]() 8 (mod 13), we
have
8 (mod 13), we
have
and
aSee Figure 3 for an illustration of the Chinese remainder theorem, modulo 65.
Thus, we can work modulo n by working modulo n directly or by working in the transformed representation using separate modulo ni computations, as convenient. The computations are entirely equivalent.
Find all solutions to the
equations x ![]() 4 (mod 5) and x
4 (mod 5) and x
![]() 5 (mod 11).
5 (mod 11).
Find all integers x that leave remainders 1, 2, 3, 4, 5 when divided by 2, 3, 4, 5, 6, respectively.
Argue that, under the definitions of Theorem 27, if gcd(a, n) = 1, then
![]()
Under the definitions of
Theorem 27, prove that the number of roots of the equation f(x) ![]() 0 (mod n)
is equal to the product of the number of roots of each the equations f(x)
0 (mod n)
is equal to the product of the number of roots of each the equations f(x)
![]() 0 (mod n1),
f(x)
0 (mod n1),
f(x) ![]() 0 (mod n2),
. . . , f(x)
0 (mod n2),
. . . , f(x) ![]() 0 (mod nk).
0 (mod nk).
Just as it is natural to consider the
multiples of a given element a, modulo n, it is often natural to
consider the sequence of powers of a, modulo n, where ![]() :
:
modulo n. Indexing from 0, the 0th value in this sequence is a0 mod n = 1, and the ith value is ai mod n. For example, the powers of 3 modulo 7 are
i 0 1 2 3 4 5 6 7 8 9 10 11whereas the powers of 2 modulo 7 are
i 0 1 2 3 4 5 6 7 8 9 10 11In this section, let ![]() a
a![]() denote the
subgroup of
denote the
subgroup of ![]() generated by a,
and let ordn (a) (the 'order of a, modulo n')
denote the order of a in
generated by a,
and let ordn (a) (the 'order of a, modulo n')
denote the order of a in ![]() . For example,
. For example,
![]() 2
2![]() =
in
=
in ![]() , and ord7
(2) = 3. Using the definition of the Euler phi function
, and ord7
(2) = 3. Using the definition of the Euler phi function ![]() (n) as
the size of
(n) as
the size of ![]() (see Section 3),
we now translate Corollary 19 into the notation of
(see Section 3),
we now translate Corollary 19 into the notation of ![]() to obtain
Euler's theorem and specialize it to
to obtain
Euler's theorem and specialize it to ![]() , where p
is prime, to obtain Fermat's theorem.
, where p
is prime, to obtain Fermat's theorem.
Theorem 30
For any integer n > 1,
![]()
Theorem 31
If p is prime, then
![]()
Proof By equation (21), ![]() (p) = p
- 1 if p is prime.
(p) = p
- 1 if p is prime.
This corollary applies to
every element in Zp except 0, since ![]() . For all a
. For all a
![]() Zp,
however, we have ap
Zp,
however, we have ap ![]() a (mod p)
if p is prime.
a (mod p)
if p is prime.
If ![]() , then every
element in
, then every
element in ![]() is a power of g,
modulo n, and we say that g is a primitive root or
a generator of
is a power of g,
modulo n, and we say that g is a primitive root or
a generator of ![]() . For example,
3 is a primitive root, modulo 7. If
. For example,
3 is a primitive root, modulo 7. If ![]() possesses a
primitive root, we say that the group
possesses a
primitive root, we say that the group ![]() is cyclic.
We omit the proof of the following theorem, which is proven by Niven and
Zuckerman [151].
is cyclic.
We omit the proof of the following theorem, which is proven by Niven and
Zuckerman [151].
Theorem 32
The values of n
> 1 for which ![]() is cyclic are
2, 4, pe, and 2pe, for all odd primes p
and all positive integers e.
is cyclic are
2, 4, pe, and 2pe, for all odd primes p
and all positive integers e.
If g is a primitive root of ![]() and a
is any element of
and a
is any element of ![]() , then there
exists a z such that gz
, then there
exists a z such that gz ![]() a (mod n).
This z is called the discrete logarithm or index
of a, modulo n, to the base g; we denote this value as indn,g(a).
a (mod n).
This z is called the discrete logarithm or index
of a, modulo n, to the base g; we denote this value as indn,g(a).
Theorem 33
Proof Suppose first that x ![]() y (mod
y (mod ![]() (n)).
Then, x = y + k
(n)).
Then, x = y + k![]() (n) for
some integer k. Therefore,
(n) for
some integer k. Therefore,
Conversely, suppose that gx
![]() gy
(mod n). Because the sequence of powers of g generates every
element of
gy
(mod n). Because the sequence of powers of g generates every
element of ![]() g
g![]() and |
and |![]() g
g![]() | =
| = ![]() (n),
Corollary 18 implies that the sequence of powers of g is periodic with
period
(n),
Corollary 18 implies that the sequence of powers of g is periodic with
period ![]() (n).
Therefore, if gx
(n).
Therefore, if gx ![]() gy
(mod n), then we must have x
gy
(mod n), then we must have x ![]() y (mod
y (mod ![]() (n)).
(n)).
Taking discrete logarithms can sometimes simplify reasoning about a modular equation, as illustrated in the proof of the following theorem.
Theorem 34
If p is an odd
prime and e ![]() 1, then the
equation
1, then the
equation
has only two solutions, namely x = 1 and x = - 1.
Proof Let n = pe. Theorem 32 implies that ![]() has a
primitive root g. Equation (34) can be written
has a
primitive root g. Equation (34) can be written
After noting that indn,g(1) = 0, we observe that Theorem 33 implies that equation (35) is equivalent to
2To solve this equation
for the unknown indn,g(x), we apply the methods of
Section 4. Letting d = gcd(2, ![]() (n)) =
gcd(2, (p - 1)pe-1) = 2, and noting that d
| 0, we find from Theorem 24 that equation (36) has exactly d = 2
solutions. Therefore, equation (34) has exactly 2 solutions, which are x
= 1 and x = - 1 by inspection.
(n)) =
gcd(2, (p - 1)pe-1) = 2, and noting that d
| 0, we find from Theorem 24 that equation (36) has exactly d = 2
solutions. Therefore, equation (34) has exactly 2 solutions, which are x
= 1 and x = - 1 by inspection.
A number x is a nontrivial
square root of 1, modulo n, if it satisfies the equation x2
![]() 1 (mod n)
but x is equivalent to neither of the two 'trivial' square
roots: 1 or -1, modulo n. For example, 6 is a nontrivial square root of
1, modulo 35. The following corollary to Theorem 34 will be used in the
correctness proof for the Miller-Rabin primality-testing procedure in Section 8.
1 (mod n)
but x is equivalent to neither of the two 'trivial' square
roots: 1 or -1, modulo n. For example, 6 is a nontrivial square root of
1, modulo 35. The following corollary to Theorem 34 will be used in the
correctness proof for the Miller-Rabin primality-testing procedure in Section 8.
Corollary 35
If there exists a nontrivial square root of 1, modulo n, then n is composite.
Proof This corollary is just the contrapositive to Theorem 34. If there exists a nontrivial square root of 1, modulo n, then n can't be a prime or a power of a prime.
A frequently occurring operation in number-theoretic computations is raising one number to a power modulo another number, also known as modular exponentiation. More precisely, we would like an efficient way to compute ab mod n, where a and b are nonnegative integers and n is a positive integer. Modular exponentiation is also an essential operation in many primality-testing routines and in the RSA public-key cryptosystem. The method of repeated squaring solves this problem efficiently using the binary representation of b.
Let ![]() bk,
bk-1, . . . , b1,b0
bk,
bk-1, . . . , b1,b0![]() be the binary
representation of b. (That is, the binary representation is k + 1
bits long, bk is the most significant bit, and b0
is the least significant bit.) The following procedure computes ac
mod n as c is increased by doublings and incrementations from 0
to b.
be the binary
representation of b. (That is, the binary representation is k + 1
bits long, bk is the most significant bit, and b0
is the least significant bit.) The following procedure computes ac
mod n as c is increased by doublings and incrementations from 0
to b.
Each exponent computed in a sequence is either twice the previous exponent or one more than the previous exponent; the binary representation
i 9 8 7 6 5 4 3 2 1 0of b is read from right to left to control which operations are performed. Each iteration of the loop uses one of the identities
a2c mod n = (ac)2 mod n ,depending on whether bi
= 0 or 1, respectively. The essential use of squaring in each iteration
explains the name 'repeated squaring.' Just after bit bi
is read and processed, the value of c is the same as the prefix ![]() bk,
bk-1, . . . , bi
bk,
bk-1, . . . , bi![]() of the binary
representation of b. As an example, for a = 7, b = 560,
and n = 561, the algorithm computes the sequence of values modulo 561
shown in Figure 4; the sequence of exponents used is shown in row c of
the table.
of the binary
representation of b. As an example, for a = 7, b = 560,
and n = 561, the algorithm computes the sequence of values modulo 561
shown in Figure 4; the sequence of exponents used is shown in row c of
the table.
The variable c is
not really needed by the algorithm but is included for explanatory purposes:
the algorithm preserves the invariant that d = ac mod n
as it increases c by doublings and incrementations until c = b.
If the inputs a, b, and n are ![]() -bit numbers,
then the total number of arithmetic operations required is O(
-bit numbers,
then the total number of arithmetic operations required is O(![]() ) and the
total number of bit operations required is O(
) and the
total number of bit operations required is O(![]() 3).
3).
Draw a table showing the
order of every element in ![]() . Pick the
smallest primitive root g and compute a table giving ind11,g (x)
for all x
. Pick the
smallest primitive root g and compute a table giving ind11,g (x)
for all x ![]()
![]() .
.
Give a modular exponentiation algorithm that examines the bits of b from right to left instead of left to right.
Explain how to compute a
-1 mod n for any ![]() using the
procedure MODULAR EXPONENTIATION, assuming that you
know
using the
procedure MODULAR EXPONENTIATION, assuming that you
know ![]() (n).
(n).
A public-key cryptosystem can be used to encrypt messages sent between two communicating parties so that an eavesdropper who overhears the encrypted messages will not be able to decode them. A public-key cryptosystem also enables a party to append an unforgeable 'digital signature' to the end of an electronic message. Such a signature is the electronic version of a handwritten signature on a paper document. It can be easily checked by anyone, forged by no one, yet loses its validity if any bit of the message is altered. It therefore provides authentication of both the identity of the signer and the contents of the signed message. It is the perfect tool for electronically signed business contracts, electronic checks, electronic purchase orders, and other electronic communications that must be authenticated.
The RSA public-key cryptosystem is based on the dramatic difference between the ease of finding large prime numbers and the difficulty of factoring the product of two large prime numbers. Section 8 describes an efficient procedure for finding large prime numbers, and Section 9 discusses the problem of factoring large integers.
In a public-key cryptosystem, each participant has both a public key and a secret key. Each key is a piece of information. For example, in the RSA cryptosystem, each key consists of a pair of integers. The participants 'Alice' and 'Bob' are traditionally used in cryptography examples; we denote their public and secret keys as PA, SA for Alice and PB, SB for Bob.
Each participant creates his own public and secret keys. Each keeps his secret key secret, but he can reveal his public key to anyone or even publish it. In fact, it is often convenient to assume that everyone's public key is available in a public directory, so that any participant can easily obtain the public key of any other participant.
The public and secret
keys specify functions that can be applied to any message. Let ![]() denote the set
of permissible messages. For example,
denote the set
of permissible messages. For example, ![]() might be the
set of all finite-length bit sequences. We require that the public and secret
keys specify one-to-one functions from
might be the
set of all finite-length bit sequences. We require that the public and secret
keys specify one-to-one functions from ![]() to itself. The
function corresponding to Alice's public key PA is denoted PA(
), and the function corresponding to her secret key SA is
denoted SA( ). The functions PA( ) and SA(
) are thus permutations of
to itself. The
function corresponding to Alice's public key PA is denoted PA(
), and the function corresponding to her secret key SA is
denoted SA( ). The functions PA( ) and SA(
) are thus permutations of ![]() . We assume
that the functions PA( ) and SA( ) are
efficiently computable given the corresponding key PA or SA.
. We assume
that the functions PA( ) and SA( ) are
efficiently computable given the corresponding key PA or SA.
The public and secret keys for any participant are a 'matched pair' in that they specify functions that are inverses of each other. That is,
M = SA(PA(M)) ,for any message ![]() . Transforming
M with the two keys PA and SA successively,
in either order, yields the message M back.
. Transforming
M with the two keys PA and SA successively,
in either order, yields the message M back.
In a public-key cryptosystem, it is essential that no one but Alice be able to compute the function SA( ) in any practical amount of time. The privacy of mail that is encrypted and sent to Alice and the authenticity of Alice's digital signatures rely on the assumption that only Alice is able to compute SA( ). This requirement is why Alice keeps SA secret; if she does not, she loses her uniqueness and the cryptosystem cannot provide her with unique capabilities. The assumption that only Alice can compute SA( ) must hold even though everyone knows PA and can compute PA( ), the inverse function to SA( ), efficiently. The major difficulty in designing a workable public-key cryptosystem is in figuring out how to create a system in which we can reveal a transformation PA( ) without thereby revealing how to compute the corresponding inverse transformation SA( ).
In a public-key cryptosystem, encryption works as follows. Suppose Bob wishes to send Alice a message M encrypted so that it will look like unintelligible gibberish to an eavesdropper. The scenario for sending the message goes as follows.
![]() Bob obtains Alice's public key PA (from a public
directory or directly from Alice).
Bob obtains Alice's public key PA (from a public
directory or directly from Alice).
![]() Bob computes the ciphertext C = PA(M)
corresponding to the message M and sends C to Alice.
Bob computes the ciphertext C = PA(M)
corresponding to the message M and sends C to Alice.
![]() When Alice receives the ciphertext C, she applies her secret key
SA to retrieve the original message: M = SA(C).
When Alice receives the ciphertext C, she applies her secret key
SA to retrieve the original message: M = SA(C).
Figure 5 illustrates this process. Because SA( ) and PA( ) are inverse functions, Alice can compute M from C. Because only Alice is able to compute SA( ), only Alice can compute M from C. The encryption of M using PA( ) has protected M from disclosure to anyone except Alice.
Digital signatures are similarly easy to implement in a public-key cryptosystem. Suppose now that Alice wishes to send Bob a digitally signed response M'. The digital-signature scenario proceeds as follows.
![]() Alice computes her digital signature
Alice computes her digital signature ![]() for the
message M' using her secret key SA and the equation
for the
message M' using her secret key SA and the equation ![]() = SA(M').
= SA(M').
![]() Alice sends the message/signature pair (M',
Alice sends the message/signature pair (M',![]() ) to Bob.
) to Bob.
![]() When Bob receives (M',
When Bob receives (M',![]() ), he can verify
that it originated from Alice using Alice's public key by verifying the
equation M' = PA(
), he can verify
that it originated from Alice using Alice's public key by verifying the
equation M' = PA(![]() ).
(Presumably, M' contains Alice's name, so Bob knows whose public key to
use.) If the equation holds, then Bob concludes that the message M' was
actually signed by Alice. If the equation doesn't hold, Bob concludes either
that the message M' or the digital signature
).
(Presumably, M' contains Alice's name, so Bob knows whose public key to
use.) If the equation holds, then Bob concludes that the message M' was
actually signed by Alice. If the equation doesn't hold, Bob concludes either
that the message M' or the digital signature ![]() was corrupted
by transmission errors or that the pair (M',
was corrupted
by transmission errors or that the pair (M', ![]() ) is an
attempted forgery.
) is an
attempted forgery.
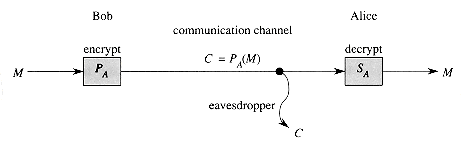
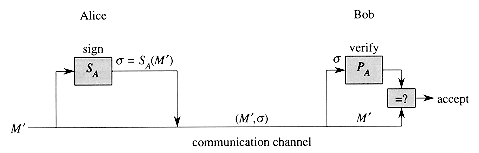
Figure 6 illustrates this process. Because a digital signature provides both authentication of the signer's identity and authentication of the contents of the signed message, it is analogous to a handwritten signature at the end of a written document.
An important property of a digital signature is that it is verifiable by anyone who has access to the signer's public key. A signed message can be verified by one party and then passed on to other parties who can also verify the signature. For example, the message might be an electronic check from Alice to Bob. After Bob verifies Alice's signature on the check, he can give the check to his bank, who can then also verify the signature and effect the appropriate funds transfer.
We note that a signed message is not encrypted; the message is 'in the clear' and is not protected from disclosure. By composing the above protocols for encryption and for signatures, we can create messages that are both signed and encrypted. The signer first appends his digital signature to the message and then encrypts the resulting message/signature pair with the public key of the intended recipient. The recipient decrypts the received message with his secret key to obtain both the original message and its digital signature. He can then verify the signature using the public key of the signer. The corresponding combined process using paper-based systems is to sign the paper document and then seal the document inside a paper envelope that is opened only by the intended recipient.
In the RSA public-key cryptosystem, a participant creates his public and secret keys with the following procedure.
1. Select at random two large prime numbers p and q. The primes p and q might be, say, 100 decimal digits each.
2. Compute n by the equation n = pq.
3. Select a small odd
integer e that is relatively prime to ![]() (n),
which, by equation (20), equals (p-1)(q - 1).
(n),
which, by equation (20), equals (p-1)(q - 1).
4. Compute d as
the multiplicative inverse of e, modulo ![]() (n).
(Corollary 26 guarantees that d exists and is uniquely defined.)
(n).
(Corollary 26 guarantees that d exists and is uniquely defined.)
5. Publish the pair P = (e, n,) as his RSA public key.
6. Keep secret the pair S = (d, n) as his RSA secret key.
For this scheme, the
domain ![]() is the set Zn.
The transformation of a message M associated with a public key P
= (e, n) is
is the set Zn.
The transformation of a message M associated with a public key P
= (e, n) is
The transformation of a ciphertext C associated with a secret key S = (d, n) is
S(C) = Cd (mod n) .These equations apply to both encryption and signatures. To create a signature, the signer applies his secret key to the message to be signed, rather than to a ciphertext. To verify a signature, the public key of the signer is applied to it, rather than to a message to be encrypted.
The public-key and
secret-key operations can be implemented using the procedure MODULAR EXPONENTIATION described in
Section 6. To analyze the running time of these operations, assume that the
public key (e,n) and secret key (d,n) satisfy |e| = O(1),
|d| = |n| = ![]() . Then,
applying a public key requires O(1) modular multiplications and uses O(
. Then,
applying a public key requires O(1) modular multiplications and uses O(![]() 2)
bit operations. Applying a secret key requires O(
2)
bit operations. Applying a secret key requires O(![]() ) modular
multiplications, using O(
) modular
multiplications, using O(![]() 3)
bit operations.
3)
bit operations.
Theorem 36
The RSA equations (39) and (40) define inverse transformations of Zn satisfying equations (37) and (38).
Proof From equations (39) and (40), we have that for any M ![]() Zn,
Zn,
Since e and d
are multiplicative inverses modulo ![]() (n) = (p - 1)(q -
1),
(n) = (p - 1)(q -
1),
for some integer k.
But then, if ![]() (mod p),
we have (using Theorem 31)
(mod p),
we have (using Theorem 31)
Also, Med
![]() M (mod p)
if M
M (mod p)
if M ![]() 0 (mod p).
Thus,
0 (mod p).
Thus,
for all M. Similarly,
Medfor all M. Thus, by Corollary 29 to the Chinese remainder theorem,
Medfor all M.
The security of the RSA cryptosystem rests in large part on the difficulty of factoring large integers. If an adversary can factor the modulus n in a public key, then he can derive the secret key from the public key, using the knowledge of the factors p and q in the same way that the creator of the public key used them. So if factoring large integers is easy, then breaking the RSA cryptosystem is easy. The converse statement, that if factoring large integers is hard, then breaking RSA is hard, is unproven. After a decade of research, however, no easier method has been found to break the RSA public-key cryptosystem than to factor the modulus n. And as we shall see in Section 9, the factoring of large integers is surprisingly difficult. By randomly selecting and multiplying together two 100-digit primes, one can create a public key that cannot be 'broken' in any feasible amount of time with current technology. In the absence of a fundamental breakthrough in the design of number-theoretic algorithms, the RSA cryptosystem is capable of providing a high degree of security in applications.
In order to achieve security with the RSA cryptosystem, however, it is necessary to work with integers that are 100-200 digits in length, since factoring smaller integers is not impractical. In particular, we must be able to find large primes efficiently, in order to create keys of the necessary length. This problem is addressed in Section 8.
For efficiency, RSA is often used in a 'hybrid' or 'key-management' mode with fast non-public-key cryptosystems. With such a system, the encryption and decryption keys are identical. If Alice wishes to send a long message M to Bob privately, she selects a random key K for the fast non-public-key cryptosystem and encrypts M using K, obtaining ciphertext C. Here, C is as long as M, but K is quite short. Then, she encrypts K using Bob's public RSA key. Since K is short, computing PB(K) is fast (much faster than computing PB(M)). She then transmits (C, PB(K)) to Bob, who decrypts PB(K) to obtain K and then uses K to decrypt C, obtaining M.
A similar hybrid approach is often used to make digital signatures efficiently. In this approach, RSA is combined with a public one-way hash function h--a function that is easy to compute but for which it is computationally infeasible to find two messages M and M' such that h(M) = h(M'). The value h(M) is a short (say, 128-bit) 'fingerprint' of the message M. If Alice wishes to sign a message M, she first applies h to M to obtain the fingerprint h(M), which she then signs with her secret key. She sends (M, SA(h(M))) to Bob as her signed version of M. Bob can verify the signature by computing h(M) and verifying that PA applied to SA(h(M)) as received equals h(M). Because no one can create two messages with the same fingerprint, it is impossible to alter a signed message and preserve the validity of the signature.
Consider an RSA key set with p = 11, q = 29, n = 319, and e = 3. What value of d should be used in the secret key? What is the encryption of the message M = 100?
Prove that if Alice's public exponent e is 3 and an adversary obtains Alice's secret exponent d, then the adversary can factor Alice's modulus n in time polynomial in the number of bits in n. (Although you are not asked to prove it, you may be interested to know that this result remains true even if the condition e = 3 is removed. See Miller [147].)
Prove that RSA is multiplicative in the sense that
PA(M1)PA(M2)Use this fact to prove that if an adversary had a procedure that could efficiently decrypt 1 percent of messages randomly chosen from Zn and encrypted with PA, then he could employ a probabilistic algorithm to decrypt every message encrypted with PA with high probability.
In this section, we consider the problem of finding large primes. We begin with a discussion of the density of primes, proceed to examine a plausible (but incomplete) approach to primality testing, and then present an effective randomized primality test due to Miller and Rabin.
For many applications (such as cryptography), we need to find large
'random' primes. Fortunately, large primes are not too rare, so that
it is not too time-consuming to test random integers of the appropriate size
until a prime is found. The prime distribution function ![]() (n)
specifies the number of primes that are less than or equal to n. For
example,
(n)
specifies the number of primes that are less than or equal to n. For
example, ![]() (10) = 4,
since there are 4 prime numbers less than or equal to 10, namely, 2, 3, 5, and
7. The prime number theorem gives a useful approximation to
(10) = 4,
since there are 4 prime numbers less than or equal to 10, namely, 2, 3, 5, and
7. The prime number theorem gives a useful approximation to ![]() (n).
(n).
Theorem 37
![]()
The approximation n/
ln n gives reasonably accurate estimates of ![]() (n)
even for small n. For example, it is off by less than 6% at n =
109, where
(n)
even for small n. For example, it is off by less than 6% at n =
109, where ![]() (n) =
50,847,478 and n/ ln n = 48,254,942. (To a number theorist, 109
is a small number.)
(n) =
50,847,478 and n/ ln n = 48,254,942. (To a number theorist, 109
is a small number.)
We can use the prime
number theorem to estimate the probability that a randomly chosen integer n
will turn out to be prime as 1/ ln n. Thus, we would need to examine
approximately ln n integers chosen randomly near n in order to
find a prime that is of the same length as n. For example, to find a
100-digit prime might require testing approximately ln 10100 ![]() 230 randomly
chosen 100-digit numbers for primality. (This figure can be cut in half by
choosing only odd integers.)
230 randomly
chosen 100-digit numbers for primality. (This figure can be cut in half by
choosing only odd integers.)
In the remainder of this section, we consider the problem of determining whether or not a large odd integer n is prime. For notational convenience, we assume that n has the prime factorization
![]()
where r ![]() 1 and p1,
p2,. . . ., pr are the prime factors of n.
Of course, n is prime if and only if r = 1 and e1
= 1.
1 and p1,
p2,. . . ., pr are the prime factors of n.
Of course, n is prime if and only if r = 1 and e1
= 1.
One simple approach to the problem of
testing for primality is trial division. We try dividing n
by each integer ![]() . (Again, even
integers greater than 2 may be skipped.) It is easy to see that n is
prime if and only if none of the trial divisors divides n. Assuming that
each trial division takes constant time, the worst-case running time is
. (Again, even
integers greater than 2 may be skipped.) It is easy to see that n is
prime if and only if none of the trial divisors divides n. Assuming that
each trial division takes constant time, the worst-case running time is ![]() , which is
exponential in the length of n. (Recall that if n is encoded in
binary using
, which is
exponential in the length of n. (Recall that if n is encoded in
binary using ![]() bits, then
bits, then ![]() =
= ![]() lg(n + 1)
lg(n + 1)![]() , and so
, and so ![]() .) Thus, trial
division works well only if n is very small or happens to have a small
prime factor. When it works, trial division has the advantage that it not only
determines whether n is prime or composite but actually determines the
prime factorization if n is composite.
.) Thus, trial
division works well only if n is very small or happens to have a small
prime factor. When it works, trial division has the advantage that it not only
determines whether n is prime or composite but actually determines the
prime factorization if n is composite.
In this section, we are interested only in finding out whether a given number n is prime; if n is composite, we are not concerned with finding its prime factorization. As we shall see in Section 9, computing the prime factorization of a number is computationally expensive. It is perhaps surprising that it is much easier to tell whether or not a given number is prime than it is to determine the prime factorization of the number if it is not prime.
We now consider a method for
primality testing that 'almost works' and in fact is good enough for
many practical applications. A refinement of this method that removes the small
defect will be presented later. Let ![]() denote the
nonzero elements of Zn:
denote the
nonzero elements of Zn:
![]()
If n is prime,
then ![]() .
.
We say that n is a base-a pseudoprime if n is composite and
an -Fermat's theorem (Theorem
31) implies that if n is prime, then n satisfies equation (42)
for every a in ![]() . Thus, if we
can find any
. Thus, if we
can find any ![]() such that n
does not satisfy equation (42), then n is certainly composite.
Surprisingly, the converse almost holds, so that this criterion forms an
almost perfect test for primality. We test to see if n satisfies
equation (42) for a = 2. If not, we declare n to be composite.
Otherwise, we output a guess that n is prime (when, in fact, all we know
is that n is either prime or a base-2 pseudoprime).
such that n
does not satisfy equation (42), then n is certainly composite.
Surprisingly, the converse almost holds, so that this criterion forms an
almost perfect test for primality. We test to see if n satisfies
equation (42) for a = 2. If not, we declare n to be composite.
Otherwise, we output a guess that n is prime (when, in fact, all we know
is that n is either prime or a base-2 pseudoprime).
The following procedure pretends in this manner to be checking the primality of n. It uses the procedure MODULAR EXPONENTIATION from Section 6. The input n is assumed to be an integer larger than 2.

This procedure can make errors, but only of one type. That is, if it says that n is composite, then it is always correct. If it says that n is prime, however, then it makes an error only if n is a base-2 pseudoprime.
How often does this
procedure err? Surprisingly rarely. There are only 22 values of n less
than 10,000 for which it errs; the first four such values are 341, 561, 645,
and 1105. It can be shown that the probability that this program makes an error
on a randomly chosen ![]() -bit number
goes to zero as
-bit number
goes to zero as ![]()
![]()
![]() . Using more
precise estimates due to Pomerance [157] of the number of base-2 pseudoprimes
of a given size, we may estimate that a randomly chosen 50-digit number that is
called prime by the above procedure has less than one chance in a million of
being a base-2 pseudoprime, and a randomly chosen 100-digit number that is
called prime has less than one chance in 1013 of being a base-2
pseudoprime.
. Using more
precise estimates due to Pomerance [157] of the number of base-2 pseudoprimes
of a given size, we may estimate that a randomly chosen 50-digit number that is
called prime by the above procedure has less than one chance in a million of
being a base-2 pseudoprime, and a randomly chosen 100-digit number that is
called prime has less than one chance in 1013 of being a base-2
pseudoprime.
Unfortunately, we cannot eliminate all the
errors by simply checking equation (42) for a second base number, say a
= 3, because there are composite integers n that satisfy equation (42)
for all ![]() . These
integers are known as Carmichael numbers. The first three
Carmichael numbers are 561, 1105, and 1729. Carmichael numbers are extremely
rare; there are, for example, only 255 of them less than 100,000,000. Exercise 8-2
helps explain why they are so rare.
. These
integers are known as Carmichael numbers. The first three
Carmichael numbers are 561, 1105, and 1729. Carmichael numbers are extremely
rare; there are, for example, only 255 of them less than 100,000,000. Exercise 8-2
helps explain why they are so rare.
We next show how to improve our primality test so that it won't be fooled by Carmichael numbers.
The Miller-Rabin primality test overcomes the problems of the simple test PSEUDOPRIME with two modifications:
![]() It tries several randomly chosen base values a instead of just
one base value.
It tries several randomly chosen base values a instead of just
one base value.
![]() While computing each modular exponentiation, it notices if a nontrivial
square root of 1, modulo n, is ever discovered. If so, it stops and
outputs COMPOSITE. Corollary 35 justifies detecting composites in this manner.
While computing each modular exponentiation, it notices if a nontrivial
square root of 1, modulo n, is ever discovered. If so, it stops and
outputs COMPOSITE. Corollary 35 justifies detecting composites in this manner.
The pseudocode for the Miller-Rabin
primality test follows. The input n > 2 is the odd number to be
tested for primality, and s is the number of randomly chosen base values
from ![]() to be tried.
The code uses the random-number generator RANDOM from Section 8.3: RANDOM(1, n - 1) returns a randomly chosen integer a satisfying
1
to be tried.
The code uses the random-number generator RANDOM from Section 8.3: RANDOM(1, n - 1) returns a randomly chosen integer a satisfying
1 ![]() a
a ![]() n - 1.
The code uses an auxiliary procedure WITNESS such that WITNESS(a, n) is TRUE if and only if a is a 'witness' to the compositeness
of n--that is, if it is possible using a to prove (in a manner
that we shall see) that n is composite. The test WITNESS(a, n) is similar
to, but more effective than, the test
n - 1.
The code uses an auxiliary procedure WITNESS such that WITNESS(a, n) is TRUE if and only if a is a 'witness' to the compositeness
of n--that is, if it is possible using a to prove (in a manner
that we shall see) that n is composite. The test WITNESS(a, n) is similar
to, but more effective than, the test
![]()
that formed the basis (using a = 2) for PSEUDOPRIME. We first present and justify the construction of WITNESS, and then show how it is used in the Miller-Rabin primality test.
WITNESS(a,n)This pseudocode for WITNESS is based on the pseudocode of the procedure MODULAR-EXPONENTIATION. Line 1 determines the binary representation of n - 1, which will be used in raising a to the (n - 1)st power. Lines 3-9 compute d as an-1 mod n. The method used is identical to that employed by MODULAR-EXPONENTIATION. Whenever a squaring step is performed on line 5, however, lines 6-7 check to see if a nontrivial square root of 1 has just been discovered. If so, the algorithm stops and returns TRUE. Lines 10-11 return TRUE if the value computed for an - 1 mod n is not equal to 1, just as the PSEUDOPRIME procedure returns COMPOSITE in this case.
We now argue that if WITNESS(a, n) returns TRUE, then a proof that n is composite can be constructed using a.
If WITNESS returns TRUE from line 11, then it has
discovered that d = an - 1 mod n ![]() 1. If n
is prime, however, we have by Fermat's theorem (Theorem 31) that an-1
1. If n
is prime, however, we have by Fermat's theorem (Theorem 31) that an-1
![]() 1 (mod n)
for all
1 (mod n)
for all ![]() . Therefore, n
cannot be prime, and the equation an - 1 mod 1
. Therefore, n
cannot be prime, and the equation an - 1 mod 1 ![]() 1 is a proof
of this fact.
1 is a proof
of this fact.
If WITNESS returns TRUE from line 7, then it has
discovered that x is a nontrivial square root of 1, modulo n,
since we have that ![]() (mod n)
yet x2
(mod n)
yet x2 ![]() 1 (mod n).
Corollary 35 states that only if n is composite can there be a
nontrivial square root of 1 modulo n, so that a demonstration that x
is a nontrivial square root of 1 modulo n is a proof that n is
composite.
1 (mod n).
Corollary 35 states that only if n is composite can there be a
nontrivial square root of 1 modulo n, so that a demonstration that x
is a nontrivial square root of 1 modulo n is a proof that n is
composite.
This completes our proof of the correctness of WITNESS. If the invocation WITNESS(a, n) outputs TRUE, then n is surely composite, and a proof that n is composite can be easily determined from a and n. We now examine the Miller-Rabin primality test based on the use of WITNESS
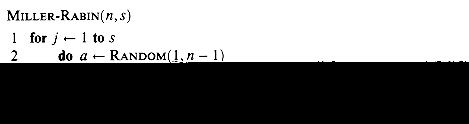
The procedure MILLER RABIN is a probabilistic search
for a proof that n is composite. The main loop (beginning on line 1)
picks s random values of a from ![]() (line 2). If
one of the a's picked is a witness to the compositeness of n,
then MILLER RABIN outputs COMPOSITE on line 4. Such an
output is always correct, by the correctness of WITNESS. If no witness can be
found in s trials, MILLER RABIN
assumes that this is because there are no witnesses to be found, and n
is therefore prime. We shall see that this output is likely to be correct if s
is large enough, but that there is a small chance that the procedure may be
unlucky in its choice of a's and that witnesses do exist even though
none has been found.
(line 2). If
one of the a's picked is a witness to the compositeness of n,
then MILLER RABIN outputs COMPOSITE on line 4. Such an
output is always correct, by the correctness of WITNESS. If no witness can be
found in s trials, MILLER RABIN
assumes that this is because there are no witnesses to be found, and n
is therefore prime. We shall see that this output is likely to be correct if s
is large enough, but that there is a small chance that the procedure may be
unlucky in its choice of a's and that witnesses do exist even though
none has been found.
To illustrate the
operation of MILLER RABIN, let n be the
Carmichael number 561. Supposing that a = 7 is chosen as a base, Figure 4
shows that WITNESS
discovers a nontrivial square root of 1 in the last squaring step, since a280
![]() 67 (mod n)
and a560
67 (mod n)
and a560 ![]() 1 (mod n).
Therefore, a = 7 is a witness to the compositeness of n, WITNESS(7, n) returns TRUE, and MILLER RABIN returns COMPOSITE
1 (mod n).
Therefore, a = 7 is a witness to the compositeness of n, WITNESS(7, n) returns TRUE, and MILLER RABIN returns COMPOSITE
If n is a ![]() -bit
number, MILLER RABIN requires O(s
-bit
number, MILLER RABIN requires O(s![]() ) arithmetic
operations and O(s
) arithmetic
operations and O(s![]() 3)
bit operations, since it requires asymptotically no more work than s
modular exponentiations.
3)
bit operations, since it requires asymptotically no more work than s
modular exponentiations.
If MILLER RABIN outputs PRIME, then there is a small chance that it has made an error. Unlike PSEUDOPRIME, however, the chance of error does not depend on n; there are no bad inputs for this procedure. Rather, it depends on the size of s and the 'luck of the draw' in choosing base values a. Also, since each test is more stringent than a simple check of equation (42), we can expect on general principles that the error rate should be small for randomly chosen integers n. The following theorem presents a more precise argument.
Theorem 38
If n is an odd composite number, then the number of witnesses to the compositeness of n is at least (n - 1)/2.
Proof The proof shows that the number of nonwitnesses is no more than (n - 1)/2, which implies the theorem.
We first observe that any
nonwitness must be a member of ![]() , since every
nonwitness a satisfies an - 1
, since every
nonwitness a satisfies an - 1 ![]() 1 (mod n),
yet if gcd(a, n) = d > 1, then there are no solutions x
to the equation ax
1 (mod n),
yet if gcd(a, n) = d > 1, then there are no solutions x
to the equation ax ![]() 1 (mod n),
by Corollary 21. (In particular, x = an - 2
is not a solution.) Thus every member of
1 (mod n),
by Corollary 21. (In particular, x = an - 2
is not a solution.) Thus every member of ![]() is a witness
to the compositeness of n.
is a witness
to the compositeness of n.
To complete the proof, we
show that the nonwitnesses are all contained in a proper subgroup B of ![]() . By Corollary
16, we then have
. By Corollary
16, we then have ![]() , we obtain |B|
, we obtain |B|
![]() (n -
1)/2. Therefore, the number of nonwitnesses is at most (n - 1)/2, so
that the number of witnesses must be at least (n - 1)/2.
(n -
1)/2. Therefore, the number of nonwitnesses is at most (n - 1)/2, so
that the number of witnesses must be at least (n - 1)/2.
We now show how to find a
proper subgroup B of ![]() containing all
of the nonwitnesses. We break the proof into two cases.
containing all
of the nonwitnesses. We break the proof into two cases.
Case 1: There exists an ![]() such that
such that
![]()
Let ![]() . Since B
is closed under multiplication modulo n, we have that B is a
subgroup of
. Since B
is closed under multiplication modulo n, we have that B is a
subgroup of ![]() by Theorem 14.
Note that every nonwitness belongs to B, since a nonwitness a
satisfies an - 1
by Theorem 14.
Note that every nonwitness belongs to B, since a nonwitness a
satisfies an - 1 ![]() 1 (mod n).
Since
1 (mod n).
Since ![]() , we have that
B is a proper subgroup of
, we have that
B is a proper subgroup of ![]() .
.
Case 2: For all ![]() ,
,
In this case, n
cannot be a prime power. To see why, let n = pe, where
p is an odd prime and e > 1. Theorem 32 implies that ![]() contains an
element g such that
contains an
element g such that ![]() . But then
equation (44) and the discrete logarithm theorem (Theorem 33, taking y =
0) imply that n - 1
. But then
equation (44) and the discrete logarithm theorem (Theorem 33, taking y =
0) imply that n - 1 ![]() 0 (mod
0 (mod ![]() (n)),
or
(n)),
or
This condition fails for e > 1, since the left-hand side is then divisible by p but the right-hand side is not. Thus, n is not a prime power.
Since n is not a
prime power, we decompose it into a product n1n2,
where n1 and n2 are greater than 1 and
relatively prime to each other. (There may be several ways to do this, and it
doesn't matter which one we choose. For example, if ![]() , then we can
choose
, then we can
choose ![]() .)
.)
Define t and u
so that n - 1 = 2tu, where
t ![]() 1 and u
is odd. For any
1 and u
is odd. For any ![]() , consider the
sequence
, consider the
sequence
where all elements are computed modulo n. Since 2t | n - 1, the binary representation of n - 1 ends in t zeros, and the elements of a are the last t + 1 values of d computed by WITNESS during a computation of an-1 mod n; the last t operations are squarings.
Now find a j ![]() such that there exists a
such that there exists a ![]() such that v2ju
such that v2ju
![]() -1 (mod n); j should be as large as possible. Such a j
certainly exists since u is odd: we can choose v = - 1 and j
= 0. Fix
-1 (mod n); j should be as large as possible. Such a j
certainly exists since u is odd: we can choose v = - 1 and j
= 0. Fix ![]() to satisfy the
given condition. Let
to satisfy the
given condition. Let
![]()
Since B is closed
under multiplication modulo n, it is a subgroup of ![]() . Therefore,
|B
divides
. Therefore,
|B
divides ![]() . Every
nonwitness must be a member of B, since the sequence (45) produced by a
nonwitness must either be all 1's or else contain a - 1 no later than the jth
position, by the maximality of j.
. Every
nonwitness must be a member of B, since the sequence (45) produced by a
nonwitness must either be all 1's or else contain a - 1 no later than the jth
position, by the maximality of j.
We now use the existence
of v to demonstrate that there exists a ![]() . Since v2ju
. Since v2ju ![]() -1 (mod n),
we have v2ju
-1 (mod n),
we have v2ju ![]() -1 (mod n1) by Corollary 29. By Corollary 28, there
is a w simultaneously satisfying the equations
-1 (mod n1) by Corollary 29. By Corollary 28, there
is a w simultaneously satisfying the equations
Therefore,
w2juTogether with Corollary 29, these equations imply that
![]()
and so w ![]() B.
Since
B.
Since ![]() , we have that
, we have that
![]() . Thus,
. Thus, ![]() . We conclude
that B is a proper subgroup of
. We conclude
that B is a proper subgroup of ![]() .
.
In either case, we see that the number of witnesses to the compositeness of n is at least (n - 1)/2.
Theorem 39
For any odd integer n > 2 and positive integer s, the probability that MILLER-RABIN(n, s) errs is at most 2-s.
Proof Using Theorem 38, we see that if n is composite, then each execution of the loop of lines 1-4 has a probability of at least 1/2 of discovering a witness x to the compositeness of n. MILLER-RABIN only makes an error if it is so unlucky as to miss discovering a witness to the compositeness of n on each of the s iterations of the main loop. The probability of such a string of misses is at most 2-s.
Thus, choosing s = 50 should suffice for almost any imaginable application. If we are trying to find large primes by applying MILLER-RABIN to randomly chosen large integers, then it can be argued (although we won't do so here) that choosing a small value of s (say 3) is very unlikely to lead to erroneous results. That is, for a randomly chosen odd composite integer n, the expected number of nonwitnesses to the compositeness of n is likely to be much smaller than (n - 1)/2. If the integer n is not chosen randomly, however, the best that can be proven is that the number of nonwitnesses is at most (n - 1)/4, using an improved version of Theorem 39. Furthermore, there do exist integers n for which the number of nonwitnesses is (n - 1)/4.
Prove that if an integer n > 1 is not a prime or a prime power, then there exists a nontrivial square root of 1 modulo n.
It is possible to strengthen Euler's theorem slightly to the form
![]()
where ![]() (n)
is defined by
(n)
is defined by
![]()
Prove that ![]() (n) |
(n) | ![]() (n). A
composite number n is a Carmichael number if
(n). A
composite number n is a Carmichael number if ![]() (n) |n - 1. The smallest
Carmichael number is 561 = 3
(n) |n - 1. The smallest
Carmichael number is 561 = 3 ![]() 11
11 ![]() 17; here,
17; here, ![]() (n) =
1cm(2, 10, 16) = 80, which divides 560. Prove that Carmichael numbers must be
both 'square-free' (not divisible by the square of any prime) and the
product of at least three primes. For this reason, they are not very common.
(n) =
1cm(2, 10, 16) = 80, which divides 560. Prove that Carmichael numbers must be
both 'square-free' (not divisible by the square of any prime) and the
product of at least three primes. For this reason, they are not very common.
Prove that if x is a nontrivial square root of 1, modulo n, then gcd(x - 1, n) and gcd(x + 1, n) are both nontrivial divisors of n.
Suppose we have an integer n that we wish to factor, that is, to decompose into a product of primes. The primality test of the preceding section would tell us that n is composite, but it usually doesn't tell us the prime factors of n. Factoring a large integer n seems to be much more difficult than simply determining whether n is prime or composite. It is infeasible with today's supercomputers and the best algorithms to date to factor an arbitrary 200-decimal-digit number.
Trial division by all integers up to B is guaranteed to factor completely any number up to B2. For the same amount of work, the following procedure will factor any number up to B4 (unless we're unlucky). Since the procedure is only a heuristic, neither its running time nor its success is guaranteed, although the procedure is very effective in practice.
POLLARD-RHO(n)![]()
The procedure works as follows. Lines 1-2 initialize i to 1 and x1 to a randomly chosen value in Zn. The while loop beginning on line 5 iterates forever, searching for factors of n. During each iteration of the while loop, the recurrence
![]()
is used on line 7 to produce the next value of xi in the infinite sequence
x , x2, x3, x4, ;the value of i is correspondingly incremented on line 6. The code is written using subscripted variables xi for clarity, but the program works the same if all of the subscripts are dropped, since only the most recent value of xi need be maintained.
Every so often, the program saves the most recently generated xi value in the variable y. Specifically, the values that are saved are the ones whose subscripts are powers of 2:
x , x2, x4, x8, x16, .Line 3 saves the value x1, and line 12 saves xk whenever i is equal to k. The variable k is initialized to 2 in line 4, and k is doubled in line 13 whenever y is updated. Therefore, k follows the sequence 1, 2, 4, 8, . . . and always gives the subscript of the next value xk to be saved in y.
Lines 8-10 try to find a factor of n, using the saved value of y and the current value of xi. Specifically, line 8 computes the greatest common divisor d = gcd(y - xi, n). If d is a nontrivial divisor of n (checked in line 9), then line 10 prints d.
This procedure for
finding a factor may seem somewhat mysterious at first. Note, however, that POLLARD-RHO never prints an
incorrect answer; any number it prints is a nontrivial divisor of n. POLLARD-RHO may not print
anything at all, though; there is no guarantee that it will produce any
results. We shall see, however, that there is good reason to expect POLLARD RHO to print a factor p
of n after approximately ![]() iterations of
the while loop. Thus, if n is composite, we can expect this
procedure to discover enough divisors to factor n completely after
approximately n1/4 updates, since every prime factor p
of n except possibly the largest one is less than
iterations of
the while loop. Thus, if n is composite, we can expect this
procedure to discover enough divisors to factor n completely after
approximately n1/4 updates, since every prime factor p
of n except possibly the largest one is less than ![]() .
.
Let us consider the question of how long it takes for the sequence of xi to repeat. This is not exactly what we need, but we shall then see how to modify the argument.
For the purpose of this
estimation, let us assume that the function (x2 - 1) mod n
behaves like a 'random' function. Of course, it is not really random,
but this assumption yields results consistent with the observed behavior of POLLARD-RHO. We can then
consider each xi to have been independently drawn from Zn
according to a uniform distribution on Zn. By the
birthday-paradox analysis of Section 6.6.1, the expected number of steps taken
before the sequence cycles is ![]() .
.
Now for the required
modification. Let p be a nontrivial factor of n such that gcd(p,
n/p) = 1. For example, if n has the factorization ![]() , then we may
take p to be
, then we may
take p to be ![]() . (If e1
= 1, then p is just the smallest prime factor of n, a good
example to keep in mind.) The sequence
. (If e1
= 1, then p is just the smallest prime factor of n, a good
example to keep in mind.) The sequence ![]() xi
xi![]() induces a
corresponding sequence
induces a
corresponding sequence ![]() modulo p,
where
modulo p,
where
![]()
for all i. Furthermore, it follows from the Chinese remainder theorem that
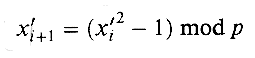
since
(x mod n) mod p = x mod p ,by Exercise 1-6.
Reasoning as before, we
find that the expected number of steps before the sequence ![]() repeats is
repeats is ![]() . If p
is small compared to n, the sequence
. If p
is small compared to n, the sequence ![]() may repeat
much more quickly than the sequence
may repeat
much more quickly than the sequence ![]() xi
xi![]() . Indeed, the
. Indeed, the ![]() sequence
repeats as soon as two elements of the sequence
sequence
repeats as soon as two elements of the sequence ![]() xi
xi![]() are merely
equivalent modulo p, rather than equivalent modulo n. See Figure 7,
parts (b) and (c), for an illustration.
are merely
equivalent modulo p, rather than equivalent modulo n. See Figure 7,
parts (b) and (c), for an illustration.
Let t denote the
index of the first repeated value in the ![]() sequence, and
let u > 0 denote the length of the cycle that has been thereby
produced. That is, t and u > 0 are the smallest values such
that
sequence, and
let u > 0 denote the length of the cycle that has been thereby
produced. That is, t and u > 0 are the smallest values such
that ![]() for all i
for all i
![]() 0. By the
above arguments, the expected values of t and u are both
0. By the
above arguments, the expected values of t and u are both ![]() . Note that if
. Note that if
![]() , then p
| (xt+u+i - xt+i). Thus, gcd(xt+u+i
- xt+i,n) > 1.
, then p
| (xt+u+i - xt+i). Thus, gcd(xt+u+i
- xt+i,n) > 1.
Therefore, once POLLARD RHO has saved as y any
value xk such that k ![]() t, then
y mod p is always on the cycle modulo p. (If a new value
is saved as y, that value is also on the cycle modulo p.)
Eventually, k is set to a value that is greater than u, and the
procedure then makes an entire loop around the cycle modulo p without
changing the value of y. A factor of n is then discovered when xi
'runs into' the previously stored value of y, modulo p,
that is, when xi
t, then
y mod p is always on the cycle modulo p. (If a new value
is saved as y, that value is also on the cycle modulo p.)
Eventually, k is set to a value that is greater than u, and the
procedure then makes an entire loop around the cycle modulo p without
changing the value of y. A factor of n is then discovered when xi
'runs into' the previously stored value of y, modulo p,
that is, when xi ![]() y (mod p).
y (mod p).
Presumably, the factor
found is the factor p, although it may occasionally happen that a
multiple of p is discovered. Since the expected values of both t
and u are ![]() , the expected
number of steps required to produce the factor p is
, the expected
number of steps required to produce the factor p is ![]() .
.
There are two reasons why
this algorithm may not perform quite as expected. First, the heuristic analysis
of the running time is not rigorous, and it is possible that the cycle of
values, modulo p, could be much larger than ![]() . In this
case, the algorithm performs correctly but much more slowly than desired. In
practice, this seems not to be an issue. Second, the divisors of n
produced by this algorithm might always be one of the trivial factors 1 or n.
For example, suppose that n = pq, where p and q are
prime. It can happen that the values of t and u for p are
identical with the values of t and u for q, and thus the
factor p is always revealed in the same gcd operation that reveals the
factor q. Since both factors are revealed at the same time, the trivial
factor pq = n is revealed, which is useless. Again, this seems
not to be a real problem in practice. If necessary, the heuristic can be
restarted with a different recurrence of the form
. In this
case, the algorithm performs correctly but much more slowly than desired. In
practice, this seems not to be an issue. Second, the divisors of n
produced by this algorithm might always be one of the trivial factors 1 or n.
For example, suppose that n = pq, where p and q are
prime. It can happen that the values of t and u for p are
identical with the values of t and u for q, and thus the
factor p is always revealed in the same gcd operation that reveals the
factor q. Since both factors are revealed at the same time, the trivial
factor pq = n is revealed, which is useless. Again, this seems
not to be a real problem in practice. If necessary, the heuristic can be
restarted with a different recurrence of the form ![]() mod n.
(The values c = 0 and c = 2 should be avoided for reasons we
won't go into here, but other values are fine.)
mod n.
(The values c = 0 and c = 2 should be avoided for reasons we
won't go into here, but other values are fine.)
Of course, this analysis
is heuristic and not rigorous, since the recurrence is not really
'random.' Nonetheless, the procedure performs well in practice, and
it seems to be as efficient as this heuristic analysis indicates. It is the
method of choice for finding small prime factors of a large number. To factor a
![]() -bit
composite number n completely, we only need to find all prime factors
less than
-bit
composite number n completely, we only need to find all prime factors
less than ![]() n1/2
n1/2![]() , and so we expect POLLARD RHO to
require at most n1/4 = 2
, and so we expect POLLARD RHO to
require at most n1/4 = 2![]() /4 arithmetic
operations and at most n ,
/4 arithmetic
operations and at most n , ![]()
![]() /4
/4![]() 3 bit operations. POLLARD RHO's
ability to find a small factor p of n with an expected number
3 bit operations. POLLARD RHO's
ability to find a small factor p of n with an expected number ![]() of arithmetic
operations is often its most appealing feature.
of arithmetic
operations is often its most appealing feature.
Referring to the execution history shown in Figure 7(a), when does POLLARD RHO print the factor 73 of 1387?
Suppose that we are given
a function f : Zn ![]() Zn
and an initial value x0
Zn
and an initial value x0 ![]() Zn. Define xi = f(xi-1)
for i = 1, 2, . . . . Let t and u > 0 be the smallest
values such that xt+i = xt+u+i for i
= 0, 1, . . . . In the terminology of Pollard's rho algorithm, t is the
length of the tail and u is the length of the cycle of the rho. Give an
efficient algorithm to determine t and u exactly, and analyze its
running time.
Zn. Define xi = f(xi-1)
for i = 1, 2, . . . . Let t and u > 0 be the smallest
values such that xt+i = xt+u+i for i
= 0, 1, . . . . In the terminology of Pollard's rho algorithm, t is the
length of the tail and u is the length of the cycle of the rho. Give an
efficient algorithm to determine t and u exactly, and analyze its
running time.
How many steps would you expect POLLARD RHO to require to discover a factor of the form pe, where p is prime and e > 1?
One disadvantage of POLLARD RHO as written is that it
requires one gcd computation for each step of the recurrence. It has been
suggested that we might batch the gcd computations by accumulating the product
of several xi in a row and then taking the gcd of this
product with the saved y. Describe carefully how you would implement
this idea, why it works, and what batch size you would pick as the most
effective when working on a ![]() -bit number n.
-bit number n.
33-1 Binary gcd algorithm
On most computers, the operations of subtraction, testing the parity (odd or even) of a binary integer, and halving can be performed more quickly than computing remainders. This problem investigates the binary gcd algorithm, which avoids the remainder computations used in Euclid's algorithm.
a. Prove that if a and b are both even, then gcd(a, b) = 2 gcd(a/2, b/2).
b. Prove that if a is odd and b is even, then gcd(a, b) = gcd(a, b/2).
c. Prove that if a and b are both odd, then gcd(a, b) = gcd((a - b)/2, b).
d. Design an efficient binary gcd algorithm for input integers a
and b, where a ![]() b, that
runs in O(lg(max(a, b))) time. Assume that each subtraction,
parity test, and halving can be performed in unit time.
b, that
runs in O(lg(max(a, b))) time. Assume that each subtraction,
parity test, and halving can be performed in unit time.
33-2 Analysis of bit operations in Euclid's algorithm
a. Show that using the ordinary 'paper and pencil' algorithm for long division--dividing a by b, yielding a quotient q and remainder r--requires O((1 + lg q) lg b) bit operations.
b. Define ![]() (a, b)
= (1 + lg a)(1 + lg b). Show that the number of bit operations
performed by EUCLID in reducing the problem of computing gcd(a, b)
to that of computing gcd(b, a mod b) is at most c(
(a, b)
= (1 + lg a)(1 + lg b). Show that the number of bit operations
performed by EUCLID in reducing the problem of computing gcd(a, b)
to that of computing gcd(b, a mod b) is at most c(![]() (a, b)
-
(a, b)
- ![]() (b, a
mod b)) for some sufficiently large constant c > 0.
(b, a
mod b)) for some sufficiently large constant c > 0.
c. Show that EUCLID(a, b) requires O(![]() (a, b))
bit operations in general and O(
(a, b))
bit operations in general and O(![]() 2)
bit operations when applied to two
2)
bit operations when applied to two ![]() -bit
inputs.
-bit
inputs.
33-3 Three algorithms for Fibonacci numbers
This problem compares the efficiency of three methods for computing the nth Fibonacci number Fn, given n. Assume that the cost of adding, subtracting, or multiplying two numbers is O(1), independent of the size of the numbers.
a. Show that the running time of the straightforward recursive method for computing Fn based on recurrence (2.13) is exponential in n.
b. Show how to compute Fn in O(n) time using memoization.
c. Show how to compute Fn in O(lg n) time using only integer addition and multiplication. (Hint: Consider the matrix
![]()
and its powers.)
d. Assume now that adding two ![]() -bit
numbers takes
-bit
numbers takes ![]() (
(![]() ) time and
that multiplying two
) time and
that multiplying two ![]() -bit
numbers takes
-bit
numbers takes ![]() (
(![]() 2)
time. What is the running time of these three methods under this more
reasonable cost measure for the elementary arithmetic operations?
2)
time. What is the running time of these three methods under this more
reasonable cost measure for the elementary arithmetic operations?
33-4 Quadratic residues
Let p be an odd prime. A number ![]() is a quadratic
residue if the equation x2 = a (mod p)
has a solution for the unknown x.
is a quadratic
residue if the equation x2 = a (mod p)
has a solution for the unknown x.
a Show that there are exactly (p - 1)/2 quadratic residues, modulo p.
b. If p is
prime, we define the Legendre symbol ![]() , to be 1 if a
is a quadratic residue modulo p and -1 otherwise. Prove that if
, to be 1 if a
is a quadratic residue modulo p and -1 otherwise. Prove that if ![]() , then
, then
![]()
Give an efficient algorithm for determining whether or not a given number a is a quadratic residue modulo p. Analyze the efficiency of your algorithm.
c. Prove
that if p is a prime of the form 4k + 3 and a is a
quadratic residue in ![]() , then ak+l
mod p is a square root of a, modulo p. How much time is
required to find the square root of a quadratic residue a modulo p?
, then ak+l
mod p is a square root of a, modulo p. How much time is
required to find the square root of a quadratic residue a modulo p?
d Describe an efficient randomized algorithm for finding a nonquadratic residue, modulo an arbitrary prime p. How many arithmetic operations does your algorithm require on average?
Niven and Zuckerman [151] provide an excellent introduction to elementary number theory. Knuth [122] contains a good discussion of algorithms for finding the greatest common divisor, as well as other basic number-theoretic algorithms. Riesel [168] and Bach [16] provide more recent surveys of computational number theory. Dixon [56] gives an overview of factorization and primality testing. The conference proceedings edited by Pomerance [159] contains several nice survey articles.
Knuth [122] discusses the origin of Euclid's algorithm. It appears in Book 7, Propositions 1 and 2, of the Greek mathematician Euclid's Elements, which was written around 300 B.C. Euclid's description may have been derived from an algorithm due to Eudoxus around 375 B.C. Euclid's algorithm may hold the honor of being the oldest nontrivial algorithm; it is rivaled only by the Russian peasant's algorithm for multiplication (see Chapter 29), which was known to the ancient Egyptians.
Knuth attributes a
special case of the Chinese remainder theorem (Theorem 27) to the Chinese
mathematician ![]() , who lived
sometime between 200 B.C. and A.D.
200--the date is quite uncertain. The same special case was given by the Greek
mathematician Nichomachus around A.D. 100. It was generalized by Chhin Chiu-Shao in 1247. The Chinese
remainder theorem was finally stated and proved in its full generality by L.
Euler in 1734.
, who lived
sometime between 200 B.C. and A.D.
200--the date is quite uncertain. The same special case was given by the Greek
mathematician Nichomachus around A.D. 100. It was generalized by Chhin Chiu-Shao in 1247. The Chinese
remainder theorem was finally stated and proved in its full generality by L.
Euler in 1734.
The randomized primality-testing algorithm
presented here is due to Miller [147] and Rabin [166]; it is the fastest
randomized primality-testing algorithm known, to within constant factors. The
proof of Theorem 39 is a slight adaptation of one suggested by Bach [15]. A
proof of a stronger result for MILLER RABIN
was given by Monier[148, 149]. Randomization appears to be necessary to obtain
a polynomial-time primality-testing algorithm. The fastest deterministic
primality-testing algorithm known is the Cohen-Lenstra version [45] of the
primality test by Adleman, Pomerance, and Rumely [3]. When testing a number n
of length ![]() lg(n +
1)
lg(n +
1)![]() for
primality, it runs in (lg n)O(1g 1g 1g n)
time, which is just slightly superpolynomial.
for
primality, it runs in (lg n)O(1g 1g 1g n)
time, which is just slightly superpolynomial.
The problem of finding large 'random' primes is nicely discussed in an article by Beauchemin, Brassard, Crpeau, Goutier, and Pomerance [20].
The rho heuristic for integer factoring was invented by Pollard [156]. The version presented here is a variant proposed by Brent [35].
The best algorithms for factoring
large numbers have a running time that grows roughly exponentially with the
square root of the length of the number n to be factored. The
quadratic-sieve factoring algorithm, due to Pomerance [158], is perhaps the
most efficient such algorithm in general for large inputs. Although it is
difficult to give a rigorous analysis of this algorithm, under reasonable assumptions
we can derive a running-time estimate of L(n)1+o(1),
where ![]() . The
elliptic-curve method due to Lenstra [137] may be more effective for some
inputs than the quadratic-sieve method, since, like Pollard's rho method, it
can find a small prime factor p quite quickly. With this method, the
time to find p is estimated to be
. The
elliptic-curve method due to Lenstra [137] may be more effective for some
inputs than the quadratic-sieve method, since, like Pollard's rho method, it
can find a small prime factor p quite quickly. With this method, the
time to find p is estimated to be ![]() .
.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1147
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved