| CATEGORII DOCUMENTE |
| Asp | Autocad | C | Dot net | Excel | Fox pro | Html | Java |
| Linux | Mathcad | Photoshop | Php | Sql | Visual studio | Windows | Xml |
The basic programming model of the CLR is based on types, objects, and values. Chapters 3 and focused primarily on types and danced lightly around the idea of objects and values. This chapter will clarify how all three of these concepts relate and are used in CLR-based programs. Again, the concepts illustrated in this chapter transcend programming languages and apply to everyone using the CLR.
The type system of the CLR distinguishes between types that correspond to simple values and types that correspond to more traditional 'objects.' The former are called value types; the latter are called reference types. Value types support a limited subset of what a reference type supports. In particular, instances of value types do not carry the storage overhead of full-blown objects. This makes value types useful in scenarios where the costs of an object would otherwise be prohibitive. It is important to note that both reference types and value types can have members such as fields and methods, and this means that statements such as the following are legal:
string s = 53.ToString();Here, 53 is an instance of a type (System.Int32) that has a method called ToString.
The term object is overloaded in the literature as well as in the CLR documentation. For consistency, we will define an object as an instance of a CLR type on the garbage-collected (GC) heap. Objects support all the methods and interfaces declared by their type. To implement polymorphism, objects always begin with the two-field object header described in Chapter 4. Value types (such as System.Int32 or System.Boolean) are also CLR types, but instances of a value type are not objects because they do not begin with an object header, nor are they allocated as distinct entities on the GC heap. This makes instances of value types somewhat less expensive than instances of reference types. Like reference types, value types can have fields and methods. This applies to primitives as well as user-defined value types.
Reference types and value types are distinguished by base type. All value types have System.ValueType as a base type. System.ValueType acts as a signal to the CLR that instances of the type must be dealt with differently. Figure 5.1 shows one view of the CLR type system. Note that the primitive types such as System.Int32 are descendants of System.ValueType, as are all user-defined structures and enumerations. All other types are reference types.
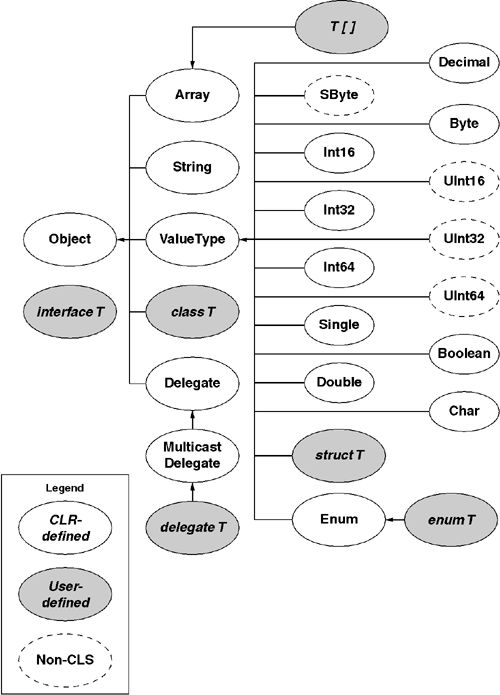
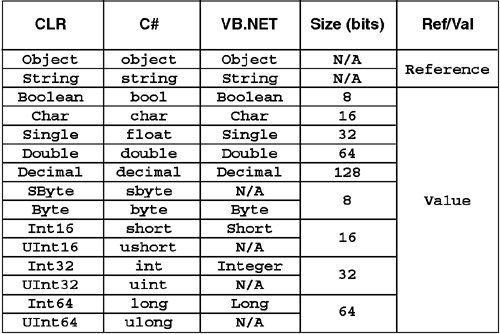
Programming languages typically have a set of built-in or primitive types. It is the job of the compiler to map these built-in types to CLR types. The CLR provides a fairly rich set of standard numeric types as well as Boolean and string types. Figure 5.2 shows the VB.NET and C# built-in types and the CLR types they correspond to. Note that all numeric types and Boolean types are value types. Also note that System.String is a reference type. That stated, in the CLR, System.String objects are immutable and cannot be changed after they are created. This makes System.String act much more like a value type than a reference type, as will be further explored later in this chapter.
For a variety of reasons, one cannot use value types as base types. To that end, all value types are marked as sealed in the type's metadata and cannot declare abstract methods. Additionally, because instances of value types are not allocated as distinct entities on the heap, value types cannot have finalizers. These are restrictions imposed by the CLR. The C# programming language imposes one additional restriction, which is that value types cannot have default constructors. In the absence of a default constructor, the CLR simply sets all of the fields of the value type to their default values when constructing an instance of a value type. Finally, because instances of value types do not have an object header, method invocation against a value type does not use virtual method dispatch. This helps performance but loses some flexibility.
There are two ways to define new value types. One way is to define a type whose base type is System.ValueType. The other way is to define a type whose base type is System.Enum. A C# struct definition is strikingly similar to a C# class definition except for the choice of keyword. There are a few subtle differences, however. For one thing, you cannot specify an explicit base type for a C# struct; rather, System.ValueType is always implied. Neither can you explicitly declare a C# struct as abstract or sealed; rather, the compiler implicitly adds sealed. Consider the following simple C# struct definition:
public struct SizeNote that like a C# class definition, a C# struct can have methods and fields. A C# struct can also support arbitrary interfaces. Ultimately, a C# struct definition is equivalent to defining a new C# class that derives from System.ValueType. For example, the previous struct is conceptually equivalent to the following class definition:
public sealed class Size : System.ValueTypeHowever, the C# compiler will not allow ValueType to be used as a base. Rather, one must use the struct construct to achieve the same end.
C# structs are useful for defining types that act like user-defined primitives but contain arbitrary composite fields. It is also possible to define specializations of the integral types that do not add any new fields but rather simply restrict the value space of the specified integral type. These restricted integral types are called enumeration types.
Enumeration types are CLR value types whose immediate base type is System.Enum rather than System.ValueType. Enumeration types must specify a second type that will be used for the data representation of the enumeration. This second type must be one of the CLR's built-in integral types (excluding System.Char). An enumeration type can contain members; however, the only members that are supported are literal fields. The literal fields of an enumeration type must match the enumeration's underlying representation type and act as the set of legal values that can be used for instances of the enumeration.
One can create new enumeration types using C# enum definitions. A C# enum looks similar to a C or C++ enum. A C# enum definition contains a comma-delimited list of unique names:
public enum BreathThe compiler will assign each of these names a numeric value. If no explicit values are provided (as is the case in this example), then the compiler will assign the values 0, 1, 2, and so on, in order of declaration. Conceptually, this enum is equivalent to the following C# class definition:
public sealed class Breath : System.EnumHowever, as with ValueType, the C# compiler prohibits the explicit use of System.Enum as a base type and requires that one instead use the enum construct. Also, unlike C, C# does not consider numeric types to be type-compatible with enumerations. Rather, to treat an enum like an int (or vice versa), one must first explicitly cast to the desired type. In contrast, C++ allows implicit conversion from an enumerated type to a numeric type.
If no explicit underlying type is specified as part of the enum definition, the C# compiler will assume that the underlying type is System.Int32. One can override this default using the following syntax:
[ System.Flags ]This example declares the underlying type of each of the literal values to be System.Byte.
Although the member names of an enumeration must be unique, there is no such uniqueness requirement for the integral values of each member. In fact, it is common to use enumeration types to represent bitmasks. To make this usage explicit, an enumeration can have the [System.Flags] attribute. This attribute signals the intended usage to developers. This attribute also affects the underlying ToString implementation so that the stringified version of the value will be a comma-delimited list of member names rather than just a number.
Reference types always yield instances that are allocated on the heap. In contrast, value types yield instances that are allocated relevant to the context in which the variable is declared. If a local variable is of a value type, the CLR allocates the memory for the instance on the stack. If a field in a class is a member of a value type, then the CLR allocates the memory for the instance as part of the layout of the object or type in which the field is declared. The rules for dealing with value and reference types are consistent for variables, fields, and parameters. To that end, this chapter will use the term variable to refer to all three concepts and will use the term local variable when discussing variables by themselves.
As their name implies, reference type variables contain object references and not instances of the type they are declared as. A reference type variable simply contains the address of the object it refers to. This means that two reference type variables may refer to the same object. It also means that it is possible for an object reference to not refer to an object at all. Before one can use a reference type variable, one must first initialize it to point to a valid object. Attempts to access a member through an object reference that does not refer to a valid object will result in a runtime error. The default value for a reference type field is null, which is a well-known address that refers to no object. Any attempts to use a null reference will result in a System.NullReferenceException. As a point of interest, one can safely assume that any object reference one uses will always point to a valid object or null because the use of an uninitialized reference would be caught by either the compiler or the CLR's verifier. Moreover, the CLR will not deallocate the object while you have a live variable or field that refers to it.
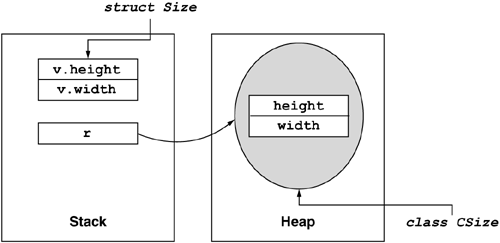
To do any meaningful work, reference type variables require an object. In contrast, value type variables are the instances themselves, not references. This means that a value type variable is useful immediately upon declaration. Listing 5.1 shows an example of two types that are identical except that one is a reference type and the other is a value type. Note that the variable v can be used immediately because the instance has already been allocated as part of the variable declaration. In contrast, the variable r cannot be used until it refers to a valid object on the heap. Figure 5.3 shows how the two variables are allocated in memory.
It is interesting to note that the C# language allows you to use the new operator for both reference and value types. When used with a reference type, the C# new operator is translated to a CIL newobj instruction, which triggers an allocation on the heap followed by a call to the type's constructor. When one uses a value type, the CLR translates the C# new operator to a CIL initobj instruction, which simply initializes the instance in place using the default values for each field. In this respect, using new with a value type is similar to using C++'s placement operator new to invoke a constructor without allocating memory.
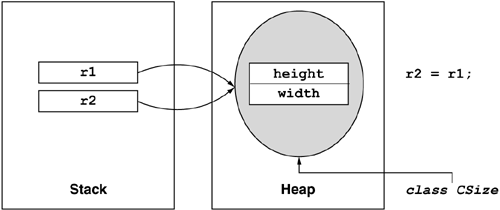
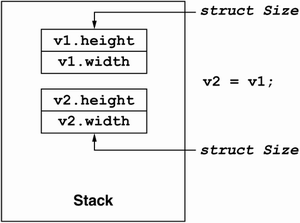
Assignment works differently for value and reference types. For reference types, assignment simply duplicates the reference to the original instance, resulting in two variables that refer to the same instance in memory. For value types, assignment overwrites one instance with the contents of another, with the two instances remaining completely unrelated after the assignment is done. Compare the code in Listing 5.2 (illustrated by Figure 5.4) to that in Listing 5.3 (illustrated by Figure 5.5). Note that in the reference type case, the assignment is only duplicating the reference and that changes through one variable are visible through the other. In contrast, the assignment of the value type yields a second independent instance. In the value type example, v1 and v2 name two distinct instances of type Size. In the reference type example, r1 and r2 are simply two names for the one instance of type CSize.
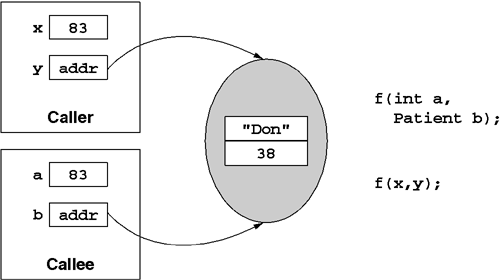
Passing parameters to a method is a variation on assignment that bears special consideration. When one passes parameters to a method, the method's declaration determines whether the parameters will be passed by reference or by value. Passing parameters by value (the default) results in the method or callee getting its own private copy of the parameter values. As shown in Figure 5.6, if the parameter is a value type, the method gets its own private copy of the instance. If the parameter is a reference type, it is the reference (not the instance) that is passed by value. The object the reference points to is not copied. Rather, both the caller and the callee wind up with private references to a shared object.
Passing parameters by reference (indicated in C# using the ref or out modifier) results in the method or callee getting a managed pointer back to the caller's variables. As shown in Figure 5.7, any changes the method makes to the value type or the reference type will be visible to the caller. Moreover, if the method overwrites an object reference parameter to redirect it to another object in memory, this change also affects the caller's variable.
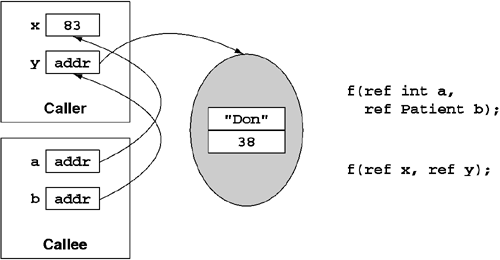
In the example shown in Figure 5.7, any assignments that the callee's method body may perform on the a or b parameter will affect the caller. Specifically, this means that setting the b parameter to null will also set the caller's y variable to null. In contrast, in the example shown in Figure 5.6, the callee's method body may freely assign a and b to the parameters without affecting the caller in any way. However, the object referenced by the b parameter is shared with the caller, and the caller will see any changes made through b. This is true in both examples.
The CLR (like many other technologies) distinguishes between object equivalence and identity. This is especially important for reference types such as classes. In general, two objects are equivalent if they are instances of the same type and if each of the fields in one object matches the values of the fields in the other object. That does not mean that they are 'the same object' but only that the two objects have the same values. In contrast, two objects are identical if they share an address in memory. Practically speaking, two references are identical if they refer to the same object.
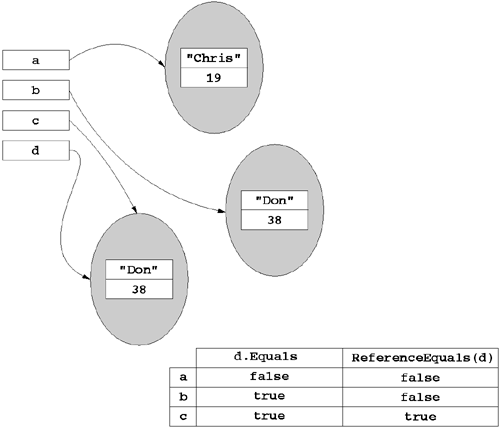
Comparing object references for identity is trivial, requiring only a comparison of memory addresses, independent of type. One can perform this test via the System.Object.ReferenceEquals static method. This method simply compares the addresses contained in two object references independent of the types of objects involved.
Unlike identity comparison, comparing for equivalence is type-specific, and for that reason, System.Object provides an Equals virtual method to compare any two objects for equivalence, as shown in Listing 5.4. As shown in Figure 5.8 and Listing 5.5, the Equals method returns true provided that the two objects have equivalent values. System.Object.ReferenceEquals returns true only when the references refer to the same object.
Implementations of Object.Equals need to ensure that the operation is reflexive, symmetric, and transitive. That is, given an instance of any type, the following assertion must always be true:
public sealed class UtilsSimilarly, Equals implementations must be symmetric:
public sealed class UtilsFinally, Equals implementations must be transitive with respect to equality:
public sealed class UtilsIn most cases, the naive implementation of Equals will adhere to these three requirements.
Each type can implement its own version of the System.Object.Equals method, as shown in Listing 5.6. The default implementation of Object.Equals for reference types simply tests for identity, and this means that it returns true if and only if the two objects are actually the same object. Because value types typically do not have meaningful identity, the default implementation of Object.Equals for value types simply does a memberwise comparison by calling Object.Equals for all instance fields. The CLR is smart enough to optimize these calls away in many cases, such as when all of a type's fields are primitives, in which case the CLR can do a type-ignorant memory comparison.
Types that override Object.Equals must also override Object.Get Hash Code. Programs can use the Object.GetHashCode method to determine whether two objects might be equivalent. If two objects return different hash codes, then they are guaranteed to not be equivalent. If two objects return the same hash codes, then they may or may not be equivalent. The only way to tell for sure is to then call the Object.Equals method. Implementations of Object.GetHashCode are typically much cheaper than Object.Equals because a definitive answer is not required.
It is difficult to look at identity and equivalence tests without considering program language specifics. In C++ and C#, the standard comparison operators are == and . When applied to primitives, these operators simply emit the CIL instructions to compare the two values directly. When applied to object references, these operators emit the CIL instruction that is the moral equivalent of calling System.Object.ReferenceEquals. However, both C++ and C# support operator overloading, and this means that a specific type may elect to map the (and ) operator to arbitrary code. One notable type that does just this is System.String. The System.String type overloads these operators to call the Equals method, and this results in the more intuitive equivalence comparison when used with strings. In general, types that override the Equals method should strongly consider overloading the and operators, especially if the type is (or behaves like) a value type.
GetHashCode and Equals are really designed for objects that act like values. In particular, they are designed for objects whose underlying values are immutable (such as System.String). Unfortunately, the contracts for GetHashCode and Equals have several inconsistencies when applied to objects whose equivalence can change over time. In general, implementing GetHashCode when there is no immutable (e.g., read only) field is exceedingly difficult.
For types that act like values, it is often useful to impose an ordering relationship on the instances of the type. To support this idea in a uniform way, the CLR provides a standard interface: System.IComparable. Types that implement the System.IComparable interface are indicating that their instances may be ordered. As shown here, IComparable has exactly one method, CompareTo:
namespace SystemThe CompareTo method returns an int and can have three possible results. CompareTo must return a negative number if the object's value is less than that of the specified argument. CompareTo must return a positive number if the object's value is greater than that of the specified argument. If the object's value is equivalent to that of the specified argument, then CompareTo must return zero.
The IComparable interface is related to the System.Object.Equals method. Types that implement IComparable must provide an implementation of Object.Equals that is consistent with their IComparable.Compare To implementation. Specifically, the following constraints must always be met:
using System;Similarly, types that override the System.Object.Equals method should also consider implementing IComparable. All of the primitive types and System.String are ordered and implement IComparable. Classes you write can be ordered provided that you implement IComparable in a way that makes sense for your type. Listing 5.7 shows a type that implements IComparable to support ordering of its instances.
One could easily rewrite the compound if-else statement in the CompareTo method as follows:
return this.age - other.age;That's because if this.age is greater than other.age, the method will return a positive number. If the two values are equivalent, the method will return zero. Otherwise, the method will return a negative number.
Assigning one reference variable to another simply creates a second reference to the same object. To make a second copy of an object, one needs some mechanism to create a new instance of the same class and initialize it based on the state of the original object. The Object.MemberwiseClone method does exactly that; however, it is not a public method. Rather, objects that wish to support cloning typically implement the System.ICloneable interface, which has one method, Clone:
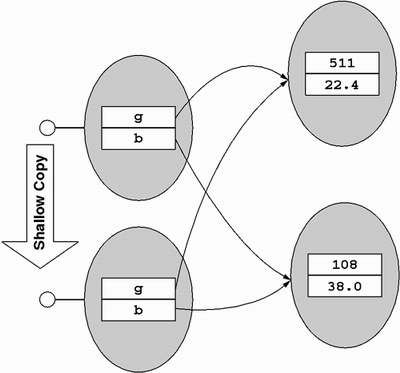
namespace SystemThe MemberwiseClone method performs what is called a shallow copy, which means that it simply copies each field's value from the source object to the clone. If the field is an object reference, only the reference, and not the referenced object, is copied. The following class implements ICloneable using shallow copies:
public sealed class Marriage : System.ICloneableFigure 5.9 shows the results of the shallow copy.
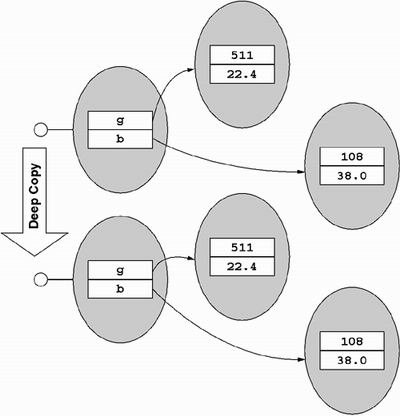
A deep copy is one that recursively copies all objects that its fields refer to, as shown in Figure 5.10. Deep copying is often what people expect; however, it is not the default behavior, nor is it a good idea to implement in the general case. In addition to causing additional memory movement and resource consumption, deep copies can be problematic when a graph of objects has cycles because a naive recursion would wind up in an infinite loop. However, for simple object graphs, it is at least implementable, as shown in Listing 5.8.
It is interesting to note that the Clone implementation in Listing 5.8 could have been written without a call to MemberwiseClone. An alternative implementation could have simply used the new operator to instantiate the second object and then manually populate the fields. Moreover, a private constructor could have been defined to allow the two parts (instantiation and initialization) to happen in one step. Listing 5.9 shows just such an implementation.
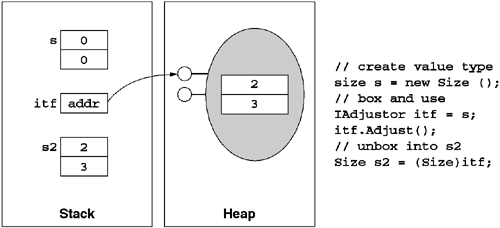
As shown in Figure 5.1, all types are compatible with System.Object. However, because System.Object is a polymorphic type, instances in memory require an object header to support dynamic method dispatching. Value types do not have this header, nor are they necessarily allocated on the heap. The CLR allows one to use a value type (which ultimately is just memory) in contexts that use object references, such as collections or generic functions that accept System.Object as a method parameter. To support this, the CLR allows one to 'clone' instances of value types onto the heap in a format that is compatible with System.Object. This procedure is known as boxing and occurs whenever an instance of a value type is assigned to an object reference variable, parameter, or field.
For example, consider the code in Listing 5.10. Note that when the instance of Size is assigned to an object reference variable (itf in this case), the CLR allocates a heap-based object that implements all of the interfaces that the underlying value type declared compatibility with. This boxed object is an independent copy, and changes to it do not propagate back to the original value type instance. However, it is possible to copy the boxed object back into a value type instance simply by using a down-cast operator, as shown in Listing 5.10. Figure 5.11 shows the process of boxing and unboxing, both visually and in code.
The CLR supports two kinds of composite types: one kind whose members are accessed by a locally unique name, and another whose members are unnamed but instead are accessed by position. The classes and structs described so far are examples of the former. Arrays are an example of the latter.
Arrays are instances of a reference type. That reference type is synthesized by the CLR based on the element type and rank of the array. All array types extend the built-in type System.Array, which is shown in Listing 5.11. This implies that all of the methods of System.Array are implicitly available to any type of array. That also means that one can write a method that accepts any type of array by declaring a parameter of type System.Array. In essence, System.Array identifies the subset of objects that are actually arrays.
Array types have their own type-compatibility rules based on the element type and the shape of the array. The shape of the array consists of the number of dimensions (also known as rank) as well as the capacity of each dimension. For determining type compatibility, two arrays whose element types and rank are identical are type-compatible. If the two arrays' element types are reference types, then additional compatibility can be assumed.
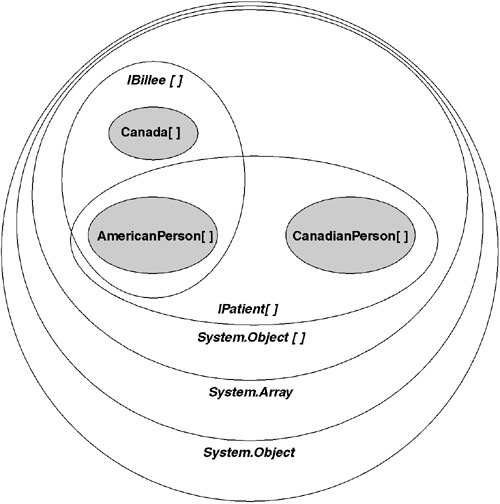
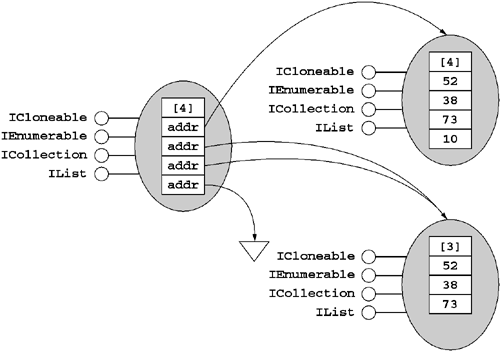
An array whose element type is a reference type (T) is type-compatible with all same-rank arrays having element type V provided that T is type-compatible with V. What this means is that all single-dimensional arrays (whose element types are reference types) are type-compatible with the type System.Object[] because all possible element types are themselves type-compatible with System.Object. Figure 5.12 illustrates this concept.
Most programming languages have some sort of array type. It is the job of the compiler to map the language-level array syntax down to a CLR array type. In the CLR, an array is an instance of a reference type and has methods, properties, and interfaces. Because arrays are reference types, an array can be passed efficiently wherever a System.Object is expected. Independent of the language in use, the total number of elements in the array is always available using the Length property.
Each programming language provides its own syntax for declaring array variables, initializing arrays, and accessing array elements. The following C# program fragment creates and uses a single-dimensional array of integers:
// declare reference to array of Int32Because arrays are reference types, the rgn variable in this example is a reference. The memory for the array elements is allocated on the heap.
The C# programming language supports a variety of syntaxes for initializing arrays. The following three techniques yield identical results:
// verboseThe compact variation has the advantage that the right-hand side of the initialization statement is a valid C# expression and can be used anywhere an int[] is expected.
An array consists of zero or more elements. These elements are accessed by position and must be a uniform type. For arrays of value types, each element will be an instance of exactly the same type (e.g., System.Int32). For arrays of reference types, each element may refer to an instance of a class that supports at least the element type, but the element may in fact refer to an instance of a derived type.
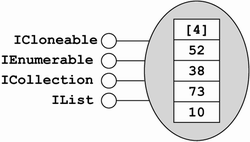
In single-dimensional arrays, the array elements are preceded by a length field that indicates the capacity of the array. One sets this field when one creates the array, and one cannot change it for the lifetime of the array. When one first instantiates an array, the CLR sets its elements to their default values. Once one instantiates the array, one can treat the elements of the array just like any other field of a type except that one addresses them by index rather than by name. Figure 5.13 shows an array of value types after each element has been assigned to. For arrays of reference types, each element is initially null and must be overwritten with a valid object reference to be useful. Figure 5.14 shows an array of reference types after each element has been assigned to.
Although the contents of an array can change after it has been created, the actual shape or capacity of the array is immutable and set at array-creation time. The CLR provides higher-level collection classes (e.g., System.Collections.ArrayList) for dynamically sized collections. It is interesting to note that the array's capacity is not part of its type. For example, consider the following C# variable declaration:
int[] rgn = new int[100];Note that the variable's type does not indicate the capacity of the array; that decision is postponed until the new operator is used. This is possible because the type of an array is based only on its element type and the number of dimensions (also known as rank) and not on its actual size.
Arrays in the CLR can be multidimensional. The preferred format for a multidimensional array is a rectangular, or C-style, array. A rectangular array has all of its elements stored in a contiguous block, as shown in Figure 5.15. Multidimensional arrays carry not only the capacity of each dimension but also the index used for the lower bound of each dimension. Despite the presence of a lower bound in the array, the CLR does not support arrays with nonzero lower bounds.
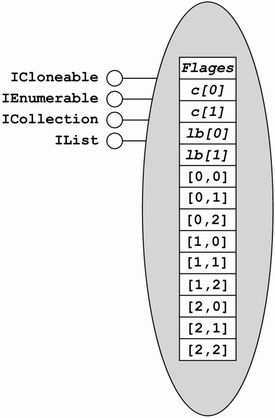
Each 'row' in a rectangular array must have the same capacity, and hence we use the term rectangular. Listing 5.12 shows a simple rectangular array program. Note the use of commas to delimit the index of each dimension. Also note the use of the GetLength method to determine the length of each dimension. For rectangular arrays, the Length property returns the total number of elements in all dimensions (i.e., for an M-by-N two-dimensional array, Length returns M * N). Additionally, rectangular arrays have a variety of initialization syntaxes in C#, the most compact of which is shown here:
int[,] matrix = ,Your programming language will likely have its own idiosyncratic ways of doing the same thing. As always, consult the appropriate programming language reference.
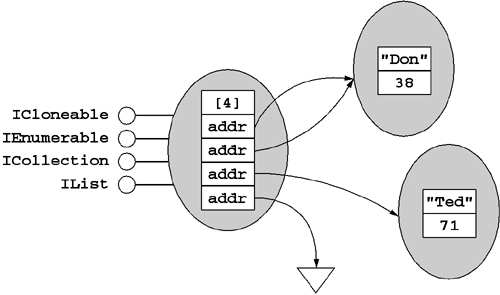
Another form of multidimensional array is a jagged array, or Java-style array. A jagged array is really just an 'array of arrays' and rarely if ever are its elements stored in a contiguous block, as shown in Figure 5.16. Each 'row' in a jagged array may have a different capacity, and hence we use the term jagged. Listing 5.13 shows a simple jagged array program. Note the alternate syntax for indexing each dimension. Also note that the use of the Length property now works as expected because the 'root' array is actually a one-dimensional array whose elements are themselves references to arrays. Although jagged arrays are quite flexible, they lend themselves to a different set of optimizations from a rectangular array. Also, VB.NET has a difficult (but not impossible) time handling jagged arrays.
Arrays support a common set of operations. Beyond the basic accessor methods shown in Listing 5.11, arrays support bulk copy operations, which are shown in Listing 5.14. In particular, the Copy method supports copying a range of elements from one array into another. Listing 5.15 shows these methods in action.
The System.Array type has several methods that apply only when the array's elements support IComparable. Listing 5.16 shows these methods. Technically, Array.IndexOf and Array.LastIndexOf require the elements only to implement Equals in a meaningful way. Listing 5.17 shows both the IndexOf and BinarySearch in action. Although the BinarySearch method requires the array to be already sorted, it performs in O(log(n)) time, which is considerably better than the O(n) time taken by IndexOf.
This chapter has focused on how objects and values are allocated and referenced. There has been no mention of how or when programmers reclaim the underlying memory an object resides in over the lifetime of a running program. This is a feature. One of the primary benefits of the CLR's managed execution mode is that memory reclamation is no longer the purview of the programmer. Rather, the CLR is responsible for all memory allocation (and deallocation). The policies and mechanisms used by the CLR for managing memory are the subject of the remainder of this chapter.
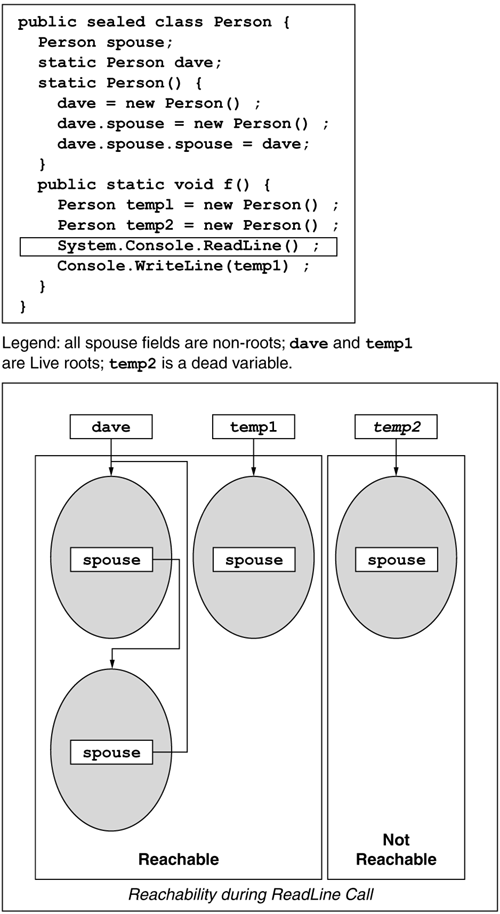
The CLR is aware of all object references in the system. Based on this global knowledge, the runtime can detect when an object is no longer referenced. The runtime distinguishes between root references and nonroot references. A root reference is typically either a live local variable or a static field of a class. A nonroot reference is typically an instance field in an object. The existence of a root reference is sufficient to keep the referenced object in memory. An object that has no root references is potentially no longer in use. To be exact, an object is guaranteed to remain in memory only for as long as one can reach it by traversing an object graph starting with a root reference. Objects that cannot be reached directly or indirectly via a root reference are susceptible to automatic memory reclamation, also known as garbage collection (GC).
Figure 5.17 shows a simple object graph and both root and nonroot references. Note that the set of roots is dynamic based on the execution of the program. In this example, the reachability graph shown is the one that is valid during the execution of the highlighted ReadLine call. Note that lexical scope is unimportant. Rather, the CLR uses liveness information created by the JIT compiler to determine which local variables are live for any given instruction pointer value. This is why temp2 is not considered a Live root in Figure 5.17.
It is sometimes desirable to hold a reference to an object that does not prevent the object from being garbage-collected. For example, keeping a lookup table of named objects in a static collection would normally prevent the named objects from ever being garbage-collected:
using System;This class ensures that, at most, one instance of a given named object will reside in memory at one time. However, because the CLR never removes the references held by the Hashtable object from the collection, none of these objects will ever be garbage-collected because the Hashtable itself remains reachable for the lifetime of this class. Ideally, the cache represented by the Hashtable would hold only 'advisory' references that, by themselves, would not be sufficient to keep the target object alive. This is the role of the System.WeakReference type.
The System.WeakReference type adds a level of indirection between an object reference and the target object. When the garbage collector is chasing down roots to determine which objects are reachable, the intermediate WeakReference stops further traversal by the garbage collector. If the target object is not reachable via some other path, the CLR will reclaim the object's memory. Equally important, the CLR sets the reference inside the WeakReference object to null to ensure that the object cannot be accessed after it has been collected. The CLR makes this internal reference available via the WeakReference.Target property, which will simply return null if the target has been collected.
To grasp how weak references are used, consider this modified version of the Get method just presented:
public static FancyObject Get(string name)Note that the Hashtable holds only weak references. This means that an entry in the cache is not sufficient to prevent the target object from being collected. Also note that when one performs a lookup on the cache, one must take care to ensure that the target object has not been collected since the time it was cached. One does this by checking the Target property for null.
The CLR performs garbage collection only when certain resource thresholds are exceeded. When this happens, the CLR takes over the CPU to track down objects that are reachable via a root reference. After identifying all of these objects, the garbage collector reclaims all remaining memory on the heap for subsequent allocations. As part of memory reclamation, the garbage collector will relocate the surviving objects in memory to avoid heap fragmentation and to tune the process's working set by keeping live objects in fewer pages of virtual memory.
The CLR exposes the garbage collector programmatically via the System.GC class. The most interesting method is Collect, which instructs the CLR to collect garbage immediately. Listing 5.18 shows this method in use. Note that in this example, one can reclaim the object referenced by r2 at the first call to System.GC.Collect inasmuch as the CLR can detect that the referenced object is no longer needed, despite the fact that it is still within lexical scope in C#. By the time the second call to System.GC.Collect executes, one can also reclaim the objects originally referenced by r1 and r3 because r1 is explicitly set to null and r3 is no longer a live variable. You can trick the garbage collector into keeping an object reference 'alive' by inserting a call to System.GC.KeepAlive. This static method does nothing other than trick the CLR into thinking that the reference passed as the parameter is actually needed, thereby keeping the referenced object from being reclaimed.
The Collect method takes an optional parameter that controls how vast the search for unreferenced objects should be. The CLR uses a generational algorithm that recognizes that the longer an object is referenced, the less likely it is to become available for collection. The Collect method allows you to specify how 'old' an object to consider. Be aware, however, that frequent calls to GC.Collect can have a negative impact on performance.
In general, there is no need for your object to know when it is being garbage-collected. All subordinate objects that your object references will themselves be automatically reclaimed as part of normal GC operation.
The preferred mechanism for triggering the execution of cleanup code is to use a termination handler. Termination handlers protect a range of instructions inside a method by guaranteeing that a 'handler' block will execute prior to leaving the protected range of instructions. This mechanism is exposed to C# programmers via the try-finally construct discussed in Chapter 6.
Despite the existence of the termination handler mechanism, old habits often die hard, and programmers who cut their teeth on C++ are accustomed to tying cleanup code to object lifetime. To allow these old dogs to avoid learning new tricks, the CLR supports a mechanism known as object finalization. However, because object finalization happens asynchronously, it is fundamentally different from the C++-style destructor that many programmers (the author included) grew to depend on in the previous millennium. Please be aware, however, that new designs that target the CLR should avoid making extensive use of finalization because it is fraught with complexity as well as performance penalties.
Objects that wish to be notified when they are about to be returned to the heap can override the Object.Finalize method. When the GC tries to reclaim an object that has a finalizer, the reclamation is postponed until the finalizer can be called. Rather than reclaim the memory, the GC enqueues the object requiring finalization onto the finalization queue. A dedicated GC thread will eventually call the object's finalizer, and after the finalizer has completed execution, the object's memory is finally available for reclamation. This means that objects with finalizers take at least two separate rounds of garbage collection before they are finally collected.
Your object can perform any application-specific logic in response to this notification. Be aware, however, that the CLR may call the Object. Finalize method long after the garbage collector identifies your object as unreachable and that this method will execute on one of the CLR's internal threads. A considerable amount of time can elapse between the point at which the garbage collector identifies your object as unreachable and the point when its finalizer is called. If you use your finalizer to release a scarce resource, in many cases it will run far later than is tolerable, and this limits the utility of finalization.
Classes that override the default Finalize method need to call their base type's version of the method to ensure that any base class functionality is not bypassed. In C#, you cannot implement the Finalize method directly. Rather, you must implement a destructor, which causes the compiler to emit your destructor code inside a Finalize method followed by a call to your base type's Finalize. Listing 5.19 shows a simple C# class that contains a destructor. Note that the comments show the compiler-generated Finalize method.
Because GC is asynchronous, it is a bad idea to rely on a finalizer to clean up scarce resources. To that end, there is a standard idiom in CLR programming of providing an explicit Dispose method that clients can call when they are finished using your object. In fact, the System.IDisposable interface standardizes this idiom. Here is the definition of System.IDisposable:
namespace SystemClasses that implement this interface are indicating that they require explicit cleanup. It is ultimately the client programmer's responsibility to invoke the IDisposable.Dispose method as soon as the referenced object is no longer needed. Because your Dispose method is likely to perform the same work as your Finalize method, it is standard practice to suppress the redundant finalization call inside your Dispose method by calling System.GC.SuppressFinalize, as shown in Listing 5.20.
Listing 5.21 shows a client that explicitly invokes the Dispose method on an object after it has finished using it. To ensure that the user of the object always calls the Dispose method even in the face of exceptions, the C# programming language provides a construct that wraps the declaration of an IDisposable-compatible variable with a termination handler that implicitly calls Dispose for you. This construct is the C# using statement.
Figure 5.18 shows the syntax for the using statement. The using statement allows the programmer to declare one or more variables whose IDisposable.Dispose method will be called automatically. The syntax for the resource acquisition clause is similar to that for a local variable declaration statement. One can declare more than one variable, but the types of each of the variables must be the same. Listing 5.22 shows a simple usage of the using statement. Note that in this example, because the using statement is used with IDisposable-compliant objects, the compiler emits code that ensures that the Dispose method is invoked even in the face of unhandled exceptions or other method termination (e.g., a return statement).

Objects are polymorphic entities that the CLR always allocates on the heap. Values are simply formatted memory that is allocated as part of a declaring context or scope. Both objects and values can support the concept of equivalence and ordering, but only objects can truly support the concept of identity. Although it is possible to force values to act like objects (or objects to act like values), the programming model is much easier to live with when one uses the right kind of instance for the task at hand
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1253
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved