| CATEGORII DOCUMENTE |
| Asp | Autocad | C | Dot net | Excel | Fox pro | Html | Java |
| Linux | Mathcad | Photoshop | Php | Sql | Visual studio | Windows | Xml |
An
Introduction to
ADO, short for ActiveX Data
Objects, and an associated technology, OLE DB, are the current incarnations of
Microsoft's data access technology. Visual FoxPro developers, having a
blindingly fast native data engine and easy access to back ends like SQL Server
and Oracle, have long turned a blind eye to this side of Microsoft's offerings.
In a multi-tier world, however, you might need to expand your horizons a bit.
In this chapter, I'm going to give you a quick tutorial on
VFP's data access is pretty darn great-it's fast, easy to use, and pretty stable. The basic concepts-record pointers navigating through a set of relational tables-haven't changed for 20 years. But not all data in the world out there is stored in .DBFs; in fact, there's an awful lot of data that isn't stored in relational tables at all.
Microsoft has been
working on the problem of providing access to this entire universe of data-and
doing so in a consistent manner. The technologies they've been working on
through the 1990s are starting to mature, and the current version, Universal
Data Access, is implemented through a pair of acronyms:
A (very brief and very rough) history of the Microsoft data access strategy
I'm going to skip over the burning questions of the moment-What is ADO and why do I care?-to give you a bit of perspective on the data access strategy coming out of Redmond.
In years gone by, Microsoft was well known for not doing data well. Until the early 1990s, in fact, after nearly 15 years in business, they still didn't have a database product of any sort. They had an excellent word processor, a great spreadsheet, a pretty good presentation tool, and so on. But the one big hole in their suite of desktop applications was any sort of database tool.
Rumor has it that they had made several attempts in the late '80s and early '90s, and each, for one reason or another, never matured enough to see the light of day. Finally, a new group put together a product called Access, and this tool was intended to do two things. First, it was going to provide a mechanism to access and manipulate a variety of data from all over the organization-thus, its name. Second, it was going to provide a mechanism for desktop PC users to work with databases of their own. Access was going to be a new part of the office suite of tools, next to Word and Excel. And for this purpose, Access needed its own database engine. Thus, JET was born.
As has been repeated ad
nauseam since its creation, JET was not named because it was fast. Rather, JET
is an acronym for "Joint Engineering Technology." Yes, it was a database engine
designed by a committee, and the early versions definitely demonstrated all the
attributes accorded to something designed by a committee. Nonetheless, as the
While this was happening, another branch of Microsoft went out and bought Fox Software, acquiring a popular and powerful database tool for the application-development side of the business. Also coming along for the ride, or perhaps the underlying reason for the acquisition, was a top-notch development team and a rabid development community.
Microsoft was finally getting serious about data.
The next step, however, was not to simply build on these two platforms, but to figure out a broader strategy for gaining access to (and, eventually, controlling) all of the data at the desktop, and then the company. A new mechanism was needed.
The database engine
development teams iterated several times, and if you've done any Visual Basic
work or know any Visual Basic developers, you've probably heard at least part
of the litany of acronyms. The most recent, before
Another, grander mechanism was needed. Enter OLE DB, stage left.
OLE DB (and
In order to explain where OLE DB fits in, let me take you back to the days of printer drivers. Back before Windows, it was a lot more difficult to talk to printers from various applications. Initially, you had to put special codes, called control strings, in your application to make a printer do anything more than print Courier 10 point. And each application required you to do this differently. It was really hard, it was boring work to figure out how to do it, and it didn't work very well. And the worst part was that if you needed to send output to a different type of printer, you had to go through the whole process again, using the special codes for that printer.
Then someone came up with the idea of creating "drivers" for printers. Instead of programming special codes, your application would come with a set of intermediary programs, each of which knew how to translate output from your application into the codes that a specific printer required. Thus, your application would have one driver for a wide-body Epson, another driver for that brand new Hewlett-Packard LaserJet, and a third driver for the fancy Sony label printer. Your app talked to the driver, and the driver talked to the printer. What could be easier?
Windows, of course, then put a common (and easy-to-use) interface on this process, but the idea remained the same.
Talking to data, on the other hand, is still sort of back in the days of inserting special codes in each program. Your application generally knows how to talk to only one type of data. Visual FoxPro reads .DBFs. Excel reads .XLS files. SQL Server opens .MDF files. And none of them reads anyone else's data-at least not very well.
Imagine if you had a set of drivers that acted as intermediaries between applications and data. And all you had to do was tell your application to use a certain driver and the app could then access data from a variety of sources. Wouldn't that be neat? Well, we've already got it in place, in a limited fashion. This is what ODBC does, for a few well-defined types of data. You can create a data source with an ODBC driver, and then configure your application to use that data source. Your application can then access the data just as if it belonged to the app itself.
There are a number of technical issues and process-oriented issues that limit ODBC in manners such that it wasn't the be-all and end-all of data access. But it was a good start, and is in widespread use today.
What a developer would really like, instead of just a dumb connection to selected data, is a more robust and flexible application that managed multiple "drivers" that could talk to a wide variety of data. Not just relational data sitting in Oracle, SQL Server, and Excel, but also data in e-mail systems, binary data like multimedia files, and random textual data like in desktop organizers.
And this driver manager application would be able to manipulate that data with a common lingua franca, so that whether your program was Visual FoxPro, Visual Basic, Excel, or a script on a Web site, the data could be accessed the same way.
This driver manager application is essentially what OLE DB is-and the drivers are called "providers." The only trouble is that using OLE DB is kinda hard. It's a sophisticated, low-level interface, and requires a lot of work to communicate with. What we really need, then, is a user-friendly interface to OLE DB.
And that's what
What is
So
what is
Since it's just a .DLL, you instantiate
So it's no big deal, and
that's why this basic fact seems to be overlooked a lot. Every discussion of
Where do I
find
The
Not sure what you have?
Do a file search in Windows Explorer for "
Depending on what you've
got installed on your machine, you might have more than one version of
What are
the previous versions of
Version
1.0 of
Version 2.0 of
Version 2.1, the current version, includes the ability to save client-side recordsets as XML documents.
Because these new releases have been introduced rapidly one after another, you very well might find MDAC 1.5 and MDAC 2.0 files on your machine along with 2.1 versions.
Getting started with ADO
I know, I know. You want to see some code. Well, we can do that! First, let me explain what you need to follow along, and the steps you're going to go through.
If you're in front of your computer, you'll need Visual FoxPro 6.0, SP3 (duh!), the latest version of MDAC, and some data. You can use either Visual FoxPro's TasTrade sample database or the Pubs database in SQL Server 7.0. You can also use another data source, but you'll have to substitute the appropriate names and IDs for the ones I use.
Bare-bones steps for
accessing data through
Once you've got your machine set up, here are the steps you'll go through:
1. 1. Create a Data Source Name on your computer.
2. 2. Instantiate ADO.
3. 3. Connect to the data.
4. 4. Create a recordset.
5. 5. Manipulate the recordset.
6.
6. Wrap a user interface around
7. 7. Go home.
Step 6 is there for a reason, by the way. You might end up having so much fun that you forget to go home. I don't want to get in trouble with your family by keeping you here late.
Create a Data Source Name
This is one of those topics that may seem a little awkward to pure VFP developers. A Data Source Name (DSN) is a file on your computer that identifies how to connect to a data source somewhere on your network. For example, suppose you're on your workstation and you want to connect to a SQL Server database on another machine. You'll need to know the following pieces of information: the name of the machine that the SQL Server is running on, the name of the SQL Server database, the username, and the password.
Once you've connected to the database, you'll need to know more stuff, such as the structure of the database files-the names of tables and fields, and perhaps something about the data inside the database.
A DSN helps you with the first half of this. It contains all this information in a single, easy-to-use place.
You can create three types of DSNs: User, System, and File. Basically, a User DSN is a data source that is available only to a specific user, and a File DSN is a data source for a specific file. While I'm sure there's a good reason for each of them, I've never run into a situation where I needed to use one. A System DSN is a data source definition for the computer, and security across multiple users is handled either by the operating system or the back-end database. So I'm just going to concentrate on System DSNs.
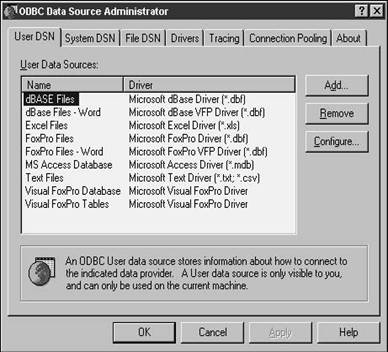
To create a DSN for either TasTrade or SQL Server (the screen shots that follow will use SQL Server), open the Control Panel from the Start, Settings menu, and select the ODBC Data Sources applet. You'll be presented with the ODBC Data Source Administrator dialog shown in Figure 28.1.
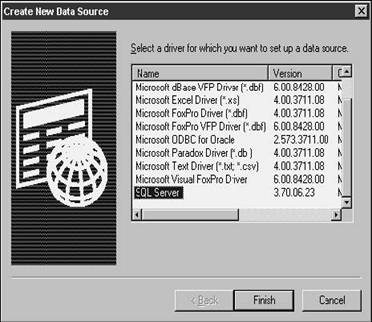
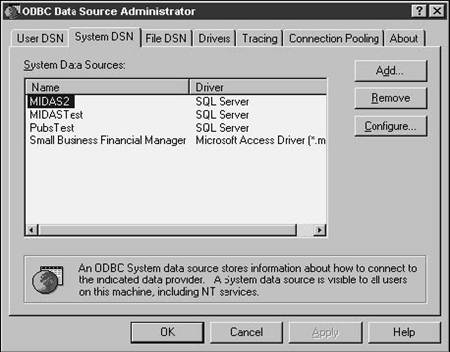
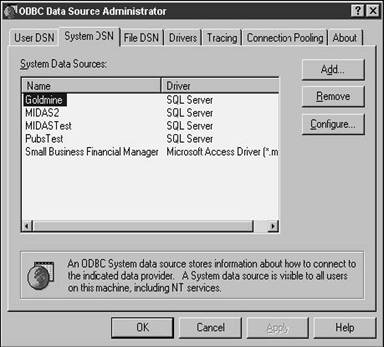
I'm going to ignore the first tab, User DSN, as well as the File DSN tab, shown in Figure 28.2. The action for the rest of today will be centered on the System DSN tab, shown in Figure 28.3.
The System DSN tab shows all of the currently installed System Data Sources. In Figure 28.3, you'll see four different data sources: a test DSN for the Pubs database that comes with SQL Server, a test DSN for another SQL Server database named MIDAS, a production version DSN for a new version of the MIDAS database, and a DSN for the Small Business Financial Manager that relies on Access instead of SQL Server. How it got there, I don't know-I don't remember installing something like this. (Have you had experiences like this, too?)
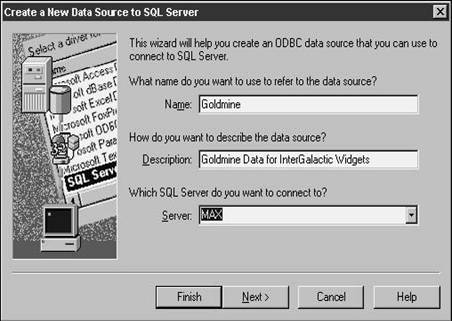
To add another DSN, click Add to open the Create a New Data Source to SQL Server dialog as shown in Figure 28.4.
The first few times you navigate through this dialog can be tricky. The Name you use to refer to the data source is the actual text string you'll use as a parameter in your code, like so:
oC.open('PubsTest','sa','')
So if you use a moniker like "Herman's Way Cool Sales Database" as the "Name", you'll end up writing code like this:
oC.open('Herman's Way Cool Sales Database','sa','')
Probably not a good idea. Instead, make the Name short and sweet. You can enter "Herman's Way Cool Sales Database" in the Description text box.
Finally, pop open the Server combo box to select which SQL Server you want to connect to. If you're new to SQL Server, this can be a bit misleading.
You know how you can use the term "server" to mean either a physical box, like a "file server," or a piece of software, like "Web server"? In this instance, the term "SQL Server" means the program running on a box. In Figure 28.4, I've got a box named "MAX" upon which SQL Server 7.0 is running. If I had another box named, say, ZEUS, with SQL Server running on it as well, there would be two items in the Server combo box, and I'd have to choose which of the two SQL Servers I wanted to connect to. So, to be clearer, the prompt should really say something like "Which instance of SQL Server do you want to connect to?"
What if you open this combo box and the name of the box upon which your SQL Server is running doesn't show up? Well, you're hosed. The
* documentation
says, "Contact your System Administrator", but, let's face it,
you're probably the system administrator, aren't you? When this has
happened to me (it really isn't a frequent occurrence, which is probably why
there's no help or error handling for this situation), I've ended up
uninstalling
the SQL Server from the box it was running on, and reloading it from scratch.
What else ya gonna do?
How do you name your machines? I've found a whimsical naming scheme is difficult to keep track of, so I've decided upon a temporal scheme, where the
![]() name has to do
with the period of time that the machine was acquired. For instance, the box I
used during the VFP 3.0 beta is named TAZ, the box I used during the VFP 5.0
beta is named ROADRUNNER, the 6.0 beta box is named TAHOE, the 7.0 box is named
SEDONA, and so on.
name has to do
with the period of time that the machine was acquired. For instance, the box I
used during the VFP 3.0 beta is named TAZ, the box I used during the VFP 5.0
beta is named ROADRUNNER, the 6.0 beta box is named TAHOE, the 7.0 box is named
SEDONA, and so on.
This method is helpful because it's an instant reminder of approximately how old the machine is. TAZ, for example, has been relegated to the basement, serving as a print server-what else are you going to do with a P90 with 32 MB of RAM? It's also helpful because it means I get to buy a new machine pretty often.
Unfortunately, MAX showed up on our doorstep one night when there wasn't a beta in sight, so there wasn't a handy acronym. However, we happened to be watching The Grinch Who Stole Christmas, and thus the machine was named MAX (after the dog).
Assuming you've found your SQL Server, click the Next button to continue with the wizard. The next dialog, shown in Figure 28.5, allows you to specify how to connect to the SQL Server. Whether you want NT authentication to do the work for you, or if you want SQL Server authentication, is up to you and your network configuration and requirements. Go ahead and click Next again.
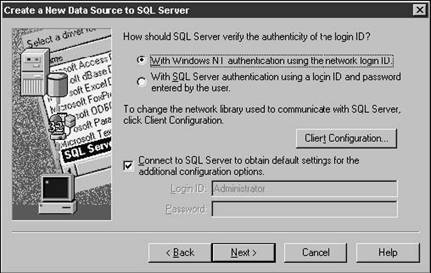
Figure 28.5.The next step in the wizard is to identify how to connect to the SQL Server.
Within a SQL Server installation on a computer,
you can have one or more databases. For example, as shown in Figure 28.6,
on the SQL Server on MAX, I've currently got a number of databases, including
model, msdb, Northwind, Pubs, tempdb, and a few more that aren't visible in the
default database combo box. Select the database that you want to connect to. In
this case, Pubs would be a good choice, because the
Again, what if your database doesn't show up in this list? Time to call your SQL Server Administrator-hoping that it's not you. A SQL Server database is just a big file with an .MDF extension, but just copying it to the box you've got SQL Server running on isn't enough. You need to go into SQL Server's Query Analyzer and attach the .MDF within SQL Server. You'd use a command like:
EXEC sp_attach_db@dbname=N'YOURDATA', @filename1='e:yourdiryourdata.mdf'
where YOURDATA is the name of the .MDF file, and so on. Well, this isn't a SQL Server tutorial, but if you get hung up on the initial attachments, a lot of the rest of the chapter isn't going to do you as much good, is it?
Back to the creation of your DSN.
After clicking Next, you'll get to change a bunch of settings in the dialog shown in Figure
28.7. I usually blow right by this one.
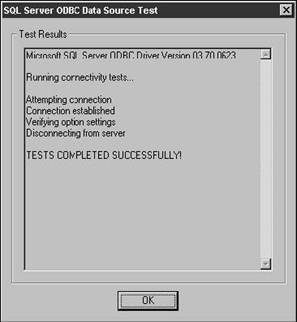
Clicking the Finish button in the dialog in Figure 28.7 allows you to verify what you've done through a configuration dialog as shown in Figure 28.8. I always click the Test Data Source button because I'm still skeptical about whether or not this is really going to work. Kind of like getting ready to go on vacation, getting in the car, driving down the street, and then driving back to make sure, one last time, that you locked the front door.
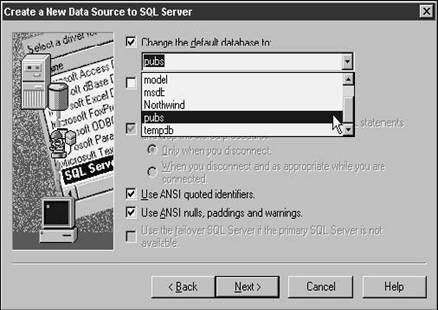
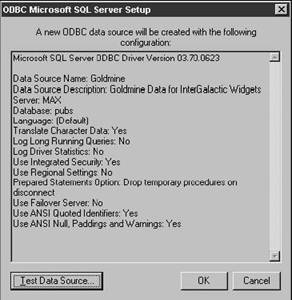
Figure 28.8.The ODBC Microsoft SQL Server Setup dialog allows you to verify the settings you've selected and to test the connection.
If the connection works, you'll get a dialog like Figure 28.9. I don't know what it looks like if it fails because I don't think the test has ever failed on me.
Click OK in the Test dialog (Figure 28.9), and then OK in the Setup dialog (Figure 28.8), and you'll see your new System DSN in the System DSN tab of the ODBC Data Source Administrator dialog, as shown in Figure 28.10.
Now it's time to attach to the data. As I said, I'm going to use the PubsTest System DSN in the following examples. If you've created a DSN to the SQL Server database Pubs and called it "HERMAN," you'll need to make the appropriate substitutions. If you're attaching to a different database, you'll need to also change the code that connects to specific tables and talks to specific fields in the tables. That's what you get for not following along with the teacher.
Instantiate
Now that you've got a DSN, you can start to write code. Create a new directory to
![]() work in, and create a new program file, say,
TEST1.PRG. If you just want to follow along, you can find the source code for
this chapter in CH28 in the source code downloads for this book. If the
work in, and create a new program file, say,
TEST1.PRG. If you just want to follow along, you can find the source code for
this chapter in CH28 in the source code downloads for this book. If the
�.* test1.prg
�.* creates a connection objectoConn = createobject('adodb.connection')
If the
By itself, a Connection object isn't very interesting. Well, maybe a few people on the far end of the pocket-protector spectrum are getting all hot and bothered, but the rest of us would like a bit more.
Connect to the data
Now that you've got a Connection object, you'd like to use it to connect to a specific data source. Use the "open" method of the Connection object, like so:
oConn.open('PubsTest', 'sa', '')
This passes the PubsTest DSN, along with the default username of "sa" and default password of a blank. If you'd named your DSN "Herman's Way Cool Sales Database" as the DSN Name, you'd use that string instead of "PubsTest."
Create a recordset
Next, it's time to use this connection to get hold of data. First, create a Recordset object:
oRS = createobject('adodb.recordset')
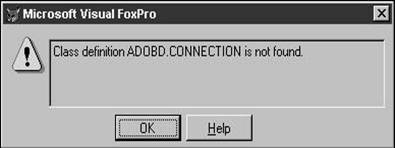
Just like creating the Connection object, the Recordset object is empty until you do something with it. So the next step is to populate the Recordset object, like so:
ORS.open('select * from AUTHORS', oConn)
The first parameter is a simple SQL SELECT command-note that you need to have some inside knowledge of what the structure is, like the name of the table you want data from. And you pass the object reference of the connection you want to use-you could have several connections open, and so you'd need to specify which connection you want to use. Altogether, the program looks like this now:
�.* test1.prg
�.* creates a connection objectoConn = createobject('adodb.connection')oConn.open('PubsTest', 'sa', '')oRS = createobject('adodb.recordset')ORS.open('select * from AUTHORS', oConn)
In Visual FoxPro, the equivalent of these four commands would be:
use PUBSTEST
Manipulate the recordset
Now the good part starts. Time to get into the data itself. The first shot at this will simply scroll through the recordset and print the name of the author to the desktop. Here's how:
do while !oRS.eof()
? oRS.fields('au_fname').value + ' ' + oRS.fields('au_lname').value
oRS.MoveNext()enddo
Pretty easy, eh? As a VFP developer, you already know most of this. The EOF() property of the Recordset object makes sense, and the MoveNext() method is also obvious. The syntax of the Fields collection-using the name of the field inside parentheses, and then identifying which property (in this case, the Value property)-is a little strange, but easy enough to understand.
And that's all there is to it!
Wrap
a user interface around
You're probably going to have to search high and low to find a user who would put up with a database program with no user interface, so how about wrapping a form around this code? Once the form has a handle on this-here recordset, you can display the information to the user in a series of text-box controls, and give users the ability to navigate through the recordset themselves. Golly, the more things change, the more they stay the same, don't they?
The screen in Figure 28.12 shows a simple navigation form that displays the first and last name for an author in the PUBS AUTHOR table.
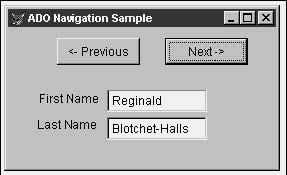
To create this form (it's called TEST2.SCX in this chapter's source code), create an
![]() empty form, and add two command buttons
(cmdNext and cmdPrevious) and two text boxes (txtFirst and txtLast). Add a
method called MapControls, and a property called
empty form, and add two command buttons
(cmdNext and cmdPrevious) and two text boxes (txtFirst and txtLast). Add a
method called MapControls, and a property called
oRSAuthor. Then stuff the following code in their respective methods:
�.* init()oC = createobject('adodb.connection')
oC.open('PubsTest','sa','')
thisform.oRSAuthor = createobject('adodb.recordset')
thisform.oRSAuthor.open('select * from authors', oC, 1)
thisform.mapcontrols()
�.* mapcontrols()thisform.txtFirst.value =
thisform.oRSAuthor.Fields('au_fname').value
thisform.txtLast.value = thisform.oRSAuthor.Fields('au_lname').value
*
cmdNext.click()if !thisform.oRSAuthor.eof()
thisform.oRSAuthor.movenext()
endif
thisform.mapcontrols()
�.* cmdPrevious.click()if !thisform.oRSAuthor.bof()
thisform.oRSAuthor.moveprevious()
endif
thisform.mapcontrols()
Now it's time to explain what's going on.
The code in the Init() looks mostly familiar. The first difference is that the object reference in the recordset creation is assigned to a form property, not simply to a memory variable as it was in TEST1.PRG. If it had been stored to a memvar, the memvar would have disappeared as soon as the Init() was finished, right? By assigning it to a form property, the entire form has access to the record set.
The MapControls method, first called from the
end of the Init(), simply binds data from specific fields in the recordset to the
text boxes. Sort of a hard-coded
The Next and Previous
command buttons' Click() methods are no big deal. First, the position of the
recordset "record pointer" is checked to make sure that you're not at beginning
or end of file, using the BOF and EOF properties of the recordset. Hmmm, BOF?
EOF? Sound familiar? Has Wayne Ratliff (the creator of dBASE II) infiltrated
the
And that's all she wrote. Well, actually, that's not all. There's one little difference in this code when compared to the TEST1.PRG code, and it's in the call to the recordset Open() method. Notice the third parameter: "1." Obviously it's important, or I wouldn't have put it there, or begun to make such a big deal out of it here.
Unlike VFP, where a cursor is a cursor is a
cursor, there are four types of
If you'd like to see what happens if you don't specify a non-forward-only recordset, drop the "1" parameter from the Open() method and run the form again. You'll be able to click Next until you reach the end of the recordset, but the first time you click Previous, you'll get a friendly warning as shown in Figure 28.13.
The MovePrevious method is not allowed with a forward-only recordset, and generates an error message.
Now, before I wrap up,
I'd like to mention one more thing. You've probably jotted down a number of
questions in the margins as you've been reading through this. How did I know to
use a "1" for a Keyset recordset, for example? And what are the other types of
recordsets? How did I know any of this syntax, in the first place? Good
questions, all of them. I'll cover the answers to these, and other interesting
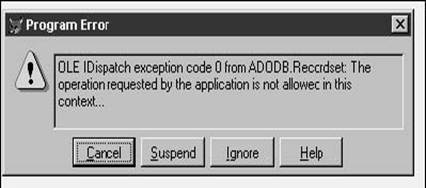
Go home
Umm, do I really need to include more details in this step?
The
In the olden days, a piece of software would
come with a manual and a quick reference card, and you could use the card to
find out what language elements you had available to you, and the reference
manual to find out more details about using those elements.
First, just about everything that comes from
Microsoft anymore has an online help file in the form of Compiled HTML Help, so
if you passed by its reference in the Readme file, just do a search for
There are also a number of books on
But even with these resources, you'd probably
like a short introduction to the object model for
The diagram in Figure
28.14 shows the primary objects and collections in the
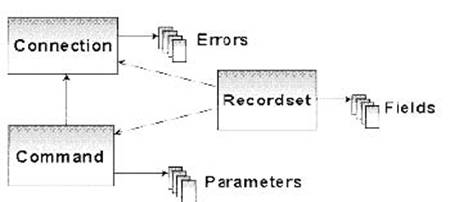
Access from your application to a data source is made through a connection. You can think of a connection as a "pipe" through which data is transferred. In fact, one of those troughs attached to a cement truck might be the best analogy, because not only do you have to have the trough, but you also have to point the trough to where you want the cement (or data) to go.
A command issued across a connection manipulates the data source in some way-either navigating through the data or maintaining (adding/deleting/editing) it. Commands aren't islands unto themselves; often you have to include variable data with the command. This variable data is a parameter. For example, you might want to apply a filter against a data source. The application of the filter would be a command, while the specifications of the filter (all names beginning with "A", all balances over $100) would be contained in parameters.
Commands that return data place that data in local storage called a recordset, much like a SELECT statement in Visual FoxPro creates a cursor. As I mentioned before, you can think of a recordset as being an objectified VFP cursor-with properties and methods.
A recordset consists of one or more rows, and it's important to note that there isn't a single object that represents a single row in a recordset. However, a row in a recordset consists of one or more fields, just like any other relational table.
The last object in the whole smash is the Errors collection. Errors can occur for any number of reasons-most often due to the inability to establish a connection, execute a command, or perform an operation (like I showed you when trying to move backward in a forward-only recordset).
The Connection object
The Connection object hosts a single session with a data source. The actual functionality available to the object depends on which OLE DB provider is being used. In addition to configuring the connection, the Connection object can execute a command, obtain schema information about the database, and examine errors returned from the data source with the Errors collection.
The Recordset object
A Recordset object represents the subset of records returned by an executed command, much like a Visual FoxPro cursor. The Recordset object has a mechanism similar to the record pointer in Xbase languages, such that at any time, a reference to the Recordset object is referring to a single record in the recordset.
There are four types of recordsets available, depending on the capabilities of the OLE DB provider. These are:
. . Dynamic cursor. This recordset allows you to view changes (additions/deletions/edits) that other users have made.
. . Keyset cursor. This recordset acts just like a dynamic cursor except that it only allows you to view edits-not additions or deletions-that other users have made.
. . Static cursor. This recordset acts the most like a VFP cursor in that once you've gotten it, the records are yours until you commit changes-and thus, changes that other users make are not visible to you until you refresh the recordset.
. . Forward-only cursor. This recordset is just like a static cursor except you can only move forward through the recordset. Sounds silly, right? This can be useful when you only need to make a single pass through a recordset, such as in a report, or when populating a List Box or Combo Box control, because it's faster than other types of recordsets.
Note that (1) not all providers support all types of recordsets, and (2) if you don't specify a cursor type, a forward-only cursor is created by default.
Recordsets support all sorts of great methods and properties. For example, MoveFirst, MoveLast, MoveNext, and MovePrevious do exactly what they sound like. Move is similar to VFP's SKIP command, while the AbsolutePosition and Filter properties also allow you to move through the recordset as you desire.
Update commits changes immediately, while UpdateBatch commits a group of changes upon call. The Status property allows you to determine if any conflicts were encountered while writing changes.
The Fields collection
A Recordset object has a Fields collection that is made up of Field objects. The Field object has a number of properties, such as Name and Value, that return information about the field. As you saw in the example above, the syntax for referencing a specific Field object is a little tricky at first:
oRS.fields('au_fname').value
But after working with it for a bit, the syntax makes a lot of sense. Other handy properties of the Field object include Type, Precision, and NumericScale, which all return characteristics of the field; DefinedSize and ActualSize, which return the field size and size of the data within the field, and manipulate the contents of fields with large amounts of binary or character data with the AppendChunk and GetChunk methods.
The Command object
The Command object is a definition of a specific command to be executed against a data source. For example, you can define the executable text of a command, such as a SQL SELECT statement, much like when you assign a SQL SELECT statement to a memory variable, define parameters, execute the command, and control how the command will execute.
The Parameters collection
The Parameters collection defines an argument that will be used with a Command object. For example, a SQL SELECT statement could use a parameter to define the column name in the fields list and another in its WHERE clause.
The Errors collection
The Errors collection is
the repository for information about problems encountered during a single
operation of data access. Each Error object represents a specific provider
error, not an
Note that
Cool enough, though, you can use AERROR to trap these errors and deal with them in your error handler. For example, you could set up an error handler like so:
�.* test3.prg
�.* generates and traps an
�.* click on Next a few times, then click on
�.* Previous to generate an error because TEST3.SCX
* has a Forward-only cursordo form TEST3 return
PROCEDURE Handler *
�.* quick and dirty error handler hijacked
�.* from the Hacker's Guide to Visual FoxPro 6.0
�.* (c) Tamar Granor and Ted Roche*
�.* Handle errors that occur
�.* In this case, we'll just figure out which kind they are
�.* then save the information to a file
LOCAL aErrData[1]
= AERROR(aErrData)
DO CASE
CASE aErrData[1,1] = 1526
* ODBC Error
WAIT WINDOW 'ODBC Error Occurred' NOWAIT CASE BETWEEN(aErrData[1,1], 1426, 1429)
* OLE Error
WAIT WINDOW 'OLE Error Occurred' NOWAIT OTHERWISE
* FoxPro error
WAIT WINDOW 'FoxPro Error Occurred' NOWAIT ENDCASE
LIST MEMORY TO FILE ErrInfo.TXT ADDITIVE NOCONSOLE
RETURN
Dealing with constants
Remember back when I
used a parameter of "1" to open a recordset as a Keyset recordset so that
navigation could occur in both directions? Well, if you look in the
recordset.Open Source, ActiveConnection, CursorType, LockType, Options
The third item in the list (after Source and ActiveConnection), CursorType, is defined as an optional parameter that determines the type of cursor that the provider should use when opening the record set. It can be one of the following constants:
|
Constant |
Description |
|
adOpenForwardOnly |
(Default) Opens a forward-only-type cursor. |
|
adOpenKeyset |
Opens a keyset-type cursor. |
|
adOpenDynamic |
Opens a dynamic-type cursor. |
|
adOpenStatic |
Opens a static-type cursor. |
The problem is that you can't plug "adOpenForwardOnly" into a Visual FoxPro statement and expect the statement to execute properly. As you know, a constant is a mnemonic text string that stands in place of a numeric (or other data type) value that might not be as easily recognizable. So while the syntax:
thisform.oRSAuthor.open('select * from authors', oC, adOpenKeyset)
is a lot easier to understand than:
thisform.oRSAuthor.open('select * from authors', oC, 1)
it won't work in VFP. Of course, you could define a VFP constant, either in your code or in a VFP header file that is included in the appropriate place in your project, like so:
#DEFINE adOpenKeyset 1
However, the problem remains: How do you know
that adOpenKeyset is equal to 1? The
As with many things in life, there's an easy way and a hard way to find out the enumerated values of these constants. The easy way is to find the ADOVFP.H include file, which is in the Program FilesMicrosoft Visual StudioVFP98ToolsXsourceVFPSourceWizardsWztable directory. (You might have to unzip the XSOURCE ZIP file in the VFP98Tools directory.)
You can also roll up your sleeves and do a bit of spelunking via the Visual Basic Object Browser. While not necessary, being comfortable with the Object Browser will come in handy one day, and the better acquainted with it you are, the better off you will be.
Open the Object Browser in Visual Basic and
inspect the
28.15. You should also have a toolbox labeled General with a selection tool and 20 controls.
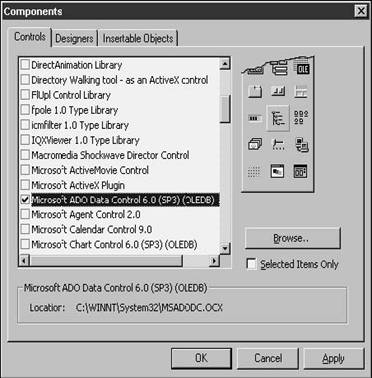
Right-click in an empty area in the General toolbar and select the Components menu option to open the Components dialog. Scroll down the list until you get to the Microsoft ADO Data Control 6.0 (SP3) (OLEDB), and check the check box on the left, as shown in Figure 28.16.
Close the dialog by clicking the Apply and OK command buttons, and you'll see the new control added to the General tab of the toolbox, in the lower right corner, as shown in Figure
28.17.
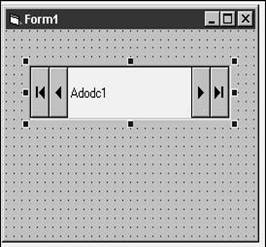
Now pop the control onto the form by selecting
the control in the toolbox, and then clicking and dragging the control's
outline on the form as shown in Figure 28.18. Note that simply clicking
on the form isn't enough-you have click and drag the control to place it on the
form. Alternately, you could just double-click the
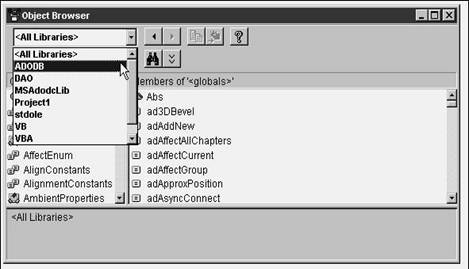
Yeah, this is a lot of work just to find out what a constant is, isn't it? Well, it is the first few times, but once you see the nifty Object Browser that's part of Visual Basic, you'll pine for one in VFP. Here it is. Select the control on the form (as opposed to the form itself), and then either press F2 or select the View, Object Browser menu command in Visual Basic. The Object Browser will open. Pop open the combo box of libraries as shown in Figure 28.19, and select the ADODB library.
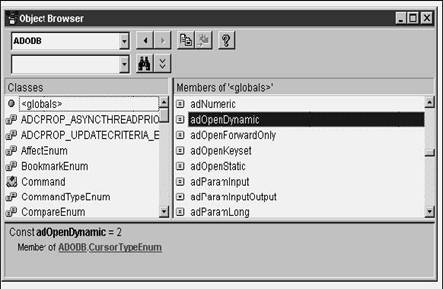
Click on the <globals> item in the Classes list box on the left, and you'll see a list of all available constants in the Members list box on the right. Scroll down to look for the constant (or constants) of interest. In Figure 28.20, I've highlighted the adOpenDynamic constant. In the bottom of the Object Browser, you'll see a bit of information about this member, including the declaration that sets the constant's value to 2.
This is how I found out that adOpenKeyset is equivalent to 1, for example, and how you can determine what the rest of the constants you're interested in evaluate to as well.
So should
you use
Now that we're done with this whirlwind tour of
Well, if you're just
dealing with straightforward data access in LAN and Client-Server applications,
you shouldn't.
But
As a result, if you're going
to be using VFP as your middle-tier development tool, the marriage of VFP and
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1284
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2026 . All rights reserved