| CATEGORII DOCUMENTE |
| Asp | Autocad | C | Dot net | Excel | Fox pro | Html | Java |
| Linux | Mathcad | Photoshop | Php | Sql | Visual studio | Windows | Xml |
Weird Question Time
The current pitch coming
from Microsoft's app dev groups is "Windows DNA"-an architecture for creating
and deploying distributed applications across multiple computers of various
platforms. You can read all about it elsewhere, such as at the Microsoft Web
site and just about every piece of marketing literature that comes out of
But you have to decide whether this is for you. In talking to developers all over the world, I've heard that many of them feel like they're the only developer on the planet who hasn't deployed a half-dozen multi-tier applications using COM+ on the Windows 2000 Beta yet. Well, 90% of you can't all be in the "last 10%." It's important to provide some perspective on all the hype you're exposed to. In this chapter, I'm going to provide you with my perspective-my opinion-on the state of things at the end of 1999. I'm also going to pull together a miscellany of definitions and other items that don't seem to be covered anywhere else, and that don't seem to fit anywhere else.
My physics teacher in high school stood in front of class on the first day and said, "Remember those weird questions you used to ask your parents? The ones like 'If I'm in an elevator that's falling to the ground, and I jump up at the last minute, will I get killed?'" Remember how your parents used to say, "I'm busy" in response? Well, now's the time to ask those weird questions.
And now here's the time to ask those questions you didn't want to ask anyone else, because you thought you were the only one who didn't know the answer.
Should I or shouldn't I?
The next few pages may get me excommunicated as far as Microsoft (and other vendors involved in the distributed arena, should any of them mistakenly pick up this book) is concerned, but I have to be blunt-I'm not a big fan of this Windows DNA and distributed computing stuff. At least not yet. Here's why.
First, it feels a lot more like marketing than anything with real substance. Sure, you've seen the demos: How to build a mission-critical, enterprise-wide application supporting hundreds or thousands of people-in two and a half hours. Uh huh.
The situation is that LAN applications are old news. We know how to build them, and there isn't a lot of hoopla around them anymore. People take them for granted. Client/Server also had its day in the sun, but that's yesterday's news as well. Product vendors (and the industry rags) need something new to blab about. Three-tier, N-tier, Web-enabled, distributed-these are the hot buttons now.
But I don't see a lot of
people doing it yet. Sure, I'm in
Second, the architecture is not sound. Reliability is haphazard; error handling is abysmal; processes are continuously being redefined. If you're undertaking application development in this environment, you're not engineering solutions, you're performing R&D and building "oneoff" models that will need constant care and supervision. My telephone line has been on, with the exception of physical interruptions like lightning strikes or substations that were flooded, for 40 years. My Web server needs to be rebooted every week or two, and my desktop computer, with the sixth set of fixes to the operating system installed, still GPFs every day.
The most common phrase you'll see in Microsoft marketing literature these days is "quickly and easily." Sure, for that two-and-a-half-hour demo. But real-world Windows DNA projects are not quick and they're not easy. Well, using today's crop of visual tools is quicker and easier than coding it all in Assembler. But that's about it. These applications are complex systems that take a long time and are hard to design and build. These are enterprise-wise systems that run entire companies. They're not mailing lists. They need to be engineered properly, with reliable tools and repeatable processes.
I've used this term-engineer-for a very specific reason. An editorial in Computing Canada in 1997 made this observation:
"IT projects are not engineering projects. Software research is a better description. In
engineering, a repeatable process is applied to a problem. The technology stays the
same, the tools the same, the process stays the same. If any of these change, the
project goes over budget, or risks failure. With software projects, the technology
changes every project, the tools change every project, and the process is in a
continuous state of flux. Add to this mix that what is likely being built is the
automation of a poorly understood system. All that should be known is that with all
the unknowns, any estimates are educated guesses."
I include this statement in every proposal I submit to a customer.
The track record of application-architecture design in our industry has been uneven. Look at DLL Hell, for example. The progenitor of Windows DNA, the .DLL architecture was supposed to reduce or eliminate multiple applications duplicating the same functionality through component reuse. What actually happened has caused countless hours of lost productivity as developers and network administrators try to reconcile issues caused by incompatible .DLLs.
Who in the military-industrial complex of the 1970s would have imagined a worldwide electronic commerce system being built upon the Internet? As a result, a lot of patches and kludges are being used day to day because the foundation was not intended for the current use.
And what about
I'm not blaming these folks-who knew back then what we'd be doing now? Ten years ago, no one had ever even heard of a terabyte. Last weekend, a bunch of college students just threw together a 2.1-terabyte system of Linux boxes-just to see if they could do it. But the fact remains that the architecture and tools aren't ready for truly well-engineered solutions.
The general approach to developing an architecture has been to throw stuff against the wall and see what sticks, using incessant revisions to fix the big things. This is a strategy introduced by Netscape, where you could live for years on one beta release after another, never having to actually buy a real product. But it bodes poorly for having a stable platform upon which you can develop systems for your customers and users.
Third, there are no comprehensive design tools that can be used to engineer a complete solution. We're being asked to build mission-critical solutions that span the enterprise, and yet we still have a hodgepodge of design and analysis tools that don't work together. Indeed, the toolbox for analysis and design processes that most developers have access to contains Word 97 and a demo copy of Visio.
In addition, the majority of developers building applications are self-taught, poorly trained, and have pulled themselves up by their bootstraps. There are no industry-wide credentialing programs or requirements as there are for medicine, law, accounting, or architecture. Thus, even if there were clearly defined processes and tools, the users-developers like you and me- wouldn't be required to use them, or be monitored as to whether we were using them correctly.
Finally, Microsoft's investment in software has slowed drastically. Most of their investments over the past couple years have been in Internet-related areas, not in the software development arena. The strategy was at one point to help developers create Windows-based applications that spanned the enterprise, so as to expand the reach of Windows throughout the enterprise as has already happened with the desktop. But this may be an afterthought anymore. Application development is clearly not a high priority. Defects continue to be a major issue. With the resources at Microsoft's disposal, they could have a revolutionary effect on defects- both with their own tools, and as a market leader that could influence the rest of the industry, but as I just explained, they won't. As a result, we are left with tools and architectures that are deemed "good enough." Not reliable, not repeatable.
While none of these is bad in and of itself, together they tell me that the WinDNA strategy isn't ready for repeatedly building reliable applications upon.
Nonetheless, though I don't think this stuff is ready for prime time yet, there are others who disagree. As a result, a couple of my authors are looking at a couple of Windows DNA-based books for mid- to late 2000, for example. And there are instances where there are significant business reasons to deploy now, even though the technology isn't stable. They're willing to put in the extra time needed to fine tune and baby sit these types of apps, because, for their particular business or application, it makes economic and competitive sense. So let's open the door, and see what's around the corner.
Where does VFP fit?
I hope you don't have to read this section, but I've included it just in case. Where does Visual FoxPro play in the bigger scheme of things?
First of all, it's still the best tool for developing high-performance desktop and LAN database applications. Period. The native data engine, the visual tools, and the rich programming language and object model-all these combine to make VFP the Dream Team for app dev on the desktop.
It's also a stupendous tool for two-tier applications-it has the same rich tools for developing a front end, and native hooks to attach to back ends as any other tool out there.
As far as three-tier, the position that VFP is supposed to commandeer is that of the middle tier, building business objects that talk to a variety of front ends, such as browser interfaces and UI's built in other languages; process operations and mash data; and then move data back and forth to a data store, such as SQL Server. Again, VFP's rich language features and speed make it ideal for performing these types of tasks.
There's a white paper on the Microsoft Web site-Visual FoxPro Strategy Backgrounder-that details this extremely well. Grab a copy and keep it with you when meeting with customers! To get there, point your browser to msdn.microsoft.com. Then on the left side, select Products, Visual FoxPro, Product Information, Future Directions. You should also be able to search on "Strategy Backgrounder" if the site has been reorganized between the time I wrote this and the time you read this.
What is a type library?
You've probably seen the term "type library" in your various readings, either in an online help file or in other documentation-most often in conjunction with something to do with Visual Basic. And you've probably shrugged it off-you've been able to get through hundreds of pages of developing database applications without hearing about it once. But you're going to hear more and more about type libraries, and eventually you're going to run into a situation where you're going to be asked, during the creation of a component, or the registration of an object, for the type library-or be told that the type library can't be found.
A type library is a binary file with an extension of .TLB that contains the definition of the interface of a COM component. This sounds like I snarfed this out of a C++ manual, so let me explain how you'd use it.
First, though, I want to reiterate what I mean by the term "interface." Many of us are still used to thinking of an interface as that picture on the monitor. That's the user interface. In this context, I'm talking about the programmatic interface-the collection of properties and methods that are visible to other objects.
When you create a COM component, your goal is for other folks to use it. And for those other folks to use it, they're going to have to know the properties and methods-well, the public properties and methods. How do they find out? If they're lucky, you've included documentation and examples, like so (I'm using VFP syntax because you know it):
o = createobject('mycomponent.myclass')m.lcName = o.GetName()
The user knows that there is a method called GetName because they read the documentation. But how does the actual software know? The type library acts as the software's documentation for the interface-the list of the object's properties and methods that are available to the outside world.
Thus, when another object wants to access your component, it's got a method call, like o.GetName, in its program code. However, just because that string of text is in its program code doesn't mean that the object, o, actually has a method called GetName(). The type library tells the calling object that the component that GetName() is okay.
An analogy is if you
went into an apartment building looking for
When you create a VFP COM component, a type library is automatically created. In VFP SP3 on Windows NT, the type library is also automatically included inside the .DLL or .EXE file, which means you don't have to distribute a second file. In earlier versions of VFP or on Windows 95/98, you'll need to distribute the .TLB and .VBR files as well.
Custom user-defined properties and methods are included in VFP type libraries (remember, the type library is simply a "listing" of properties and methods that are available to the outside world) as long as they are defined as PUBLIC. Visual FoxPro type libraries also include a return value type and a list of parameters (all are defined as variants), and property descriptions (if you were good developer and entered descriptions for your properties!).
How does this work inside? Don't know, don't care. But that's why COM components- even COM components created with VFP-need type libraries. Most of the time, as with Service Pack 3 of Visual FoxPro 6.0, the type library details are taken care of for you.
What is a GUID?
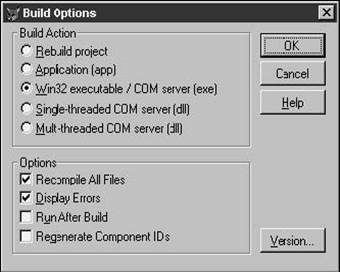
In the Build Options dialog (see Figure 27.1), you'll notice a check box that says "Regenerate Component IDs." Hmmm. What does that do?
Your next step is to open the help, only to find this less-than-lucid explanation:
"Installs and registers Automation servers contained in the project. When marked, this option specifies that new GUIDs (Globally Unique Identifiers) are generated when you build a program. Only those classes marked OLE Public in the Class Info dialog box of the Class menu will be created and registered. This option is enabled when you have marked Build OLE DLL or Build Executable and have already built a program containing the OLEPublic keyword."
Aha! It makes sure new GUIDs are created! But what's a GUID? For the longest time, I thought it meant Gooey, Uooey, Icky Database. Who could have guessed it had to do with computers? Well, maybe you did. So you did a search on "GUID" in MSDN online help (I told you to install the whole thing, didn't I?), and the top-ranked topic is.
SQL OLEDB Provider Events for Visual Studio Analyzer
Helpful, eh? Well, scroll on down a bit more, and find this definition:
"An identifier used to precisely identify objects and interfaces. All Windows applications
and OLE objects have a GUID that is stored in the Windows registry."
So it appears that when you build a project with an OLE Public class (one that will become a server that needs to be registered with Windows), you may want to create a new ID in the Windows registry. But nowhere in the doc does it say why you might want to-or not want to! Here's the deal.
First of all, this check box is enabled only when you want to build a server. You want to check this box when you change the programmatic interface to your server. In other words, if you add or delete public properties or methods, you'll want to have a new GUID generated.
Why? Well, this server is going to be called by another component or object-and you don't know what that is going to be. When you change the interface, that other component or object doesn't automatically know about the change. In fact, when that other component is built, the type library for your server is included in the component. This is how that other component knows what the interface to your server is-and what the GUID for the server is. If you change your server's interface but not the GUID, how is that other component going to know that the interface changed? It won't-it will still use the old type library, which points to the same old GUID, but also describes an interface that is no longer valid. What's the most likely result? GPF city, dude!
When you change the GUID for your server, the type library bound into the other component will now point to a GUID that is no longer valid, and you'll get a nice friendly message like "Server not found." Instead of a GPF.
It actually gets a bit more interesting-see the next bit on early versus late binding.
What's the difference between early and late binding?
If you're hearing or reading about GUIDs and type libraries, you're probably being exposed to terms "early binding" and "late binding" as well. This is clearly another topic that Visual FoxPro developers have been able to live without for a long time-it really smells like a "C" kind of thing-best left alone in many people's minds. But as you get into the world of components and servers and ActiveX controls, you're going to be hearing about this stuff.
When you create an executable, a lot of things are included in the file. As Fox developers, we have been accustomed to ignoring all that-we just waited until the thermometer bar finished scrolling across the screen, and then ran the Setup Wizard.
Different tools perform the executable-building process in different ways.
There's a bunch happening behind the scenes, however, particularly if you include COM components and ActiveX controls. For example, the type libraries for these components can be built right into the executable. In other words, suppose your component-your client-makes method calls to "another server." If, while you're building the component, you can determine what object the methods belong to, the reference is resolved at compile time, and your component includes the code necessary to invoke the server's method.
This makes performance pretty fast-the executable can get to the memory address for a specific method call immediately because it's part of the executable. The call overhead can be a significant part of the total time required to set or retrieve a property, and, for short methods, you can also see huge benefits. This is called early binding. Some people use the term "vtable binding."
However, if you don't build the type library of the component into the executable, you have a more flexible architecture-your executable can read the address of the method at run time. It's slower, but you can make the address dynamic. (Actually, you wouldn't yourself, but the tools you use would do so.) This process-not including the type library into the executable, and reading the addresses at run time-is called late binding. Some people call this "IDispatch binding." The executable is "binding" to the addresses as late as possible-when the app is actually executing.
Thus, particularly with early binding, you'll want to change the GUID for a server when you change the interface, because the actual addresses that are bound into the executable are very likely going to be wrong-so your executable is going to make a call to a routine in memory that isn't there. Yes, that's pretty close to a guaranteed GPF.
Put another way, binding (in general) describes how one object can access properties and methods of another-specifically, how a client can access the interface elements of a server. Early binding provides better performance, but at a loss of flexibility.
What is Visual InterDev?
Visual Studio consists of about a half-dozen tools: Visual Basic, Visual C++, Visual FoxPro, Visual InterDev, and Visual J++. You know what VB and C do, and you probably don't care what J++ does, although you probably guessed it has something to do with Java or the Web. But what's this InterDev? Sounds . cool. Well, sorta confusing, too. Maybe you even opened it up and goofed around a bit. And the question on the tip of your tongue is still, "What is it?"
Well, we can figure this out. "Inter" must have something to do with the Internet! And "Dev" must be for developers, right? Internet Development? OK, we guessed that much already. But what does it do? Does it replace Front Page? Maybe it's a second Java language development environment? Or . what?
It's a development environment-a very, very cool development environment-for putting together database applications that are deployed on the Web. Now, I know you're thinking that there are a lot of tools that claim to do this, so it might be hard to differentiate.
Let me draw an analogy. In the olden days, in order to create an application, you used a file editor-or, more accurately a text editor, to enter a series of commands into a text file. Then you would use a development tool to link libraries with the text file:
C:>emlink myprog.txt lib1.lib, lib2.lib, lib3.lib
Then you would compile that text file, usually through a command line:
C:>emmake myprog.txt myprog.exe
The libraries would automatically be included. Then you would run that executable, sometimes with an additional runtime, and sometimes not:
C:>MYPROG
Then development tools became more sophisticated. They bundled a text editor and some other tools in an integrated package, and you could do the text editing, the linking, the compiling, and even run the executable all within that same program. And these development environments-or "IDE" for Integrated Development Environment-became more and more sophisticated. You could open multiple text files, create lists of subroutines, open link files, store libraries, and so on.
With Windows and other GUI environments came a whole new set of tools that allowed you to create visual components as well as text files, and perform all sorts of related tasks, all within the same IDE. Whether you're using Visual C++, Visual Basic, or Visual FoxPro, life as a developer is pretty good, compared to the old days.
The development of database applications that you want to deploy on the Internet, however, sent developers back to the days of multiple programs, each good for just one thing. One tool was used for creating HTML, another managed site diagrams, a third provided scripts, another deployed files from the development machine to the live Web server, and yet another dealt with the actual databases. And, of course, there were a lot of discontinuities between the tools. There had to be a better way-fortunately, it didn't take 20 years to get to that better way.
Visual InterDev is an integrated environment that does all of this, plus lots, lots more. You can create Web pages, work with style sheets, create components, write scripts, open and manipulate databases, create site diagrams six ways from Sunday, deploy your applications, and even shell out to other programs. And about another million functions that I haven't mentioned.
It's probably the single coolest program with the most potential in Microsoft's stable. It's just awesome. Unfortunately, like much of what Microsoft sends out the door, it's not quite ready for prime time. As of version 6.0, it's very slow, requires huge amounts of resources, and the various pieces are still buggy and don't work well with each other. However, if you recall, the same could be said of many other early Microsoft programs. If they continue to put reasonable resources towards improving VID, it will be the killer tool for the early 2000s.
What's a ProgID?
Sounds like a user-friendly name for a GUID, doesn't it? Well, kinda sorta, but not really. When you create a component and register it with Windows, several entries are made for the component. One is the GUID-that 16-byte value that uniquely identifies the component. However, if you're writing a program and want to refer to that component, you probably don't want to use the GUID. Instead, you can refer to a second entry in the Windows Registry (called a ProgID) for the component.
A ProgID is the "user-friendly" name of the component that you use to instantiate it. The ProgID takes the form of myobj.myclass. That's all!
What does reentrant mean?
You've probably heard the mantra, "Builders are reentrant, wizards aren't." But that doesn't tell you much, other than possibly hinting at the idea that builders are cooler than wizards.
Reentrant, a term borrowed from C++, actually means something slightly different in VFP. In C++, when a program was reentrant, it meant that a second user could run it, and the second user wouldn't interface with the first user. In other words, user A is running a routine, and is currently executing line 20. Then a second user runs the same routine, and is on line 14. If the program is reentrant, there is no conflict. This sounds like a definition of multi-user, but in this case, it's really referring to a blob of code.
In VFP, being reentrant simply means remembering the state when it's run a second time.
What's the difference between "in-process servers" and "out-of-process servers"?
An in-process server-a file with a .DLL extension-is run in the same memory space, and requires fewer resources. It's also faster, because there's no communication needed between one process and another. But crashing the app brings down the server, and crashing the server will likely hose the app. And an in-process server can't be deployed remotely.
Out-of-process-with an .EXE extension-is run in a separate memory space and requires more resources. But it can be deployed remotely. And crashing the server doesn't crash the app, or vice versa. Not every .EXE is an out-of-process server, though. You have to include an OLE Public class in your executable in order to expose functionality of that class to other applications. The very cool thing is that you don't lose any of the normal functionality of your application-the rest of your users may not even know that other applications (not just other users) are calling the application as well.
Where do I go next?
The single best resource to learn more about these things is the Visual Basic Programmer's Journal. While it focuses on VB, it has a ton of useful articles on topics relating to Windows, components, servers, and other Visual Studio-oriented topics. And you might find some of the VB articles interesting as well; the most common use of VB (unbelievably) is to build database applications. You'll learn things about user interfaces, and chortle uncontrollably at the basic information presented about data, but all in all, it's a great read.
You might also try MIND: Microsoft Internet Developer (although they may have changed the name again since this writing). This publication has lots of good stuff-although much of it is slanted for the C++ crowd. There's usually at least one excellent, on-target article each month.
There is a little-known help file for Service Pack 3 of Visual Studio. Look for VFPSP3.CHM in the root of your Visual FoxPro directory (most likely Program FilesMicrosoft Visual StudioVFP98). This file contains a bunch of good information-when you're finished with this chapter, check it out. You'll probably learn much more from this additional help file.
|
Politica de confidentialitate | Termeni si conditii de utilizare |

Vizualizari: 1090
Importanta: ![]()
Termeni si conditii de utilizare | Contact
© SCRIGROUP 2025 . All rights reserved